

Research on optimizing SQL efficiency

This is a case shared by teacher Chen Hongyi (Old K) at the Shanghai MOORACLE Conference in August 2016. By rewriting a merge SQL into plsql, the execution efficiency was greatly improved. When Tiger Liu saw this case, he initially did not notice the actual number of records in each table displayed in the execution plan. He did not think that the way of rewriting plsql was more efficient than the way of writing analytic functions. He also had several email discussions with Teacher Chen. It wasn’t until later that I took a closer look at the execution plan.
The original SQL is as follows:merge into t_customer c using
(
select a.cstno, a.amount from t_trade a,
(select cstno,max(trade_date) trade_date from t_trade
group by cstno) b
where a.cstno = b.cstno and a.trade_date=b.trade_date
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
This SQL is to update the latest consumption amount in the user transaction details table (t_trade) to the consumption amount field in the user information table (t_customer), using the merge operation.
Implementation plan:

Tiger Liu Note:
Before mastering the writing method of analysis function, the red part of SQL is a common way of writing other field information after group by, which is also the fundamental reason for the poor execution efficiency of this SQL.
There is another hidden danger in the original SQL, that is, if the maximum trade_date corresponding to a certain cstno of t_trade is repeated, then this SQL will report an ORA-30926 error and cannot be executed.
If you don’t look carefully at the execution plan (real data volume information of the two tables), the usual optimization method for this kind of SQL is to use analytic functions to rewrite:
Rewriting method 1:merge into t_customer c using
(
select a.cstno,a.amount from
(select trade_date,cstno,amount,
row_number()over(partition by cstno order by trade_date desc) RNO from t_trade)a
where RNO=1
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
This rewriting method will be much more efficient than the original SQL, and there will be no problem of repeated error reports for max trade_date corresponding to a certain cstno.
However, Teacher Chen did not use the rewriting method of analytic function. Instead, based on the large difference in data volume between the two tables, he rewritten the SQL into a more efficient plsql:
Rewriting method 2:declare
vamount number;
begin
for v in (select * from t_customer )
loop
select amount into vamount from
(select amount from t_trade where cstno=v.cstno order by trade_date desc)
where rownum
update t_customer set amount = vamount where cstno=v.cstno;
end loop
commit;
end;
/
According to the original SQL execution plan, we know that the number of records in the t_customer table is relatively small, only more than 1,000, while the t_trade table has 10 million records, with a ratio of 1:10000 (I don’t know if this is real data or test data, only There are more than 1,000 users, and an average user has 10,000 consumption details, which does not look like real data).
In such a special case where the data between the two tables is quite different, the plsql writing method is indeed more efficient than the analytical function writing method. This rewriting is very clever.
Let’s analyze the advantages and disadvantages of these two rewritings:1. The rewriting method of plsql is suitable when the t_customer table is relatively small, and the ratio of the number of records in the t_customer and t_trade tables is relatively large. The execution efficiency will be higher than the rewriting of the analytical function. In this example, if the number of records in the t_customer table is 100,000, then the way of writing the analytical function is dozens to hundreds of times faster than the way of writing plsql.
3. The prerequisite for this rewriting of plsql is that there must be a joint index of the two fields of the t_trade table cstno trade_date. The rewriting of analytic functions does not require any index support.
4. For tables with tens of millions of records like t_trade, writing analytical functions can speed up by turning on parallelism; if you want to improve efficiency when rewriting plsql, you need to first group the t_customer table by cstno and use multiple sessions. Concurrent execution.
Let’s see if Teacher Chen’s plsql can be implemented with a single sql. I made an attempt. The SQL code is as follows:
merge into t_customer c using
(
select tc.cstno,
(select amount
from t_trade td1
where td1.cstno=tc.cstno and td1.trade_date = (select max(trade_date) from t_trade td2 where tc.cstno = td2.cstno) and rownum=1 ) as amount
from t_customer tc
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
The execution plan is roughly as follows:
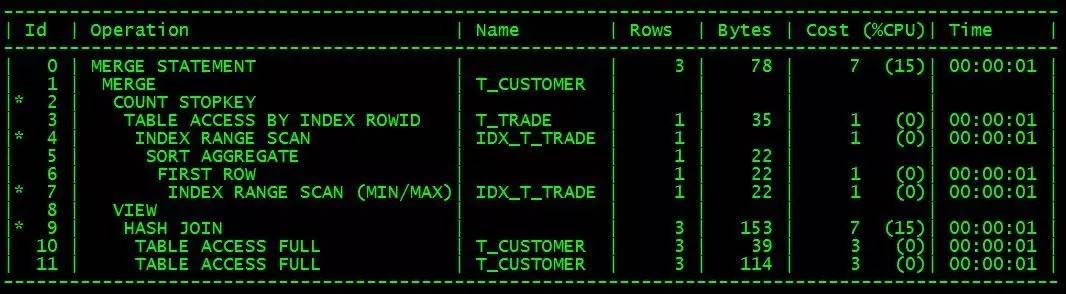
This writing method also requires the cstno trade_date joint index (IDX_T_TRADE) to exist in the t_trade table, and the data volume of the T_customer table is much lower than that of T_trade.
According to the execution plan, the execution efficiency of this sql should be comparable to that of plsql writing.
Summarize:SQL optimization, in addition to avoiding inefficient SQL writing, mainly depends on the data volume and data distribution of the table. The rewriting method of plsql will show higher efficiency in a few special cases. In some cases of data distribution, the efficiency may not be as good as the original SQL. However, the optimization ideas are worth learning from.
The way the analysis function is rewritten, no matter how the data is distributed, will be more efficient and more versatile than the original SQL.
There should still be many developers and DBAs using the SQL before this example was rewritten. After understanding how to use the analysis function, the inefficient way of writing the original SQL should be completely abandoned.
The last plsql is rewritten into a single SQL. The logic seems to be complicated and difficult to understand. Generally, such rewriting is not used. It would be nice for everyone to understand it.
Again, there is no definite formula for optimization. The optimizer is dead, but the human brain is alive. Only by mastering the principles can SQL execution efficiency become higher and higher.
The above is the detailed content of Research on optimizing SQL efficiency. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
DeepSeek is a powerful intelligent search and analysis tool that provides two access methods: web version and official website. The web version is convenient and efficient, and can be used without installation; the official website provides comprehensive product information, download resources and support services. Whether individuals or corporate users, they can easily obtain and analyze massive data through DeepSeek to improve work efficiency, assist decision-making and promote innovation.
 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet is a cryptocurrency exchange that provides a variety of trading services including spot trading, contract trading and derivatives. Founded in 2018, the exchange is headquartered in Singapore and is committed to providing users with a safe and reliable trading platform. BITGet offers a variety of trading pairs, including BTC/USDT, ETH/USDT and XRP/USDT. Additionally, the exchange has a reputation for security and liquidity and offers a variety of features such as premium order types, leveraged trading and 24/7 customer support.
 Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi OKX, the world's leading digital asset exchange, has now launched an official installation package to provide a safe and convenient trading experience. The OKX installation package of Ouyi does not need to be accessed through a browser. It can directly install independent applications on the device, creating a stable and efficient trading platform for users. The installation process is simple and easy to understand. Users only need to download the latest version of the installation package and follow the prompts to complete the installation step by step.
 Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Gate.io is a popular cryptocurrency exchange that users can use by downloading its installation package and installing it on their devices. The steps to obtain the installation package are as follows: Visit the official website of Gate.io, click "Download", select the corresponding operating system (Windows, Mac or Linux), and download the installation package to your computer. It is recommended to temporarily disable antivirus software or firewall during installation to ensure smooth installation. After completion, the user needs to create a Gate.io account to start using it.
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, also known as OKX, is a world-leading cryptocurrency trading platform. The article provides a download portal for Ouyi's official installation package, which facilitates users to install Ouyi client on different devices. This installation package supports Windows, Mac, Android and iOS systems. Users can choose the corresponding version to download according to their device type. After the installation is completed, users can register or log in to the Ouyi account, start trading cryptocurrencies and enjoy other services provided by the platform.
 gate.io official website registration installation package link
Feb 21, 2025 pm 08:15 PM
gate.io official website registration installation package link
Feb 21, 2025 pm 08:15 PM
Gate.io is a highly acclaimed cryptocurrency trading platform known for its extensive token selection, low transaction fees and a user-friendly interface. With its advanced security features and excellent customer service, Gate.io provides traders with a reliable and convenient cryptocurrency trading environment. If you want to join Gate.io, please click the link provided to download the official registration installation package to start your cryptocurrency trading journey.
 How to Install phpMyAdmin with Nginx on Ubuntu?
Feb 07, 2025 am 11:12 AM
How to Install phpMyAdmin with Nginx on Ubuntu?
Feb 07, 2025 am 11:12 AM
This tutorial guides you through installing and configuring Nginx and phpMyAdmin on an Ubuntu system, potentially alongside an existing Apache server. We'll cover setting up Nginx, resolving potential port conflicts with Apache, installing MariaDB (
