

As multimodal large models (LMMs) continue to advance, the need to evaluate the performance of LMMs is also growing. Especially in the Chinese environment, it becomes more important to evaluate the advanced knowledge and reasoning ability of LMM.
In this context, in order to evaluate the expert-level multi-modal understanding capabilities of the basic model in various tasks in Chinese, the M-A-P open source community, Hong Kong University of Science and Technology, University of Waterloo and Zero-One Everything Jointly launched the CMMMU (Chinese Massive Multi-discipline Multimodal Understanding and Reasoning) benchmark. This benchmark aims to provide a comprehensive evaluation platform for large-scale multi-disciplinary multi-modal understanding and reasoning in Chinese. The benchmark allows researchers to test models on a variety of tasks and compare their multimodal understanding capabilities to professional levels. The goal of this joint project is to promote the development of the field of Chinese multimodal understanding and reasoning and provide a standardized reference for related research.
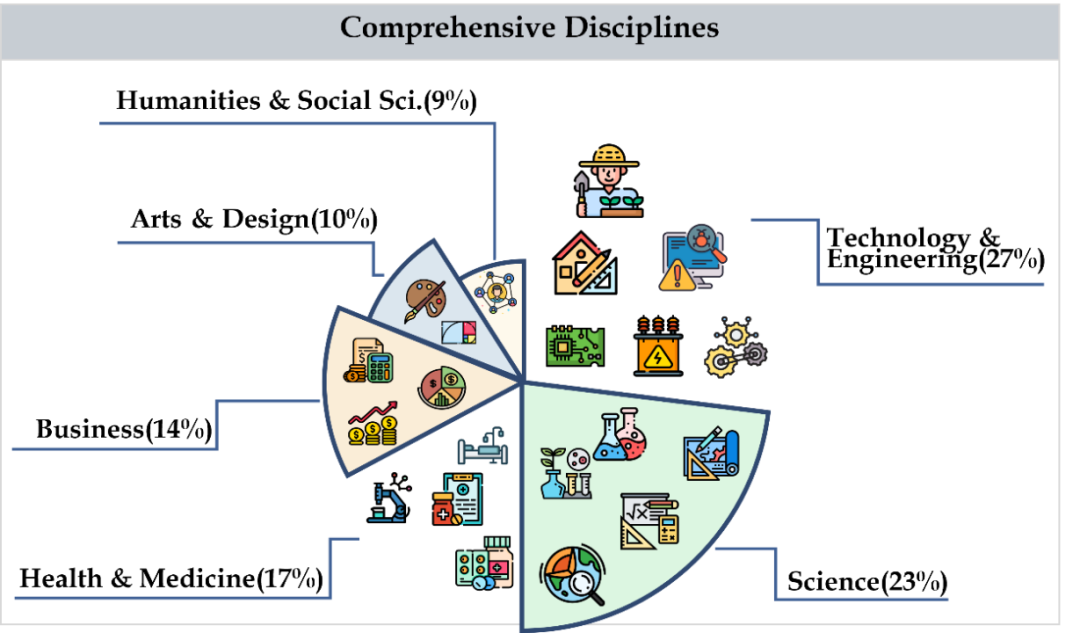
CMMMU covers six major categories of subjects, including arts, business, health and medicine, science, humanities and social sciences, technology and engineering, involving more than 30 sub-field subjects. The figure below shows an example of a question for each sub-field subject. CMMMU is one of the first multi-modal benchmarks in the Chinese context and one of the few multi-modal benchmarks that examines the complex understanding and reasoning capabilities of LMM.

##Data collection
Data collection is divided into three stages. First, the researchers collected question sources for each subject that met copyright licensing requirements, including web pages or books. During this process, they worked hard to avoid duplication of question sources to ensure data diversity and accuracy. Secondly, the researchers forwarded the question sources to crowdsourced annotators for further annotation. All annotators are individuals with a bachelor's degree or higher to ensure they can verify the annotated questions and associated explanations. During the annotation process, researchers require annotators to strictly follow the annotation principles. For example, filter out questions that don't require pictures to answer, filter out questions that use the same images whenever possible, and filter out questions that don't require expert knowledge to answer. Finally, in order to balance the number of questions in each subject in the data set, the researchers specifically supplemented the subjects with fewer questions. Doing so ensures the completeness and representativeness of the data set, allowing subsequent analysis and research to be more accurate and comprehensive.
Dataset Cleaning
In order to further improve the data quality of CMMMU, researchers follow strict data quality control protocol. First, each question is personally verified by at least one of the paper's authors. Secondly, in order to avoid data pollution problems, they also screened out questions that several LLMs could answer without resorting to OCR technology. These measures ensure the reliability and accuracy of CMMMU data.
Dataset Overview
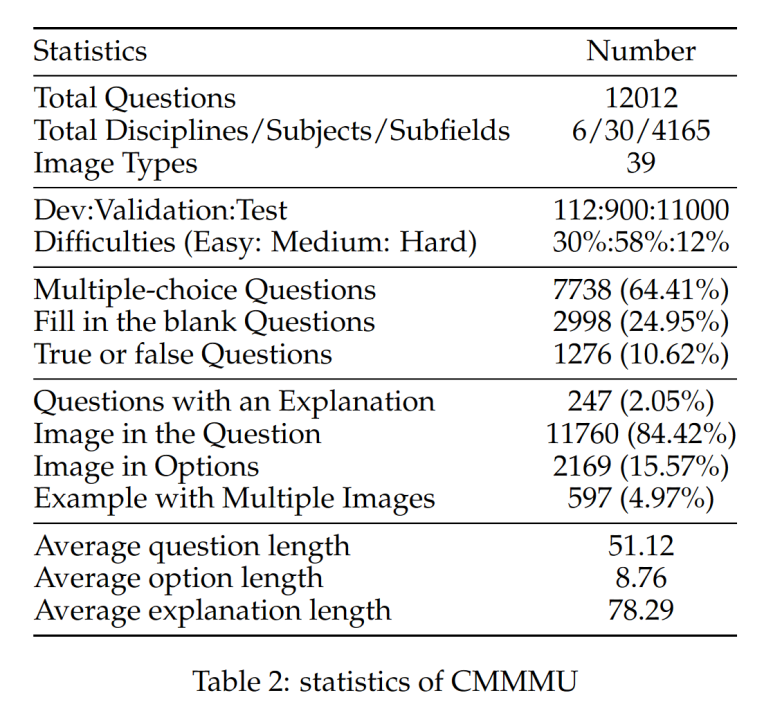
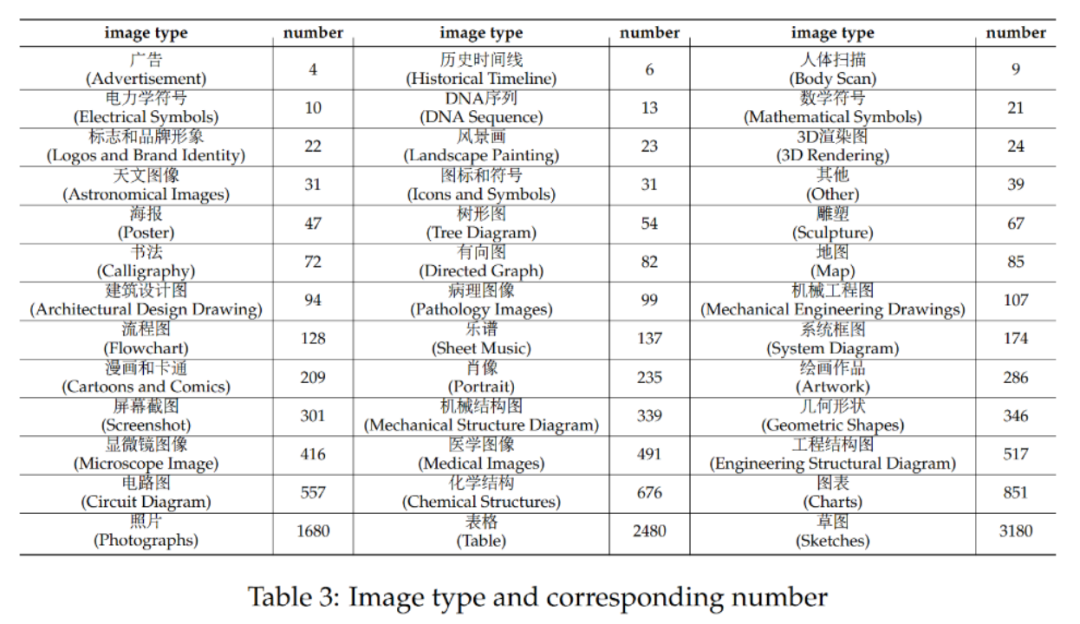
CMMMU has a total of 12K questions, which are divided into few-sample development set, verification set and test set. The few-sample development set contains about 5 questions for each subject, the validation set has 900 questions, and the test set has 11K questions. The questions cover 39 types of pictures, including pathological diagrams, musical notation diagrams, circuit diagrams, chemical structure diagrams, etc. The questions are divided into three difficulty levels: easy (30%), medium (58%), and hard (12%) based on logical difficulty rather than intellectual difficulty. More question statistics can be found in Table 2 and Table 3.
The team tested the performance of a variety of mainstream Chinese and English bilingual LMMs and several LLMs on CMMMU. Both closed source and open source models are included. The evaluation process uses zero-shot settings instead of fine-tuning or few-shot settings to check the raw capabilities of the model. LLM also added experiments in which image OCR result text is used as input. All experiments were performed on an NVIDIA A100 graphics processor.
Main results
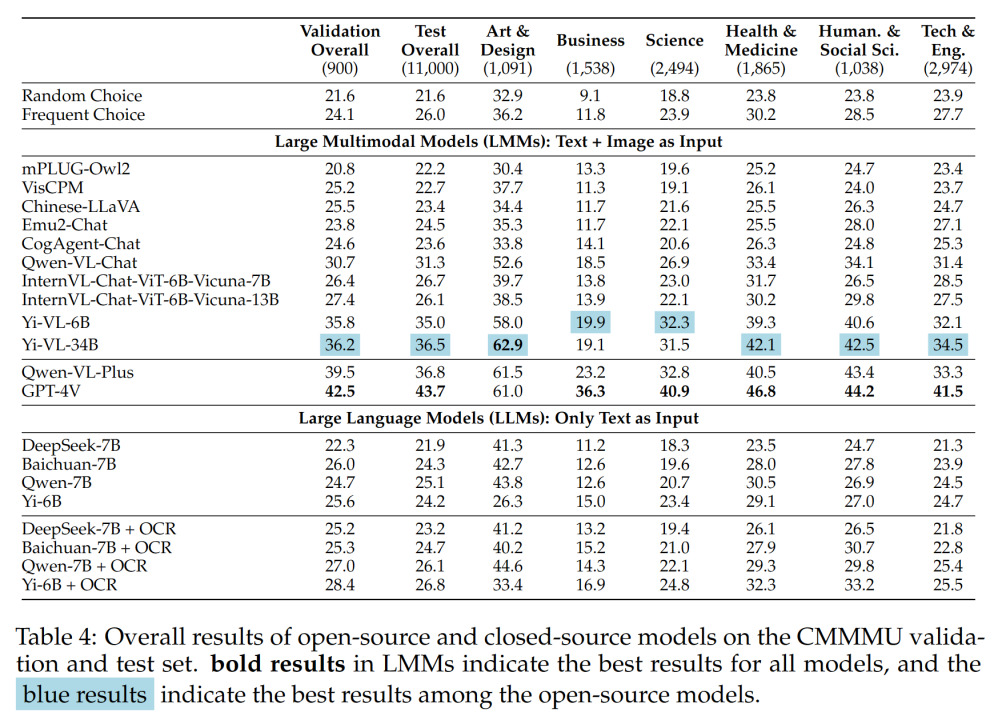
Table 4 shows the experimental results:
Some important findings include:
- CMMMU is more challenging than MMMU, and this is when MMMU has Very challenging premise.
The accuracy of GPT-4V in the Chinese context is only 41.7%, while the accuracy in the English context is 55.7%. This shows that existing cross-language generalization methods are not good enough even for state-of-the-art closed-source LMMs.
- Compared with MMMU, the gap between the domestic representative open source model and GPT-4V is relatively small.
The difference between Qwen-VL-Chat and GPT-4V on MMMU is 13.3%, while the difference between BLIP2-FLAN-T5-XXL and GPT-4V on MMMU is 21.9%. Surprisingly, Yi-VL-34B even narrows the gap between the open source bilingual LMM and GPT-4V on CMMMU to 7.5%, which means that in the Chinese environment, the open source bilingual LMM is equivalent to GPT-4V, which is This is a promising development in the open source community.
# - In the open source community, the game in the pursuit of multimodal artificial general intelligence (AGI) for Chinese experts is just beginning.
The team pointed out that except for the recently released Qwen-VL-Chat, Yi-VL-6B and Yi-VL-34B, all bilingual LMMs from the open source community can only Achieve accuracy comparable to CMMMU's frequent choice.
Analysis of different question difficulty and question types
- Different question types
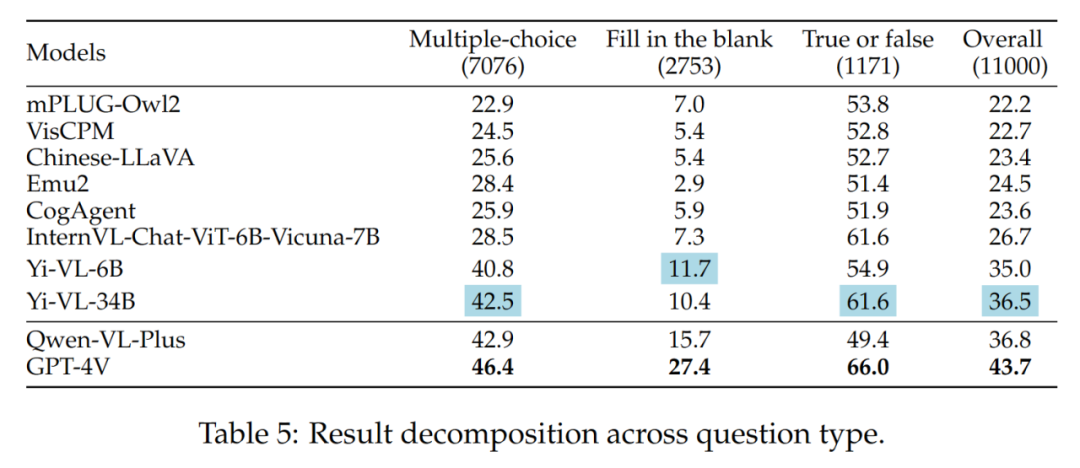
The difference between Yi-VL series, Qwen-VL-Plus and GPT-4V is mainly due to their different abilities to answer multiple-choice questions.
The results of different question types are shown in Table 5:
- Different questions Difficulty
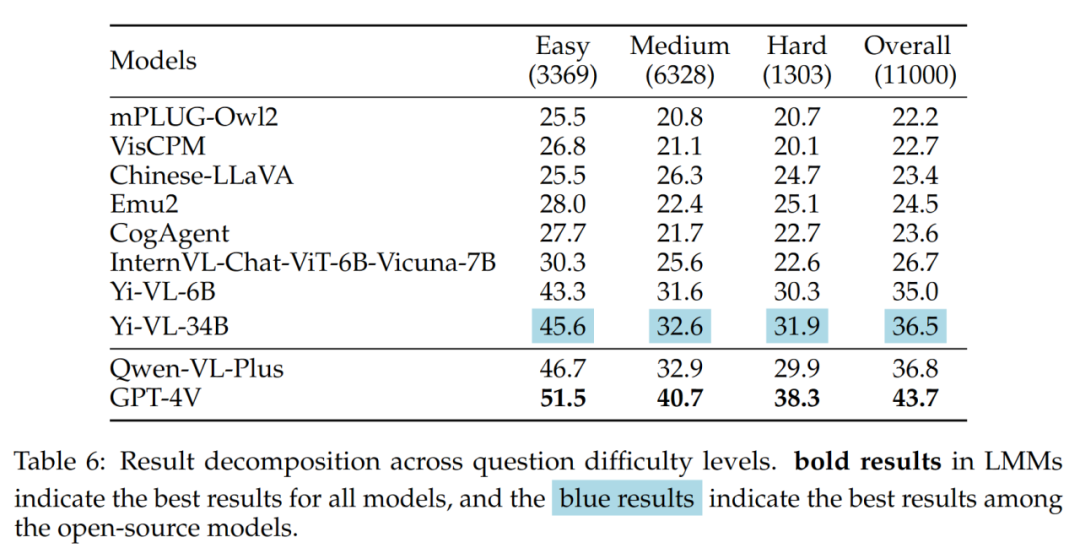
What is worth noting in the results is that the best open source LMM (i.e. Yi-VL-34B) and GPT-4V exist when facing medium and hard problems A larger gap. This is further strong evidence that the key difference between open source LMMs and GPT-4V is the ability to compute and reason under complex conditions.
The results of different question difficulties are shown in Table 6:
Error analysis
Researchers carefully analyzed the wrong answers of GPT-4V. As shown in the figure below, the main types of errors are perception errors, lack of knowledge, reasoning errors, refusal to answer, and annotation errors. Analyzing these error types is key to understanding the capabilities and limitations of current LMMs and can also guide future design and training model improvements.
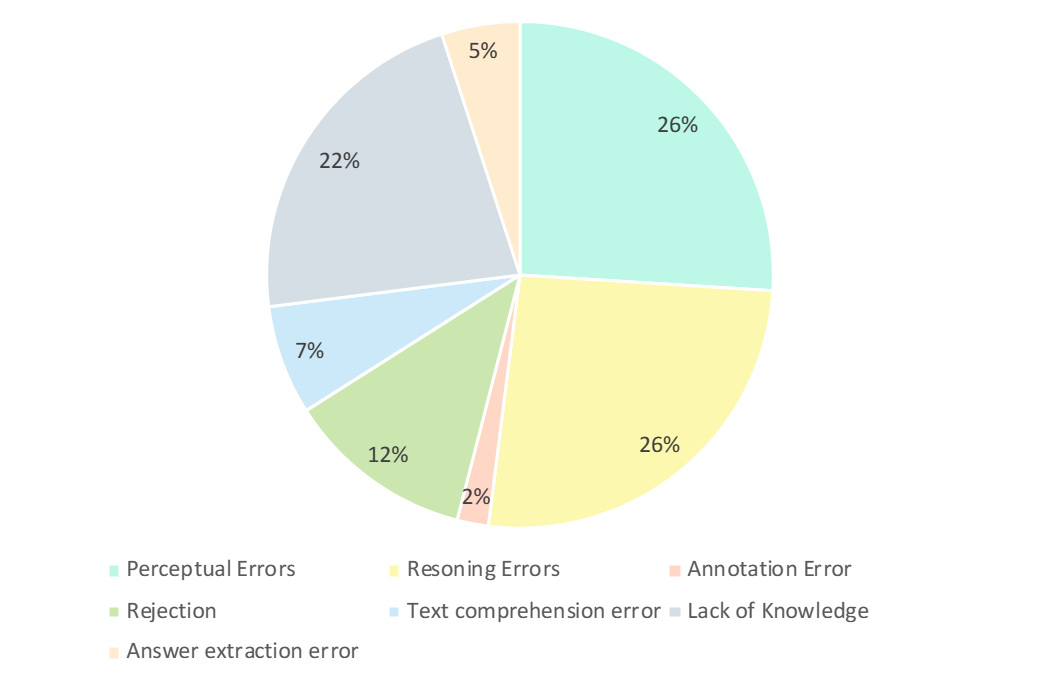
- Perceived error (26%): Perceived error is an example of an error generated by GPT-4V One of the main reasons. On the one hand, when the model cannot understand the image, it introduces a bias to the underlying perception of the image, leading to incorrect responses. On the other hand, when a model encounters ambiguities in domain-specific knowledge, implicit meanings, or unclear formulas, it often exhibits domain-specific perceptual errors. In this case, GPT-4V tends to rely more on textual information-based answers (i.e. questions and options), prioritizing textual information over visual input, resulting in a bias in understanding multi-modal data.
- Inference Errors (26%) : Inference errors are another major factor in GPT-4V producing erroneous examples. Even when models correctly perceive the meaning conveyed by images and text, errors can still occur during reasoning when solving problems that require complex logical and mathematical reasoning. Typically, this error is caused by the model's weak logical and mathematical reasoning capabilities.
- Lack of knowledge (22%): Lack of expertise is also one of the reasons for incorrect answers to GPT-4V. Since CMMMU is a benchmark for evaluating LMM expert AGI, expert-level knowledge in different disciplines and subfields is required. Therefore, injecting expert-level knowledge into LMM is also one of the directions that can be worked on.
- Refusal to answer (12%): It is also common for models to refuse to answer. Through analysis, they pointed out several reasons why the model refused to answer the question: (1) The model failed to perceive information from the image; (2) It was a question involving religious issues or personal real-life information, and the model would actively avoid it; (3) When questions involve gender and subjective factors, the model avoids providing direct answers.
- Its errors: The remaining errors include text comprehension errors (7%), annotation errors (2%) and answer extraction errors (5%). These errors are caused by a variety of factors such as complex structure tracking capabilities, complex text logic understanding, limitations in response generation, errors in data annotation, and problems encountered in answer matching extraction.
The CMMMU benchmark marks significant progress in the development of advanced general artificial intelligence (AGI). CMMMU is designed to rigorously evaluate the latest large multimodal models (LMMs) and test basic perceptual skills, complex logical reasoning, and deep expertise in a specific domain. This study pointed out the differences by comparing the reasoning ability of LMM in Chinese and English bilingual contexts. This detailed assessment is critical in determining how far a model falls short of the proficiency of experienced professionals in each field.
The above is the detailed content of The latest benchmark CMMMU suitable for Chinese LMM physique: includes more than 30 subdivisions and 12K expert-level questions. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



