
 Technology peripherals
AI
7B open source mathematical model defeats billions of GPT-4, produced by a Chinese team
Technology peripherals
AI
7B open source mathematical model defeats billions of GPT-4, produced by a Chinese team
7B open source mathematical model defeats billions of GPT-4, produced by a Chinese team

7B open source model, the mathematical power exceeds the 100 billion-scale GPT-4!
Its performance can be said to have broken through the limits of the open source model. Even researchers from Alibaba Tongyi lamented whether the scaling law has failed.

Without any external tools, it achieves an accuracy of 51.7% on the competition-level MATH dataset.
Among the open source models, it is the first to achieve half accuracy on this dataset, even surpassing the early and API versions of GPT-4.
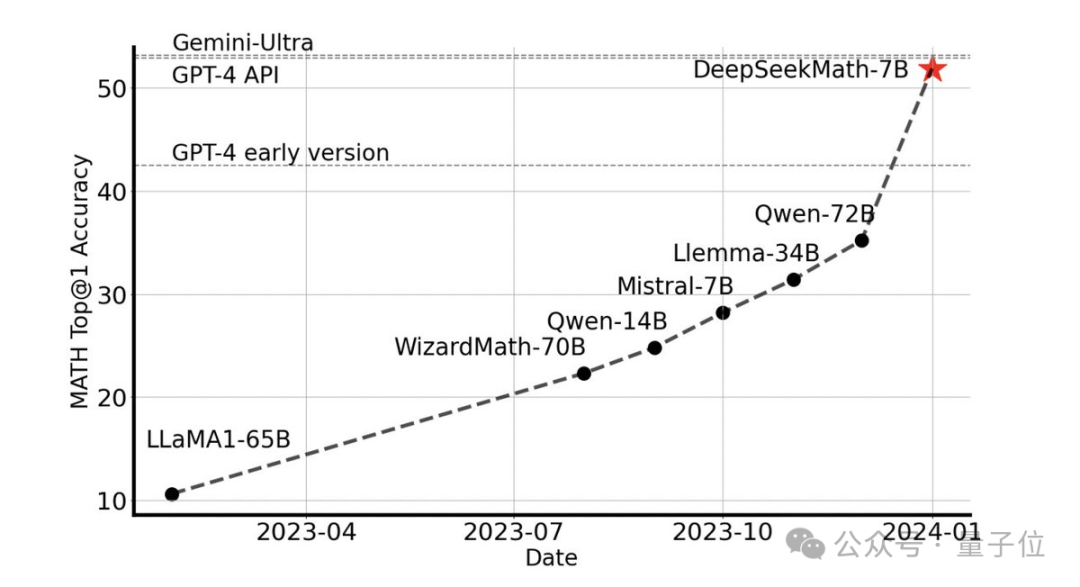
This performance shocked the entire open source community, with Stability AI founder Emad Mostaque praising the R&D team as "impressive" and with "underestimated potential".
It is the deep search team’s latest open source 7B large mathematical model DeepSeekMath.
7B model beats the crowd
In order to evaluate the mathematical ability of DeepSeekMath, the research team used Chinese (MGSM-zh, CMATH) English (GSM8K, MATH )Bilingual data set was tested.
Without using auxiliary tools and relying only on the prompts of the chain of thought (CoT) , DeepSeekMath's performance surpassed other open source models, including the 70B large mathematical model MetaMATH.
Compared with the 67B general large model launched by the company, DeepSeekMath's results have also been significantly improved.
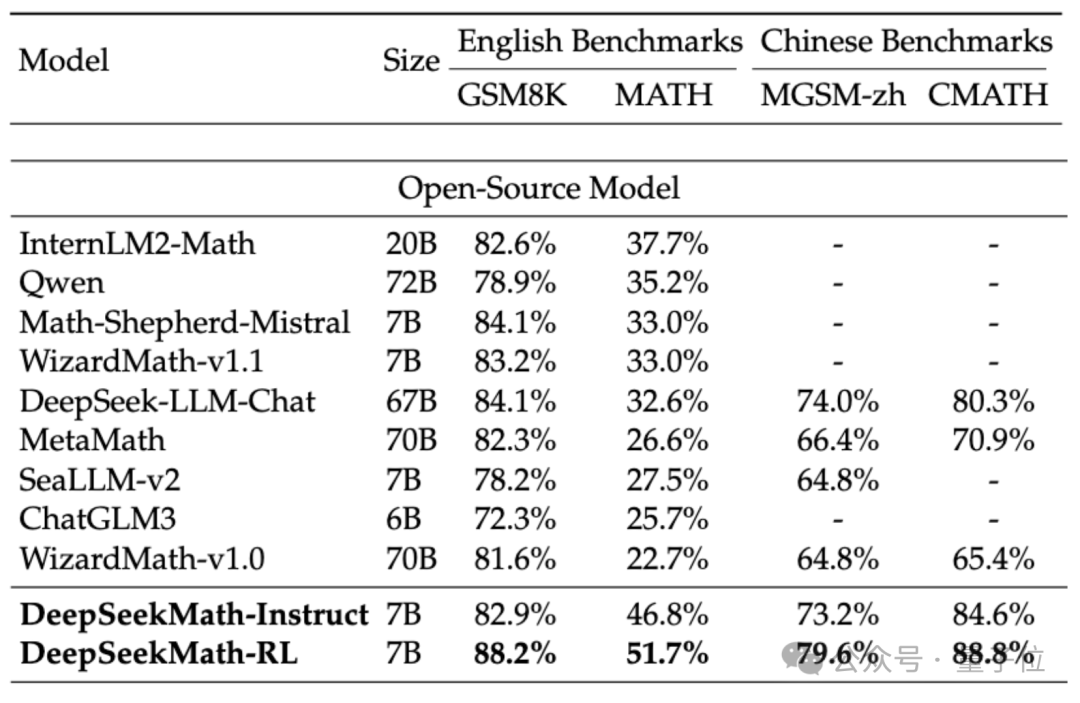
If we consider the closed-source model, DeepSeekMath also surpassed Gemini Pro and GPT-3.5 on several data sets, and surpassed GPT-4 on Chinese CMATH. The performance on MATH is also close to it.
But it should be noted that GPT-4 is a behemoth with hundreds of billions of parameters according to leaked specifications, while DeepSeekMath has only 7B parameters.
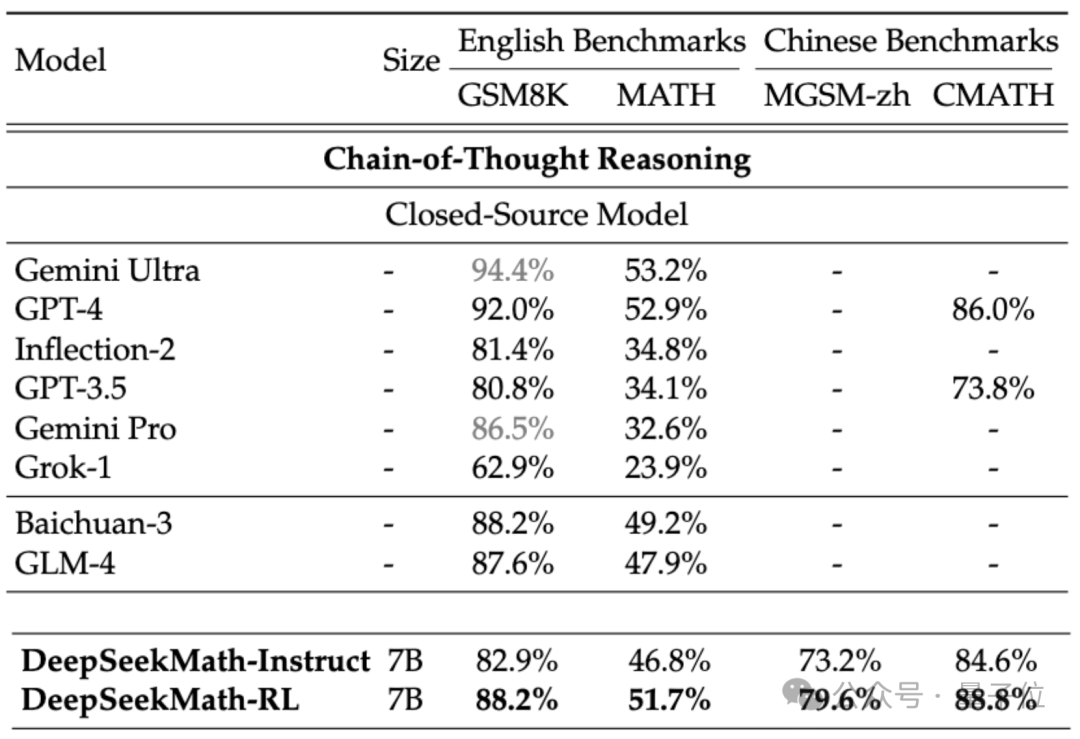
If the tool (Python) is allowed to be used for assistance, DeepSeekMath's performance on the competition difficulty (MATH) data set is still good can be increased by another 7 percentage points.
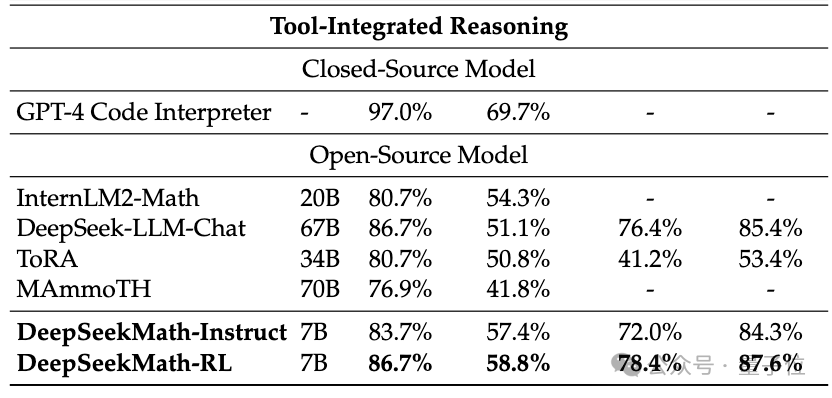
So, what technologies are applied behind the excellent performance of DeepSeekMath?
Built based on code model
In order to obtain better mathematical capabilities than from the general model, the research team used the code model DeepSeek-Coder-v1.5 to initialize it.
Because the team found that, whether in a two-stage training or a one-stage training setting, code training can improve the mathematical capabilities of the model compared to general data training.
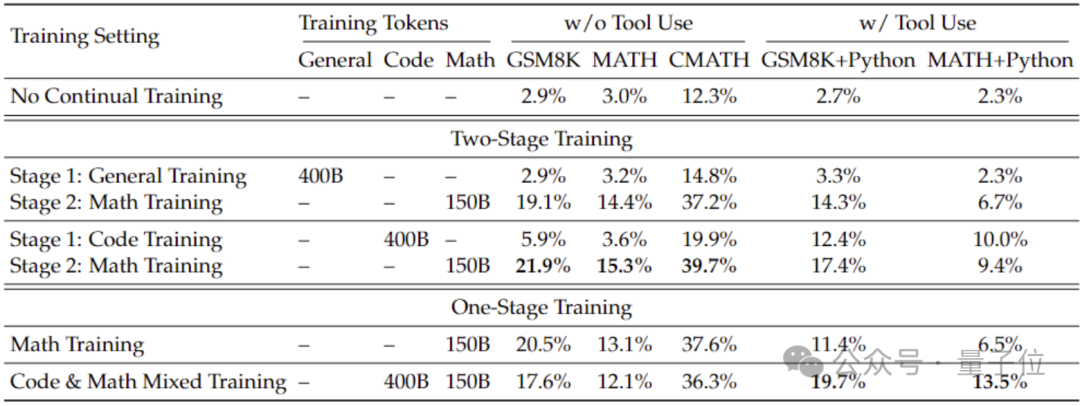
Based on Coder, the research team continued to train 500 billion tokens. The data distribution is as follows:
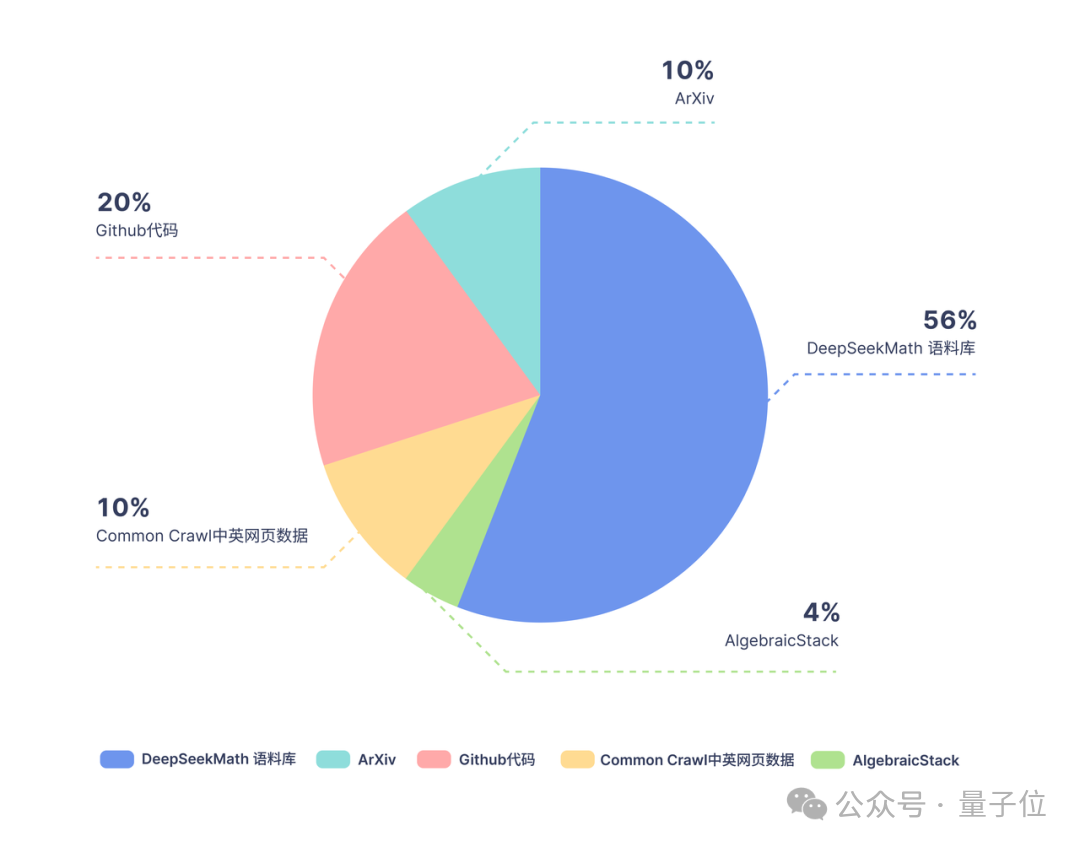
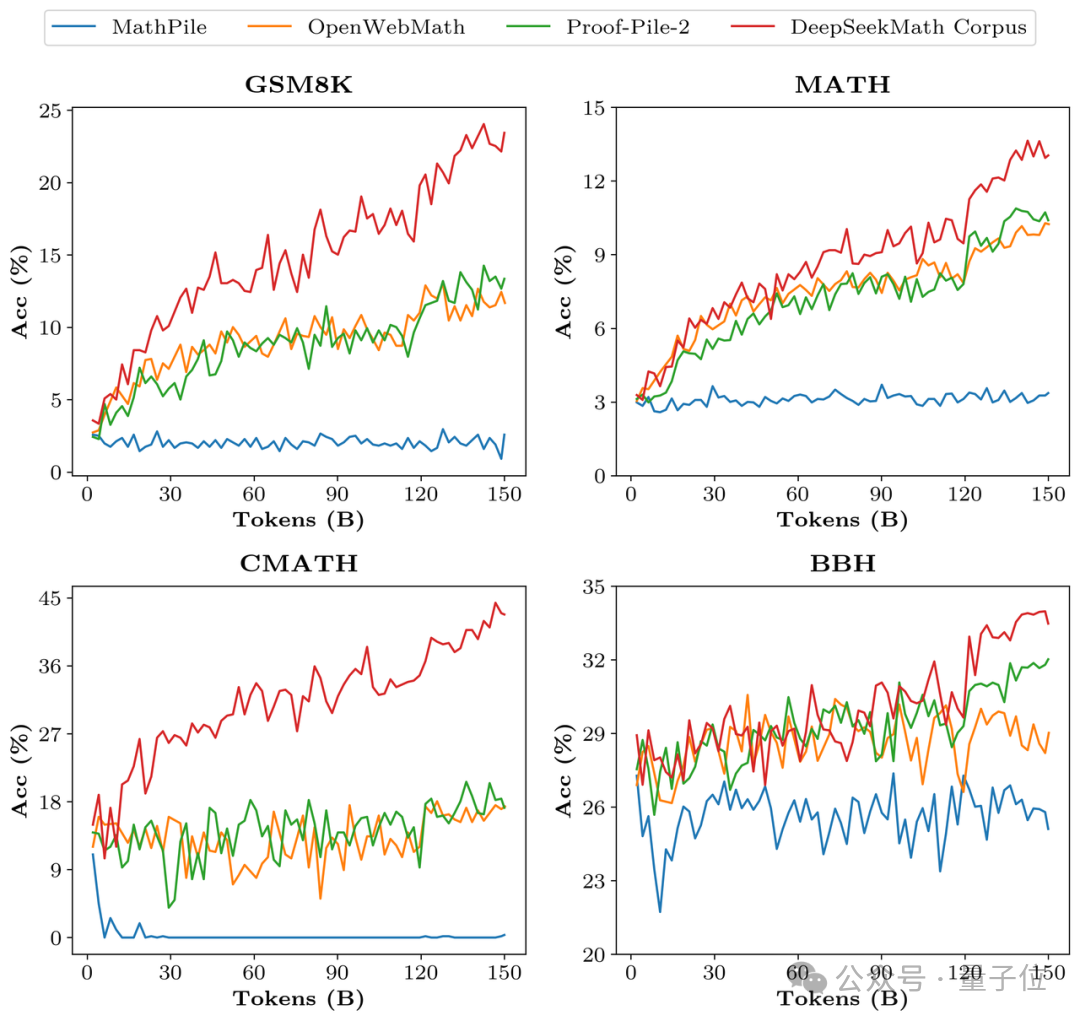
In terms of training data, DeepSeekMath uses 120B of high-quality mathematical webpage data extracted from Common Crawl to obtain DeepSeekMath Corpus. The total data volume is 9 times that of the open source data set OpenWebMath.
The data collection process is carried out iteratively. After four iterations, the research team collected more than 35 million mathematical web pages, and the number of Tokens reached 120 billion.
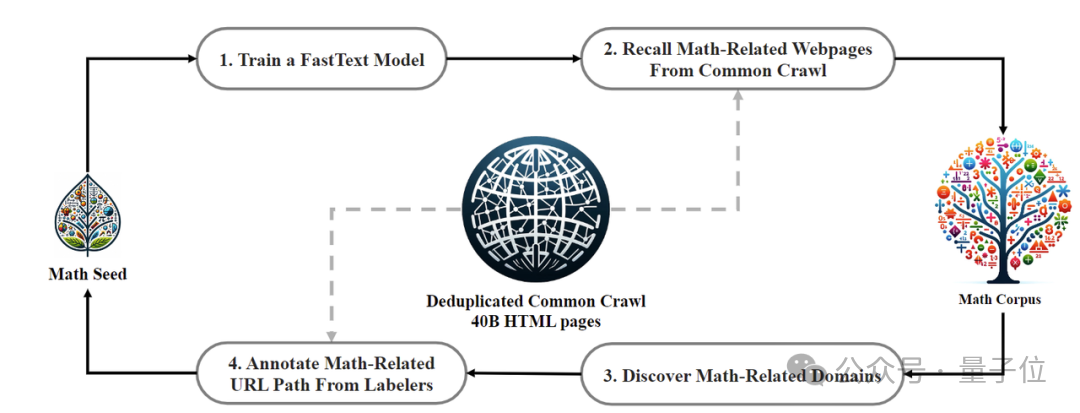
In order to ensure that the training data does not contain the content of the test set (because the content in GSM8K and MATH exists in large quantities on the Internet), the research team also Specially filtered.
In order to verify the data quality of DeepSeekMath Corpus, the research team trained 150 billion tokens using multiple data sets such as MathPile. As a result, Corpus was significantly ahead in multiple mathematical benchmarks.
In the alignment stage, the research team first constructed a 776K sample Chinese and English mathematics guided supervised fine-tuning (SFT) data set, including CoT, PoT and tool-integrated reasoning and other three formats.
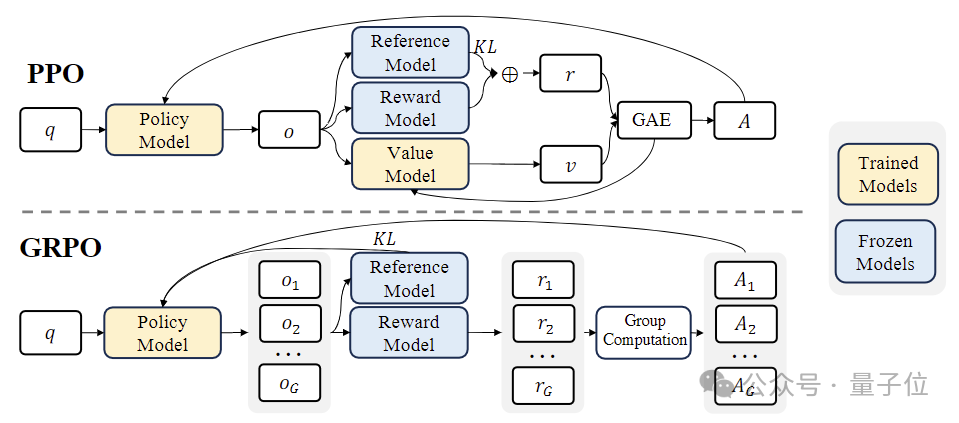
In the reinforcement learning (RL) stage, the research team used an efficient method called "group-based relative policy optimization" (Group Relative Policy Optimization, GRPO) algorithm.
GRPO is a variant of proximal policy optimization (PPO) . In the process, the traditional value function is replaced by a group-based relative reward estimate, which can reduce the complexity of the training process. Computational and memory requirements.
At the same time, GRPO is trained through an iterative process, and the reward model is continuously updated based on the output of the policy model to ensure continuous improvement of the policy.
Have launched the first domestic open source MoE model
The in-depth search team that launched DeepSeekMath is a "leading player" in the field of domestic open source models.
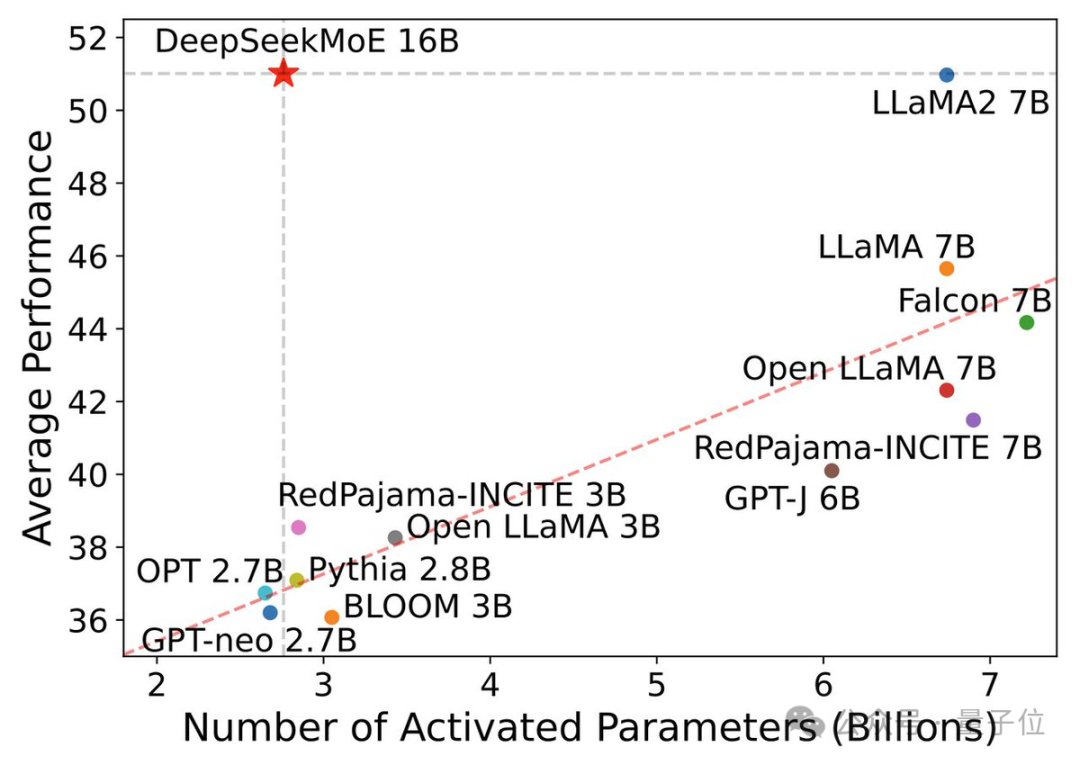
Previously, the team had launched the first domestic open source MoE model DeepSeek MoE. Its 7B version defeated the dense model Llama 2 of the same scale with 40% of the calculation amount.
As a general model, DeepSeek MoE's performance on coding and mathematical tasks is already very impressive, and its resource consumption is very low.
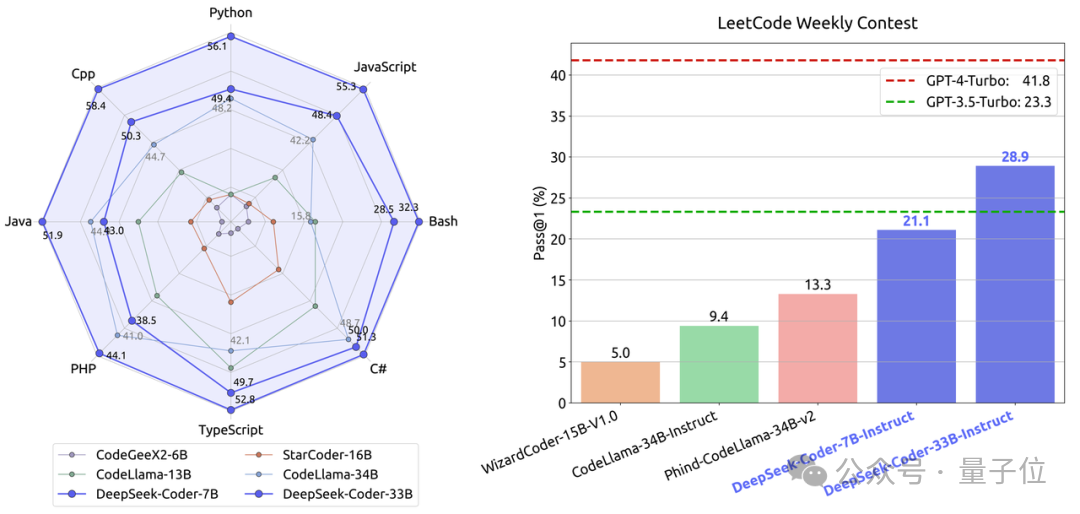
In terms of code, the programming capabilities of DeepSeek-Coder launched by the team exceed CodeLllama, an open source benchmark of the same scale.
At the same time, it also defeated GPT-3.5-Turbo and became the open source code model closest to GPT-4-Turbo.
As mentioned above, the DeepSeekMath launched this time is also built on the basis of Coder.
On X, some people are already looking forward to the MoE versions of Coder and Math.

Paper address: https://arxiv.org/abs/2402.03300
The above is the detailed content of 7B open source mathematical model defeats billions of GPT-4, produced by a Chinese team. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
 How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
During Laravel development, it is often necessary to add virtual columns to the model to handle complex data logic. However, adding virtual columns directly into the model can lead to complexity of database migration and maintenance. After I encountered this problem in my project, I successfully solved this problem by using the stancl/virtualcolumn library. This library not only simplifies the management of virtual columns, but also improves the maintainability and efficiency of the code.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
