

Flume vs. Kafka: Which tool is better for handling your data flows?


Flume vs Kafka: Which tool is better for your data stream processing?
Overview
Flume and Kafka are both popular data stream processing tools for collecting, aggregating and transmitting large amounts of real-time data. Both have the characteristics of high throughput, low latency, and reliability, but they have some differences in functionality, architecture, and applicable scenarios.
Flume
Flume is a distributed, reliable and highly available data collection, aggregation and transmission system. It can collect data from various sources and then store it in HDFS, HBase or in other storage systems. Flume is composed of multiple components, including:
- Agent: The Flume agent is responsible for collecting data from data sources.
- Channel: The Flume channel is responsible for storing and buffering data.
- Sink: Flume sink is responsible for writing data to the storage system.
Advantages of Flume include:
- Easy to use: Flume has a user-friendly interface and simple configuration, making it easy to install and use.
- High throughput: Flume can handle large amounts of data, making it suitable for big data processing scenarios.
- Reliability: Flume has a reliable data transmission mechanism to ensure that data will not be lost.
Disadvantages of Flume include:
- Low latency: Flume has a high latency and is not suitable for scenarios that require real-time processing of data.
- Scalability: Flume has limited scalability and is not suitable for scenarios that require processing large amounts of data.
Kafka
Kafka is a distributed, scalable and fault-tolerant messaging system that can store and process large amounts of real-time data. Kafka is composed of multiple components, including:
- Broker: The Kafka broker is responsible for storing and managing data.
- Topic: A Kafka topic is a logical data partition, which can contain multiple partitions.
- Partition: Kafka partition is a physical data storage unit that can store a certain amount of data.
- Consumer: The Kafka consumer is responsible for consuming data from Kafka topics.
The advantages of Kafka include:
- High throughput: Kafka can handle large amounts of data, making it suitable for big data processing scenarios.
- Low latency: Kafka has low latency, making it suitable for scenarios that require real-time processing of data.
- Scalability: Kafka has good scalability, allowing it to be easily expanded to handle more data.
The disadvantages of Kafka include:
- Complexity: The configuration and management of Kafka is relatively complex and requires certain technical experience.
- Reliability: Kafka’s data storage mechanism is not reliable and data may be lost.
Applicable scenarios
Both Flume and Kafka are suitable for big data processing scenarios, but there are differences in their specific applicable scenarios.
Flume is suitable for the following scenarios:
- Need to collect and aggregate data from different sources.
- Need to store data in HDFS, HBase or other storage systems.
- Requires simple processing and conversion of data.
Kafka is suitable for the following scenarios:
- Need to process a large amount of real-time data.
- Requires complex processing and analysis of data.
- The data needs to be stored in a distributed file system.
Code Example
Flume
# 创建一个Flume代理 agent1.sources = r1 agent1.sinks = hdfs agent1.channels = c1 # 配置数据源 r1.type = exec r1.command = tail -F /var/log/messages # 配置数据通道 c1.type = memory c1.capacity = 1000 c1.transactionCapacity = 100 # 配置数据汇 hdfs.type = hdfs hdfs.hdfsUrl = hdfs://localhost:9000 hdfs.fileName = /flume/logs hdfs.rollInterval = 3600 hdfs.rollSize = 10485760
Kafka
# 创建一个Kafka主题 kafka-topics --create --topic my-topic --partitions 3 --replication-factor 2 # 启动一个Kafka代理 kafka-server-start config/server.properties # 启动一个Kafka生产者 kafka-console-producer --topic my-topic # 启动一个Kafka消费者 kafka-console-consumer --topic my-topic --from-beginning
Conclusion
Flume and Kafka are both popular data stream processing Tools have different functions, architectures and applicable scenarios. When choosing, you need to evaluate your specific needs.
The above is the detailed content of Flume vs. Kafka: Which tool is better for handling your data flows?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
With the development of the Internet and technology, digital investment has become a topic of increasing concern. Many investors continue to explore and study investment strategies, hoping to obtain a higher return on investment. In stock trading, real-time stock analysis is very important for decision-making, and the use of Kafka real-time message queue and PHP technology is an efficient and practical means. 1. Introduction to Kafka Kafka is a high-throughput distributed publish and subscribe messaging system developed by LinkedIn. The main features of Kafka are
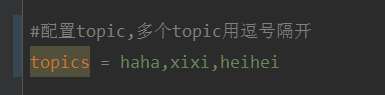 How to dynamically specify multiple topics with @KafkaListener in springboot+kafka
May 20, 2023 pm 08:58 PM
How to dynamically specify multiple topics with @KafkaListener in springboot+kafka
May 20, 2023 pm 08:58 PM
Explain that this project is a springboot+kafak integration project, so it uses the kafak consumption annotation @KafkaListener in springboot. First, configure multiple topics separated by commas in application.properties. Method: Use Spring’s SpEl expression to configure topics as: @KafkaListener(topics="#{’${topics}’.split(’,’)}") to run the program. The console printing effect is as follows
 How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to use React and Apache Kafka to build real-time data processing applications Introduction: With the rise of big data and real-time data processing, building real-time data processing applications has become the pursuit of many developers. The combination of React, a popular front-end framework, and Apache Kafka, a high-performance distributed messaging system, can help us build real-time data processing applications. This article will introduce how to use React and Apache Kafka to build real-time data processing applications, and
 Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five options for Kafka visualization tools ApacheKafka is a distributed stream processing platform capable of processing large amounts of real-time data. It is widely used to build real-time data pipelines, message queues, and event-driven applications. Kafka's visualization tools can help users monitor and manage Kafka clusters and better understand Kafka data flows. The following is an introduction to five popular Kafka visualization tools: ConfluentControlCenterConfluent
 Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
How to choose the right Kafka visualization tool? Comparative analysis of five tools Introduction: Kafka is a high-performance, high-throughput distributed message queue system that is widely used in the field of big data. With the popularity of Kafka, more and more enterprises and developers need a visual tool to easily monitor and manage Kafka clusters. This article will introduce five commonly used Kafka visualization tools and compare their features and functions to help readers choose the tool that suits their needs. 1. KafkaManager
 Sample code for springboot project to configure multiple kafka
May 14, 2023 pm 12:28 PM
Sample code for springboot project to configure multiple kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Configuration file related information kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#The number of threads that can be consumed concurrently (usually consistent with the number of partitions )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 The practice of go-zero and Kafka+Avro: building a high-performance interactive data processing system
Jun 23, 2023 am 09:04 AM
The practice of go-zero and Kafka+Avro: building a high-performance interactive data processing system
Jun 23, 2023 am 09:04 AM
In recent years, with the rise of big data and active open source communities, more and more enterprises have begun to look for high-performance interactive data processing systems to meet the growing data needs. In this wave of technology upgrades, go-zero and Kafka+Avro are being paid attention to and adopted by more and more enterprises. go-zero is a microservice framework developed based on the Golang language. It has the characteristics of high performance, ease of use, easy expansion, and easy maintenance. It is designed to help enterprises quickly build efficient microservice application systems. its rapid growth
 How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
To install ApacheKafka on RockyLinux, you can follow the following steps: Update system: First, make sure your RockyLinux system is up to date, execute the following command to update the system package: sudoyumupdate Install Java: ApacheKafka depends on Java, so you need to install JavaDevelopmentKit (JDK) first ). OpenJDK can be installed through the following command: sudoyuminstalljava-1.8.0-openjdk-devel Download and decompress: Visit the ApacheKafka official website () to download the latest binary package. Choose a stable version
