
 Technology peripherals
AI
The first universal framework in the graph field is here! Selected into ICLR\'24 Spotlight, any data set and classification problem can be solved
Technology peripherals
AI
The first universal framework in the graph field is here! Selected into ICLR\'24 Spotlight, any data set and classification problem can be solved
The first universal framework in the graph field is here! Selected into ICLR\'24 Spotlight, any data set and classification problem can be solved

Can there be a general graph model——
It can not only predict toxicity based on molecular structure, but also give information about social networks A friend recommended?
Or can it not only predict the citations of papers by different authors, but also discover the human aging mechanism in the gene network?
Don’t tell me, the “One for All(OFA)” framework accepted as Spotlight by ICLR 2024 achieves this "essence".
This research was jointly proposed by researchers such as Professor Chen Yixin’s team at Washington University in St. Louis, Zhang Muhan from Peking University, and Tao Dacheng from Jingdong Research Institute.
As the first general framework in the graph field, OFA enables training a single GNN model to solve the classification task of any data set, any task type, and any scene in the graph field.

How to implement it, the following is the author's contribution.
The design of universal models in the graph field faces three major difficulties
Designing a universal basic model to solve a variety of tasks is a long-term goal in the field of artificial intelligence. In recent years, basic large language models (LLMs) have performed well in processing natural language tasks. However, in the field of graphs, although graph neural networks
(GNNs)have good performance in different graph data, how to design and train a network that can handle multiple graphs at the same time? The basic graph model of the task still has a long way to go. Compared with the natural language field, the design of general models in the graph field faces many unique difficulties.
First of all, different from natural language, different graph data have completely different attributes and distributions.
For example, a molecular diagram describes how multiple atoms form different chemical substances through different force relationships. The citation relationship diagram describes the network of mutual citations between articles.
These different graph data are difficult to unify under a training framework.
Secondly, unlike all tasks in LLMs, which can be converted into unified context generation tasks, graph tasks include a variety of sub-tasks, such as node tasks, link tasks, full-graph tasks, etc.
Different subtasks usually require different task representations and different graph models.
Finally, the success of large language models is inseparable from context learning
(in-context learning)achieved through prompt paradigms. In large language models, the prompt paradigm is usually a readable text description of the downstream task.
But for graph data that is unstructured and difficult to describe in words, how to design an effective graph prompt paradigm to achieve in-context learning is still an unsolved mystery.
Use the concept of "text diagram" to solve the problem
The following figure gives the overall framework of OFA:
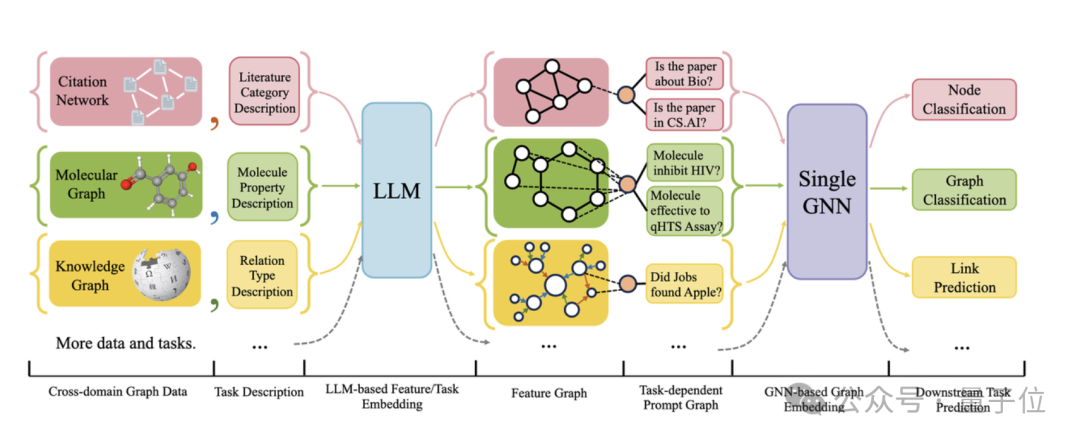 Specifically, OFA's team solved the three main problems mentioned above through clever design.
Specifically, OFA's team solved the three main problems mentioned above through clever design.
To solve the problem of different graph data attributes and distributions, OFA unifies all graph data by proposing the concept of text graph
(Text-Attributed Graph, TAGs). Using text graphs, OFA describes the node information and edge information in all graph data using a unified natural language framework, as shown in the following figure:

 Next, OFA uses a single LLM model to learn the representation of the text in all data to obtain its embedding vectors.
Next, OFA uses a single LLM model to learn the representation of the text in all data to obtain its embedding vectors.
These embedding vectors will serve as input features for the graphical model. In this way, graph data from different domains will be mapped to the same feature space, making it feasible to train a unified GNN model.
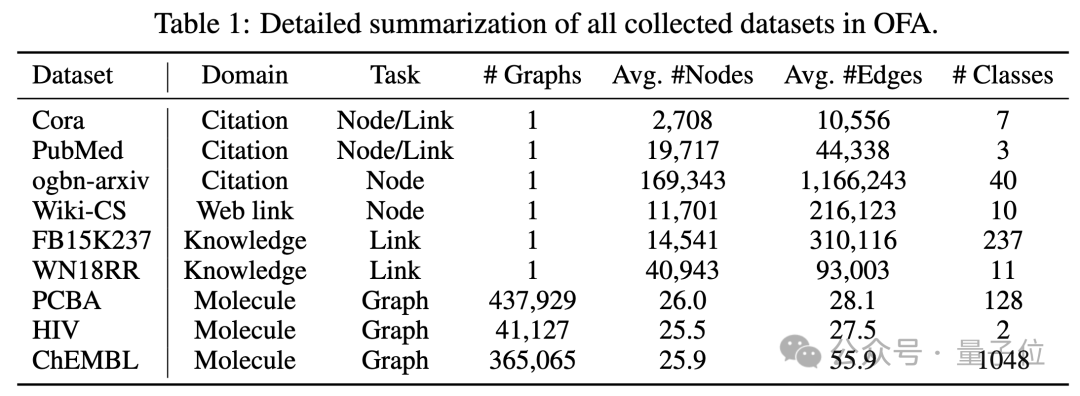
OFA has collected 9 graph data sets of different sizes from different fields, including citation relationship graphs, Web link graphs, knowledge graphs, and molecular graphs, as shown in the following figure:
 In addition, OFA proposes Nodes-of-Interest
In addition, OFA proposes Nodes-of-Interest
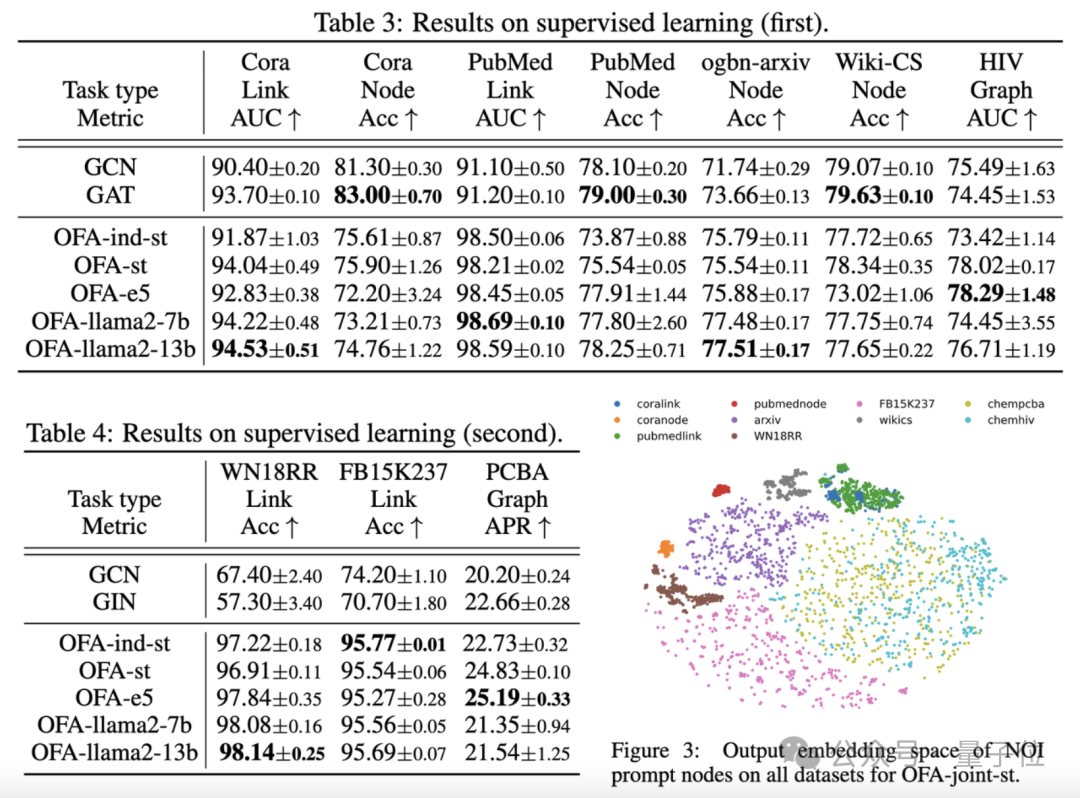
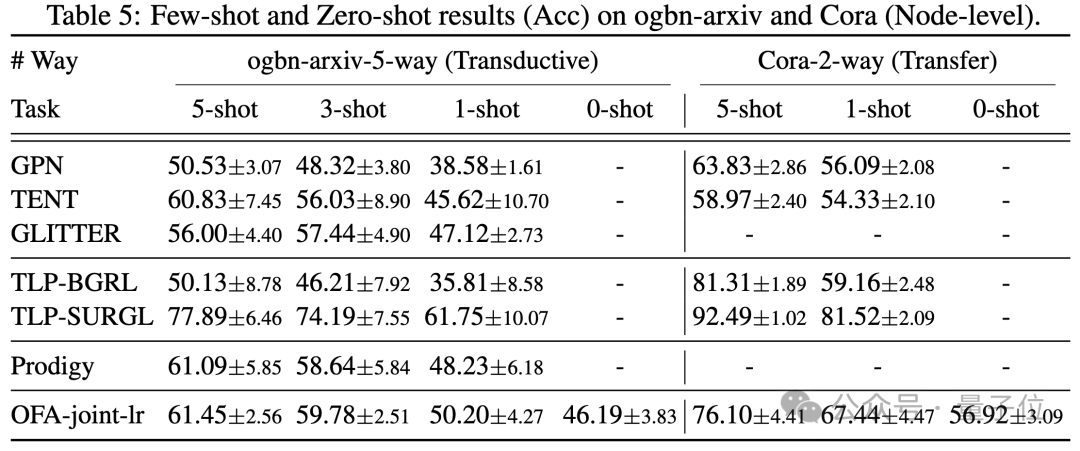
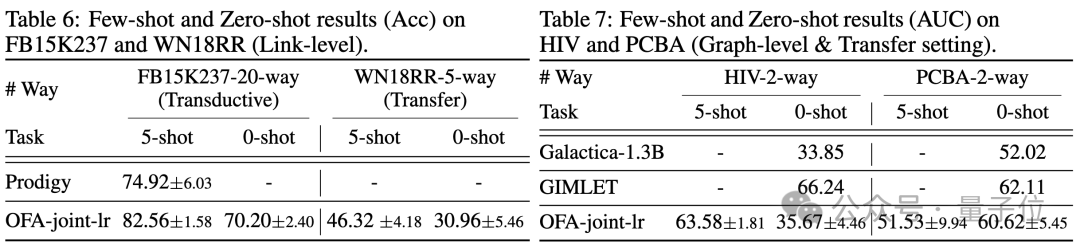
Subgraph and NOI Prompt Node (NOI Prompt Node) to unify different subgraphs in the graph field Task type. Here NOI represents a set of target nodes participating in the corresponding task. For example, in the node prediction task, the NOI refers to a single node that needs to be predicted; while in the link task, the NOI includes two nodes that need to predict the link. The NOI subgraph refers to a subgraph containing h-hop neighborhoods extended around these NOI nodes. Then, the NOI prompt node is a newly introduced node type, directly connected to all NOIs. Importantly, each NOI prompt node contains description information of the current task. This information exists in the form of natural language and is represented by the same LLM as the text graph. Since the information contained in the nodes in the NOI will be collected by the NOI prompt node after passing the message of GNNs, the GNN model only needs to make predictions through the NOI prompt node. In this way, all different task types will have a unified task representation. The specific example is shown in the figure below: Finally, in order to realize in-context learning in the graph field, OFA introduces a unified prompt subgraph. In a supervised k-way classification task scenario, this prompt subgraph contains two types of nodes: one is the NOI prompt node mentioned above, and the other represents k different categories. Class Node (Class Node). The text of each category node will describe relevant information for this category. NOI prompt nodes will be connected to all category nodes in one direction. The graph constructed in this way will be input into the graph neural network model for message passing and learning. Finally, OFA will perform a two-classification task on each category node, and select the category node with the highest probability as the final prediction result. Since category information exists in the cue subgraph, even if a completely new classification problem is encountered, OFA can directly predict without any fine-tuning by constructing the corresponding cue subgraph, thus achieving zero-shot learning. For a few-shot learning scenario, a classification task will include a query input graph and multiple support input graphs. OFA's prompt graph paradigm will associate the NOI prompt node of each support input graph with its corresponding category node. Connect, and at the same time connect the NOI prompt node of the query input graph to all category nodes. The subsequent prediction steps are consistent with those described above. In this way, each category node will receive additional information from the support input graph, thereby achieving few-shot learning under a unified paradigm. The main contributions of OFA are summarized as follows: Unified graph data distribution: By proposing text graphs and using LLM to transform text information, OFA achieves distribution alignment and unification of graph data. Uniform graph task form: Through NOI subgraphs and NOI prompt nodes, OFA achieves a unified representation of subtasks in various graph fields. Unified graph prompting paradigm: By proposing a novel graph prompting paradigm, OFA realizes multi-scenario in-context learning in the graph field. The article tested the OFA framework on 9 collected data sets. These tests covered ten different tasks in supervised learning scenarios. Including node prediction, link prediction and graph classification. The purpose of the experiment is to verify the ability of a single OFA model to handle multiple tasks, in which the author compares the use of different LLM (OFA-{LLM}) and training a separate model for each task (OFA-ind-{LLM}) effect. The comparison results are shown in the following table: It can be seen that based on OFA’s powerful generalization ability, a separate graph model (OFA -st, OFA-e5, OFA-llama2-7b, OFA-llama2-13b) That is, it can have the same traditional separate training model on all tasks (GCN, GAT, OFA-ind-st ) Similar or better performance. At the same time, using a more powerful LLM can bring certain performance improvements. The article further plots the representation of NOI prompt nodes for different tasks by the trained OFA model. It can be seen that different tasks are embedded into different subspaces by the model, so that OFA can learn different tasks separately without affecting each other. In the scenario of few samples and zero samples, OFA is used in ogbn-arxiv (reference graph) , FB15K237 (knowledge graph) and Chemble ( Use a single model to pre-train on molecular graphs), and test its performance on different downstream tasks and data sets. The results are as follows: It can be seen that even in the zero-sample scenario, OFA can still achieve good results. Taken together, the experimental results well verify the powerful general performance of OFA and its potential as a basic model in the graph field. For more research details, please refer to the original paper. Address: https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/ LechengKong/OneForAll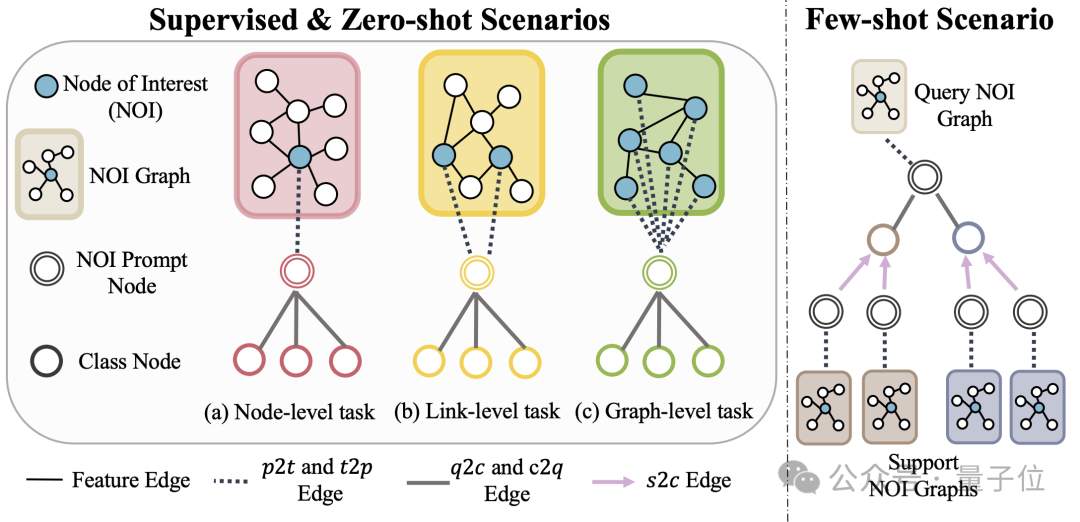
Super Generalization Ability
The above is the detailed content of The first universal framework in the graph field is here! Selected into ICLR\'24 Spotlight, any data set and classification problem can be solved. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
Unfortunately, people often delete certain contacts accidentally for some reasons. WeChat is a widely used social software. To help users solve this problem, this article will introduce how to retrieve deleted contacts in a simple way. 1. Understand the WeChat contact deletion mechanism. This provides us with the possibility to retrieve deleted contacts. The contact deletion mechanism in WeChat removes them from the address book, but does not delete them completely. 2. Use WeChat’s built-in “Contact Book Recovery” function. WeChat provides “Contact Book Recovery” to save time and energy. Users can quickly retrieve previously deleted contacts through this function. 3. Enter the WeChat settings page and click the lower right corner, open the WeChat application "Me" and click the settings icon in the upper right corner to enter the settings page.
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
The familiar open source large language models such as Llama3 launched by Meta, Mistral and Mixtral models launched by MistralAI, and Jamba launched by AI21 Lab have become competitors of OpenAI. In most cases, users need to fine-tune these open source models based on their own data to fully unleash the model's potential. It is not difficult to fine-tune a large language model (such as Mistral) compared to a small one using Q-Learning on a single GPU, but efficient fine-tuning of a large model like Llama370b or Mixtral has remained a challenge until now. Therefore, Philipp Sch, technical director of HuggingFace
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
