
 Technology peripherals
AI
Decision-making collaboration between humans and AI: formulation, explanation and evaluation of decision-making problems
Technology peripherals
AI
Decision-making collaboration between humans and AI: formulation, explanation and evaluation of decision-making problems
Decision-making collaboration between humans and AI: formulation, explanation and evaluation of decision-making problems

In fields such as artificial intelligence and data visualization, how to use information display to assist humans in making better decisions is an important research goal. However, there is currently no clear consensus on the definition of decision problems and the design of experiments on how to assess human decision-making performance. A recent paper proposes a definition of a decision problem based on statistical decision theory and information economics and provides a framework for assessing the loss of human decision-making performance. This article will interpret the paper and explore its implications for advancing research on decision-making.
Three American experts in the paper "Decision Theoretic Foundations for Experiments Evaluating Human Decisions" provide information interfaces to aid decision-making on human-centered artificial intelligence (HCAI), visualization and Research in related fields achieves common goals. These experts argue that visualization researchers emphasize decision-making assistance as an important goal of data visualization. At the same time, in human-centered artificial intelligence, empirical research on human decision-making behavior is also widely regarded as "evaluating the effectiveness of artificial intelligence technology in assisting decision-making and developing a basic understanding of how people interact with artificial intelligence to make decisions" ” necessary content. The goals of these studies are to improve the accuracy and efficiency of decision-making, ensure good interaction between artificial intelligence technology and human decision-makers, and provide people with better decision-making support.
They believe that by studying the information display of human decision-making, a minimal set of theoretical commitments can be clearly defined, thereby providing the possibility to determine normative behavior for the task. Fortunately, existing statistical decision theory and expected utility theory can address this challenge and provide a rigorously derived and widely applicable framework for studying decision-making. In addition, the development of information economics also provides solutions for the formalization of information structures for decision-making problems, which may involve how to design visualization and interpretation options for model predictions.
They synthesize a broadly applicable definition of well-defined decision problems from statistical decision theory and information economics, and inspire this approach from data-driven interfaces in HCAI and related Value in decision-making research. Their first contribution was to establish and motivate the minimal set of components that must be defined for a decision problem to identify optimal decisions and thereby identify biases in human decision-making. Using the concept of rational Bayesian agents, they show that performance losses can only be taken into account when research participants are theoretically able to identify normative decisions from the information they are provided with. They found that in a sample of 46 existing studies, 35 studies used predictive displays to draw conclusions about human decision-making deficits, but only 6 of these (17%) were explicit study tasks because participants were given enough information that, at least in principle, can determine the best decision. They use examples to illustrate the epistemological risks of these conclusions and provide suggestions for experimenters to improve the interpretability of their findings.
Paper author background
The title of this paper is "Decision Theoretic Foundations for Experiments Evaluating Human Decisions", written by Jessica Hullman, Alex Kale , Jason Hartline, co-authored by three computer scientists from Northwestern University, published on arXiv on January 25, 2024 (paper address: https://arxiv.org/abs/2401.15106). These three authors are well-known scholars in the fields of artificial intelligence, data visualization, human-computer interaction, etc. Their research results have been published in top academic conferences and journals, such as ACM CHI, ACM CSCW, IEEE VIS, ACM EC, etc. Their research interests mainly focus on how to use artificial intelligence and data visualization to help humans understand and make decisions on complex uncertainty issues, such as risk assessment, prediction, recommendation, etc.
Main contributions of the paper
The definition of a general decision-making problem is given, including action space, state space, scoring rules, and prior beliefs. , data generation models, and signaling strategies, and explains how to use these elements to determine optimal actions and expected utility.
Propose a framework for evaluating human decision-making performance losses, including four potential sources of losses, including prior loss, reception loss, update loss and optimization loss, and explore how to use experimental design and results to estimate and analyze these losses.
In recent years, researchers have coded and evaluated AI-assisted decision-making and found that only a small number of studies (about 17%) provided enough information to enable participants to determine Normative decision-making. Instead, most studies (approximately 83%) suffer from unclear and incomplete decision-making problems, which leads to unreliable conclusions about human decision-making biases and flaws.
Theoretical basis and method
The theoretical basis of this paper mainly comes from statistical decision theory and information economics. Statistical decision theory studies methods of making optimal choices under uncertainty, focusing on the relationship between decision-makers' preferences, beliefs, and actions, and how to use data and information to update beliefs and select actions. Information economics studies the impact of information on economic behavior and results, focusing on the production, dissemination and consumption mechanisms of information, as well as the impact of asymmetric, incomplete and unreliable information on the market and society. These two disciplines provide an important theoretical foundation for the paper and help us deeply understand the role and impact of decision-making and information in the economy.
The method of this paper is mainly based on Bayesian theory and expected utility theory. Bayesian theory is a probability theory used to describe and reason about uncertainty, focusing on calculating posterior beliefs based on prior beliefs and observational data, that is, the probability of a certain hypothesis or event occurring under given data conditions. Expected utility theory is a theory for evaluating risky decisions that focuses on how to calculate expected utility, a weighted average of the utility produced in different states, based on utility functions and probability distributions. This approach combines Bayesian reasoning and utility assessment to provide decision makers with optimal decisions in the face of uncertainty.
Definition of Decision Problem
They define a decision problem and the corresponding optimal behavior criterion to determine performance relative to that criterion loss. Their definition aims at the controlled evaluation of human behavior, that is, the study of normative decision-making. This type of evaluative research requires the ability to determine basic facts about whatever state the research participants are being asked about. Behavioral data (which can be generated by humans or simulations) are collected under controlled conditions with the goal of understanding the behavior elicited by information provision. Such studies are often used to describe the quality of human performance in certain situations (e.g., the extent to which people make decisions based on displays in strategic contexts) and to rank different assistive elements according to human performance (e.g., different visualizations or artificial intelligence). Intelligent explanation strategies), or testing hypotheses about how humans make decisions or what will help them do better (e.g., cognitive forcing capabilities will improve AI-assisted decision-making).
Calculation of optimal actions and expected utility
Given the decision problem defined above, they do this by assuming that the agent is under uncertainty in the outcome What does it mean to have consistent preferences and make the best decision between actions under the circumstances, to compute normative ("optimal") decisions. They can therefore interpret the performance of experimental participants as an attempt to meet this criterion and identify sources of error (loss) in performance.
To do this, they will first assume that the agent's preferences can be summarized by a scoring rule. Assume that he will choose the action that maximizes his expected utility (score):
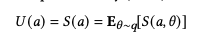 Picture
Picture
describes the subject's belief distribution, that is, the probability distribution of the subject's belief in the state of the world. We can define the optimal action as the action that maximizes the agent's expected utility:
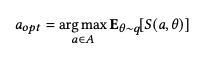 Picture
Picture
Specifically, To compute the optimal decision for a decision task, they first define the agent in π: Pr(θ) or p(θ) as we described above. Whenever a signaling strategy does not display π(θ |u) directly through the signal but does inform θ, we assume that, after seeing the signal, the agents use Bayes' rule to predict their response to the signal based on their knowledge of the data-generating model The previous belief of the sum state is updated to the posterior belief π:
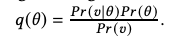 picture
picture
u is a normalization factor. Note that the definition in Equation 3 implies that q(θ) is calculated for the agent to know.
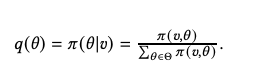 Picture
Picture
Given these posterior beliefs, we use Equation 2 to determine the order in which a perfectly rational agent would maximize her expected utility And the chosen action S.
The author's computing framework provides a useful tool for decision-making collaboration between humans and artificial intelligence, which can help analyze and improve human decision-making behaviors and effects, as well as improve human decision-making quality and satisfaction. Their computational framework also provides an inspiring and innovative space for the expansion and deepening of decision-making theories and methods, and can explore more decision-making factors and mechanisms, as well as more decision-making models and strategies.
Evaluation of Human Decision-Making Performance Loss
The main motivations for using the above framework are epistemological in nature and they relate to our knowledge of experimental results . In order to interpret responses to decision problems in human decision-making experiments as evidence of faulty decision-making processes, the experiment must provide participants with sufficient information to, in principle, determine the normative decisions against which their behavior will be judged. In other words, does the experiment provide participants with enough information to make their understanding of the decision problem consistent with its normative interpretation?
They found that neural network models can reproduce and surpass existing psychological research, such as prospect theory, environment-based models, hybrid models, etc. The neural network model can automatically learn different risk perception functions and the weights between them based on different assumptions. The authors also found that human risk perception functions are nonlinear, scenario-dependent, and that there is an interdependent relationship between probability and return. These findings illustrate that human risk decision-making is extremely complex and cannot be attributed to simple assumptions.
The authors used a simple metric to measure the degree of loss in human decision-making performance, which is the average difference between the human choice and the optimal choice. The authors found that human decision-making performance loss varied significantly across scenarios, ranging from 0.01 to 0.5. The authors also found that the loss of human decision-making performance is positively correlated with the prediction error of the neural network model, that is, the more difficult it is for the neural network model to predict human choices, the greater the loss of human decision-making performance. This illustrates that the neural network model can effectively capture the characteristics of human risk perception, as well as the irrationality and inconsistency of human risk decision-making.
The author's evaluation framework provides a useful tool for human and artificial intelligence decision-making collaboration, which can help analyze and improve human decision-making behavior and effects, as well as improve the quality and quality of human decision-making. Satisfaction. The author's evaluation framework also provides an inspiring and innovative space for the expansion and deepening of decision-making theories and methods, and can explore more decision-making factors and mechanisms, as well as more decision-making models and strategies.
Empirical analysis and results
The empirical analysis of this paper mainly codes and evaluates the research on artificial intelligence-assisted decision-making in recent years. , to test whether these studies conform to the framework of decision theory and whether they make reasonable conclusions about the defects or losses of human decision-making. The author randomly selected 46 studies from the literature review by Lai et al., which were published at ACM or ACL conferences between 2018 and 2021 and involved experiments on artificial intelligence-assisted decision-making for classification or regression problems. .
The authors coded these studies according to the following three aspects.
Applicability of the decision theory framework: Whether there is a real state that can be determined, and whether there is a gain or loss associated with the state.
Evaluation of human decision-making: Whether an evaluation or judgment has been made on the performance or quality of human decision-making, such as pointing out the phenomenon of over-reliance or under-reliance on artificial intelligence, or speculating on human decision-making causes or influencing factors.
Clarity of the decision problem: Whether sufficient information is provided to participants to identify normative decisions, including action space, state space, scoring rules, prior beliefs, and data generation models and signaling strategies, etc.
The author's coding results show that 11 studies (24%) have tasks that do not have a determinable real state, such as subjective music or movie recommendations or emotion recognition. These studies are not suitable for decision-making theoretical frameworks. . The remaining 35 studies (76%) made evaluations or judgments about the performance or quality of human decision-making, but only 6 studies (17%) provided participants with enough information to identify normative decisions, while the others 29 studies (83%) had unclear and incomplete decision-making issues, leading to unreliable conclusions about biases and flaws in human decision-making. The author also provides a detailed analysis and discussion of the specific problems and improvement methods of these studies, such as the lack of communication of prior beliefs, the lack of calculation of posterior beliefs, the lack of motivation and comparison of scoring rules, etc. The author believes that these problems all stem from researchers' insufficient definition and communication of decision-making problems, as well as their unclear understanding of the relationship between the experimental world and the actual world. The author recommends that researchers should fully consider the framework of decision-making theory when designing experiments, and clearly communicate all necessary components of the decision-making problem to participants and readers, so as to effectively evaluate and improve human decision-making behavior.
Future work
The limitations of this paper mainly come from the challenges and criticisms of expected utility theory and normative methods. Expected utility theory is a decision-making theory based on rationality and optimization, which assumes that decision makers have complete information and computing power, as well as consistent and stable preferences. However, these assumptions often do not hold true in the real world. Human decision-making behavior may be affected by cognitive, emotional, social, moral and other factors, leading to deviations from the predictions of expected utility theory. The normative approach is a value- and goal-based approach to decision-making that assumes that the decision maker has a clear value goal and a way to evaluate the impact of different actions on the value goal. However, these assumptions often do not hold true in the real world, where human values may be diverse, dynamic, ambiguous, and may conflict with or harmonize with the values of other people or society. Therefore, the framework and methods of this paper may not be suitable for some subjective, complex, multi-objective decision-making problems, and may also ignore the inherent value and significance of some human decision-making.
Future work will mainly expand and deepen in the following four aspects.
Explore other decision-making theories and methods, such as behavioral economics, multi-attribute utility theory, multi-criteria decision analysis, etc., to better describe and evaluate human actual decision-making behavior and preferences .
Study different information display and interaction methods, such as natural language, graphics, sound, touch, etc., to better communicate and explain the various components of decision-making problems, as well as improve human Information receiving and processing capabilities.
Try different incentive and feedback mechanisms, such as rewards, punishments, credibility, reputation, social influence, etc., to better stimulate and maintain human decision-making motivation and participation, as well as improve Human capacity for decision-making learning and improvement.
Expand different collaboration models between artificial intelligence and humans, such as assistance, advice, agency, negotiation, coordination, etc., to better balance and utilize the strengths and weaknesses of artificial intelligence and humans , as well as improving trust and satisfaction in artificial intelligence and humans.
Significance and value
This paper provides a clear and A framework for structured decision problem definition and evaluation to better design and analyze experiments in human and artificial intelligence decision-making collaboration.
Provides researchers in artificial intelligence, data visualization, human-computer interaction and other fields with an objective and rigorous evaluation and analysis method of decision-making performance loss in order to better identify and Improve the effectiveness and quality of decision-making collaboration between humans and artificial intelligence. They provide a critical and reflective perspective on the communication and interpretation of decision-making problems in order to better understand and communicate the issues and challenges of human and AI decision-making collaboration. They also provide an inspiring and innovative direction of expanding and in-depth decision-making problems to better explore and discover the possibilities and potential of decision-making collaboration between humans and artificial intelligence.
Summary and Outlook
The paper proposes a definition of decision-making problems based on statistical decision theory and information economics, as well as a framework for evaluating the loss of human decision-making performance. Their purpose is to provide a clear and organized guide and reference for researchers in the fields of artificial intelligence, data visualization, human-computer interaction and other fields to better design and analyze experiments on decision-making collaboration between humans and artificial intelligence. They coded and evaluated relevant studies in recent years and found that only a small proportion of studies provided participants with sufficient information to identify normative decisions, while most studies suffered from unclear and incomplete decision problems. Leading to conclusions about biases and flaws in human decision-making are unreliable. We recommend that researchers fully consider the framework of decision-making theory when designing experiments and clearly convey all necessary components of the decision-making problem to participants and readers in order to effectively evaluate and improve human decision-making behavior.
The authors are also aware of the limitations of the framework and methods and the need for future work. Their framework and methods are based on expected utility theory and normative methods, which also have some challenges and criticisms, such as being inconsistent with actual human decision-making behaviors and preferences, and ignoring the intrinsic value and significance of human decision-making. Their frameworks and methods may also not be suitable for some subjective, complex, multi-objective decision-making problems, and may not cover all possibilities and potentials of decision-making collaboration between humans and artificial intelligence. Therefore, our future work is mainly to expand and deepen in the following aspects: explore other decision-making theories and methods, study different information display and interaction methods, study different incentive and feedback mechanisms, study different artificial intelligence and human Collaboration mode. (END)
Reference: https://arxiv.org/abs/2401.15106
The above is the detailed content of Decision-making collaboration between humans and AI: formulation, explanation and evaluation of decision-making problems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
When installing and configuring GitLab on a CentOS system, the choice of database is crucial. GitLab is compatible with multiple databases, but PostgreSQL and MySQL (or MariaDB) are most commonly used. This article analyzes database selection factors and provides detailed installation and configuration steps. Database Selection Guide When choosing a database, you need to consider the following factors: PostgreSQL: GitLab's default database is powerful, has high scalability, supports complex queries and transaction processing, and is suitable for large application scenarios. MySQL/MariaDB: a popular relational database widely used in Web applications, with stable and reliable performance. MongoDB:NoSQL database, specializes in
