
 Technology peripherals
AI
Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3
Technology peripherals
AI
Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3
Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3

Dynamic visual word segmentation unified graphic and text representation, Kuaishou and Peking University cooperated to propose the base model LaVIT to brush the list of multi-modal understanding and generation tasks.
Current large-scale language models such as GPT, LLaMA, etc. have made significant progress in the field of natural language processing, and they are able to understand and generate complex text content. However, have we considered transferring this powerful understanding and generation ability to multimodal data? This will allow us to easily make sense of massive amounts of images and videos and create richly illustrated content. To realize this vision, Kuaishou and Peking University recently collaborated to develop a new multi-modal large model called LaVIT. LaVIT is gradually turning this idea into reality, and we look forward to its further development.

Paper title: Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Paper address : https://arxiv.org/abs/2309.04669
Code model address: https://github.com/jy0205/LaVIT
Model Overview
LaVIT is a new general multi-modal base model, similar to a language model, that can understand and generate visual content. LaVIT's training paradigm draws on the successful experience of large language models and uses an autoregressive approach to predict the next image or text token. After training, LaVIT can serve as a multimodal universal interface that can perform multimodal understanding and generation tasks without further fine-tuning. For example, LaVIT has the following capabilities:
LaVIT is an advanced image generation model that can generate high-quality, multiple aspect ratios, and high-aesthetic images based on text prompts. LaVIT's image generation capabilities compare favorably with state-of-the-art image generation models such as Parti, SDXL, and DALLE-3. It can effectively achieve high-quality text-to-image generation, providing users with more choices and a better visual experience.

Image generation based on multi-modal prompts: Since in LaVIT, images and text are uniformly represented as discretized tokens, it can accept multiple modalities Combinations (e.g. text, image text, image image) serve as prompts and generate corresponding images without any fine-tuning.

Understand image content and answer questions: Given an input image, LaVIT is able to read the image content and understand its semantics. For example, the model can provide captions for input images and answer corresponding questions.

Method Overview
The model structure of LaVIT is shown in the figure below. Its entire optimization process includes two stages:
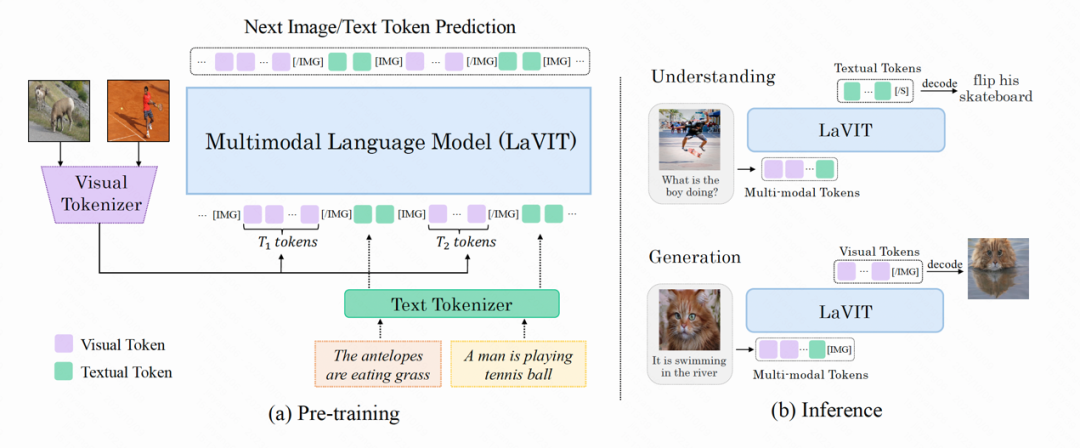
Figure: The overall architecture of the LaVIT model
Phase 1: Dynamic visual tokenizer
To be able to understand and generate visual content like natural language, LaVIT introduces a well-designed visual tokenizer to convert visual content (continuous signals) into text-like token sequences, just like LLM Can understand foreign languages as well. The author believes that in order to achieve unified vision and language modeling, the visual tokenizer (Tokenizer) should have the following two characteristics:
Discretization: Visual token should be represented as a discretized form like text. This uses a unified representation form for the two modalities, which is conducive to LaVIT using the same classification loss for multi-modal modeling optimization under a unified autoregressive generative training framework.
Dynamicization: Unlike text tokens, image patches have significant interdependencies, which makes it possible to distinguish them from other Inferring one image patch from another is relatively simple. Therefore, this dependence reduces the effectiveness of the original LLM's next-token prediction optimization goal. LaVIT proposes to reduce the redundancy between visual patches by using token merging, which encodes a dynamic number of visual tokens based on the different semantic complexity of different images. In this way, for images of different complexity, the use of dynamic token encoding further improves the efficiency of pre-training and avoids redundant token calculations.
The following figure is the visual word segmenter structure proposed by LaVIT:
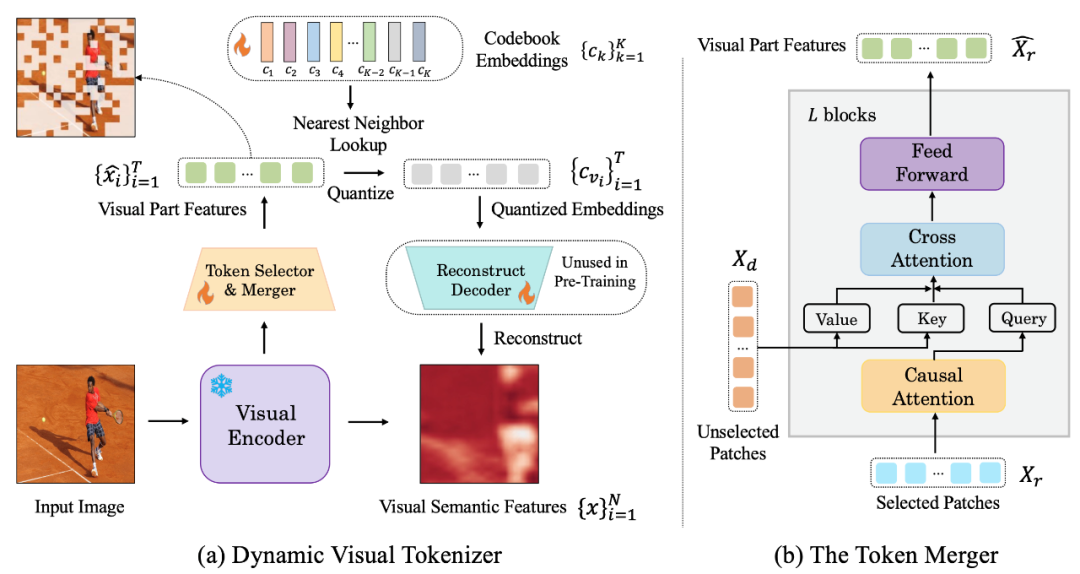
#Рис.: (a) Динамический визуальный генератор токенов (b) Комбинатор токенов
Динамическая визуальная сегментация слов Процессор включает в себя селектор токенов и объединитель токенов. Как показано на рисунке, селектор токенов используется для выбора наиболее информативных блоков изображений, в то время как слияние токенов сжимает информацию этих неинформативных визуальных блоков в оставшиеся токены, чтобы добиться объединения избыточных токенов. Весь динамический визуальный сегментатор слов обучается путем максимизации семантической реконструкции входного изображения.
Селектор токеновСелектор токенов получает на вход N функций уровня блока изображения, и его цель — оценить важность каждого блока изображения и выбрать блок с максимальное количество информации для полного представления семантики всего изображения. Для достижения этой цели для прогнозирования распределения π используется легкий модуль, состоящий из нескольких слоев MLP. Путем выборки из распределения π генерируется двоичная маска решения, которая указывает, следует ли сохранять соответствующий патч изображения.
Объединитель токеновОбъединитель токенов делит N блоков изображения на две группы: сохраняет X_r и отбрасывает X_d в соответствии с сгенерированной маской решения. В отличие от прямого отбрасывания X_d, объединитель токенов может в максимальной степени сохранить подробную семантику входного изображения. Объединитель токенов состоит из L сложенных друг на друга блоков, каждый из которых включает в себя причинный уровень самообслуживания, уровень перекрестного внимания и уровень прямой связи. На уровне причинного самообслуживания каждый токен в X_r обращает внимание только на свой предыдущий токен, чтобы обеспечить согласованность с формой текстового токена в LLM. Эта стратегия работает лучше по сравнению с двунаправленным вниманием к себе. Уровень перекрестного внимания принимает сохраненный токен X_r в качестве запроса и объединяет токены в X_d на основе их семантического сходства.
Фаза 2: унифицированное генеративное предварительное обучениеВизуальный токен, обрабатываемый визуальным токенизатором, соединяется с текстовым токеном для формирования мультимодальной последовательности при входе в обучение . Чтобы различать две модальности, автор вставляет в начало и конец последовательности токенов изображения специальные токены: [IMG] и [/IMG], которые используются для обозначения начала и конца визуального контента. Чтобы иметь возможность генерировать текст и изображения, LaVIT использует две формы связи изображения с текстом: [изображение, текст] и [текст; изображение].
Для этих мультимодальных входных последовательностей LaVIT использует единый авторегрессионный подход, чтобы напрямую максимизировать вероятность каждой мультимодальной последовательности для предварительного обучения. Эта полная унификация пространства представления и методов обучения помогает LLM лучше изучать мультимодальное взаимодействие и согласованность. После завершения предварительного обучения LaVIT обладает способностью воспринимать изображения, а также понимать и генерировать изображения, такие как текст.
ЭкспериментМультимодальное понимание с нулевого выстрела
LaVIT в создании субтитров к изображениям (NoCaps, Flickr30k) и визуальных ответах на вопросы Он достиг лучших результатов в решении мультимодальных задач понимания, таких как (VQAv2, OKVQA, GQA, VizWiz). 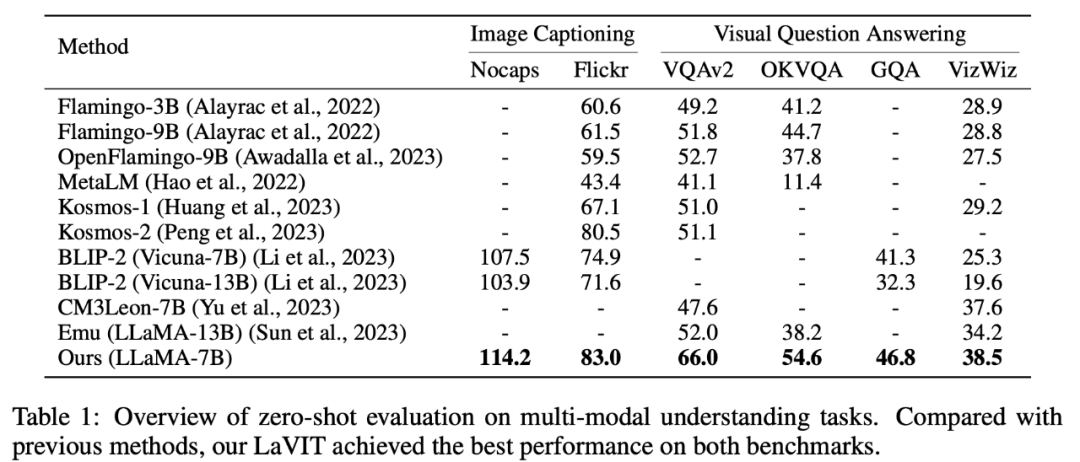
##Таблица 1 Оценка мультимодальных задач понимания с нулевыми выборками
Множественный ноль образцы Генерация модальности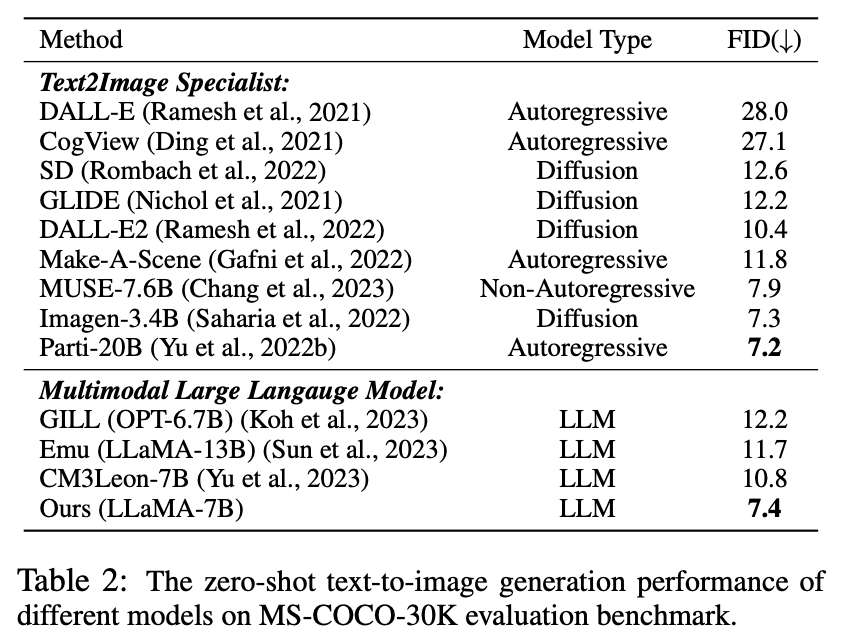
Таблица 2. Производительность преобразования текста с нулевой выборкой в изображение для различных моделей
Как видно из таблицы Оказывается, LaVIT превосходит все другие модели мультимодального языка. По сравнению с Emu, LaVIT обеспечивает дальнейшие улучшения на небольших моделях LLM, демонстрируя превосходные возможности визуально-вербального выравнивания. Кроме того, LaVIT достигает производительности, сравнимой с производительностью современного эксперта по преобразованию текста в изображение Parti, используя при этом меньше обучающих данных.
LaVIT может легко принимать несколько модальных комбинаций в качестве подсказок и генерировать соответствующее изображение без какой-либо тонкой настройки. LaVIT генерирует изображения, которые точно отражают стиль и семантику данного мультимодального сигнала. И он может изменять исходное входное изображение с помощью мультимодальных сигналов ввода. Традиционные модели генерации изображений, такие как Stable Diffusion, не могут обеспечить эту возможность без дополнительных точно настроенных последующих данных.
Пример результатов генерации мультимодального изображения###############Качественный анализ#### ##
Как показано на рисунке ниже, динамический токенизатор LaVIT может динамически выбирать наиболее информативные блоки изображения на основе содержимого изображения, а изученный код может производить визуальное кодирование с семантикой высокого уровня.

Визуализация динамического визуального токенизатора (слева) и изученной кодовой книги (справа)
Резюме
Появление LaVIT обеспечивает инновационную парадигму для обработки мультимодальных задач.Используя динамический визуальный сегментатор слов для представления видения и языка в едином представлении дискретных токенов, наследование Успешная авторегрессия парадигма генеративного обучения для LLM. Оптимизируясь под цель унифицированного создания, LaVIT может обрабатывать изображения как иностранный язык, понимая и генерируя их как текст. Успех этого метода дает новое вдохновение для направления развития будущих мультимодальных исследований, используя мощные логические возможности LLM, чтобы открыть новые возможности для более разумного и всестороннего мультимодального понимания и создания.
The above is the detailed content of Kuaishou and Beida multi-modal large models: images are foreign languages, comparable to the breakthrough of DALLE-3. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Conference Introduction With the rapid development of science and technology, artificial intelligence has become an important force in promoting social progress. In this era, we are fortunate to witness and participate in the innovation and application of Distributed Artificial Intelligence (DAI). Distributed artificial intelligence is an important branch of the field of artificial intelligence, which has attracted more and more attention in recent years. Agents based on large language models (LLM) have suddenly emerged. By combining the powerful language understanding and generation capabilities of large models, they have shown great potential in natural language interaction, knowledge reasoning, task planning, etc. AIAgent is taking over the big language model and has become a hot topic in the current AI circle. Au
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
