
 Technology peripherals
AI
Stanford and OpenAI proposed meta-prompting, and the strongest zero-sample prompting technology was born.
Technology peripherals
AI
Stanford and OpenAI proposed meta-prompting, and the strongest zero-sample prompting technology was born.
Stanford and OpenAI proposed meta-prompting, and the strongest zero-sample prompting technology was born.

The latest generation of language models (such as GPT-4, PaLM and LLaMa) have made important breakthroughs in natural language processing and generation. These large-scale models are capable of tasks ranging from writing Shakespearean sonnets to summarizing complex medical reports and even solving competition-level programming problems. While these models are capable of solving a diverse range of problems, they are not always correct. Sometimes they may generate inaccurate, misleading, or contradictory response results. Therefore, when using these models, care still needs to be taken to evaluate and verify the accuracy and reliability of their outputs.
As the cost of running models decreases, people are beginning to consider using scaffolding systems and multi-language model queries to improve the accuracy and stability of model output. This approach optimizes model performance and provides a better experience for users.
This research from Stanford and OpenAI proposes a new technology that can be used to improve the power and performance of language models called meta-prompting.

- Paper title: Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
- Paper address: https://arxiv.org/abs/2401.12954
- Project address: https://github.com/suzgunmirac/meta-prompting
This technology involves building a high-level "meta" prompt, which The function is to instruct the language model to do the following:
1. Decompose complex tasks or problems into smaller sub-tasks that are easy to solve;
2. Assign these subtasks to specialized "expert" models using appropriate and detailed natural language instructions;
3. Supervise the communication between these expert models;
4. Apply their own critical thinking, reasoning, and verification skills through this process.
For a language model that can be effectively called using meta-prompting, the model acts as a conductor when queried. It outputs a message history (or narrative) consisting of responses from multiple expert models. This language model is first responsible for generating the commander part of the message history, which includes the selection of experts and the construction of specific instructions for them. However, the same language model also acts as an independent expert in its own right, generating output based on expertise and information selected by the commander for each specific query.
This approach allows a single unified language model to maintain a coherent line of reasoning while also leveraging a variety of expert roles. By dynamically selecting context for prompting, these experts can bring a fresh perspective to the process, while the commander model maintains a bird's-eye view of the complete history and maintains coordination.
Therefore, this approach allows a single black box language model to effectively serve as both a central commander and a series of different experts, resulting in more accurate, reliable and consistent response.
The newly proposed meta-prompting technology here combines and expands a variety of different prompting ideas proposed in recent research, including high-level planning and decision-making, dynamic personality allocation, and multi-agent Debate, self-debug and self-reflection.
A key aspect of meta-prompting is its property of being task-agnostic.
Unlike traditional scaffolding methods that require specific instructions or examples to be tailored to each task, meta-prompting uses the same high-level hierarchy across multiple tasks and inputs. instruction. This versatility is especially beneficial for trouble-shy users, since it eliminates the need to provide detailed examples or specific instructions for each specific task.
For example, for a one-time request like "Write a Shakespearean sonnet about taking a selfie," users don't need to supplement it with high-quality examples of neoclassical poetry.
meta-prompting methods can improve the usefulness of language models by providing a broad and flexible framework without compromising their specificity or relevance. In addition, to demonstrate the versatility and integration capabilities of the meta-prompting method, the team also enhanced its system so that it can call the Python interpreter. This will allow the technology to support more dynamic and comprehensive applications, further increasing its potential to efficiently handle a wide range of tasks and queries.
Figure 2 shows an example of a meta-prompting conversation flow.
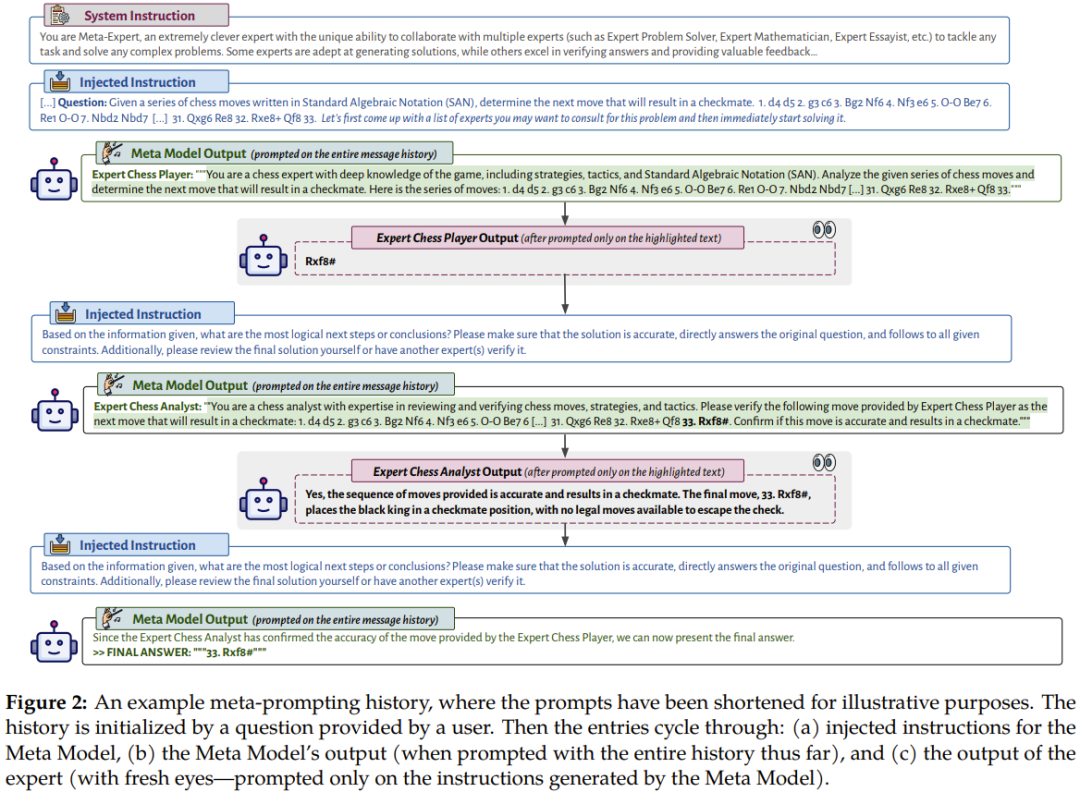
It depicts the Meta Model (Commander Model) using input and execution from multiple different professional expert models or codes Output is the process of interpreting its own output. This configuration makes meta-prompting a nearly universal tool. It allows the interactions and computations of multiple language models to be aggregated into a single and coherent narrative. Meta-prompting is different in that it lets the language model decide for itself which prompts to use or which snippets to use.
The team conducted comprehensive experiments using GPT-4 as the base language model, comparing meta-prompting with other task-independent scaffolding methods.
Experiments have found that meta-prompting can not only improve overall performance, but also often achieve new best results on multiple different tasks. Its flexibility is particularly noteworthy: the commander model has the ability to call on the expert model (which is basically itself, with different instructions) to perform a variety of different functions. These functions may include reviewing previous output, choosing a specific AI persona for a specific task, optimizing the generated content, and ensuring that the final output meets required standards in both substance and form.
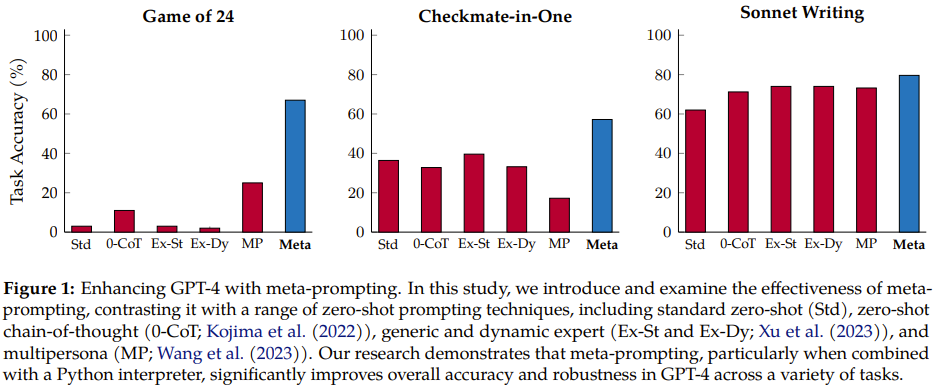
As shown in Figure 1, compared with the previous methods, the new method has obvious improvements.
meta-prompting
Intuitive knowledge and abstract overview. Meta-prompting works by using a model to coordinate and execute multiple independent queries, then combining their responses to render a final response. In principle, this mechanism adopts an integrated approach that borrows the power and diversity of independent professional models to collaboratively solve and handle multi-faceted tasks or problems.
The core of the meta-prompting strategy is its shallow structure, which uses a single model (called the metamodel) as the authoritative master entity.
This prompting structure is similar to an orchestra, in which the role of the conductor is played by a meta-model, and each musical player corresponds to a different domain-specific model. Just as a conductor can coordinate multiple instruments to play a harmonious melody, a metamodel can combine answers and insights from multiple models to provide accurate and comprehensive answers to complex questions or tasks.
Conceptually, within this framework, domain-specific experts can take many forms, such as language models fine-tuned for specific tasks, used to handle specific types of queries A dedicated API, or even a calculation tool like a calculator or a coding tool like a Python interpreter for executing code. These functionally diverse experts are instructed and unified under the supervision of the meta-model and cannot directly interact or communicate with each other.
Algorithmic Procedure. Algorithm 1 gives the pseudocode of the newly proposed meta-prompting method.

To briefly summarize, the first step is to transform the input so that it conforms to the appropriate template; then the following loop is executed: (a) to the meta model Submit the prompt, (b) use domain-specific expert models if necessary, (c) return a final response, (d) handle errors.
It should be pointed out that the meta-model and expert model used by the team in the experiment are both GPT-4. The difference in their roles is determined by the instructions each receives; where the meta-model follows the set of instructions provided in Figure 3, and the expert model follows the instructions dynamically determined by the meta-model at inference time.

Experimental setup
Benchmark
##The team compared meta-prompting with the following prompting methods Irrelevant task-type zero-sample version:
- ##Standard prompting
- Zero-sample thinking chain prompting
- Expert prompting
- Multiplayer prompting
The team used a variety of tasks and data sets in their experiments that require a variety of different abilities, such as mathematical and algorithmic reasoning, domain-specific knowledge, and literary creativity. These datasets and tasks include:
Game of 24: The goal is to use four given values (each can only be used once) to construct an arithmetic expression that results in 24 Mode.
- Three BIG-Bench Hard (BBH) tasks: Geometric Shapes, MultiStep Arithmetic Two and Word Sorting; there is also an inference task Checkmate-in taken directly from the BIG-Bench suite -One.
- Python Programming Puzzles (P3), which are Python programming questions, include multiple difficulties.
- Multilingual Grade School Math is a multilingual version of the GSM8K dataset that includes Bengali, Japanese, and Swahili.
- Shakespearean Sonnet Writing, a new task created by the team, aims to write ten sonnets that rhyme strictly with "ABAB CDCD EFEF GG" A four-line poem, which should contain the three words provided verbatim.
As shown in Figure 3, for the newly proposed meta- prompting method, system instructions will encourage the meta-model to give the final answer in a specific format.
As for evaluation, one of the following three indicators will be used, depending on the nature and form of the task:
Exact Match ( EM), Exact Match
- Soft Match (SM), Soft Match
- Functionally Correct (FC), Functional Correctness
The team’s main experiments all used GPT-4 (gpt-4-32k) . Some additional experiments used GPT-3.5 (gpt-35-turbo). Whether it is GPT-3.5 or GPT-4, the following instructions are used for fine-tuning.
In all experiments, the parameters and system instructions used by the meta-model are the same. The temperature value is set to 0, the top-p value is set to 0.95, and the maximum number of tokens is 1024.
Main Results and Discussion
Table 1 summarizes the experimental results, and the superiority of the newly proposed meta-prompting is reflected.
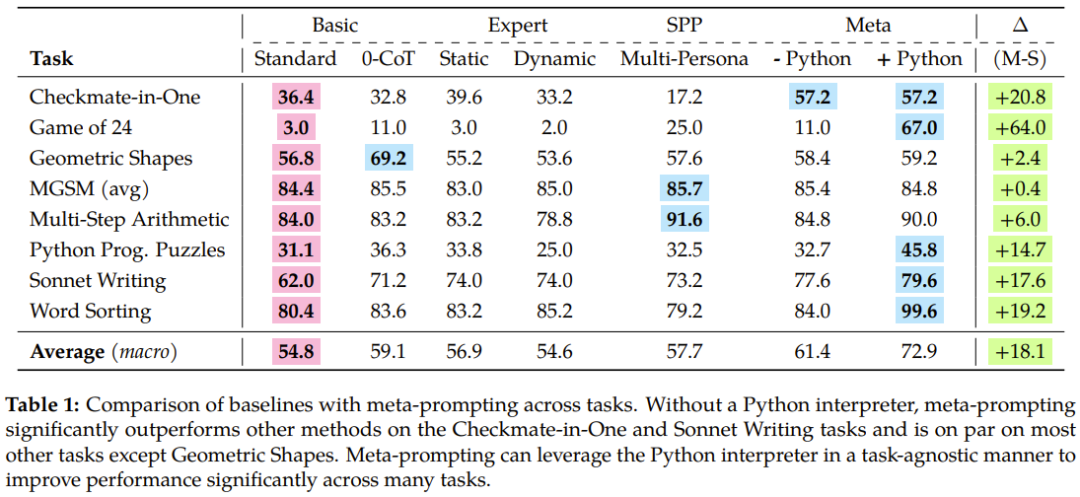 Looking at the overall performance of these methods on all tasks, we can see that meta-prompting brings significant improvements to accuracy, especially when using When assisted by the Python interpreter tool.
Looking at the overall performance of these methods on all tasks, we can see that meta-prompting brings significant improvements to accuracy, especially when using When assisted by the Python interpreter tool.
Specifically, the meta-prompting method outperforms the standard prompting method by 17.1%, exceeds expert (dynamic) prompting by 17.3%, and is also 15.2% better than multi-person prompting.
In addition, we can see from Figures 4 and 5 that compared to meta-prompting without using the Python interpreter, when integrating the Python interpreter, the overall performance on different tasks can be obtained 11.5% improvement.
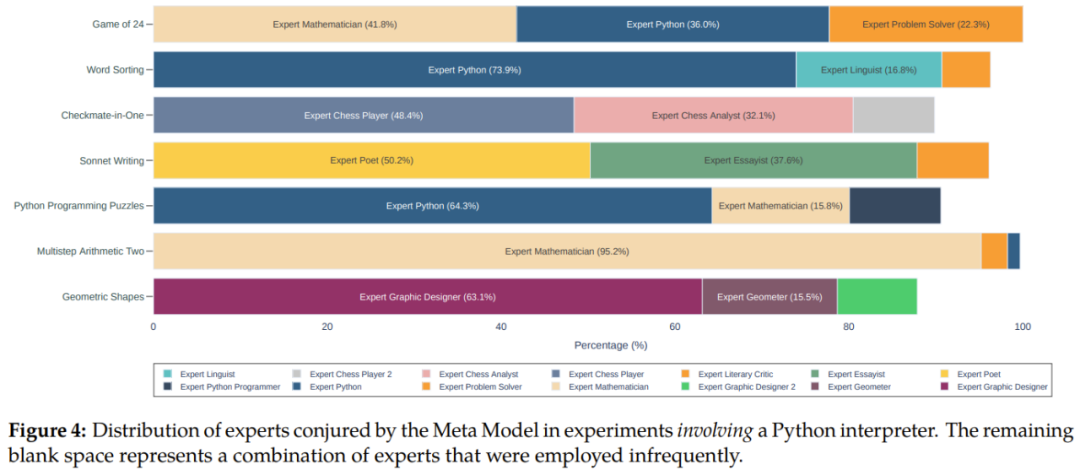
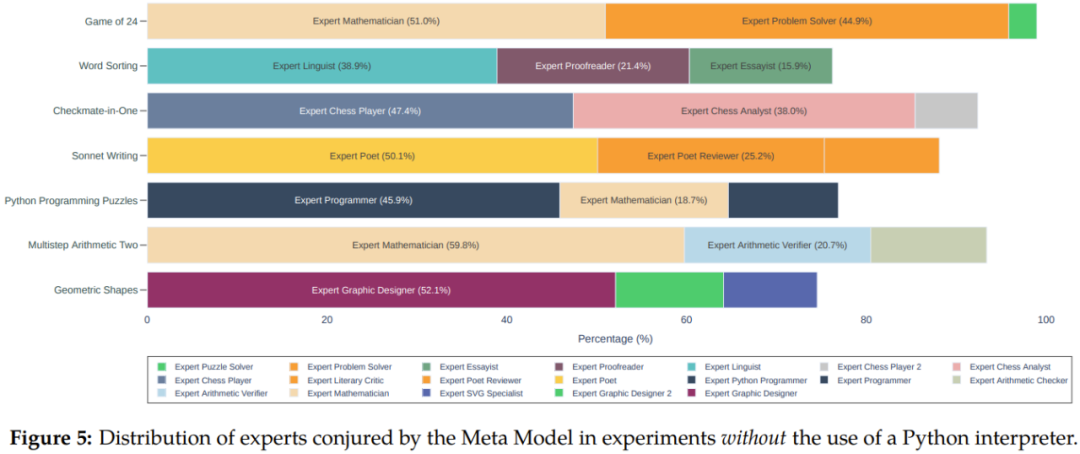 The team also discusses in depth in the paper key insights gained from the experiments, including meta- The performance superiority of prompting, zero-sample decomposition capability, error detection, information aggregation and code execution, etc. We won’t go into details here, but the concept of Fresh Eyes is worth introducing.
The team also discusses in depth in the paper key insights gained from the experiments, including meta- The performance superiority of prompting, zero-sample decomposition capability, error detection, information aggregation and code execution, etc. We won’t go into details here, but the concept of Fresh Eyes is worth introducing.
Fresh Eyes, or seeing with another pair of eyes, helps alleviate a well-known problem with language models: making mistakes goes all the way to the end and exhibits overconfidence.
Fresh Eyes is a key difference between meta-prompting and multiplayer prompting, and experimental results have also proven its advantages. In meta-prompting, experts (or personas) can be used to re-evaluate the problem. This approach offers the opportunity to gain new insights, potentially uncovering answers that have not been found to be incorrect before.
Based on cognitive psychology, Fresh Eyes can lead to more creative problem solving and error detection results.
The examples below demonstrate the benefits of Fresh Eyes in practice. Suppose the task is Game of 24. The values provided are 6, 11, 12, and 13. You are required to construct an arithmetic expression that results in 24 and use each number only once. Its history might look something like this:
1. The metamodel proposes consulting expert models that solve mathematical problems and programming in Python. It emphasizes the need for accuracy and compliance with constraints and recommends involving another expert if necessary.
#2. One expert gives a solution, but another expert thinks it is wrong, so the meta-model suggests writing a Python program to find a valid solution.
3. Consult a programming expert and ask him to write a program.
4. Another programming expert finds an error in the script, modifies it and executes the modified script.
5. Consult a math expert to verify the solution output by the program.
6. After the verification is completed, the meta-model will output it as the final answer.
This example shows how meta-prompting can incorporate new perspectives at every step, not only to find answers, but also to effectively identify and correct errors.
The team concluded by discussing some other issues related to meta-prompting, including an analysis of the type of experts used, the number of dialogue turns needed to get the final result, and how to deal with no Solving problems, etc. Please refer to the original paper for details.
The above is the detailed content of Stanford and OpenAI proposed meta-prompting, and the strongest zero-sample prompting technology was born.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Why is it necessary to pass pointers when using Go and viper libraries?
Apr 02, 2025 pm 04:00 PM
Why is it necessary to pass pointers when using Go and viper libraries?
Apr 02, 2025 pm 04:00 PM
Go pointer syntax and addressing problems in the use of viper library When programming in Go language, it is crucial to understand the syntax and usage of pointers, especially in...
 Go language slice: Why does it not report an error when single-element slice index 1 intercept?
Apr 02, 2025 pm 02:24 PM
Go language slice: Why does it not report an error when single-element slice index 1 intercept?
Apr 02, 2025 pm 02:24 PM
Go language slice index: Why does a single-element slice intercept from index 1 without an error? In Go language, slices are a flexible data structure that can refer to the bottom...
 Why do all values become the last element when using for range in Go language to traverse slices and store maps?
Apr 02, 2025 pm 04:09 PM
Why do all values become the last element when using for range in Go language to traverse slices and store maps?
Apr 02, 2025 pm 04:09 PM
Why does map iteration in Go cause all values to become the last element? In Go language, when faced with some interview questions, you often encounter maps...
 Go language slice index: Why doesn't single-element slice interception go beyond the bounds?
Apr 02, 2025 pm 02:36 PM
Go language slice index: Why doesn't single-element slice interception go beyond the bounds?
Apr 02, 2025 pm 02:36 PM
Exploring the problem of cross-border of Go slicing index: Single-element slice intercepting In Go, slices are a flexible data structure that can be used for arrays or other...
 How to correctly import custom packages under Go Modules?
Apr 02, 2025 pm 03:42 PM
How to correctly import custom packages under Go Modules?
Apr 02, 2025 pm 03:42 PM
In Go language development, properly introducing custom packages is a crucial step. This article will target "Golang...
 In Go, how to call a function in a sibling file within the same package?
Apr 02, 2025 pm 12:33 PM
In Go, how to call a function in a sibling file within the same package?
Apr 02, 2025 pm 12:33 PM
How to call functions in sibling files within the same package? In Go programming, the organization of project structure and import of packages are very important. We...
 How to distinguish between debug mode and normal operation mode when Go program is running?
Apr 02, 2025 pm 01:45 PM
How to distinguish between debug mode and normal operation mode when Go program is running?
Apr 02, 2025 pm 01:45 PM
When the Go language program is running, how to distinguish between debug mode and normal operation mode? Many developers want to develop Go programs according to different operating modes...
 Bytes.Buffer in Go language causes memory leak: How does the client correctly close the response body to avoid memory usage?
Apr 02, 2025 pm 02:27 PM
Bytes.Buffer in Go language causes memory leak: How does the client correctly close the response body to avoid memory usage?
Apr 02, 2025 pm 02:27 PM
Analysis of memory leaks caused by bytes.makeSlice in Go language In Go language development, if the bytes.Buffer is used to splice strings, if the processing is not done properly...
