

With the success of large language models such as LLaMA and Mistral, many companies have begun to create their own large language models. However, training a new model from scratch is expensive and may have redundant capabilities.
Recently, researchers from Sun Yat-sen University and Tencent AI Lab proposed FuseLLM, which is used to "fuse multiple heterogeneous large models."
Different from traditional model integration and weight merging methods, FuseLLM provides a new way to fuse the knowledge of multiple heterogeneous large language models. Instead of deploying multiple large language models at the same time or requiring the merging of model results, FuseLLM uses a lightweight continuous training method to transfer the knowledge and capabilities of individual models into a fused large language model. What is unique about this approach is its ability to use multiple heterogeneous large language models at inference time and externalize their knowledge into a fused model. In this way, FuseLLM effectively improves the performance and efficiency of the model.
The paper has just been published on arXiv and has attracted a lot of attention and forwarding from netizens.

Someone thought it would be interesting to train a model on another language and I’ve been thinking about it.
This paper has been accepted by ICLR 2024.

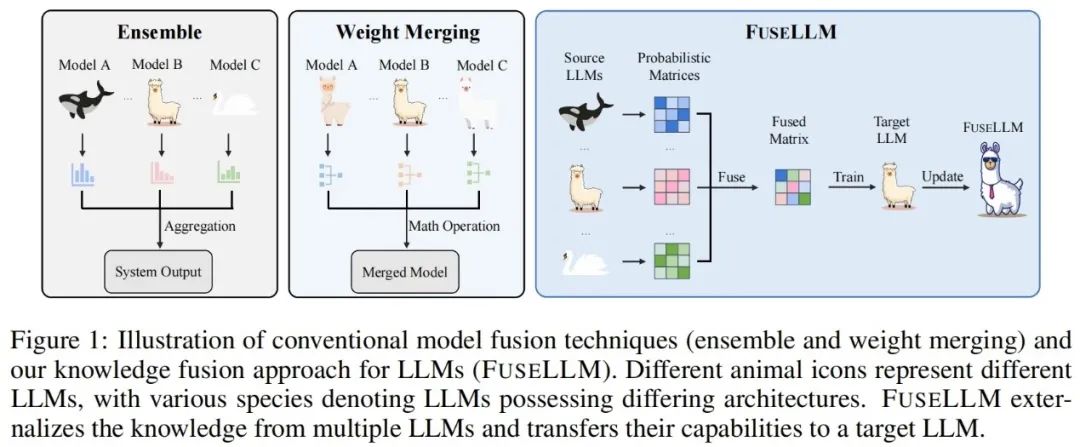
In order to combine the collective knowledge of multiple large language models while maintaining their respective strengths, strategies for fused model-generated representations need to be carefully designed. Specifically, FuseLLM evaluates how well different large language models understand this text by calculating the cross-entropy between the generated representation and the label text, and then introduces two fusion functions based on cross-entropy:
Experimental results
The author evaluated FuseLLM in scenarios such as general reasoning, common sense reasoning, code generation, text generation, and instruction following, and found that it achieved significant performance improvements compared to all source models and continued training baseline models. General Reasoning & Common Sense Reasoning ## On the Big-Bench Hard Benchmark that tests general reasoning capabilities, Llama-2 CLM after continuous training achieved an average improvement of 1.86% on 27 tasks compared to Llama-2, while FuseLLM achieved an average improvement of 1.86% compared to Llama-2. An improvement of 5.16% was achieved, which is significantly better than Llama-2 CLM, indicating that FuseLLM can combine the advantages of multiple large language models to achieve performance improvements. On the Common Sense Benchmark, which tests common sense reasoning ability, FuseLLM surpassed all source models and baseline models, achieving the best performance on all tasks. Code Generation & Text Generation On multiple text generation benchmarks measuring knowledge question answering (TrivialQA), reading comprehension (DROP), content analysis (LAMBADA), machine translation (IWSLT2017) and theorem application (SciBench) ,FuseLLM also outperforms all source models in all tasks,and outperforms Llama-2 CLM in 80% of tasks.
directive follows FuseLLM vs. Knowledge Distillation & Model Integration & Weight Merging
Finally, although the community has been paying attention to the fusion of large models, current practices are mostly based on weight merging and cannot be extended to model fusion scenarios of different structures and sizes. Although FuseLLM is only a preliminary research on heterogeneous model fusion, considering that there are currently a large number of language, visual, audio and multi-modal large models of different structures and sizes in the technical community, what will the fusion of these heterogeneous models burst out in the future? Astonishing performance? let us wait and see! 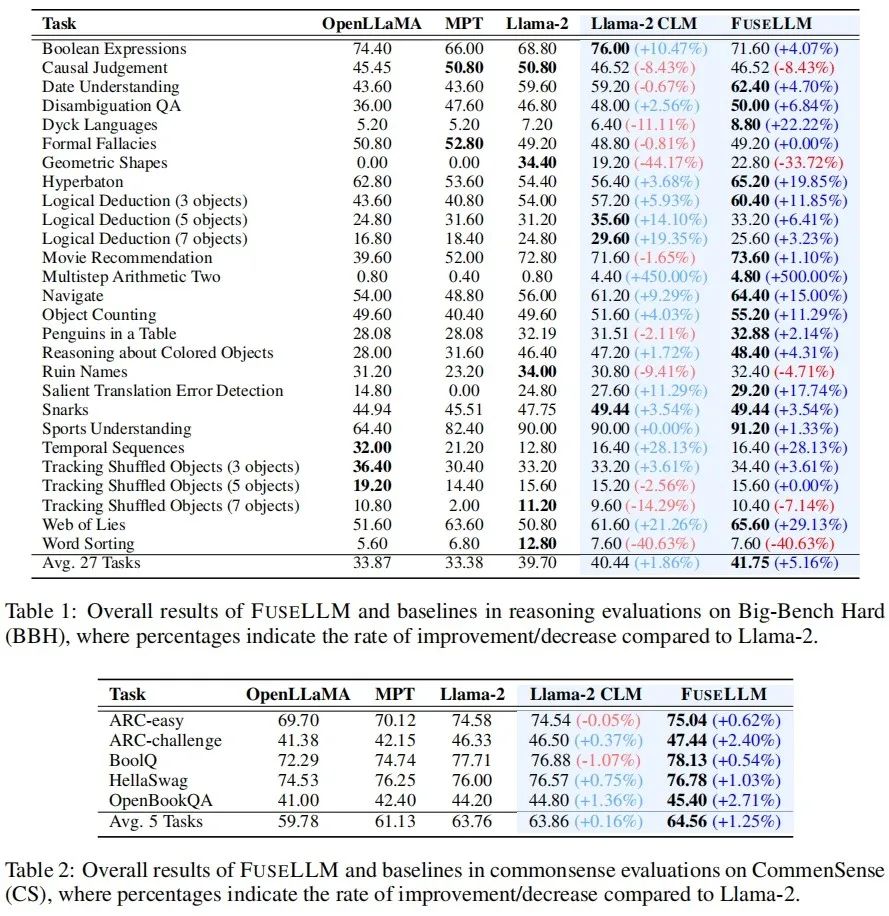

 ## Since FuseLLM only It is necessary to extract the representations of multiple source models for fusion, and then continuously train the target model, so it can also be applied to the fusion of instruction fine-tuning large language models. On the Vicuna Benchmark, which evaluates instruction following ability, FuseLLM also achieved excellent performance, surpassing all source models and CLM.
## Since FuseLLM only It is necessary to extract the representations of multiple source models for fusion, and then continuously train the target model, so it can also be applied to the fusion of instruction fine-tuning large language models. On the Vicuna Benchmark, which evaluates instruction following ability, FuseLLM also achieved excellent performance, surpassing all source models and CLM. 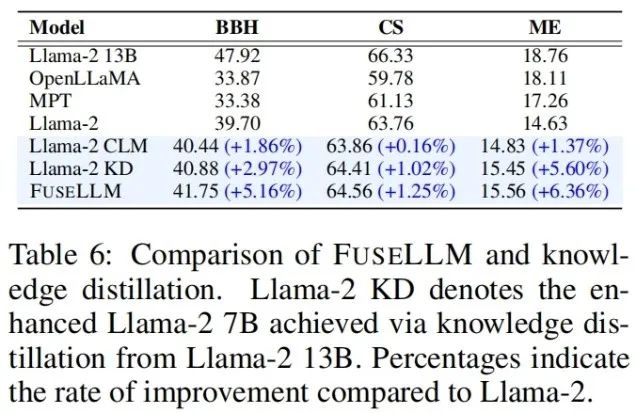 Considering that knowledge distillation is also a method of using representation to improve the performance of large language models, the author compared FuseLLM with Llama-2 KD distilled with Llama-2 13B. Results show that FuseLLM outperforms distillation from a single 13B model by fusing three 7B models with different architectures.
Considering that knowledge distillation is also a method of using representation to improve the performance of large language models, the author compared FuseLLM with Llama-2 KD distilled with Llama-2 13B. Results show that FuseLLM outperforms distillation from a single 13B model by fusing three 7B models with different architectures.  To compare FuseLLM with existing fusion methods (such as model ensemble and weight merging), the authors simulated multiple source models from the same structure base model, but continuously trained on different corpora, and tested the perplexity of various methods on different test benchmarks. It can be seen that although all fusion techniques can combine the advantages of multiple source models, FuseLLM can achieve the lowest average perplexity, indicating that FuseLLM has the potential to combine the collective knowledge of source models more effectively than model ensemble and weight merging methods.
To compare FuseLLM with existing fusion methods (such as model ensemble and weight merging), the authors simulated multiple source models from the same structure base model, but continuously trained on different corpora, and tested the perplexity of various methods on different test benchmarks. It can be seen that although all fusion techniques can combine the advantages of multiple source models, FuseLLM can achieve the lowest average perplexity, indicating that FuseLLM has the potential to combine the collective knowledge of source models more effectively than model ensemble and weight merging methods.
The above is the detailed content of The fusion of multiple heterogeneous large models brings amazing results. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



