

Knowledge graph: the ideal partner for large models

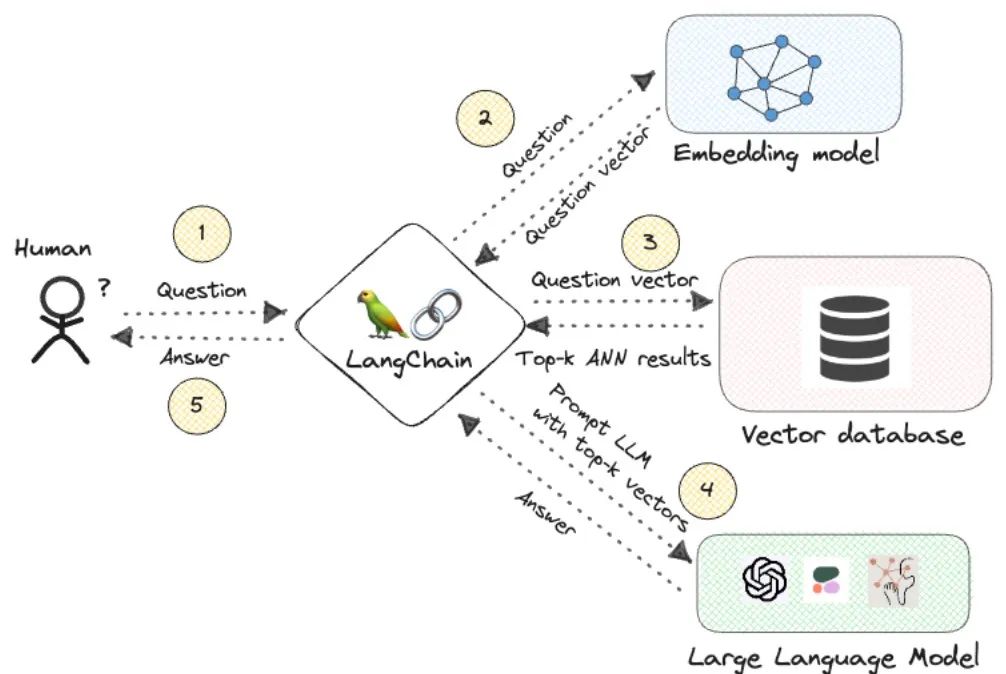
Large-scale language models (LLM) have the ability to generate smooth and coherent text, bringing new prospects to fields such as artificial intelligence dialogue and creative writing. However, LLM also has some key limitations. First, their knowledge is limited to patterns recognized from training data, lacking a true understanding of the world. Second, reasoning skills are limited and cannot make logical inferences or fuse facts from multiple data sources. When faced with more complex and open-ended questions, LLM's answers may become absurd or contradictory, known as "illusions." Therefore, although LLM is very useful in some aspects, it still has certain limitations when dealing with complex problems and real-world situations.
To bridge these gaps, retrieval-augmented generation (RAG) systems have emerged in recent years. The core idea is to provide context to LLM by retrieving relevant knowledge from external sources in order to make more informed decisions. Reaction. Current systems mostly use semantic similarity of vector embeddings to retrieve passages, however, this approach has its own shortcomings, such as lack of true correlation, inability to aggregate facts, and lack of inference chains. The application fields of knowledge graphs can solve these problems. Knowledge graph is a structured representation of real-world entities and relationships. By encoding the interconnections between contextual facts, knowledge graphs overcome the shortcomings of pure vector search, and graph search enables complex multi-level reasoning across multiple information sources.
The combination of vector embedding and knowledge graph can improve the reasoning ability of LLM and enhance its accuracy and interpretability. This partnership perfectly blends surface semantics with structured knowledge and logic, enabling LLM to apply statistical learning and symbolic representation simultaneously.
 Picture
Picture
1. Limitations of vector search
Most RAG systems search through paragraphs in a document collection Vector search to find the context of LLM. There are several key steps in this process.
- #Text encoding: The system uses an embedding model like BERT to encode text from paragraphs in the corpus into vector representations. Each article is compressed into a dense vector to capture the semantics.
- Indexing: These channel vectors are indexed in a high-dimensional vector space to enable fast nearest neighbor searches. Popular methods include Faiss and Pinecone, among others.
- Query encoding: The user’s query statement is also encoded into a vector representation using the same embedding model.
- Similarity search: A nearest neighbor search is run across the indexed paragraphs to find the paragraph closest to the query vector based on a distance metric (such as cosine distance).
- Return paragraph results: Return the most similar paragraph vector, extract the original text to provide context for LLM.
This pipeline has several major limitations:
- The channel vector may not fully capture the semantics of the query Intentional,embeddings cannot represent certain inferential connections and,important context ends up being ignored.
- Compressing an entire paragraph into a single vector will lose nuance, and key relevant details embedded in the sentence will become blurred.
- Matching is done independently for each paragraph, there is no joint analysis across different paragraphs, and there is a lack of connecting facts and arriving at answers that need to be summarized.
- The ranking and matching process is opaque, with no transparency to explain why certain passages are deemed more relevant.
- Only semantic similarity is encoded, not content representing relationships, structures, rules and other different connections between them.
- A single focus on semantic vector similarity leads to a lack of real understanding in retrieval.
#As queries become more complex, these limitations become increasingly apparent in the inability to reason about what is retrieved.
2. Integrate the knowledge graph
The knowledge graph is based on entities and relationships, transmits information through interconnected networks, and improves performance through complex reasoning Search capabilities.
- Explicit facts, facts are captured directly as nodes and edges rather than compressed into opaque vectors, which preserves critical details.
- Context details, entities contain rich attributes, such as descriptions, aliases and metadata that provide key context.
- The network structure expresses the real connections, capture rules, hierarchies, timelines, etc. between relationship modeling entities.
- Multi-level reasoning is based on relationship traversal and joining facts from different sources to derive answers that require reasoning across multiple steps.
- Federated reasoning links to the same real-world objects through entity resolution, allowing for collective analysis.
- Interpretable correlation, graph topology provides a transparency that can explain why certain basedonconnectedfacts are correlated of.
- Personalization, capturing user attributes, context and historical interactions to tailor results.
#The knowledge graph is not just a simple match, but a process of traversing the graph to collect contextual facts related to the query. Interpretable ranking methods leverage the topology of graphs to improve retrieval capabilities by encoding structured facts, relationships, and context, thereby enabling accurate multi-step reasoning. This approach provides greater correlation and explanatory power relative to pure vector searches.
3. Using simple constraints to improve the embedding of knowledge graphs
Embedding knowledge graphs in continuous vector spaces is a current research hotspot. Knowledge graphs use vector embeddings to represent entities and relationships to support mathematical operations. Additionally, additional constraints can further optimize the representation.
- Non-negativity constraints, restricting entity embeddings to positive values between 0 and 1 lead to sparsity, explicitly model their positive properties, and improve Interpretability.
- Implication constraints directly encode logical rules such as symmetry, inversion, and composition into relationship-embedded constraints to enforce these patterns.
- Confidence modeling, soft constraints with slack variables can encode the confidence of logical rules based on evidence.
- Regularization, which imposes a useful inductive bias, only adds a projection step without making the optimization more complex.
- Interpretability, structured constraints provide transparency to the patterns learned by the model, which explains the inference process.
- Accuracy, constraints improve generalization by reducing the hypothesis space to a representation that meets the requirements.
Simple and universal constraints are added to the embedding of the knowledge graph, resulting in a more optimized, easier to interpret and logically compatible representation. Embeddings obtain inductive biases that mimic real-world structures and rules without introducing much additional complexity for more accurate and interpretable reasoning.
4. Integrate multiple reasoning frameworks
Knowledge graph requires reasoning to derive new facts, answer questions, and make predictions. Different technologies have complementary advantages. :
Logical rules express knowledge as logical axioms and ontology, conduct reasonable and complete reasoning through theorem proof, and realize limited uncertainty processing. Graph embedding is an embedded knowledge graph structure used for vector space operations, which can handle uncertainty but lacks expressivity. Neural networks combined with vector lookups are adaptive, but the inference is opaque. Rules can be automatically created through statistical analysis of graph structure and data, but the quality is uncertain. Hybrid pipelines encode explicit constraints through logical rules, embeddings provide vector space operations, and neural networks gain the benefits of fusion through joint training. Use case-based, fuzzy or probabilistic logic methods to increase transparency, express uncertainty and confidence in rules. Extend knowledge by embodying inferred facts and learned rules into graphs, providing a feedback loop.
The key is to identify the types of inference required and map them to the appropriate techniques. A composable pipeline that combines logical forms, vector representations, and neuronal components provides robustness and scalability. interpretive.
4.1 Maintaining information flow for LLM
Retrieving facts in the knowledge graph for LLM introduces information bottlenecks that require design to maintain relevance. Breaking content into small chunks improves isolation but loses surrounding context, which hinders reasoning between chunks. Generating block summaries provides more concise context, with key details condensed to highlight meaning. Attach summaries, titles, tags, etc. as metadata to maintain context about the source content. Rewriting the original query into a more detailed version can better target the retrieval to the needs of the LLM. The traversal function of the knowledge graph maintains the connection between facts and maintains context. Sorting chronologically or by relevance can optimize the information structure of the LLM, and converting implicit knowledge into explicit facts stated for the LLM can make reasoning easier.
The goal is to optimize the relevance, context, structure, and explicit expression of retrieved knowledge to maximize reasoning capabilities. A balance needs to be struck between granularity and cohesion. Knowledge graph relationships help build context for isolated facts.
4.2 Unlocking reasoning capabilities
The combination of knowledge graphs and embedded technology has the advantage of overcoming each other's weaknesses.
Knowledge graph provides a structured expression of entities and relationships. Enhance complex reasoning capabilities through traversal functions and handle multi-level reasoning; embedding encodes information for similarity-based operations in vector space, supports effective approximate search at a certain scale, and surfaces potential patterns. Joint encoding generates embeddings for entities and relationships in knowledge graphs. Graph neural networks operate on graph structures and embedded elements via differentiable message passing.
The knowledge graph first collects structured knowledge, and then embeds search and retrieval focused on related content. Explicit knowledge graph relationships provide interpretability for the reasoning process. Inferred knowledge can be extended to graphs, and GNNs provide learning of continuous representations.
This partnership can be recognized by patterns! The scalability of forces and neural networks enhances the representation of structured knowledge. This is key to the need for statistical learning and symbolic logic to advance linguistic AI.
4.3 Use collaborative filtering to improve search
Collaborative filtering uses the connections between entities to enhance search. The general process is as follows:
- Construct a knowledge graph in which nodes represent entities and edges represent relationships.
- Generate an embedding vector for certain key node attributes (such as title, description, etc.).
- Vector Index - Constructs a vector similarity index for node embeddings.
- Nearest Neighbor Search - For a search query, find nodes with the most similar embeddings.
- Collaborative Adjustment — Based on node connections, similarity scores are propagated and adjusted using algorithms such as PageRank.
- Edge weight - Adjust the weight according to edge type, strength, confidence, etc.
- Score Normalization—Normalizes adjusted scores to maintain relative ranking.
- Results reordered - Initial results reordered based on adjusted collaboration scores.
- User context - further tuned based on user profile, history and preferences.
 Pictures
Pictures
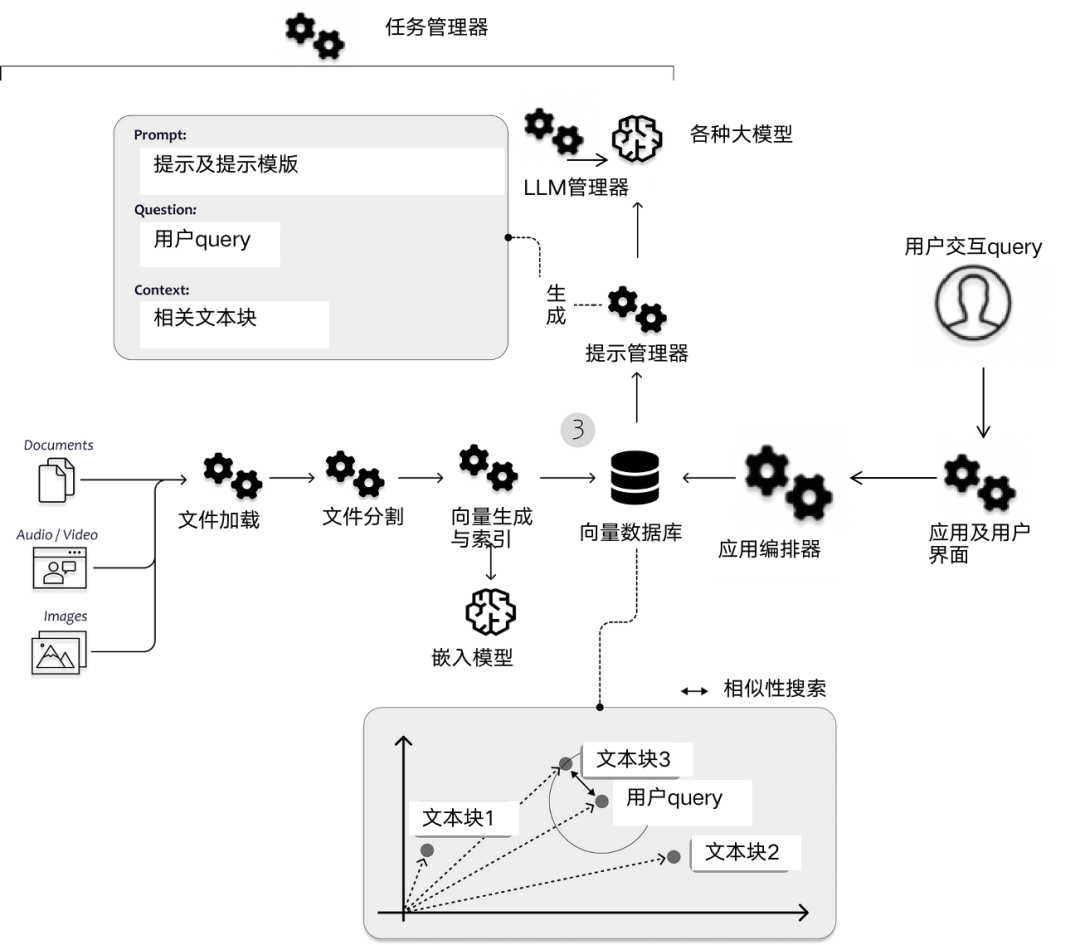
5. Fuel the RAG engine - data flywheel
Build a continuous Improved high-performance retrieval augmentation generation (RAG) systems may require the implementation of a data flywheel. Knowledge graphs unlock new reasoning capabilities for language models by providing structured world knowledge. However, constructing high-quality maps remains challenging. This is where the data flywheel comes in, continuously improving the knowledge graph by analyzing system interactions.
Record all system queries, responses, scores, user actions and other data, provide visibility into how to use the knowledge graph, use data aggregation to surface bad responses, cluster and analyze these responses , to identify patterns that indicate gaps in knowledge. Manually review problematic system responses and trace issues back to missing or incorrect facts in the map. Then, modify the chart directly to add those missing factual data, improve structure, increase clarity, and more. The above steps are completed in a continuous loop, and each iteration further enhances the knowledge graph.
Streaming real-time data sources like news and social media provide a constant flow of new information to keep the knowledge graph current. Using query generation to identify and fill critical knowledge gaps is beyond the scope of what streaming provides. Find holes in the graph, ask questions, retrieve missing facts, and add them. For each cycle, the knowledge graph is gradually enhanced by analyzing usage patterns and fixing data problems. The improved graph enhances the performance of the system.
This flywheel process enables knowledge graphs and language models to co-evolve based on feedback from real-world use. Maps are actively modified to fit the needs of the model.
In short, the data flywheel provides a scaffold for the continuous and automatic improvement of the knowledge graph by analyzing system interactions. This powers the accuracy, relevance, and adaptability of graph-dependent language models.
6. Summary
Artificial intelligence needs to combine external knowledge and reasoning, which is where the knowledge graph comes in. Knowledge graphs provide structured representations of real-world entities and relationships, encoding facts about the world and the connections between them. This allows complex logical reasoning to span multiple steps by traversing those interrelated facts
However, knowledge graphs have their own limitations, such as sparsity and lack of uncertainty Processing, this is where graph embedding helps. By encoding knowledge graph elements in vector space, embeddings allow statistical learning from large corpora to representations of latent patterns, and also enable efficient similarity-based operations.
Neither knowledge graphs nor vector embeddings by themselves are sufficient to form human-like language intelligence, but together they provide an effective combination of structured knowledge representation, logical reasoning and statistical learning. While knowledge graphs cover symbolic logic and relationships above the pattern recognition capabilities of neural networks, technologies like graph neural networks further unify these methods through information transfer graph structures and embeddings. This symbiotic relationship enables the system to utilize both statistical learning and symbolic logic, combining the advantages of neural networks and structured knowledge representation.
There are still challenges in building high-quality knowledge graphs, benchmark testing, noise processing, etc. However, hybrid technologies spanning symbolic and neural networks remain promising. As knowledge graphs and language models continue to develop, their integration will open up new areas of explainable AI.
The above is the detailed content of Knowledge graph: the ideal partner for large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
