
 Technology peripherals
AI
Without dividing it into tokens, learn directly from bytes efficiently. Mamba can also be used in this way.
Technology peripherals
AI
Without dividing it into tokens, learn directly from bytes efficiently. Mamba can also be used in this way.
Without dividing it into tokens, learn directly from bytes efficiently. Mamba can also be used in this way.

When defining a language model, basic word segmentation methods are often used to divide sentences into words, subwords or characters. Subword segmentation has long been the most popular choice because it strikes a balance between training efficiency and the ability to handle words outside the vocabulary. However, some studies have pointed out problems with subword segmentation, such as lack of robustness to the handling of typos, spelling and case changes, and morphological changes. Therefore, these issues need to be carefully considered in the design of language models to improve the accuracy and robustness of the model.
Therefore, some researchers have chosen an approach that uses byte sequences, that is, through end-to-end mapping of raw data to prediction results, without any word segmentation. Compared with sub-word models, byte-level language models are easier to generalize to different writing forms and morphological changes. However, modeling text as bytes means that the generated sequences are longer than the corresponding subwords. In order to improve efficiency, it needs to be achieved by improving the architecture.
Autoregressive Transformer occupies a dominant position in language modeling, but its efficiency problem is particularly prominent. Its computational cost increases quadratically as the sequence length increases, resulting in poor scalability for long sequences. To solve this problem, the researchers compressed the Transformer’s internal representation in order to handle long sequences. One such approach is the development of a length-aware modeling approach that merges groups of tokens within an intermediate layer, thereby reducing computational cost. Recently, Yu et al. proposed a method called MegaByte Transformer. It uses fixed-size byte fragments to simulate compressed forms as subwords, thus reducing computational cost. However, this may not be the best solution at present and requires further research and improvement.
In a latest study, scholars at Cornell University introduced an efficient and simple byte-level language model called MambaByte. This model is derived from a direct improvement of the recently introduced Mamba architecture. The Mamba architecture is built on the state space model (SSM) method, while MambaByte introduces a more efficient selection mechanism, making it perform better when processing discrete data such as text, and also provides an efficient GPU implementation. The researchers briefly observed using unmodified Mamba and found that it was able to alleviate a major computational bottleneck in language modeling, thereby eliminating the need for patches and making full use of available computational resources.

- ##Paper title: MambaByte: Token-free Selective State Space Model
- Paper link: https://arxiv.org/pdf/2401.13660.pdf
In the experiment , they compared MambaByte with Transformers, SSM, and MegaByte (patching) architectures. These architectures are evaluated under fixed parameter and computational settings and on multiple long-form text datasets. Figure 1 summarizes their main findings.
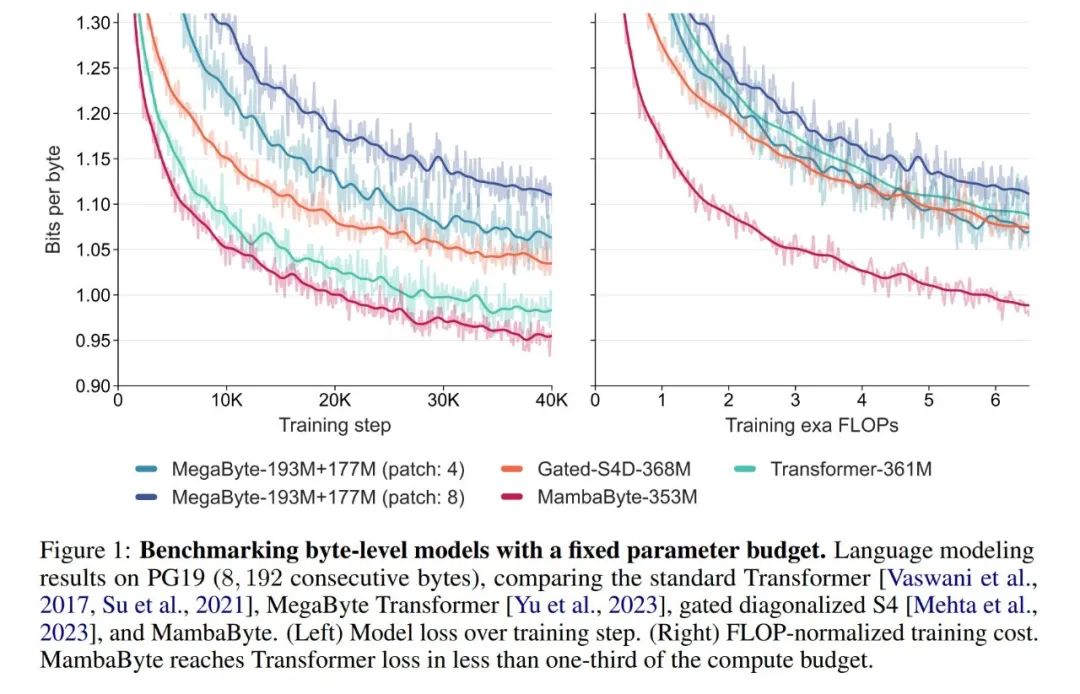
Compared with byte-level Transformers, MambaByte provides a faster and high-performance solution, while computing efficiency has also been significantly improved. . The researchers also compared token-free language models with current state-of-the-art subword models and found that MambaByte is competitive in this regard and can handle longer sequences. The results of this study show that MambaByte can be a powerful alternative to existing tokenizers that rely on them, and is expected to promote the further development of end-to-end learning.
Background: Selective State Space Sequence Model
SSM models the temporal evolution of hidden states using first-order differential equations. Linear time-invariant SSM has shown good results in a variety of deep learning tasks. However, recently Mamba authors Gu and Dao argued that the constant dynamics of these methods lack input-dependent context selection in hidden states, which may be necessary for tasks such as language modeling. Therefore, they proposed the Mamba method, which is dynamically defined by taking a given input x(t) ∈ R, hidden state h(t) ∈ R^n, and output y(t) ∈ R as a time-varying continuous state at time t is:
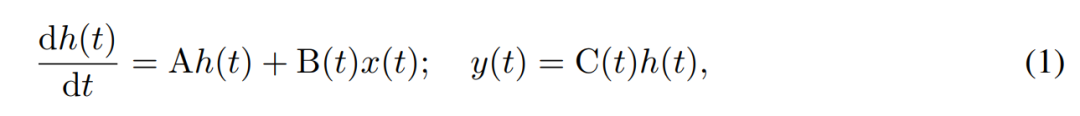
Its parameters are the diagonal time-invariant system matrix A∈R^(n×n), and Time-varying input and output matrices B (t)∈R^(n×1) and C (t)∈R^(1×n).
To model discrete time series such as bytes, the continuous time dynamics in (1) must be approximated through discretization. This produces a discrete-time latent recurrence, with new matrices A, B and C at each time step, i.e.
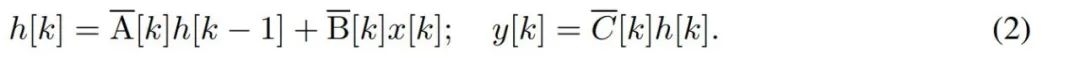
Please note that ( 2) Similar to a linear version of a recurrent neural network, it can be applied in this recurrent form during language model generation. The discretization requires that each input position has a time step, that is, Δ[k], corresponding to x [k] = x (t_k) of 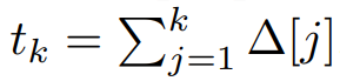 . The discrete-time matrices A, B and C can then be calculated from Δ[k]. Figure 2 shows how Mamba models discrete sequences.
. The discrete-time matrices A, B and C can then be calculated from Δ[k]. Figure 2 shows how Mamba models discrete sequences.
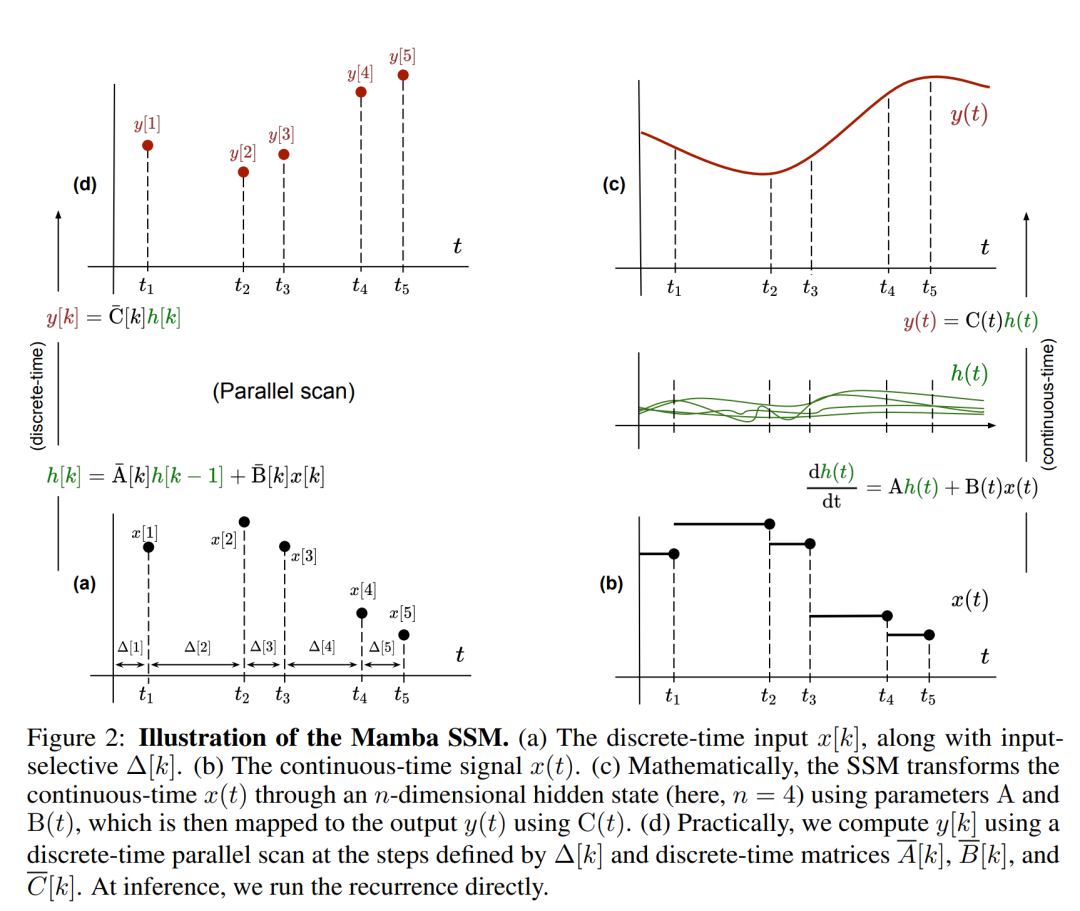
In Mamba, the SSM term is input selective, that is, B, C and Δ are defined as the input x [k]∈R^ Function of d:
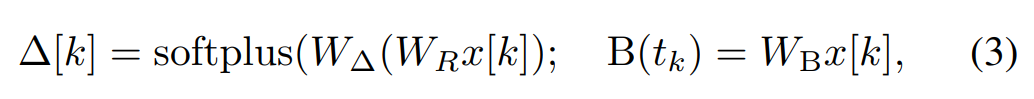
where W_B ∈ R^(n×d) (the definition of C is similar), W_Δ ∈ R^(d×r) and W_R ∈ R^(r×d) (for some r ≪d) are learnable weights, while softplus ensures positivity. Note that for each input dimension d, the SSM parameters A, B, and C are the same, but the number of time steps Δ is different; this results in a hidden state size of n × d for each time step k.
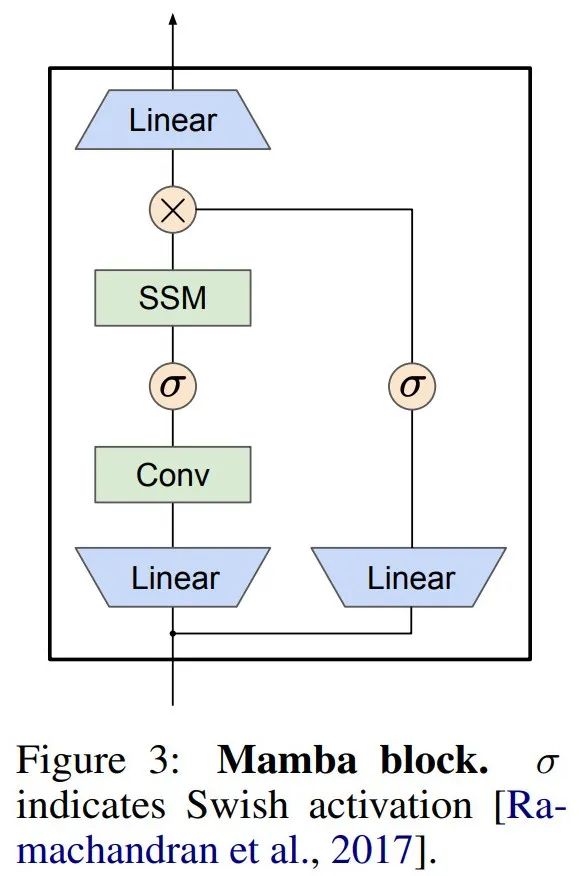
Mamba embeds this SSM layer into a complete neural network language model. Specifically, the model employs a series of gating layers inspired by previous gated SSMs. Figure 3 shows the Mamba architecture that combines SSM layers with gated neural networks.
Parallel scan of linear recurrence. At training time, the authors have access to the entire sequence x, allowing more efficient calculation of linear recurrence. Research by Smith et al. [2023] demonstrates that sequential recurrence in linear SSM can be efficiently calculated using efficient parallel scans. For Mamba, the author first maps recurrence to L tuple sequences, where e_k = , and then defines an association operator
, and then defines an association operator  such that
such that 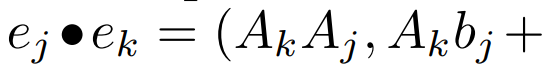
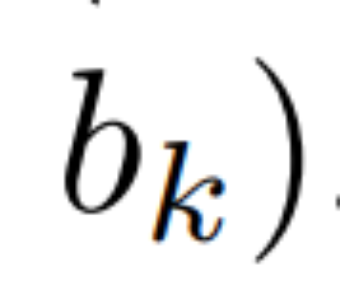 . Finally, they applied a parallel scan to compute the sequence
. Finally, they applied a parallel scan to compute the sequence 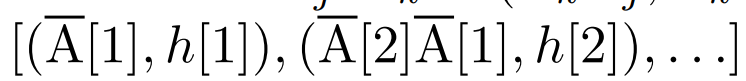 . In general, this takes
. In general, this takes 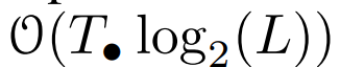 time, using L/2 processors, where
time, using L/2 processors, where 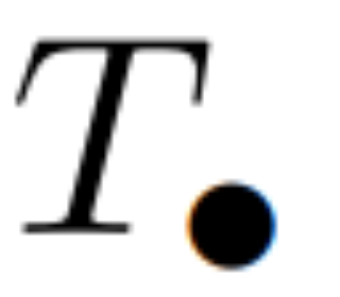 is the cost of the matrix multiplication. Note that A is a diagonal matrix and linear recurrence can be computed in parallel in
is the cost of the matrix multiplication. Note that A is a diagonal matrix and linear recurrence can be computed in parallel in 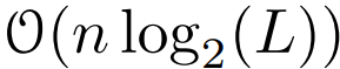 time and O (nL) space. Parallel scans using diagonal matrices also run very efficiently, requiring only O (nL) FLOPs.
time and O (nL) space. Parallel scans using diagonal matrices also run very efficiently, requiring only O (nL) FLOPs.
Experimental results
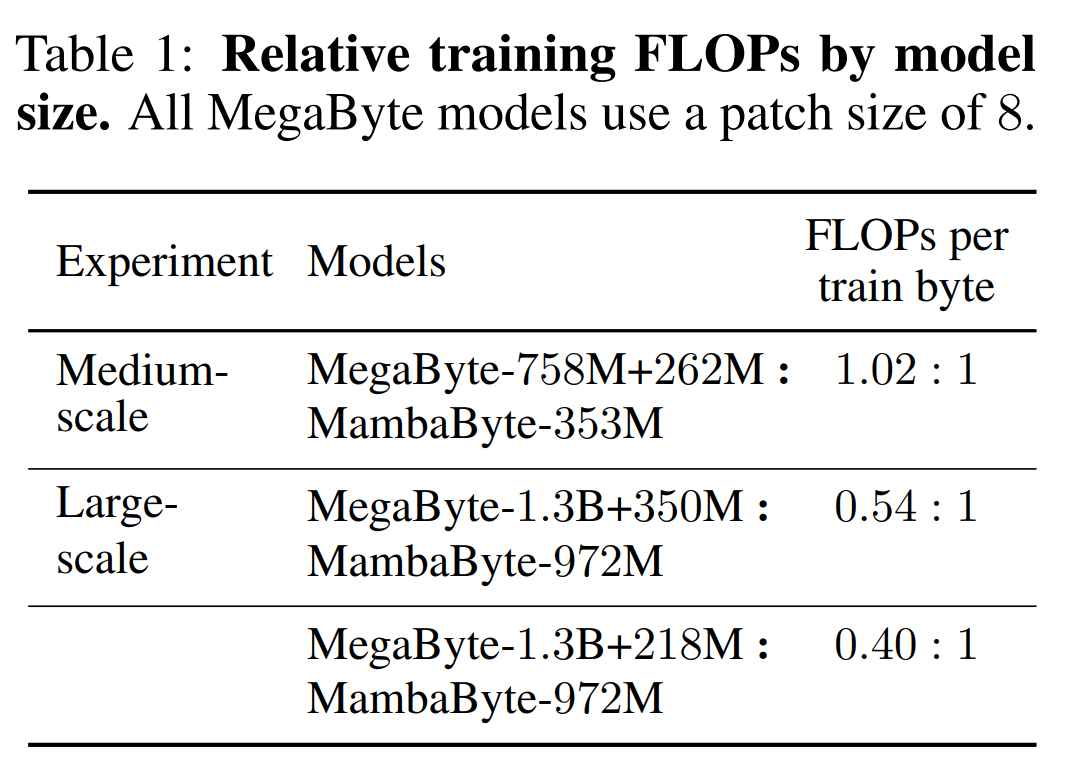
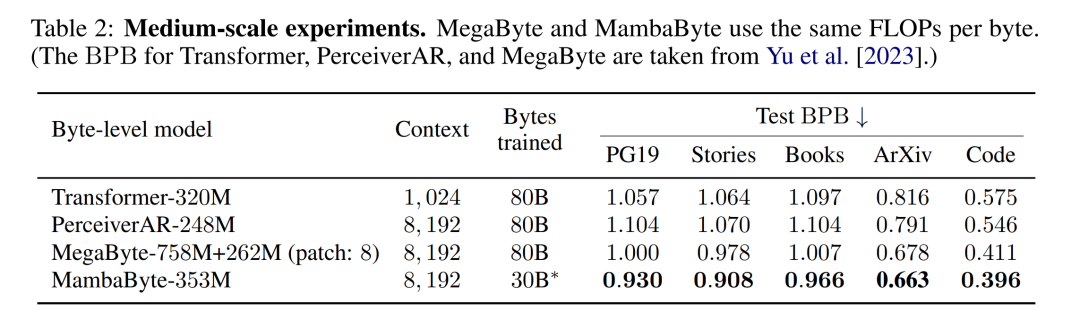
Table 2 shows the bits per byte (BPB) for each dataset. In this experiment, the MegaByte758M 262M and MambaByte models used the same number of FLOPs per byte (see Table 1). The authors found that MambaByte consistently outperformed MegaByte on all datasets. Additionally, the authors note that due to funding constraints they were unable to train MambaByte on the full 80B bytes, but MambaByte still outperformed MegaByte with 63% less computation and 63% less training data. Additionally, MambaByte-353M outperforms byte-scale Transformer and PerceiverAR.
##In so few training steps, why is MambaByte better than Does a much larger model perform better? Figure 1 further explores this relationship by looking at models with the same number of parameters. The figure shows that for MegaByte models of the same parameter size, the model with less input patching performs better, but after calculating normalization, they perform similarly. In fact, the full-length Transformer, while slower in absolute terms, also performs similarly to MegaByte after computational normalization. In contrast, switching to the Mamba architecture can significantly improve computational usage and model performance.
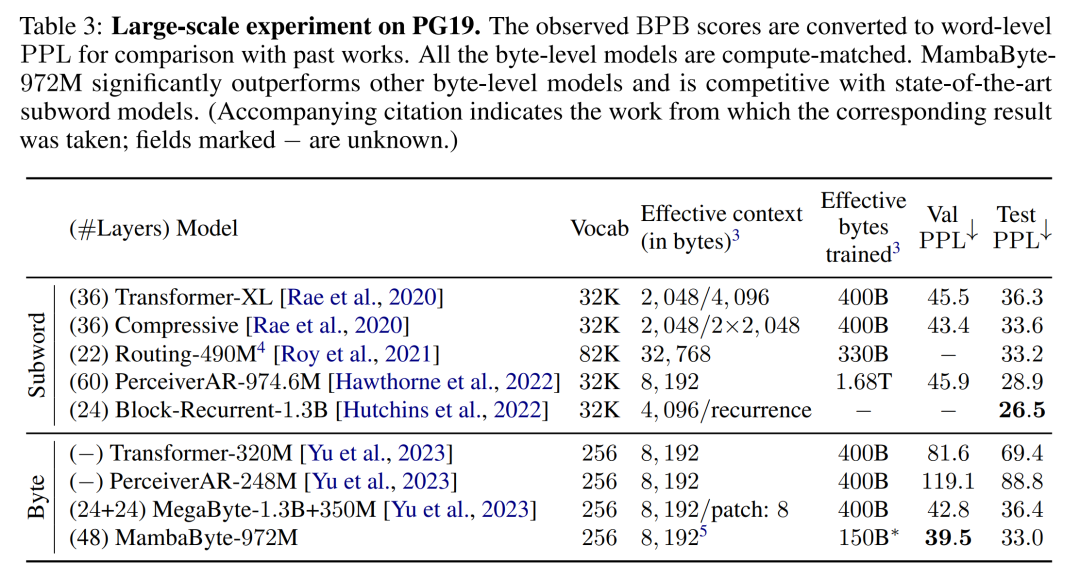
Based on these findings, Table 3 compares larger versions of these models on the PG19 dataset. In this experiment, the authors compared MambaByte-972M with MegaByte-1.3B 350M and other byte-level models as well as several SOTA subword models. They found that MambaByte-972M outperformed all byte-level models and was competitive with subword models even when trained on only 150B bytes.
Text generation. Autoregressive inference in Transformer models requires caching the entire context, which significantly affects generation speed. MambaByte does not have this bottleneck because it retains only one time-varying hidden state per layer, so the time per generation step is constant. Table 4 compares text generation speeds of MambaByte-972M and MambaByte-1.6B with MegaByte-1.3B 350M on an A100 80GB PCIe GPU. Although MegaByte greatly reduces the generation cost through patching, they observed that MambaByte is 2.6 times faster under similar parameter settings due to the use of loop generation.

The above is the detailed content of Without dividing it into tokens, learn directly from bytes efficiently. Mamba can also be used in this way.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
When installing PyTorch on CentOS system, you need to carefully select the appropriate version and consider the following key factors: 1. System environment compatibility: Operating system: It is recommended to use CentOS7 or higher. CUDA and cuDNN:PyTorch version and CUDA version are closely related. For example, PyTorch1.9.0 requires CUDA11.1, while PyTorch2.0.1 requires CUDA11.3. The cuDNN version must also match the CUDA version. Before selecting the PyTorch version, be sure to confirm that compatible CUDA and cuDNN versions have been installed. Python version: PyTorch official branch
