

Things about Linux byte alignment

Recently, I was working on a project and encountered a problem. When ThreadX running on ARM communicates with the DSP, it uses a message queue to deliver messages (the final implementation uses interrupts and shared memory methods). However, during actual operation, it was found that ThreadX often crashed. After investigation, it was found that the problem lies in the fact that the structure passing the message does not consider byte alignment.
I would like to sort out the issues about byte alignment in C language and share them with you.
1. Concept
Byte alignment is related to the location of data in memory. If the memory address of a variable is exactly an integer multiple of its length, then it is said to be naturally aligned. For example, under a 32-bit CPU, assuming the address of an integer variable is 0x00000004, then it is naturally aligned.
First understand what bits, bytes and words are
| name | English name | meaning |
|---|---|---|
| Bit | bit | 1 binary bit is called 1 bit |
| byte | Byte | 8 binary bits are called 1 Byte |
| Character | word | A fixed length used by computers to process transactions at one time |
Word length
The number of bits in a word, the word length of modern computers is usually 16, 32, or 64 bits. (Generally, the word length of N-bit systems is N/8 bytes.)
Different CPUs can process different number of data bits at a time. A 32-bit CPU can process 32-bit data at a time, and a 64-bit CPU can process 64-bit data at a time. The bits here refer to the word length.
The so-called word length is sometimes called word. In a 16-bit CPU, a word is exactly two bytes, while in a 32-bit CPU, a word is four bytes. If we take characters as units, there are double characters (two characters) and quad characters (four characters) upwards.
2. Alignment rules
For standard data types, its address only needs to be an integer multiple of its length. Non-standard data types are aligned according to the following principles: Array: Aligned according to basic data types. The first one is aligned with the following ones. It's aligned. Union: Aligned by the data type it contains with the largest length. Structure: Each data type in the structure must be aligned.
3. How to limit the number of byte alignments?
1. Default
By default, the C compiler allocates space for each variable or data unit according to its natural boundary conditions. Generally, the default boundary conditions can be changed by the following methods:
2. #pragma pack(n)
· Using the #pragma pack (n) directive, the C compiler will align by n bytes. · Use the directive #pragma pack () to cancel the custom byte alignment.
#pragma pack(n) is used to set variables to n-byte alignment. n-byte alignment means that there are two situations for the offset of the starting address where the variable is stored:
- If n is greater than or equal to the number of bytes occupied by the variable, then the offset must meet the default alignment
- If n is less than the number of bytes occupied by the variable's type, the offset is a multiple of n and does not need to meet the default alignment.
The total size of the structure also has a constraint. If n is greater than or equal to the number of bytes occupied by all member variable types, then the total size of the structure must be the number of spaces occupied by the variable that occupies the largest space. Multiple; otherwise it must be a multiple of n.
3. __attribute
In addition, there is the following method: · __attribute((aligned (n))), which aligns the structure members being acted on on the natural boundary of n bytes. If the length of any member in the structure is greater than n, it is aligned according to the length of the largest member. · attribute ((packed)), cancels the optimization alignment of the structure during compilation, and aligns it according to the actual number of bytes occupied.
3. Assembly.align
Assembly code usually uses .align to specify the number of byte alignment bits.
.align: used to specify the alignment of data, the format is as follows:
.align [absexpr1, absexpr2]
Fill the unused storage area with values in a certain alignment. The first value represents the alignment, 4, 8, 16 or 32. The second expression value represents the filled value.
四、为什么要对齐?
操作系统并非一个字节一个字节访问内存,而是按2,4,8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,IO的数据长度通常是字长。如32位系统访问粒度是4字节(bytes), 64位系统的是8字节。当被访问的数据长度为n字节且该数据地址为n字节对齐时,那么操作系统就可以高效地一次定位到数据, 无需多次读取,处理对齐运算等额外操作。数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU需要做两次内存访问。
字节对齐可能带来的隐患:
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678; unsigned char *p=NULL; unsigned short *p1=NULL; p=&i; *p=0x00; p1=(unsigned short *)(p+1); *p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
五、举例
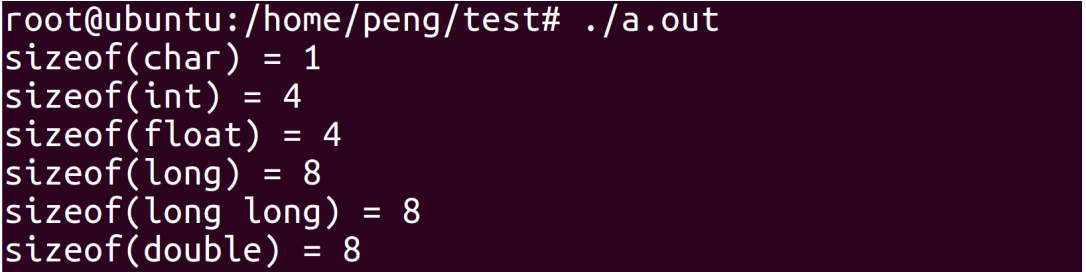
例1:os基本数据类型占用的字节数
首先查看操作系统的位数
在64位操作系统下查看基本数据类型占用的字节数:
#include
int main()
{
printf("sizeof(char) = %ld\n", sizeof(char));
printf("sizeof(int) = %ld\n", sizeof(int));
printf("sizeof(float) = %ld\n", sizeof(float));
printf("sizeof(long) = %ld\n", sizeof(long));
printf("sizeof(long long) = %ld\n", sizeof(long long));
printf("sizeof(double) = %ld\n", sizeof(double));
return 0;
}
例2:结构体占用的内存大小–默认规则
考虑下面的结构体占用的位数
struct yikou_s
{
double d;
char c;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 16
在内容中各变量位置关系如下:
其中成员C的位置
还受字节序的影响,有的可能在位置8
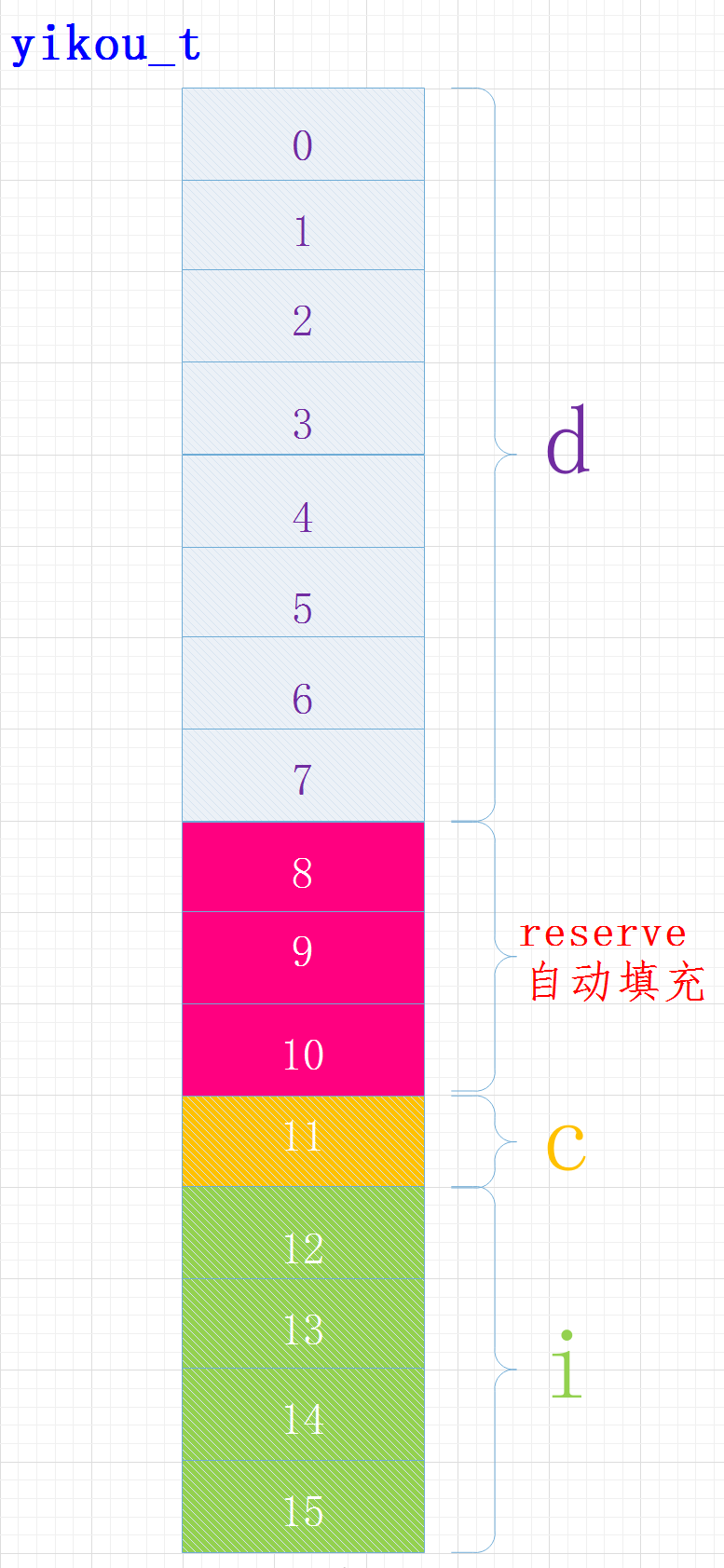 还受字节序的影响,有的可能在位置8
还受字节序的影响,有的可能在位置8编译器给我们进行了内存对齐,各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量类型所占用的字节数的倍数, 且结构的大小为该结构中占用最大空间的类型所占用的字节数的倍数。
对于偏移量:变量type n起始地址相对于结构体起始地址的偏移量必须为sizeof(type(n))的倍数结构体大小:必须为成员最大类型字节的倍数
char: 偏移量必须为sizeof(char) 即1的倍数 int: 偏移量必须为sizeof(int) 即4的倍数 float: 偏移量必须为sizeof(float) 即4的倍数 double: 偏移量必须为sizeof(double) 即8的倍数
例3:调整结构体大小
我们将结构体中变量的位置做以下调整:
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 24
各变量在内存中布局如下:
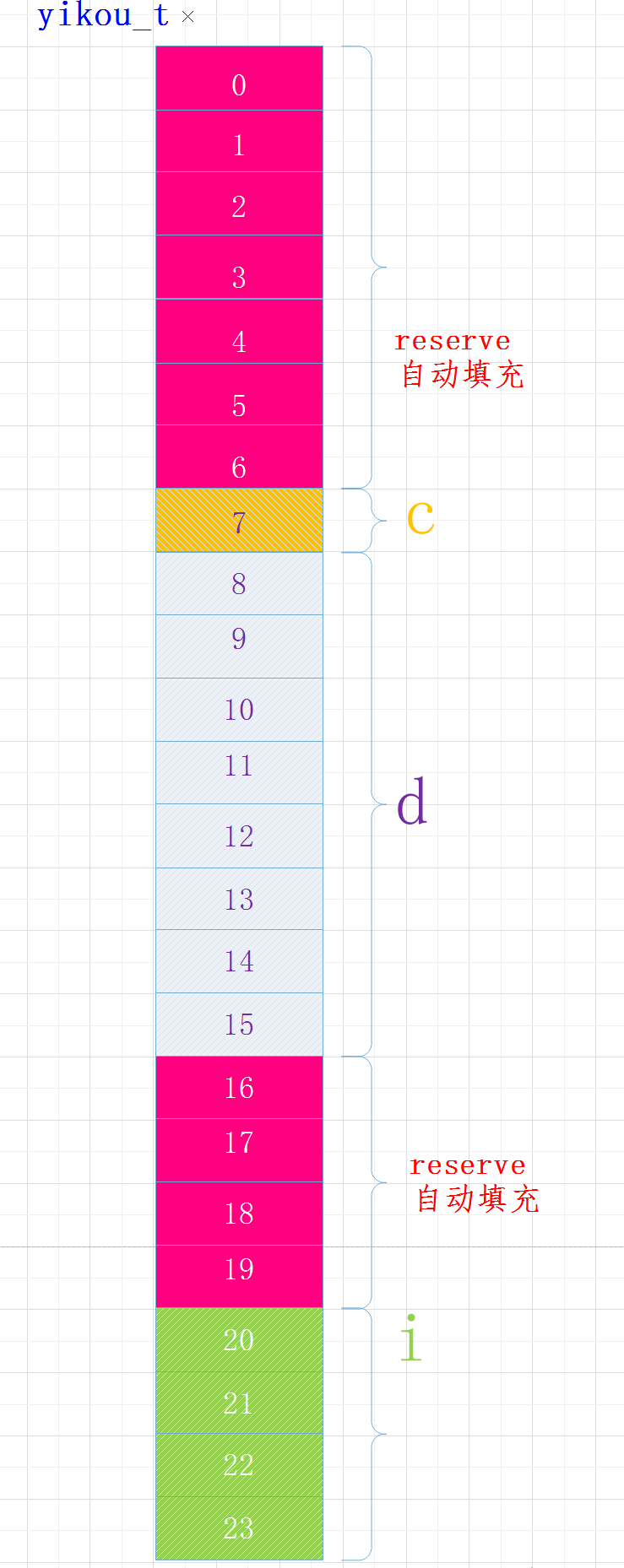
当结构体中有嵌套符合成员时,复合成员相对于结构体首地址偏移量是复合成员最宽基本类型大小的整数倍。
例4:#pragma pack(4)
#pragma pack(4)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 16
例5:#pragma pack(8)
#pragma pack(8)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 24
例6:汇编代码
举例:以下是截取的uboot代码中异常向量irq、fiq的入口位置代码: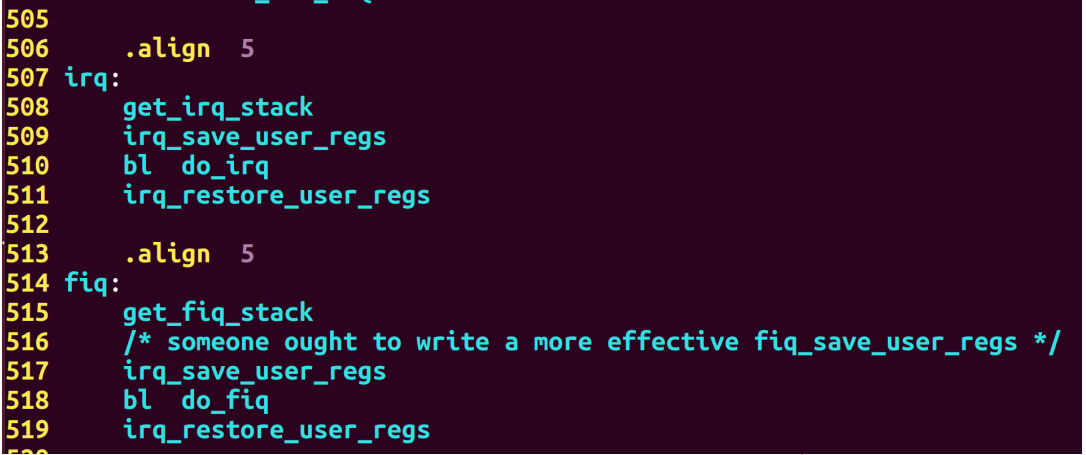
六、汇总实力
有手懒的同学,直接贴一个完整的例子给你们:
#include
main()
{
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
struct AA {
// int a;
char b;
short c;
};
struct BB {
char b;
// int a;
short c;
};
#pragma pack (2) /*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#pragma pack ()/*取消指定对齐,恢复缺省对齐*/
int s1=sizeof(struct A);
int s2=sizeof(struct AA);
int s3=sizeof(struct B);
int s4=sizeof(struct BB);
int s5=sizeof(struct C);
int s6=sizeof(struct D);
printf("%d\n",s1);
printf("%d\n",s2);
printf("%d\n",s3);
printf("%d\n",s4);
printf("%d\n",s5);
printf("%d\n",s6);
}
The above is the detailed content of Things about Linux byte alignment. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
Using python in Linux terminal...
 Four ways to implement multithreading in C language
Apr 03, 2025 pm 03:00 PM
Four ways to implement multithreading in C language
Apr 03, 2025 pm 03:00 PM
Multithreading in the language can greatly improve program efficiency. There are four main ways to implement multithreading in C language: Create independent processes: Create multiple independently running processes, each process has its own memory space. Pseudo-multithreading: Create multiple execution streams in a process that share the same memory space and execute alternately. Multi-threaded library: Use multi-threaded libraries such as pthreads to create and manage threads, providing rich thread operation functions. Coroutine: A lightweight multi-threaded implementation that divides tasks into small subtasks and executes them in turn.
 How to open web.xml
Apr 03, 2025 am 06:51 AM
How to open web.xml
Apr 03, 2025 am 06:51 AM
To open a web.xml file, you can use the following methods: Use a text editor (such as Notepad or TextEdit) to edit commands using an integrated development environment (such as Eclipse or NetBeans) (Windows: notepad web.xml; Mac/Linux: open -a TextEdit web.xml)
 Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Regarding the problem of removing the Python interpreter that comes with Linux systems, many Linux distributions will preinstall the Python interpreter when installed, and it does not use the package manager...
 What is the Linux best used for?
Apr 03, 2025 am 12:11 AM
What is the Linux best used for?
Apr 03, 2025 am 12:11 AM
Linux is best used as server management, embedded systems and desktop environments. 1) In server management, Linux is used to host websites, databases, and applications, providing stability and reliability. 2) In embedded systems, Linux is widely used in smart home and automotive electronic systems because of its flexibility and stability. 3) In the desktop environment, Linux provides rich applications and efficient performance.
 How is Debian Hadoop compatibility
Apr 02, 2025 am 08:42 AM
How is Debian Hadoop compatibility
Apr 02, 2025 am 08:42 AM
DebianLinux is known for its stability and security and is widely used in server, development and desktop environments. While there is currently a lack of official instructions on direct compatibility with Debian and Hadoop, this article will guide you on how to deploy Hadoop on your Debian system. Debian system requirements: Before starting Hadoop configuration, please make sure that your Debian system meets the minimum operating requirements of Hadoop, which includes installing the necessary Java Runtime Environment (JRE) and Hadoop packages. Hadoop deployment steps: Download and unzip Hadoop: Download the Hadoop version you need from the official ApacheHadoop website and solve it
 Do I need to install an Oracle client when connecting to an Oracle database using Go?
Apr 02, 2025 pm 03:48 PM
Do I need to install an Oracle client when connecting to an Oracle database using Go?
Apr 02, 2025 pm 03:48 PM
Do I need to install an Oracle client when connecting to an Oracle database using Go? When developing in Go, connecting to Oracle databases is a common requirement...
 Is Debian Strings compatible with multiple browsers
Apr 02, 2025 am 08:30 AM
Is Debian Strings compatible with multiple browsers
Apr 02, 2025 am 08:30 AM
"DebianStrings" is not a standard term, and its specific meaning is still unclear. This article cannot directly comment on its browser compatibility. However, if "DebianStrings" refers to a web application running on a Debian system, its browser compatibility depends on the technical architecture of the application itself. Most modern web applications are committed to cross-browser compatibility. This relies on following web standards and using well-compatible front-end technologies (such as HTML, CSS, JavaScript) and back-end technologies (such as PHP, Python, Node.js, etc.). To ensure that the application is compatible with multiple browsers, developers often need to conduct cross-browser testing and use responsiveness
