
 Technology peripherals
AI
The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark
Technology peripherals
AI
The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark
The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark

OpenAI’s GPT-4V and Google’s Gemini multi-modal large language model have attracted widespread attention from the industry and academia. These models demonstrate deep understanding of video in multiple domains, demonstrating its potential from different perspectives. These advances are widely viewed as an important step toward artificial general intelligence (AGI).
But if I tell you that GPT-4V can even misread the behavior of characters in comics, let me ask: Yuanfang, what do you think?
Let’s take a look at this mini comic series:
 Pictures
Pictures
If you ask the highest intelligence in the biological world - human beings, that is, readers, to describe it, you will most likely say:
 Picture
Picture
Then let’s take a look Look, when the highest intelligence in the machine world - that is, GPT-4V - looks at this mini comic series, what will it describe like this?
 Picture
Picture
GPT-4V, as a machine intelligence recognized as standing at the top of the contempt chain, openly tells lies.
What’s even more outrageous is that even if GPT-4V is given actual life image clips, it will also absurdly recognize the behavior of a person talking to another person while going up the stairs as two people holding " Weapons" fight and play with each other (as shown in the picture below).
 Picture
Picture
Gemini is not far behind. The same image fragment sees the process as a man struggling to go upstairs and arguing with his wife while being locked in inside the house.
 Picture
Picture
These examples come from the latest results of a research team from the University of Maryland and North Carolina Chapel Hill, who launched a system specifically designed for MLLM An inference benchmark for image sequences - Mementos.
Just as Nolan’s film Memento redefined storytelling, Mementos is reshaping the limits of testing artificial intelligence.
As a new benchmark test, it challenges artificial intelligence's understanding of image sequences like memory fragments.
 Pictures
Pictures
Paper link: https://arxiv.org/abs/2401.10529
Project homepage: https://mementos -bench.github.io
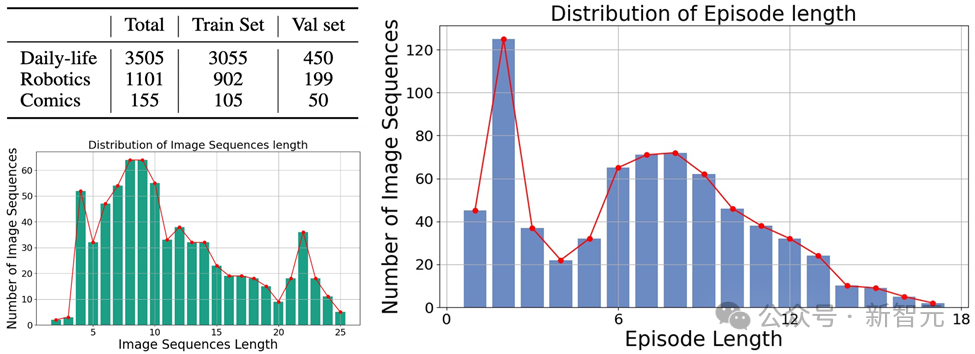
Mementos is the first benchmark test for image sequence reasoning designed specifically for MLLM, focusing on object hallucination and behavioral hallucination of large models on continuous images.
It involves a variety of image types, covering three major categories: real-world images, robot images, and animation images.
and contains 4,761 diverse image sequences of different lengths, each with human-annotated descriptions of the main objects and their behavior in the sequence.
 Picture
Picture
The data is now open source and is still being updated.
Type of hallucination
The author explains in the paper two kinds of hallucinations that MLLM will produce in Mementos: object hallucination and behavioral hallucination. .
As the name suggests, object hallucination is the imagining of a non-existent object (object), while behavioral hallucination is the imagining of actions and behaviors that the object did not perform.
Evaluation method
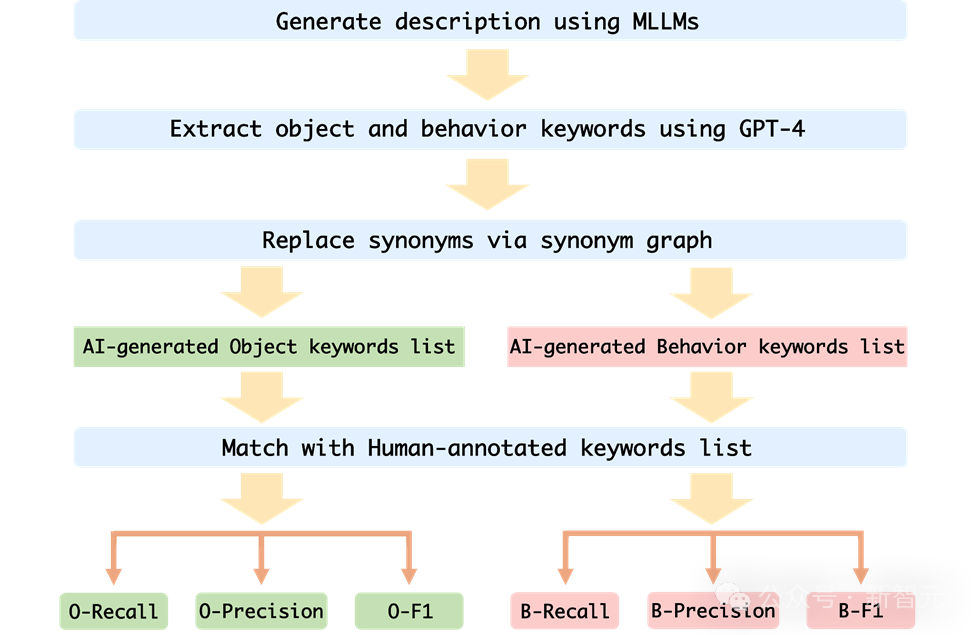
In order to accurately evaluate the behavioral hallucination and object hallucination of MLLM on Mementos, the research team chose to use the image description and person annotation generated by MLLM. Description for keyword matching.
In order to automatically evaluate the performance of each MLLM, the author uses the GPT-4 auxiliary test method to evaluate:
 Picture
Picture
1. The author takes the image sequence and prompt words as input to MLLM, and generates a description corresponding to the corresponding image sequence;
2. Request GPT-4 to extract the object and behavior keywords in the AI-generated description;
3. Obtain two keyword lists: the object keyword list generated by AI and the behavior keyword list generated by AI;
4. Calculate the object keyword list and behavior keyword list generated by AI and the person The recall rate, precision rate and F1 index of the annotated keyword table.
Evaluation results
The author evaluated the performance of MLLMs in sequence image reasoning on Mementos, and conducted experiments on nine latest MLLMs including GPT4V and Gemini. Careful assessment.
MLLM is asked to describe the events occurring in the image sequence to evaluate the reasoning ability of MLLM for continuous images.
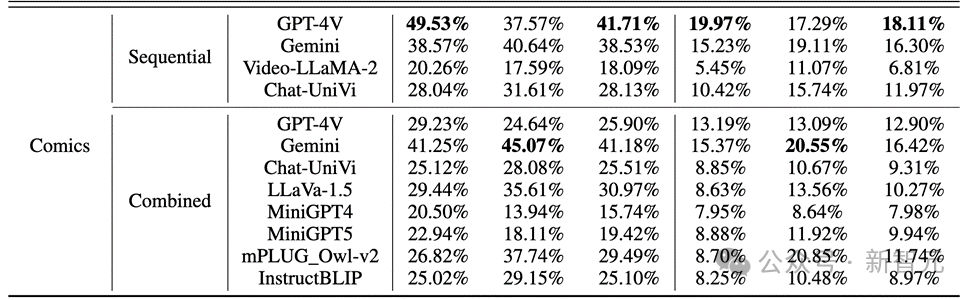
The results found that, as shown in the figure below, the accuracy of GPT-4V and Gemini for character behavior in the comic data set was less than 20%.
 Picture
Picture
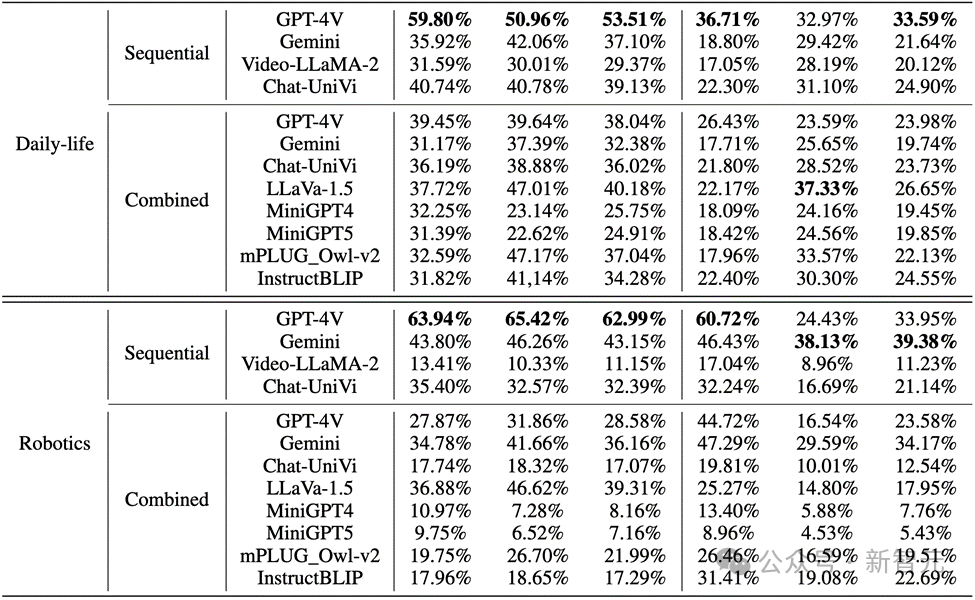
In real-world images and robot images, the performance of GPT-4V and Gemini is not satisfactory:
 Picture
Picture
Key Points
1. GPT-4V and LLaVA-1.5 when evaluating multi-modal large language models These are the best-performing models in black-box and open-source MLLMs respectively. GPT-4V outperforms all other MLLMs in reasoning ability in understanding image sequences, while LLaVA-1.5 is almost on par with or even surpasses the black-box model Gemini in object understanding.
2. Although Video-LLaMA-2 and Chat-UniVi are designed for video understanding, they do not show better advantages than LLaVA-1.5.
3. All MLLMs perform significantly better than behavioral reasoning on the three indicators of object reasoning in image sequences, indicating that current MLLMs are not strong in the ability to autonomously infer behaviors from consecutive images.
4. The black box model performs best in the field of robotics, while the open source model performs relatively well in the field of daily life. This may be related to the distribution shift of the training data.
5. The limitations of training data lead to weak inference capabilities of open source MLLMs. This demonstrates the importance of training data and its direct impact on model performance.
Error reasons
The author analyzed the reasons why current multi-modal large-scale language models fail when processing image sequence reasoning, and mainly identified three error reasons:
1. Interaction between object and behavioral hallucinations
The study hypothesized that incorrect object recognition would lead to inaccurate subsequent behavioral recognition. Quantitative analysis and case studies show that object hallucinations can lead to behavioral hallucinations to a certain extent. For example, when MLLM mistakenly identifies a scene as a tennis court, it may describe a character playing tennis, even though this behavior does not exist in the image sequence.
2. The impact of co-occurrence on behavioral hallucinations
MLLM tends to generate behavioral combinations that are common in image sequence reasoning, which exacerbates Problems with behavioral hallucinations. For example, when processing images from the robotics domain, MLLM may incorrectly describe a robot arm pulling open a drawer after "grabbing the handle" even though the actual action was "grabbing the side of the drawer."
3. The Snowball Effect of Behavioral Illusions
As the image sequence proceeds, errors may gradually accumulate or intensify, which is called Snowball effect. In image sequence reasoning, if errors occur early, these errors may accumulate and amplify in the sequence, resulting in reduced accuracy in object and action recognition.
For example
 Picture
Picture
From As can be seen from the above figure, the reasons for the failure of MLLM include object hallucinations, the correlation between object hallucinations and behavioral hallucinations, and co-occurring behaviors.
For example, after experiencing the object hallucination of "tennis court", MLLM then showed the behavioral hallucination of "holding a tennis racket" (correlation between object hallucination and behavioral hallucination) and the common feeling of "appearing to be playing tennis" current behavior.
 Picture
Picture
#Observing the sample in the picture above, you can find that MLLM mistakenly believes that the chair goes further Lean back and think the chair is broken.
This phenomenon reveals that MLLM can also produce the illusion that some action has occurred on the object for static objects in the image sequence.
 Picture
Picture
#In the above image sequence display of the robotic arm, the robotic arm reaches Next to the handle, MLLM mistakenly believed that the robot arm had grasped the handle, proving that MLLM generates behavioral combinations that are common in image sequence reasoning, thereby creating hallucinations.
 Picture
Picture
In the case above, the old master is not holding the dog, MLLM error It is believed that when walking a dog, the dog must be held on a leash, and "the dog's pole vaulting" is recognized as "creating a fountain".
The large number of errors reflects MLLM’s unfamiliarity with the comic field. In the field of two-dimensional animation, MLLM may require substantial optimization and pre-training.
In the appendix, the author displays failure cases in each major category in detail and conducts in-depth analysis.
Summary
In recent years, multi-modal large-scale language models have demonstrated excellent capabilities in processing various visual-linguistic tasks.
These models, such as GPT-4V and Gemini, are able to understand and generate text related to images, greatly promoting the development of artificial intelligence technology.
However, existing MLLM benchmarks mainly focus on inference based on a single static image, while inference from image sequences is crucial for understanding our changing world. , there are relatively few studies on the ability.
To address this challenge, the researchers proposed a new benchmark "Mementos" to evaluate the capabilities of MLLMs in sequence image reasoning.
Mementos contains 4761 diverse image sequences of different lengths. In addition, the research team also adopted the GPT-4 auxiliary method to evaluate the inference performance of MLLM.
Through careful evaluation of nine latest MLLMs (including GPT-4V and Gemini) on Mementos, the study found that these models exist in accurately describing the dynamic information of a given image sequence. Challenges, often resulting in hallucinations/misrepresentations of objects and their behavior.
Quantitative analysis and case studies identify three key factors affecting sequence image reasoning in MLLMs:
1. Between object and behavioral illusions Correlation;
2. Impact of co-occurring behaviors;
3. Cumulative impact of behavioral hallucinations.
This discovery is of great significance for understanding and improving the ability of MLLMs in processing dynamic visual information. The Mementos benchmark not only reveals the limitations of current MLLMs, but also provides directions for future research and improvements.
With the rapid development of artificial intelligence technology, the application of MLLMs in the field of multi-modal understanding will become more extensive and in-depth. The introduction of the Mementos benchmark not only promotes research in this field, but also provides us with new perspectives to understand and improve how these advanced AI systems process and understand our complex and ever-changing world.
Reference materials:
https://github.com/umd-huanglab/Mementos
The above is the detailed content of The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Understand Tokenization in one article!
Apr 12, 2024 pm 02:31 PM
Understand Tokenization in one article!
Apr 12, 2024 pm 02:31 PM
Language models reason about text, which is usually in the form of strings, but the input to the model can only be numbers, so the text needs to be converted into numerical form. Tokenization is a basic task of natural language processing. It can divide a continuous text sequence (such as sentences, paragraphs, etc.) into a character sequence (such as words, phrases, characters, punctuation, etc.) according to specific needs. The units in it Called a token or word. According to the specific process shown in the figure below, the text sentences are first divided into units, then the single elements are digitized (mapped into vectors), then these vectors are input to the model for encoding, and finally output to downstream tasks to further obtain the final result. Text segmentation can be divided into Toke according to the granularity of text segmentation.
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
 How can AI make robots more autonomous and adaptable?
Jun 03, 2024 pm 07:18 PM
How can AI make robots more autonomous and adaptable?
Jun 03, 2024 pm 07:18 PM
In the field of industrial automation technology, there are two recent hot spots that are difficult to ignore: artificial intelligence (AI) and Nvidia. Don’t change the meaning of the original content, fine-tune the content, rewrite the content, don’t continue: “Not only that, the two are closely related, because Nvidia is expanding beyond just its original graphics processing units (GPUs). The technology extends to the field of digital twins and is closely connected to emerging AI technologies. "Recently, NVIDIA has reached cooperation with many industrial companies, including leading industrial automation companies such as Aveva, Rockwell Automation, Siemens and Schneider Electric, as well as Teradyne Robotics and its MiR and Universal Robots companies. Recently,Nvidiahascoll
 After 2 months, the humanoid robot Walker S can fold clothes
Apr 03, 2024 am 08:01 AM
After 2 months, the humanoid robot Walker S can fold clothes
Apr 03, 2024 am 08:01 AM
Editor of Machine Power Report: Wu Xin The domestic version of the humanoid robot + large model team completed the operation task of complex flexible materials such as folding clothes for the first time. With the unveiling of Figure01, which integrates OpenAI's multi-modal large model, the related progress of domestic peers has been attracting attention. Just yesterday, UBTECH, China's "number one humanoid robot stock", released the first demo of the humanoid robot WalkerS that is deeply integrated with Baidu Wenxin's large model, showing some interesting new features. Now, WalkerS, blessed by Baidu Wenxin’s large model capabilities, looks like this. Like Figure01, WalkerS does not move around, but stands behind a desk to complete a series of tasks. It can follow human commands and fold clothes
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Three secrets for deploying large models in the cloud
Apr 24, 2024 pm 03:00 PM
Three secrets for deploying large models in the cloud
Apr 24, 2024 pm 03:00 PM
Compilation|Produced by Xingxuan|51CTO Technology Stack (WeChat ID: blog51cto) In the past two years, I have been more involved in generative AI projects using large language models (LLMs) rather than traditional systems. I'm starting to miss serverless cloud computing. Their applications range from enhancing conversational AI to providing complex analytics solutions for various industries, and many other capabilities. Many enterprises deploy these models on cloud platforms because public cloud providers already provide a ready-made ecosystem and it is the path of least resistance. However, it doesn't come cheap. The cloud also offers other benefits such as scalability, efficiency and advanced computing capabilities (GPUs available on demand). There are some little-known aspects of deploying LLM on public cloud platforms
 Ten humanoid robots shaping the future
Mar 22, 2024 pm 08:51 PM
Ten humanoid robots shaping the future
Mar 22, 2024 pm 08:51 PM
The following 10 humanoid robots are shaping our future: 1. ASIMO: Developed by Honda, ASIMO is one of the most well-known humanoid robots. Standing 4 feet tall and weighing 119 pounds, ASIMO is equipped with advanced sensors and artificial intelligence capabilities that allow it to navigate complex environments and interact with humans. ASIMO's versatility makes it suitable for a variety of tasks, from assisting people with disabilities to delivering presentations at events. 2. Pepper: Created by Softbank Robotics, Pepper aims to be a social companion for humans. With its expressive face and ability to recognize emotions, Pepper can participate in conversations, help in retail settings, and even provide educational support. Pepper's
