
 Technology peripherals
AI
Why didn't ICLR accept Mamba's paper? The AI community has sparked a big discussion
Technology peripherals
AI
Why didn't ICLR accept Mamba's paper? The AI community has sparked a big discussion
Why didn't ICLR accept Mamba's paper? The AI community has sparked a big discussion

In 2023, the status of Transformer, the dominant player in the field of AI large models, will begin to be challenged. A new architecture called "Mamba" has emerged. It is a selective state space model that is comparable to Transformer in terms of language modeling, and may even surpass it. At the same time, Mamba can achieve linear scaling as the context length increases, which enables it to handle million-word-length sequences and improve inference throughput by 5 times when processing real data. This breakthrough performance improvement is eye-catching and brings new possibilities to the development of the AI field.
In more than a month after its release, Mamba began to gradually show its influence and spawned many projects such as MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte, etc. . Mamba has shown great potential in continuously overcoming the shortcomings of Transformer. These developments demonstrate Mamba’s continued development and advancement, bringing new possibilities to the field of artificial intelligence.
However, this rising "star" encountered a setback at the 2024 ICLR meeting. The latest public results show that Mamba’s paper is still pending. We can only see its name in the column of pending decision, and we cannot determine whether it was delayed or rejected.

Overall, Mamba received ratings from four reviewers, which were 8/8/6/3 respectively. Some people said it was really puzzling to still be rejected after receiving such a rating.

To understand the reason, we have to look at what the reviewers who gave low scores said.
Paper review page: https://openreview.net/forum?id=AL1fq05o7H
Why is it “not good enough”?
In the review feedback, the reviewer who gave a score of "3: reject, not good enough" explained several opinions about Mamba:
Thoughts on model design:
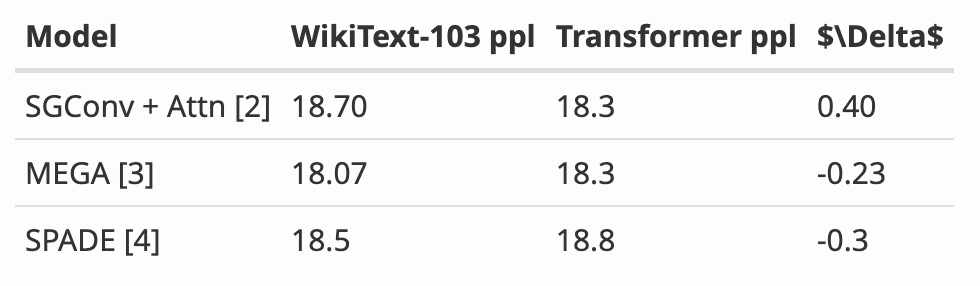
- Mamba’s motivation is to address the shortcomings of recursive models while improving the efficiency of attention-based models. There are many studies along this direction: S4-diagonal [1], SGConv [2], MEGA [3], SPADE [4], and many efficient Transformer models (e.g. [5]). All these models achieve near linear complexity and the authors need to compare Mamba with these works in terms of model performance and efficiency. Regarding model performance, some simple experiments (such as language modeling of Wikitext-103) are enough.
- Many attention-based Transformer models show length generalization ability, that is, the model can be trained on shorter sequence lengths and tested on longer sequence lengths. Examples include relative position encoding (T5) and Alibi [6]. Since SSM is generally continuous, does Mamba have this length generalization ability?
Thoughts on the experiment:
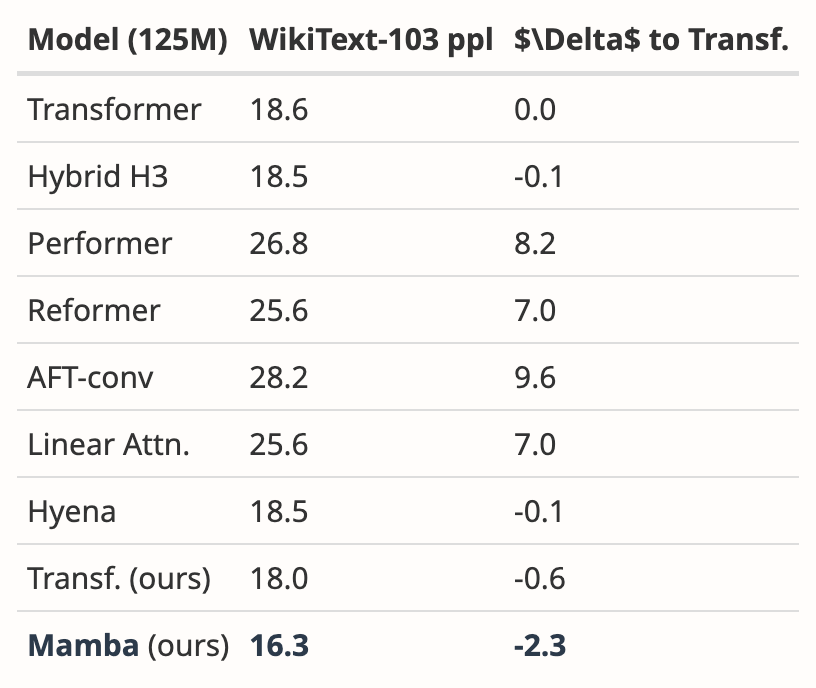
- The authors need to compare to a stronger baseline. The authors stated that H3 was used as motivation for the model architecture, however they did not compare with H3 in experiments. According to Table 4 in [7], on the Pile dataset, the ppl of H3 are 8.8 (1.25 M), 7.1 (3.55 M), and 6.0 (1.3B) respectively, which are significantly better than Mamba. The authors need to show a comparison with H3.
- For the pre-trained model, the author only shows the results of zero-sample inference. This setup is rather limited and the results do not support Mamba's effectiveness well. I recommend that the authors conduct more experiments with long sequences, such as document summarization, where the input sequences are naturally very long (e.g., the average sequence length of the arXiv dataset is >8k).
- The author claims that one of his main contributions is long sequence modeling. The authors should compare with more baselines on LRA (Long Range Arena), which is basically the standard benchmark for long sequence understanding.
- Missing memory benchmark. Although Section 4.5 is titled “Speed and Memory Benchmarks,” only speed comparisons are presented. In addition, the authors should provide more detailed settings on the left side of Figure 8, such as model layers, model size, convolution details, etc. Can the authors provide some intuition as to why FlashAttention is slowest when the sequence length is very large (Figure 8 left)?
Additionally, another reviewer also pointed out a shortcoming of Mamba: the model still has secondary memory requirements during training like Transformers.
Author: Revised, please review
After summarizing the opinions of all reviewers, the author team also revised and improved the content of the paper and added new Experimental results and analysis:
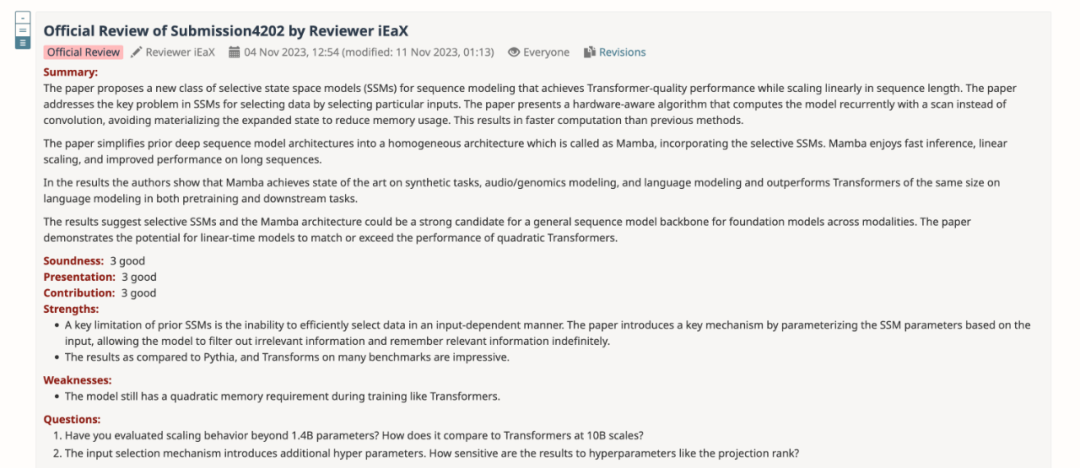
- Added the evaluation results of the H3 model
The author downloaded the size to 125M-2.7 Pretrained H3 model with B parameters and performed a series of evaluations. Mamba is significantly better in all language evaluations. It is worth noting that these H3 models are hybrid models using quadratic attention, while the author's pure model using only the linear-time Mamba layer is significantly better in all indicators. .
The evaluation comparison with the pre-trained H3 model is as follows:
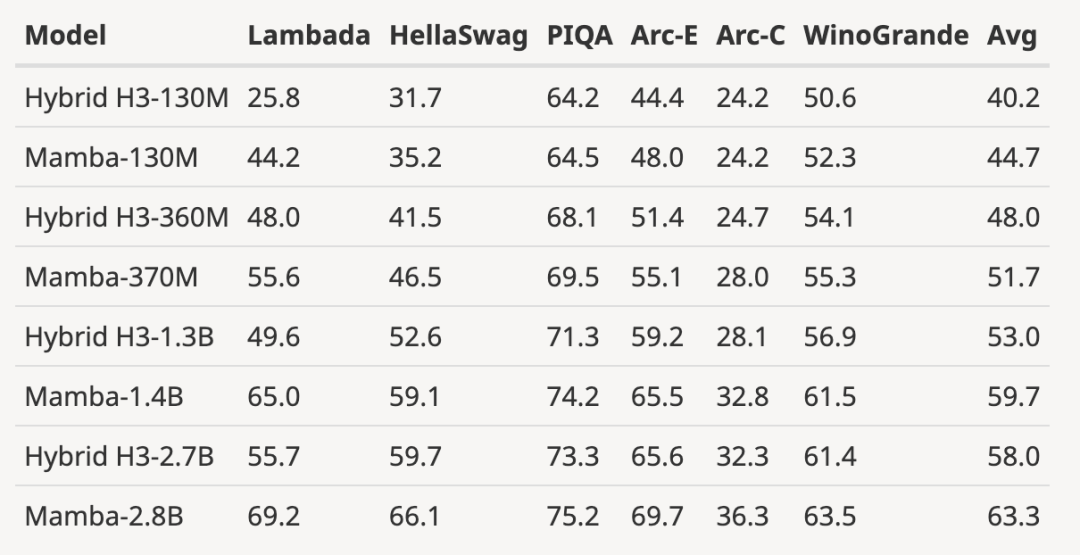
- ##Expand the fully trained model to a larger model size
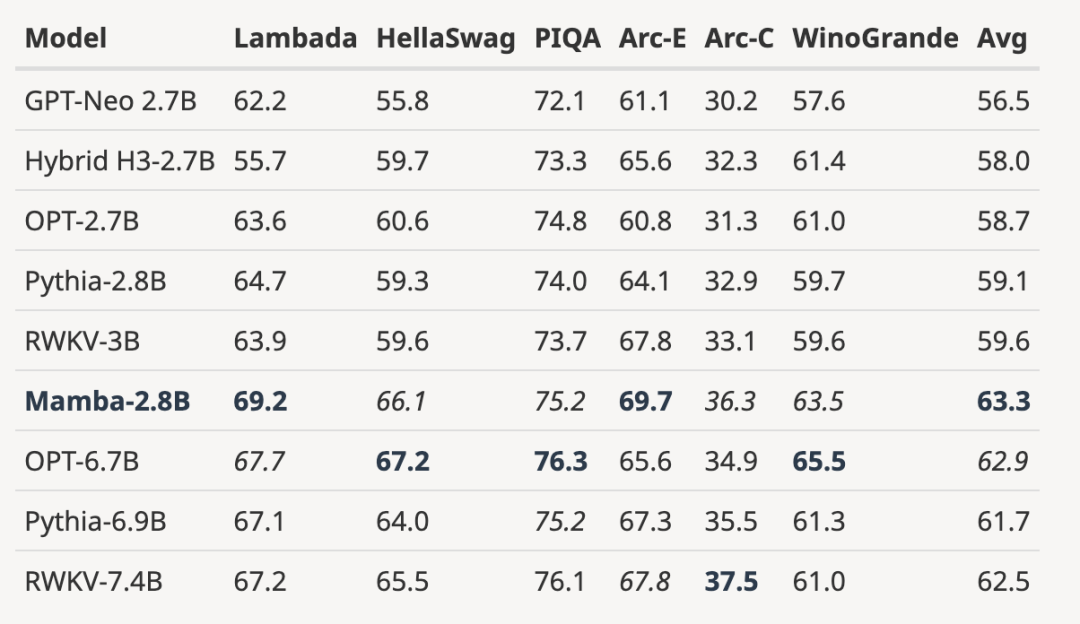
As shown in the figure below, with 3B open source trained based on the same number of tokens (300B) Compared with the model, Mamba is superior in every evaluation result. It is even comparable to 7B-scale models: when comparing Mamba (2.8B) with OPT, Pythia and RWKV (7B), Mamba achieves the best average score and best/second best on every benchmark Score.
- shows the length extrapolation results beyond the training length
The author has attached a picture to evaluate the length extrapolation of the pre-trained 3B parameter language model:
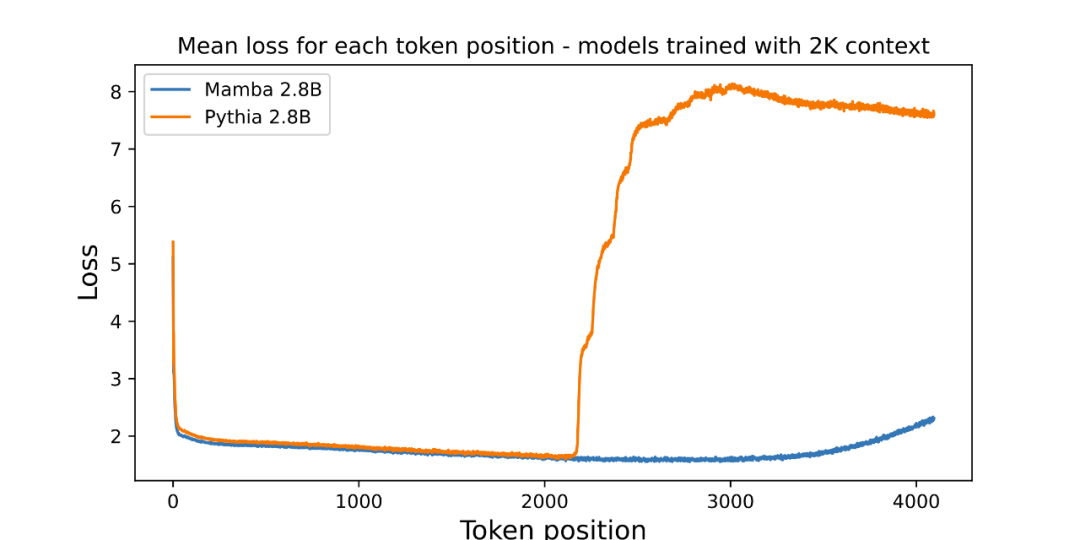
Picture The average loss (log readability) per position is plotted in . The perplexity of the first token is high because it has no context, while the perplexity of both Mamba and the baseline Transformer (Pythia) increases before training on the context length (2048). Interestingly, Mamba's solvability improves significantly beyond its training context, up to a length of around 3000.
The author emphasizes that length extrapolation is not a direct motivation for the model in this article, but treats it as an additional feature:
- The baseline model here (Pythia) was not trained with length extrapolation in mind, and there may be other Transformer variants that are more general (such as T5 or Alibi relative position encoding).
- No open source 3B models trained on Pile using relative position encoding were found, so this comparison cannot be made.
- Mamba, like Pythia, does not take length extrapolation into account when training, so it is not comparable. Just as Transformers have many techniques (such as different positional embeddings) to improve their ability on length generalization isometrics, it might be interesting in future work to derive SSM-specific techniques for similar capabilities.
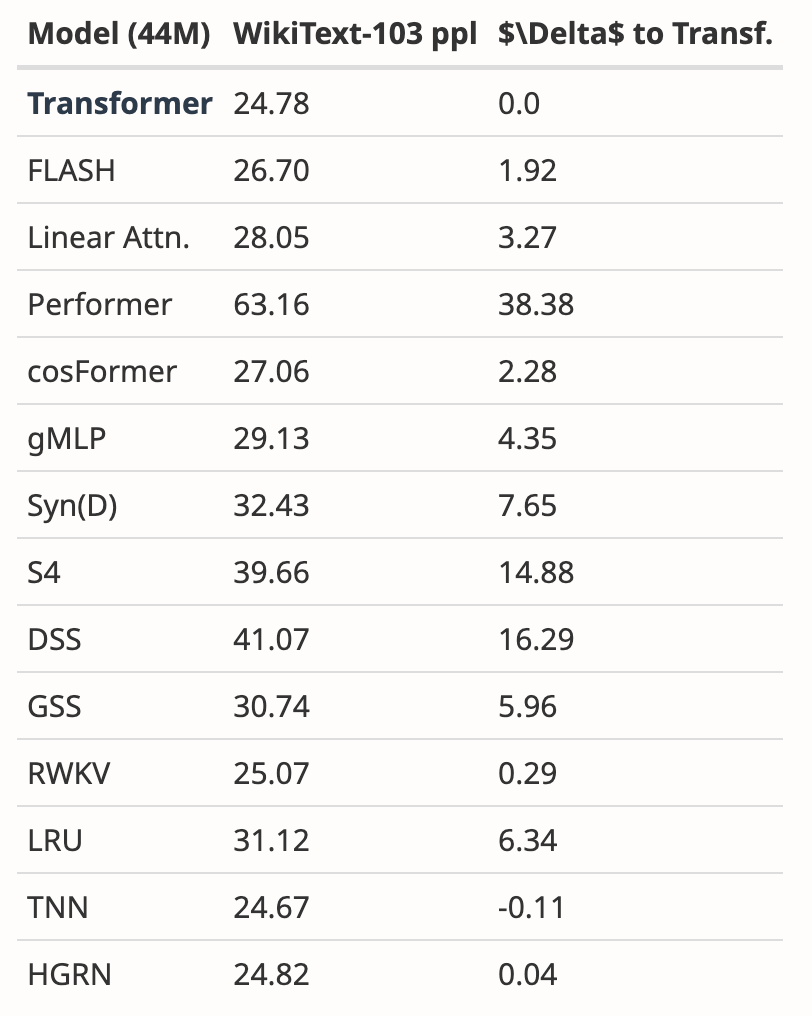
- Added new results from WikiText-103
The author analyzed the results of multiple papers, It shows that Mamba performs significantly better on WikiText-103 than more than 20 other state-of-the-art sub-quadratic sequence models.
In major AI top conferences, "explosion in the number of submissions" is a headache, so energy is limited Reviewers will inevitably make mistakes. This has led to the rejection of many famous papers in history, including YOLO, transformer XL, Dropout, support vector machine (SVM), knowledge distillation, SIFT, and Google search engine's webpage ranking algorithm PageRank (see: "The famous YOLO and PageRank influential research was rejected by the top CS conference"). Even Yann LeCun, one of the three giants of deep learning, is also a major paper maker who is often rejected. Just now, he tweeted that his paper "Deep Convolutional Networks on Graph-Structured Data", which has been cited 1887 times, was also rejected by the top conference. During ICML 2022, he even "submitted three articles and three were rejected." So, just because a paper is rejected by a top conference does not mean it has no value. Among the above-mentioned rejected papers, many chose to transfer to other conferences and were eventually accepted. Therefore, netizens suggested that Mamba switch to COLM, which was established by young scholars such as Chen Danqi. COLM is an academic venue dedicated to language modeling research, focused on understanding, improving, and commenting on the development of language model technology, and may be a better choice for papers like Mamba's. However, regardless of whether Mamba is ultimately accepted by ICLR, it has become an influential work and has allowed the community to see a breakthrough The hope of Transformer shackles has injected new vitality into the exploration beyond the traditional Transformer model. Those papers rejected by top conferences

The above is the detailed content of Why didn't ICLR accept Mamba's paper? The AI community has sparked a big discussion. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to get logged in user information in WordPress for personalized results
Apr 19, 2025 pm 11:57 PM
How to get logged in user information in WordPress for personalized results
Apr 19, 2025 pm 11:57 PM
Recently, we showed you how to create a personalized experience for users by allowing users to save their favorite posts in a personalized library. You can take personalized results to another level by using their names in some places (i.e., welcome screens). Fortunately, WordPress makes it very easy to get information about logged in users. In this article, we will show you how to retrieve information related to the currently logged in user. We will use the get_currentuserinfo(); function. This can be used anywhere in the theme (header, footer, sidebar, page template, etc.). In order for it to work, the user must be logged in. So we need to use
 How to elegantly obtain entity class variable names to build database query conditions?
Apr 19, 2025 pm 11:42 PM
How to elegantly obtain entity class variable names to build database query conditions?
Apr 19, 2025 pm 11:42 PM
When using MyBatis-Plus or other ORM frameworks for database operations, it is often necessary to construct query conditions based on the attribute name of the entity class. If you manually every time...
 Java BigDecimal operation: How to accurately control the accuracy of calculation results?
Apr 19, 2025 pm 11:39 PM
Java BigDecimal operation: How to accurately control the accuracy of calculation results?
Apr 19, 2025 pm 11:39 PM
Java...
 How to solve the problem of username and password authentication failure when connecting to local EMQX using Eclipse Paho?
Apr 19, 2025 pm 04:54 PM
How to solve the problem of username and password authentication failure when connecting to local EMQX using Eclipse Paho?
Apr 19, 2025 pm 04:54 PM
How to solve the problem of username and password authentication failure when connecting to local EMQX using EclipsePaho's MqttAsyncClient? Using Java and Eclipse...
 How to properly configure apple-app-site-association file in pagoda nginx to avoid 404 errors?
Apr 19, 2025 pm 07:03 PM
How to properly configure apple-app-site-association file in pagoda nginx to avoid 404 errors?
Apr 19, 2025 pm 07:03 PM
How to correctly configure apple-app-site-association file in Baota nginx? Recently, the company's iOS department sent an apple-app-site-association file and...
 How to package in IntelliJ IDEA for specific Git versions to avoid including unfinished code?
Apr 19, 2025 pm 08:18 PM
How to package in IntelliJ IDEA for specific Git versions to avoid including unfinished code?
Apr 19, 2025 pm 08:18 PM
In IntelliJ...
 How to process and display percentage numbers in Java?
Apr 19, 2025 pm 10:48 PM
How to process and display percentage numbers in Java?
Apr 19, 2025 pm 10:48 PM
Display and processing of percentage numbers in Java In Java programming, the need to process and display percentage numbers is very common, for example, when processing Excel tables...
 How to efficiently query large amounts of personnel data through natural language processing?
Apr 19, 2025 pm 09:45 PM
How to efficiently query large amounts of personnel data through natural language processing?
Apr 19, 2025 pm 09:45 PM
Effective method of querying personnel data through natural language processing How to efficiently use natural language processing (NLP) technology when processing large amounts of personnel data...
