

Netizens exposed the embedding technology used in OpenAI's new model

A few days ago, OpenAI had a major update and announced 5 new models in one go, including two new text embedding models.
Embedding is the use of numerical sequences to represent concepts in natural language, code, etc. They help machine learning models and other algorithms better understand the relationships between content and make it easier to perform tasks such as clustering or retrieval.
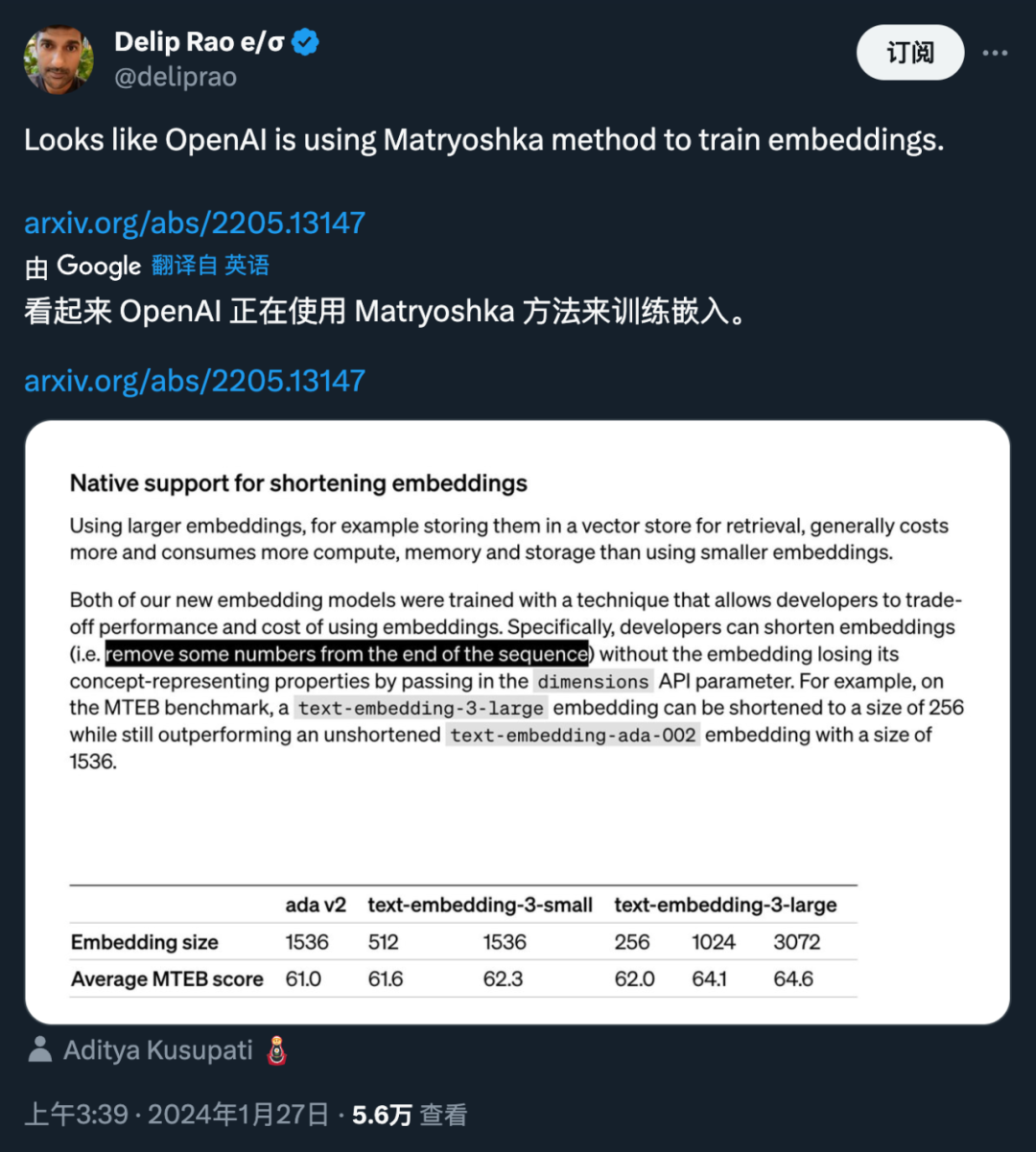
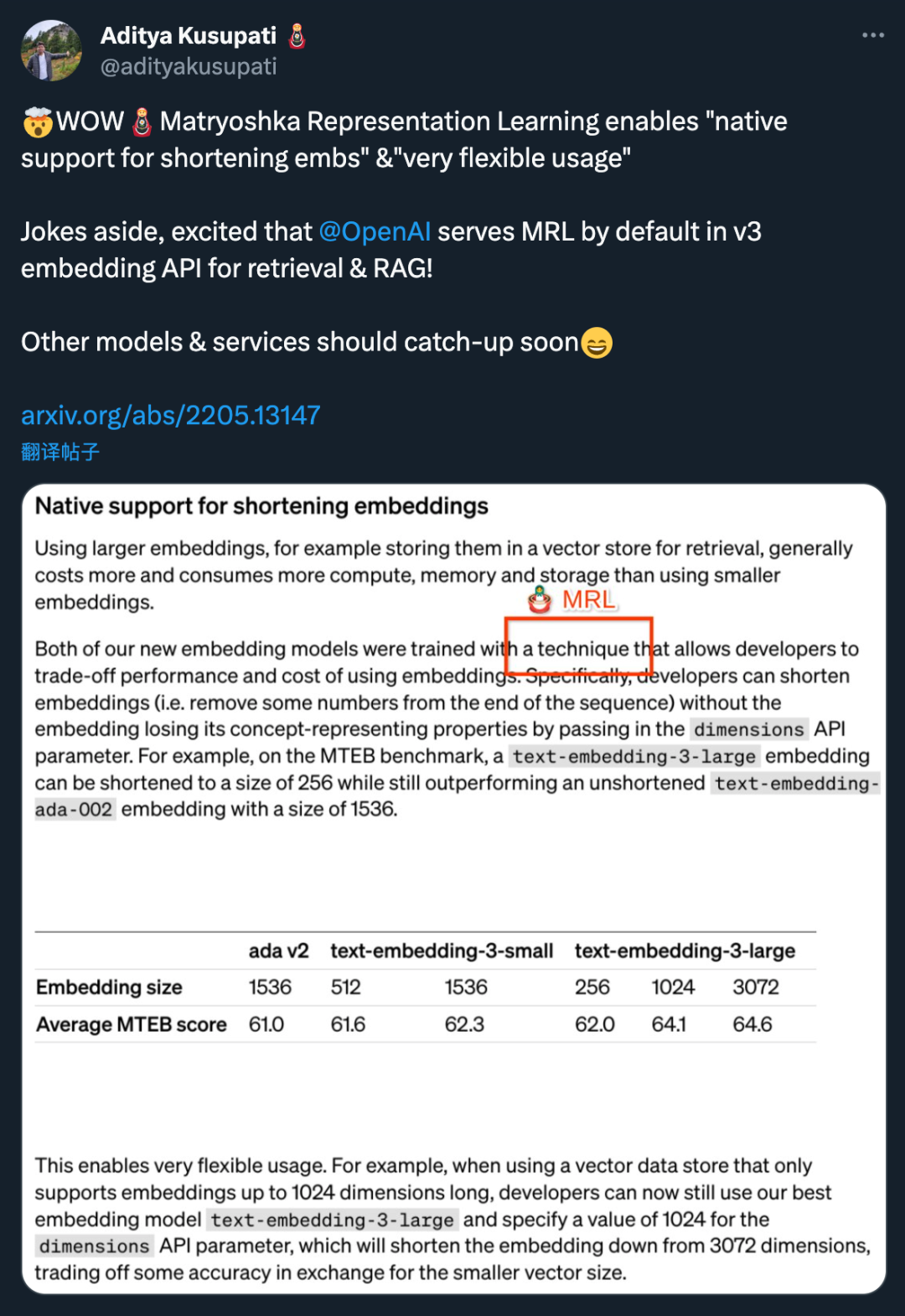
Generally, using larger embedding models (such as stored in vector memory for retrieval) consumes more cost, computing power, memory and storage resources. However, the two text embedding models launched by OpenAI offer different options. First, the text-embedding-3-small model is a smaller but efficient model. It can be used in resource-limited environments and performs well when handling text embedding tasks. On the other hand, the text-embedding-3-large model is larger and more powerful. This model can handle more complex text embedding tasks and provide more accurate and detailed embedding representations. However, using this model requires more computing resources and storage space. Therefore, depending on the specific needs and resource constraints, a suitable model can be selected to balance the relationship between cost and performance.
Both new embedding models are performed using a training technique that allows developers to trade off the performance and cost of embedding. Specifically, developers can shorten the size of the embedding without losing its conceptual representation properties by passing the embedding in the dimensions API parameter. For example, on the MTEB benchmark, text-embedding-3-large can be shortened to a size of 256 but still outperforms the unshortened text-embedding-ada-002 embedding (of size 1536). In this way, developers can choose a suitable embedding model based on specific needs, which can not only meet performance requirements but also control costs.

#The application of this technology is very flexible. For example, when using a vector data store that only supports embeddings up to 1024 dimensions, a developer can select the best embedding model text-embedding-3-large and change the embedding dimensions from 3072 by specifying a value of 1024 for the dimensions API parameter. shortened to 1024. Although some accuracy may be sacrificed by doing this, smaller vector sizes can be obtained.
The "shortened embedding" method used by OpenAI subsequently attracted widespread attention from researchers.
It was found that this method is the same as the "Matryoshka Representation Learning" method proposed in a paper in May 2022.
Hidden behind OpenAI’s new embedding model update is a cool one proposed by @adityakusupati et al. Embedding representation technology.
And Aditya Kusupati, one of the authors of MRL, also said: "OpenAI uses MRL by default in the v3 embedded API for retrieval and RAG! Other models and services should catch up soon."
So what exactly is MRL? How's the effect? It’s all in the 2022 paper below.
MRL Paper Introduction

- ##Paper title: Matryoshka Representation Learning
- Paper link: https://arxiv.org/pdf/2205.13147.pdf
The question posed by the researchers is: Can a flexible representation method be designed to adapt to multiple downstream tasks with different computing resources?
MRL learns representations of different capacities in the same high-dimensional vector by explicitly optimizing O (log (d)) low-dimensional vectors in a nested manner, hence the name Matryoshka "Russian matryoshka doll". MRL can be adapted to any existing representation pipeline and can be easily extended to many standard tasks in computer vision and natural language processing.
Figure 1 shows the core idea of MRL and the adaptive deployment setup of the learned Matryoshka representation:
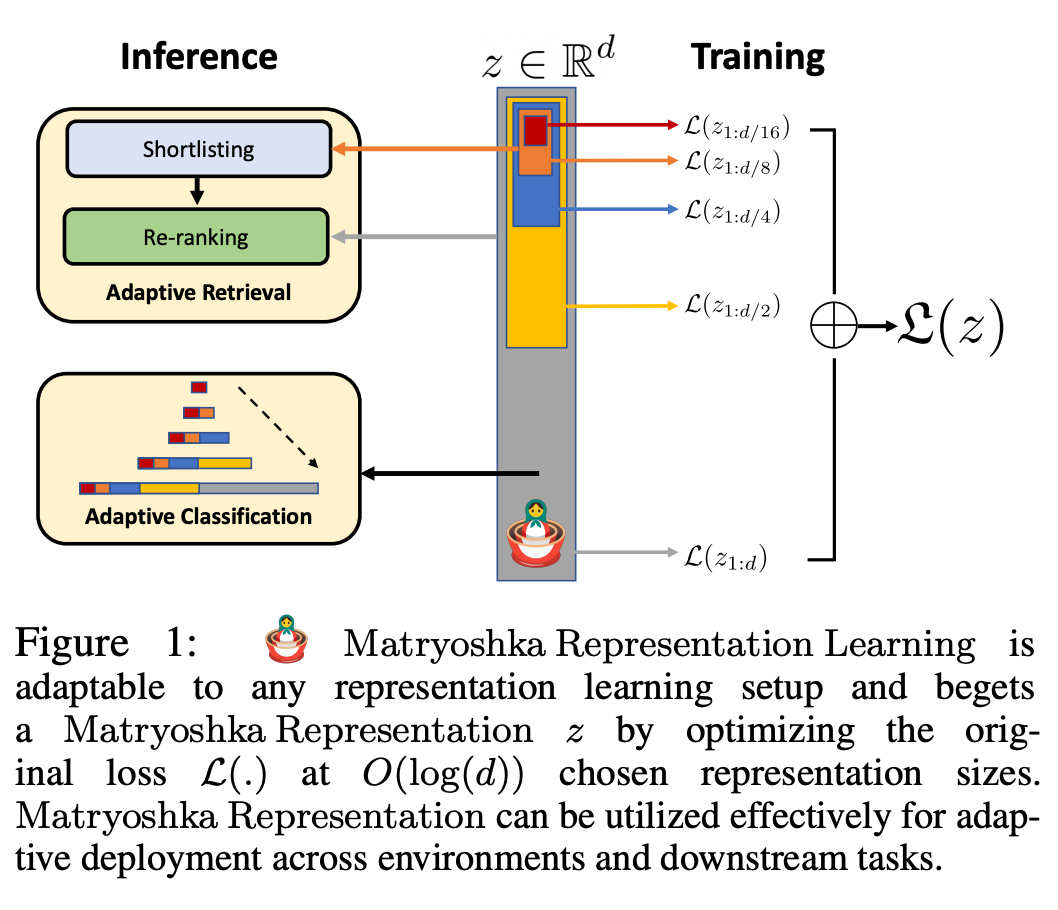
The first of Matryoshka representation An m-dimensions (m∈[d]) is an information-rich low-dimensional vector that requires no additional training cost and is as accurate as an independently trained m-dimensional representation. The information content of Matryoshka representations increases with increasing dimensionality, forming a coarse-to-fine representation without requiring extensive training or additional deployment overhead. MRL provides the required flexibility and multi-fidelity for characterizing vectors, ensuring a near-optimal trade-off between accuracy and computational effort. With these advantages, MRL can be deployed adaptively based on accuracy and computational constraints.
In this work, we focus on two key building blocks of real-world ML systems: large-scale classification and retrieval.
For classification, the researchers used adaptive cascades and used variable-size representations produced by models trained by MRL, which greatly reduced the time required to achieve a specific accuracy. Embedded average dimensionality. For example, on ImageNet-1K, MRL adaptive classification results in representation size reduction of up to 14x with the same accuracy as the baseline.
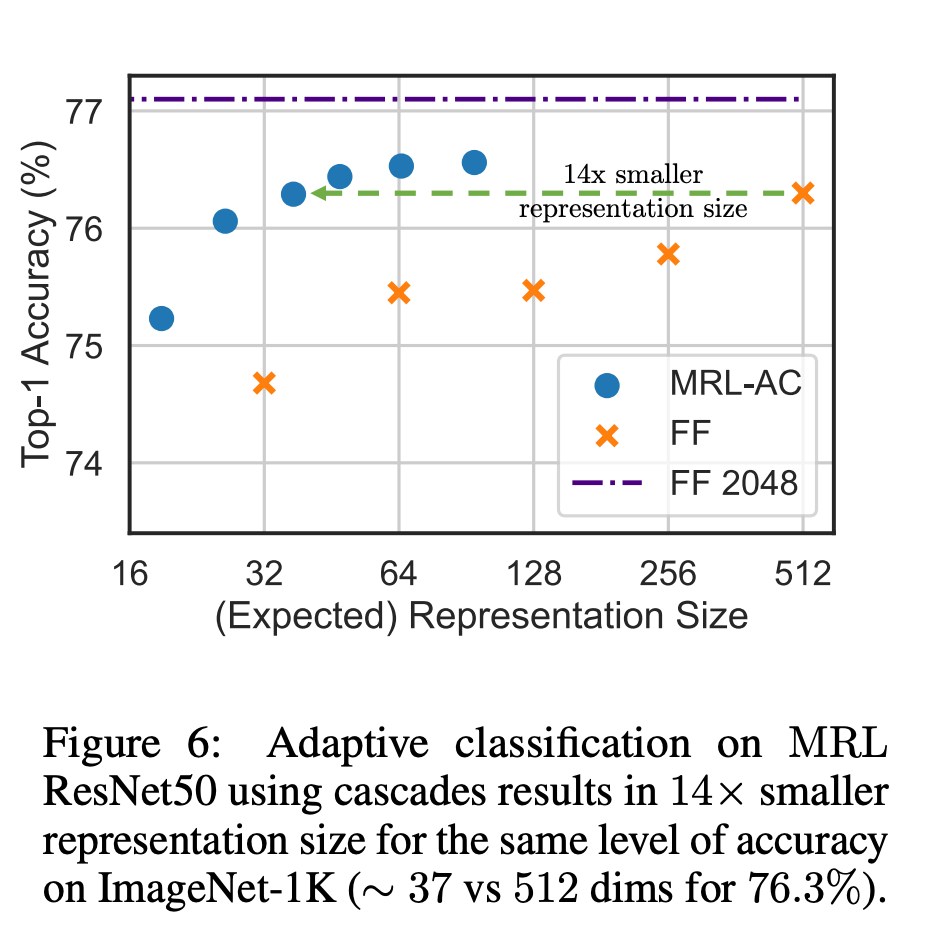
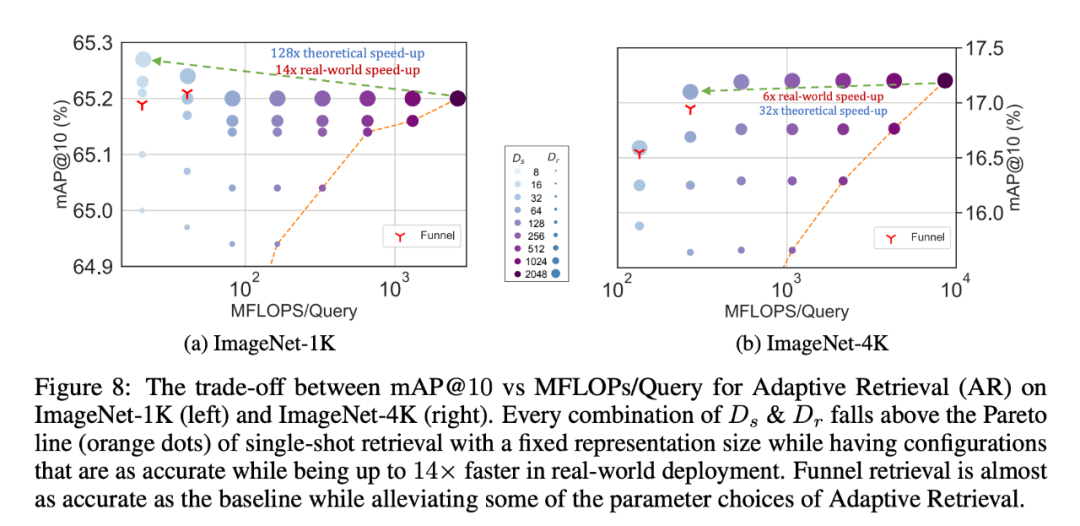
Similarly, researchers have also used MRL in adaptive retrieval systems. Given a query, the first few dimensions of the query embedding are used to filter the retrieval candidates, and then successively more dimensions are used to reorder the retrieval set. A simple implementation of this approach achieves 128x the theoretical speed in FLOPS and 14x the wall clock time compared to a single retrieval system using standard embedding vectors; it is important to note that the retrieval accuracy of MRL Comparable to the accuracy of a single retrieval (Section 4.3.1).
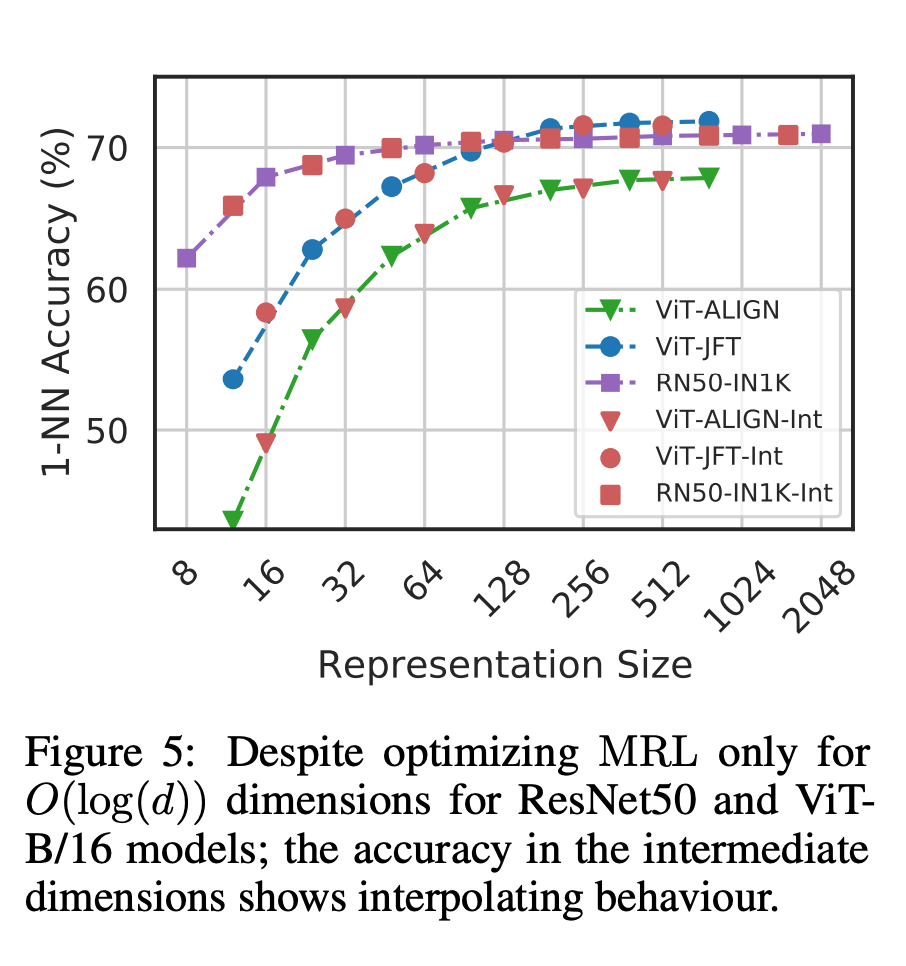
Finally, since MRL explicitly learns the representation vector from coarse to fine, intuitively it should be shared among different dimensions More semantic information (Figure 5). This is reflected in long-tail continuous learning settings, which can improve accuracy by up to 2% while being as robust as the original embeddings. In addition, due to the coarse-grained to fine-grained nature of MRL, it can also be used as a method to analyze the ease of instance classification and information bottlenecks.
For more research details, please refer to the original text of the paper.
The above is the detailed content of Netizens exposed the embedding technology used in OpenAI's new model. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
SQLLIMIT clause: Control the number of rows in query results. The LIMIT clause in SQL is used to limit the number of rows returned by the query. This is very useful when processing large data sets, paginated displays and test data, and can effectively improve query efficiency. Basic syntax of syntax: SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows: Specify the number of rows returned. Syntax with offset: SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset: Skip
 Laravel Eloquent ORM in Bangla partial model search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent ORM in Bangla partial model search)
Apr 08, 2025 pm 02:06 PM
LaravelEloquent Model Retrieval: Easily obtaining database data EloquentORM provides a concise and easy-to-understand way to operate the database. This article will introduce various Eloquent model search techniques in detail to help you obtain data from the database efficiently. 1. Get all records. Use the all() method to get all records in the database table: useApp\Models\Post;$posts=Post::all(); This will return a collection. You can access data using foreach loop or other collection methods: foreach($postsas$post){echo$post->
 How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.
 The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The MySQL primary key cannot be empty because the primary key is a key attribute that uniquely identifies each row in the database. If the primary key can be empty, the record cannot be uniquely identifies, which will lead to data confusion. When using self-incremental integer columns or UUIDs as primary keys, you should consider factors such as efficiency and space occupancy and choose an appropriate solution.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
