
 Technology peripherals
AI
Learn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times
Technology peripherals
AI
Learn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times
Learn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times

Existing large model alignment methods include examplebased supervised fine-tuning (SFT) and score feedbackbased reinforcement learning (RLHF). However, the score can only reflect the quality of the current response and cannot clearly indicate the shortcomings of the model. In contrast, we humans typically learn and adjust our behavioral patterns from verbal feedback. Just like the review comments are not just a score, but also include many reasons for acceptance or rejection.
So, can large language models also use language feedback to improve themselves like humans?
Researchers from the Chinese University of Hong Kong and Tencent AI Lab recently proposed an innovative research called Contrastive Unlikelihood Learning (CUT). The research uses language feedback to adjust language models so that they can learn and improve from different criticisms, just like humans. This research aims to improve the quality and accuracy of language models to make them more consistent with the way humans think. By comparing non-likelihood training, researchers hope to enable the language model to better understand and adapt to diverse language usage situations, thereby improving its performance in natural language processing tasks. This innovative research is expected to provide a simple and effective method for language models
#CUT. By using only 1317 pieces of language feedback data, CUT was able to significantly improve the winning rate of LLaMA2-13b on AlpacaEval, soaring from 1.87% to 62.56%, and successfully defeated 175B DaVinci003. What’s exciting is that CUT can also perform iterative cycles of exploration, criticism, and improvement like other reinforcement learning and reinforcement learning reinforcement feedback (RLHF) frameworks. In this process, the criticism stage can be completed by the automatic evaluation model to achieve self-evaluation and improvement of the entire system.
The author conducted four rounds of iterations on LLaMA2-chat-13b, gradually improving the model's performance on AlpacaEval from 81.09% to 91.36%. Compared with alignment technology based on score feedback (DPO), CUT performs better under the same data size. The results reveal that language feedback has great potential for development in the field of alignment, opening up new possibilities for future alignment research. This finding has important implications for improving the accuracy and efficiency of alignment techniques and provides guidance for achieving better natural language processing tasks.

- ##Paper title: Reasons to Reject? Aligning Language Models with Judgments
- Paper link: https://arxiv.org/abs/2312.14591
- Github link: https://github.com/ wwxu21/CUT
Alignment of large models
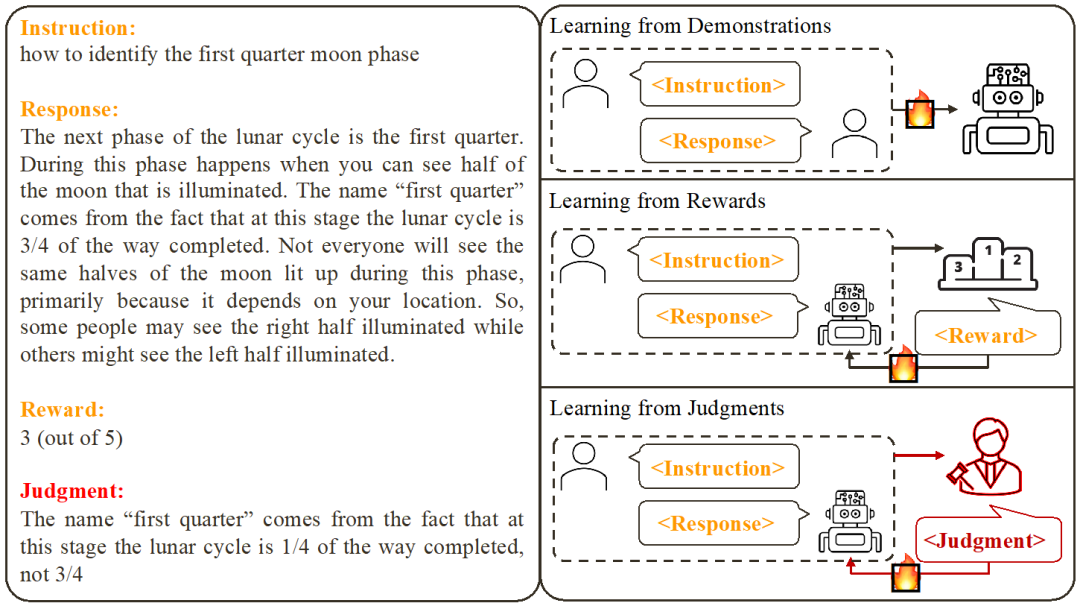
Based on existing work , researchers summarized two common large model alignment methods:
1. Learning from Demonstration: Based on ready-made instructions - Reply Yes, using supervised training methods to align large models.
Advantages: stable training; simple implementation.- Disadvantages: The cost of collecting high-quality and diverse example data is high; it is impossible to learn from error responses; example data is often irrelevant to the model.
- 2. Learning from Rewards: Score the command-reply pair and use reinforcement learning to train the model to maximize its response score.
Advantages: Correct responses and error responses can be used simultaneously; feedback signals are related to the model.
- Disadvantages: The feedback signal is sparse; the training process is often complicated.
- This study focuses on learning from Language feedback (Learning from Judgments): giving instructions - replying to writing comments, based on the language feedback Improve the defects of the model and maintain the advantages of the model, thereby improving the model performance.
It can be seen that language feedback inherits the advantages of score feedback. Compared with score feedback, verbal feedback is more informative: instead of letting the model guess what it did right and what it went wrong, verbal feedback can directly point out detailed deficiencies and directions for improvement. Unfortunately, however, researchers have found that there is currently no effective way to fully utilize verbal feedback. To this end, researchers have proposed an innovative framework, CUT, designed to take full advantage of language feedback.
Contrastive non-likelihood training
The core idea of CUT is to learn from contrast. Researchers compare the responses of large models under different conditions to find out which parts are satisfactory and should be maintained, and which parts are flawed and need to be modified. Based on this, researchers use maximum likelihood estimation (MLE) to train the satisfactory part, and use unlikelihood training (UT) to modify the flaws in the reply.
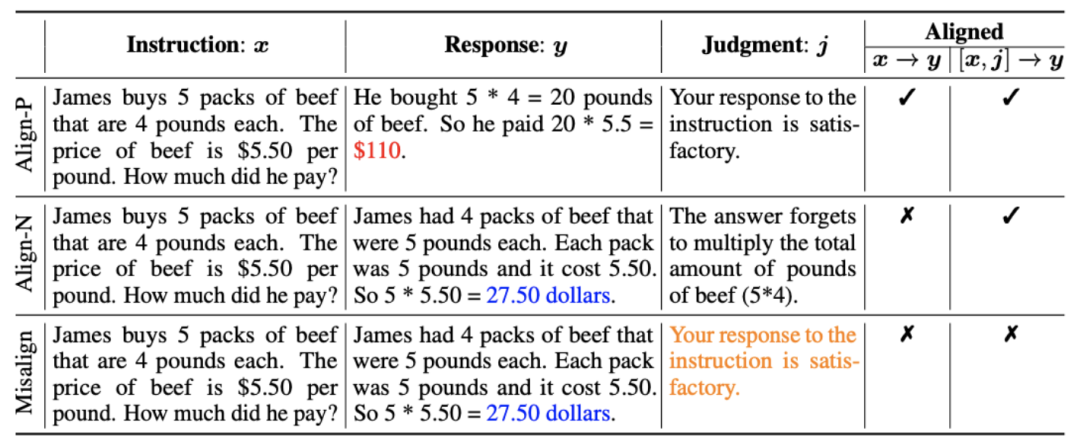
1. Alignment scenario: As shown in the figure above, the researchers considered two alignment scenarios:
a) : This is a commonly understood alignment scenario where a reply needs to faithfully follow instructions and be consistent with human expectations and values.
: This is a commonly understood alignment scenario where a reply needs to faithfully follow instructions and be consistent with human expectations and values.
b)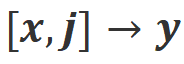 : This scenario introduces verbal feedback as an additional condition. In this scenario, the response must satisfy both instructions and verbal feedback. For example, when receiving a negative feedback, the large model needs to make mistakes based on the issues mentioned in the corresponding feedback.
: This scenario introduces verbal feedback as an additional condition. In this scenario, the response must satisfy both instructions and verbal feedback. For example, when receiving a negative feedback, the large model needs to make mistakes based on the issues mentioned in the corresponding feedback.
2. Alignment data: As shown in the figure above, based on the above two alignment scenarios, researchers constructed three types of alignment data:
a) Align-P: The large model generated satisfactory responses and thus received positive feedback. Obviously, Align-P satisfies alignment in both  and
and  scenarios.
scenarios.
b) Align-N: The large model generated flawed (blue bold) replies and therefore received negative feedback. For Align-N, alignment is not satisfied in  . But after considering this negative feedback, Align-N is still aligned in the
. But after considering this negative feedback, Align-N is still aligned in the 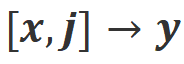 scenario.
scenario.
c) Misalign: Real negative feedback in Align-N is replaced with a fake positive feedback. Obviously, Misalign does not satisfy alignment in both  and
and 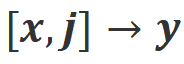 scenarios.
scenarios.
3. Learn from contrast:
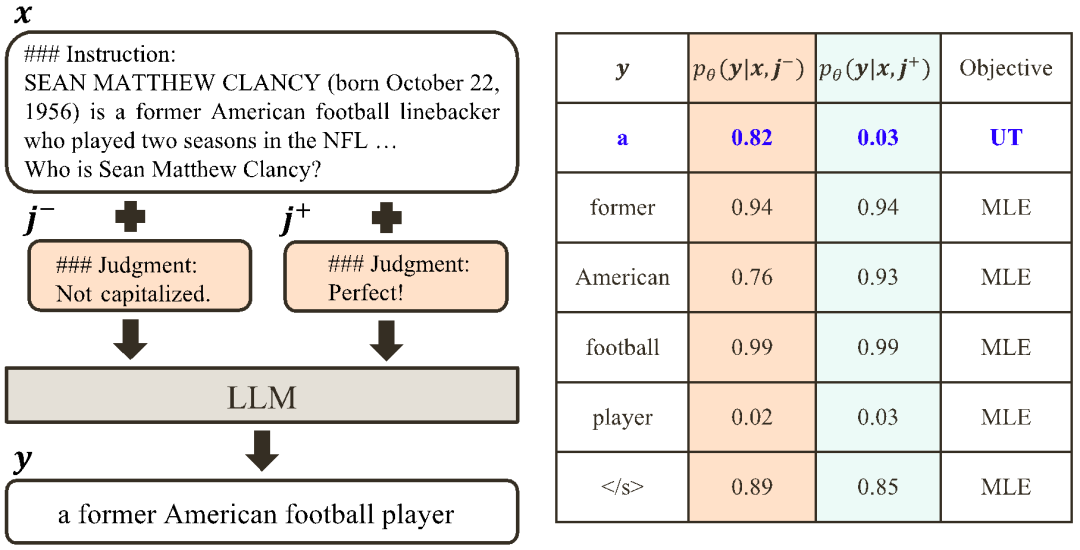
a) Align-N vs. Misalign: The difference between the two is mainly the degree of alignment under 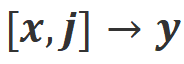 . Given the powerful in-context learning capabilities of large models, the alignment polarity flip from Align-N to Misalign is usually accompanied by a significant change in the generation probability of specific words, especially those words that are closely related to real negative feedback. . As shown in the figure above, under the condition of Align-N (left channel), the probability of large model generating "a" is significantly higher than Misalign (right channel). And the place where the probability changes significantly is where the big model makes a mistake.
. Given the powerful in-context learning capabilities of large models, the alignment polarity flip from Align-N to Misalign is usually accompanied by a significant change in the generation probability of specific words, especially those words that are closely related to real negative feedback. . As shown in the figure above, under the condition of Align-N (left channel), the probability of large model generating "a" is significantly higher than Misalign (right channel). And the place where the probability changes significantly is where the big model makes a mistake.
In order to learn from this comparison, the researchers input Align-N and Misalign data to the large model at the same time to obtain the generation probabilities of the output words under the two conditions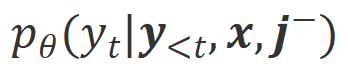 and
and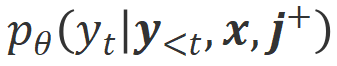 . Words that have a significantly higher generation probability in the
. Words that have a significantly higher generation probability in the 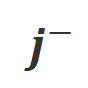 condition than in the
condition than in the  condition are marked as inappropriate words. Specifically, researchers used the following criteria to quantify the definition of inappropriate words:
condition are marked as inappropriate words. Specifically, researchers used the following criteria to quantify the definition of inappropriate words:
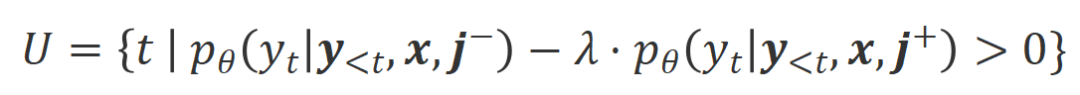
where 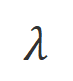 is Hyperparameters that trade off precision and recall during inappropriate word recognition.
is Hyperparameters that trade off precision and recall during inappropriate word recognition.
The researchers used unlikelihood training (UT) on these identified inappropriate words, thereby forcing the large model to explore more satisfactory responses. For other reply words, researchers still use maximum likelihood estimation (MLE) to optimize:
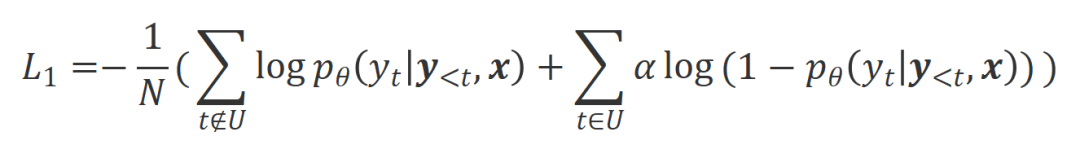
where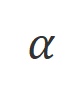 is a hyperparameter that controls the proportion of non-likelihood training,
is a hyperparameter that controls the proportion of non-likelihood training,  is the number of reply words.
is the number of reply words.
b) Align-P v.s. Align-N: The difference between the two mainly lies in the degree of alignment under 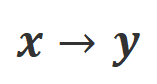 . Essentially, the large model controls the quality of the output reply by introducing language feedback of different polarities. Therefore, the comparison between the two can inspire large models to distinguish satisfactory responses from defective responses. Specifically, we learn from this set of comparisons via the following maximum likelihood estimation (MLE) loss:
. Essentially, the large model controls the quality of the output reply by introducing language feedback of different polarities. Therefore, the comparison between the two can inspire large models to distinguish satisfactory responses from defective responses. Specifically, we learn from this set of comparisons via the following maximum likelihood estimation (MLE) loss:
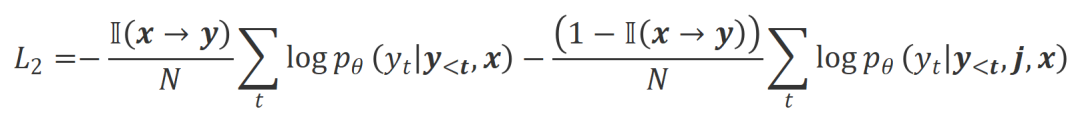
where 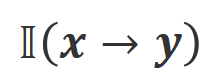 is an indicator function that returns 1 if the data satisfies
is an indicator function that returns 1 if the data satisfies 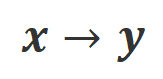 alignment, otherwise it returns 0.
alignment, otherwise it returns 0.
CUT’s final training goal combines the above two sets of comparisons: 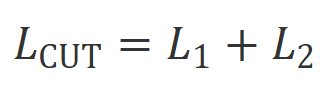 .
.
Experimental evaluation
1. Offline alignment
In order to save Qian, the researchers first tried to use existing language feedback data to align large models. This experiment was used to demonstrate CUT's ability to utilize language feedback.
a) General model
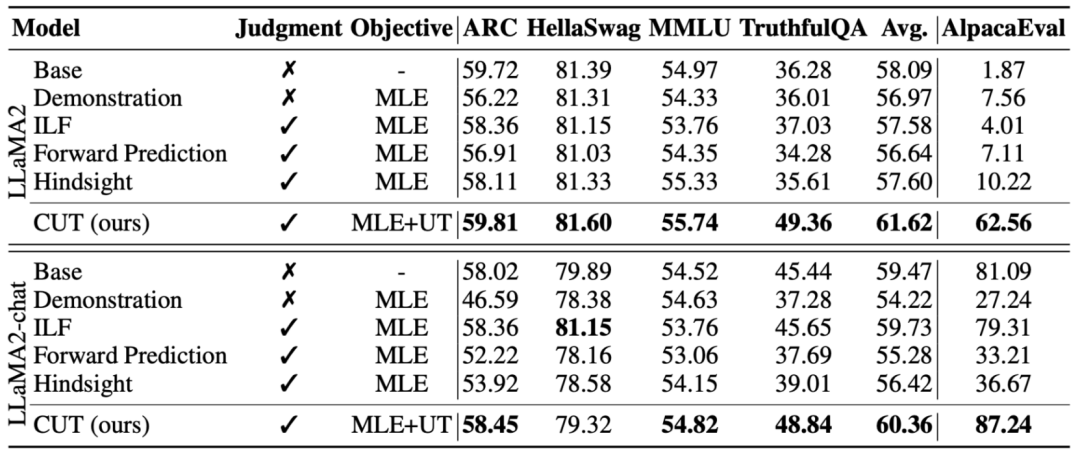
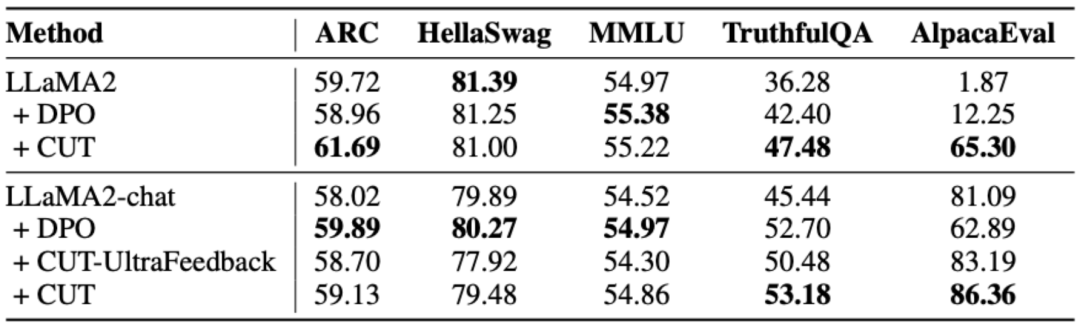
As shown in the table above, for general model alignment, the researchers used 1317 alignment data provided by Shepherd to compare CUT under cold start (LLaMA2) and hot start (LLaMA2-chat) conditions. versus existing methods for learning from linguistic feedback.
Under the cold start experiment based on LLaMA2, CUT significantly surpassed existing alignment methods on the AlpacaEval test platform, fully proving its advantages in utilizing language feedback. Moreover, CUT has also achieved significant improvements in TruthfulQA compared to the base model, which reveals that CUT has great potential in alleviating the hallucination problem of large models.
In the hot start scenario based on LLaMA2-chat, existing methods perform poorly in improving LLaMA2-chat and even have negative effects. However, CUT can further improve the performance of the base model on this basis, once again verifying the great potential of CUT in utilizing language feedback.
b) Expert model
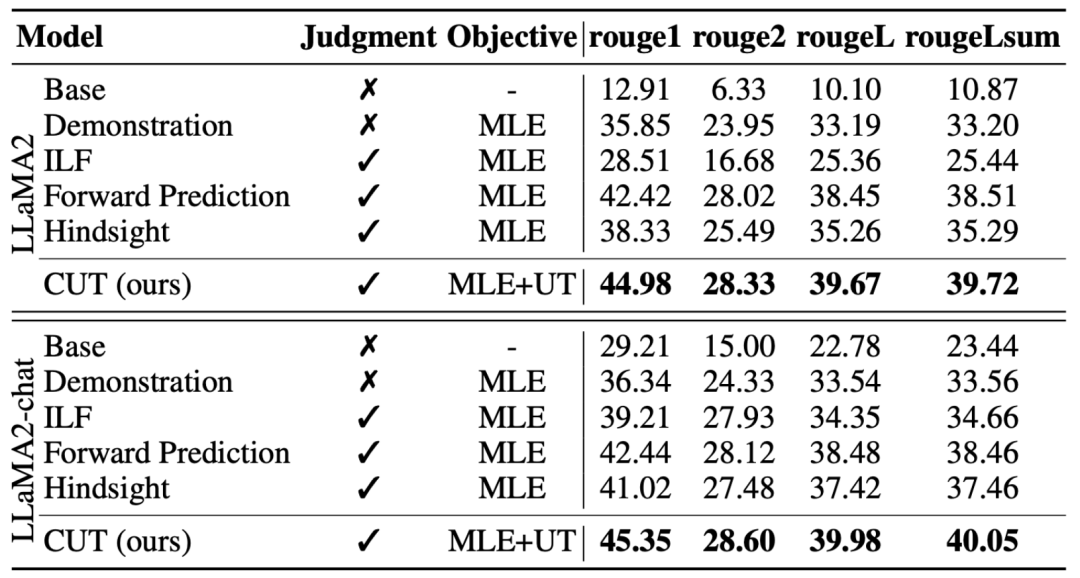
The researchers also tested on specific expert tasks (text abstract ) on the CUT alignment effect. As shown in the table above, CUT also achieves significant improvements compared to existing alignment methods on expert tasks.
2. Online alignment
Research on offline alignment has successfully demonstrated the powerful alignment performance of CUT. Now, researchers are further exploring online alignment scenarios that are closer to practical applications. In this scenario, researchers iteratively annotate the responses of the target large model with language feedback so that the target model can be more accurately aligned based on the language feedback associated with it. The specific process is as follows:
-
Step 1: Collect instructions
 , and obtain the reply from the target large model .
, and obtain the reply from the target large model .
-
Step 2: In response to the above instruction-reply pair, mark the language feedback .
-
Step 3: Use CUT to fine-tune the target large model based on the collected triplet data.


As shown in the figure above, after four rounds of online alignment iterations, CUT has only Under the conditions of 4000 training data and a small 13B model size, it can still achieve an impressive score of 91.36. This achievement further demonstrates CUT’s excellent performance and huge potential.
3. AI comment model
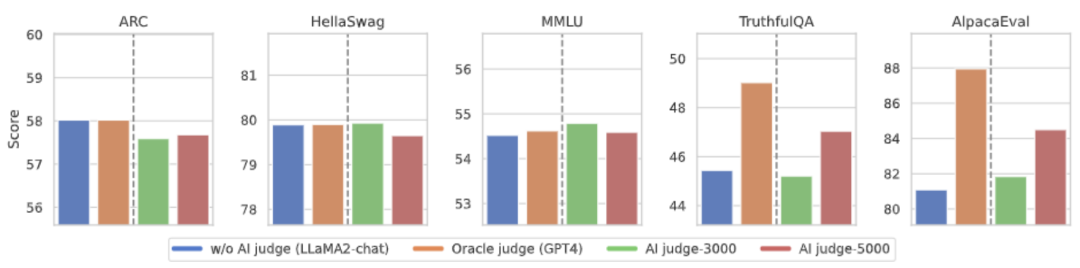
Annotation taking into account language feedback To reduce the cost, researchers try to train a judgment model to automatically annotate language feedback for the target large model. As shown in the figure above, the researchers used 5,000 pieces (AI Judge-5000) and 3,000 pieces (AI Judge-3000) of language feedback data to train two review models. Both review models have achieved remarkable results in optimizing the target large-scale model, especially the effect of AI Judge-5000.
This proves the feasibility of using AI comment models to align target large models, and also highlights the importance of comment model quality in the entire alignment process. This set of experiments also provides strong support for reducing annotation costs in the future.
4. Language feedback vs. score feedback
In order to deeply explore the huge potential of language feedback in large model alignment, researchers compared CUT based on language feedback with the method based on score feedback (DPO). In order to ensure a fair comparison, the researchers selected 4,000 sets of the same instruction-response pairs as experimental samples, allowing CUT and DPO to learn from the score feedback and language feedback corresponding to these data respectively.
As shown in the table above, CUT performed significantly better than DPO in the cold start (LLaMA2) experiment. In the hot start (LLaMA2-chat) experiment, CUT can achieve results comparable to DPO on tasks such as ARC, HellaSwag, MMLU, and TruthfulQA, and is significantly ahead of DPO on the AlpacaEval task. This experiment confirmed the greater potential and advantages of linguistic feedback compared to fractional feedback during large model alignment.
Summary and Challenges
In this work, the researchers systematically explored the current status and innovation of language feedback in large model alignment We proposed an alignment framework CUT based on language feedback, revealing the great potential and advantages of language feedback in the field of large-scale model alignment. In addition, there are some new directions and challenges in the research of language feedback, such as:
1. The quality of the comment model: Although research The researchers have successfully demonstrated the feasibility of training a review model, but when observing the model output, they still find that the review model often gives less than accurate reviews. Therefore, improving the quality of the review model is of great significance for large-scale use of language feedback for alignment in the future.
2. Introduction of new knowledge: When language feedback involves knowledge that the large model lacks, even if the large model can accurately Errors were identified, but there was no clear direction for correction. Therefore, it is very important to supplement the knowledge that the large model lacks while aligning.
3. Multi-modal alignment: The success of language models has promoted the research of multi-modal large models, such as language, speech, A combination of images and videos. In these multi-modal scenarios, studying language feedback and feedback of corresponding modalities has ushered in new definitions and challenges.
The above is the detailed content of Learn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times. For more information, please follow other related articles on the PHP Chinese website!
Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
