

Deploy large language models locally on 2GB DAYU200


Implementation ideas and steps
Port the lightweight LLM model inference framework InferLLM to the OpenHarmony standard system, and compile it to run on OpenHarmony Binary file to run. This inference framework is a simple and efficient LLM CPU inference framework that can locally deploy the quantitative model in LLM.
Use OpenHarmony NDK to compile the InferLLM executable file on OpenHarmony (specifically use the OpenHarmony lycium cross-compilation framework, and then write some scripts. Then store it in the tpc_c_cplusplusSIG warehouse.)
Deploy the large language model locally on DAYU200
Compile and obtain the InferLLM third-party library compiled product
Download OpenHarmony sdk, download address:
http://ci.openharmony.cn/workbench/cicd/dailybuild/dailyList
Download this warehouse
git clone https://gitee.com/openharmony-sig/tpc_c_cplusplus.git --depth=1
# 设置环境变量export OHOS_SDK=解压目录/ohos-sdk/linux# 请替换为你自己的解压目录 cd lycium./build.sh InferLLM
Get the InferLLM third party library header file and the generated library
In the tpc_c_cplusplus/thirdparty/InferLLM/ directory The InferLLM-405d866e4c11b884a8072b4b30659c63555be41d directory will be generated. There are compiled 32-bit and 64-bit third-party libraries in this directory. (The relevant compilation results will not be packaged into the usr directory under the lycium directory).
InferLLM-405d866e4c11b884a8072b4b30659c63555be41d/arm64-v8a-buildInferLLM-405d866e4c11b884a8072b4b30659c63555be41d/armeabi-v7a-build
Push the compiled product and model file to the development board for running
- Download the model file: https ://huggingface.co/kewin4933/InferLLM-Model/tree/main
- will compile the llama executable file generated by InferLLM, the libc _shared.so in OpenHarmony sdk, and the downloaded The model file chinese-alpaca-7b-q4.bin is packaged into the folder llama_file
# 将llama_file文件夹发送到开发板data目录hdc file send llama_file /data
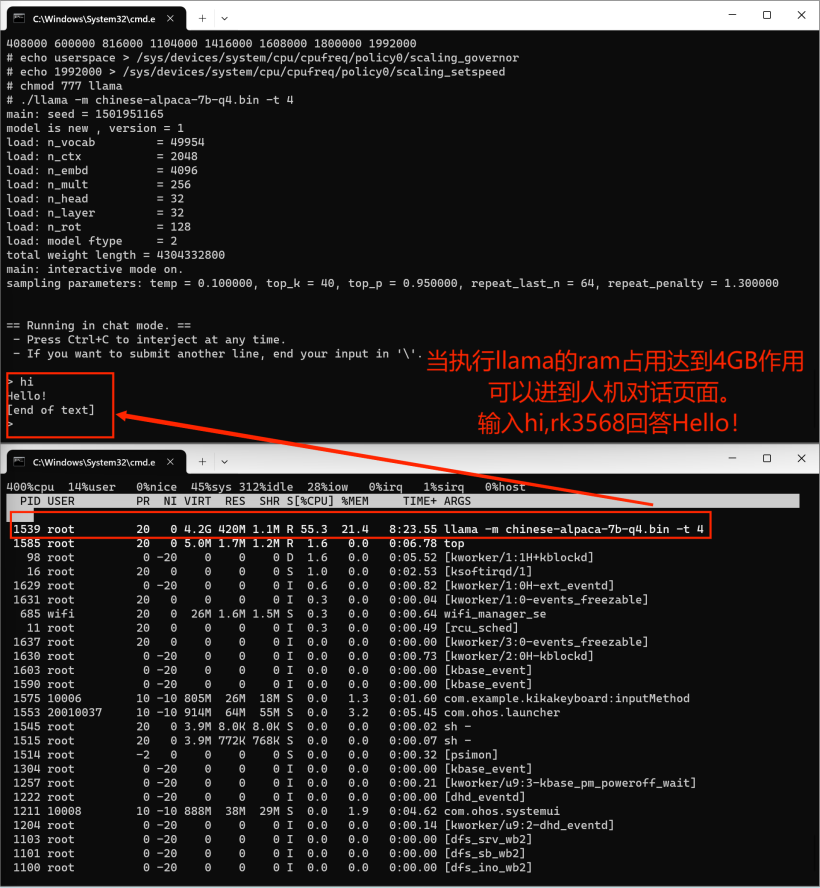
# hdc shell 进入开发板执行cd data/llama_file# 在2GB的dayu200上加swap交换空间# 新建一个空的ram_ohos文件touch ram_ohos# 创建一个用于交换空间的文件(8GB大小的交换文件)fallocate -l 8G /data/ram_ohos# 设置文件权限,以确保所有用户可以读写该文件:chmod 777 /data/ram_ohos# 将文件设置为交换空间:mkswap /data/ram_ohos# 启用交换空间:swapon /data/ram_ohos# 设置库搜索路径export LD_LIBRARY_PATH=/data/llama_file:$LD_LIBRARY_PATH# 提升rk3568cpu频率# 查看 CPU 频率cat /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cur_freq# 查看 CPU 可用频率(不同平台显示的可用频率会有所不同)cat /sys/devices/system/cpu/cpufreq/policy0/scaling_available_frequencies# 将 CPU 调频模式切换为用户空间模式,这意味着用户程序可以手动控制 CPU 的工作频率,而不是由系统自动管理。这样可以提供更大的灵活性和定制性,但需要注意合理调整频率以保持系统稳定性和性能。echo userspace > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor# 设置rk3568 CPU 频率为1.9GHzecho 1992000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_setspeed# 执行大语言模型chmod 777 llama./llama -m chinese-alpaca-7b-q4.bin -t 4
Port the InferLLM third-party library in A large language model is deployed on the OpenHarmmony device rk3568 to realize human-computer dialogue. The final running effect is a bit slow, and the pop-up of the human-machine dialog box is also a bit slow. Please wait patiently.
The above is the detailed content of Deploy large language models locally on 2GB DAYU200. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Yu Chengdong steps down as CEO of Huawei Terminal BG, He Gang will take over
May 02, 2024 pm 04:01 PM
Yu Chengdong steps down as CEO of Huawei Terminal BG, He Gang will take over
May 02, 2024 pm 04:01 PM
According to multiple media reports, Huawei internally issued a personnel adjustment document on the afternoon of April 30, announcing that Yu Chengdong would step down as CEO of Huawei Terminal BG. Yu Chengdong will remain as chairman of Terminal BG. He Gang, the former Huawei Terminal BG and Chief Operating Officer, will take over the position of CEO of Huawei Terminal BG. According to reports, apart from the above-mentioned personal changes and adjustments, the document does not contain any more information. There is no further explanation on the background of this major personnel change and Yu Chengdong’s new business focus after stepping down as CEO of Terminal BG. Some sources said that this adjustment is a routine business structure adjustment, which will allow Yu Chengdong to have more energy to create high-quality products for consumers. Yu Chengdong was born in 1969. He graduated from the Automatic Control Department of Northwestern Polytechnical University with a bachelor's degree and a master's degree from Tsinghua University.
 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 HarmonyOS NEXT native intelligence opens up a new OS experience in the AI big model era! Huawei Xiaoyi turns into a smart body
Jun 22, 2024 am 02:30 AM
HarmonyOS NEXT native intelligence opens up a new OS experience in the AI big model era! Huawei Xiaoyi turns into a smart body
Jun 22, 2024 am 02:30 AM
AI large models have become a hot topic in the current technology circle. More and more companies are beginning to deploy large model capabilities, and more and more products are beginning to emphasize AI. However, judging from the current experience, most of the AI products flooding into the market often simply integrate large model applications at the application level, and do not realize systematic AI technology changes from the bottom up. At HDC2024, with the opening of HarmonyOSNEXT Beta to developers and pioneer users, Huawei demonstrated to the industry what true "native intelligence" is - with system-level AI capabilities, AI is no longer just an add-on to mobile phones, but is integrated with The operating system is deeply integrated and becomes a system-level core capability. According to reports, through the integration of software, hardware and core cloud, HarmonyO
 Xiaoyi upgraded to an intelligent agent! HarmonyOS NEXT Hongmeng native intelligence opens a new AI era
Jun 22, 2024 am 01:56 AM
Xiaoyi upgraded to an intelligent agent! HarmonyOS NEXT Hongmeng native intelligence opens a new AI era
Jun 22, 2024 am 01:56 AM
On June 21, Huawei Developer Conference 2024 (HDC2024) gathered again in Songshan Lake, Dongguan. At this conference, the most eye-catching thing is that HarmonyOSNEXT officially launched Beta for developers and pioneer users, and comprehensively demonstrated the three "king-breaking" innovative features of HarmonyOSNEXT in all scenarios, native intelligence and native security. HarmonyOSNEXT native intelligence: Opening a new AI era After abandoning the Android framework, HarmonyOSNEXT has become a truly independent operating system independent of Android and iOS, which can be called an unprecedented rebirth. Among its many new features, native intelligence is undoubtedly the new feature that can best bring users intuitive feelings and experience upgrades.
 Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
This article will open source the results of "Local Deployment of Large Language Models in OpenHarmony" demonstrated at the 2nd OpenHarmony Technology Conference. Open source address: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/InferLLM/docs/ hap_integrate.md. The implementation ideas and steps are to transplant the lightweight LLM model inference framework InferLLM to the OpenHarmony standard system, and compile a binary product that can run on OpenHarmony. InferLLM is a simple and efficient L
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Introduction to Huawei Hongmeng system update and upgrade methods
May 06, 2024 pm 06:40 PM
Introduction to Huawei Hongmeng system update and upgrade methods
May 06, 2024 pm 06:40 PM
Huawei's Hongmeng system has attracted the attention of many users. This system is suitable for most Huawei mobile phones and supports ota upgrades. However, many users do not know how to upgrade. The following editor will introduce to you the update and upgrade methods of Huawei's Hongmeng system. . How to upgrade Huawei Hongmeng system 1. First open the Huawei phone and click. 2. Then find it in settings. 3. A software update prompt will appear, click on it. 4. It will then jump to the Hongmeng system update entrance. If there is no update interface, click to view it. 5. After the update is completed, return to the settings interface and click About Phone to see the Hongmeng system display. The mobile phone models supported by Hongmeng system support Huawei Mate40, Mate40Pro, Mate40Pro+, Mate4
