

OccNeRF: No lidar data supervision required at all

Written before&The author’s personal summary
In recent years, the 3D occupancy prediction task in the field of autonomous driving has been widely studied by academia and industry because of its unique advantages. focus on. This task provides detailed information for autonomous driving planning and navigation by reconstructing the 3D structure of the surrounding environment. However, most current mainstream methods rely on labels generated based on LiDAR point clouds to supervise network training. In a recent OccNeRF study, the authors proposed a self-supervised multi-camera occupancy prediction method called Parameterized Occupancy Fields. This method solves the problem of boundarylessness in outdoor scenes and reorganizes the sampling strategy. Then, through volume rendering (Volume Rendering) technology, the occupied field is converted into a multi-camera depth map and supervised by multi-frame photometric consistency (Photometric Error). In addition, the method also utilizes a pre-trained open vocabulary semantic segmentation model to generate 2D semantic labels to endow the occupation field with semantic information. This open-lexicon semantic segmentation model is able to segment different objects in a scene and assign semantic labels to each object. By combining these semantic labels with occupancy fields, models are able to better understand the environment and make more accurate predictions. In summary, the OccNeRF method achieves high-precision occupancy prediction in autonomous driving scenarios through the combined use of parameterized occupancy fields, volume rendering, and multi-frame photometric consistency, as well as with an open vocabulary semantic segmentation model. This method provides the autonomous driving system with more environmental information and is expected to improve the safety and reliability of autonomous driving.

- Paper link: https://arxiv.org/pdf/2312.09243.pdf
- Code link: https://github.com /LinShan-Bin/OccNeRF
OccNeRF Problem Background
In recent years, with the rapid development of artificial intelligence technology, great progress has been made in the field of autonomous driving . 3D perception is the basis for autonomous driving and provides necessary information for subsequent planning and decision-making. In traditional methods, lidar can directly capture accurate 3D data, but the high cost of the sensor and the sparse scanning points limit its practical application. In contrast, image-based 3D sensing methods are low-cost and effective and have received increasing attention. Multi-camera 3D object detection has been the mainstream of 3D scene understanding tasks for some time, but it cannot cope with the infinite categories in the real world and is subject to dataThe influence of long tail distribution.
3D occupancy prediction can well compensate for these shortcomings by directly reconstructing the geometry of the surrounding scene through multi-view input. Most existing methods focus on model design and performance optimization, relying on labels generated by LiDAR point clouds to supervise network training, which is not available in image-based systems. In other words, we still need to use expensive data collection vehicles to collect training data and waste a large amount of real data without LiDAR point cloud-assisted annotation, which limits the development of 3D occupancy prediction to a certain extent. Therefore exploring self-supervised 3D occupancy prediction is a very valuable direction.
Detailed explanation of OccNeRF algorithmThe following figure shows the basic process of the OccNeRF method. The model takes multi-camera images
as input, first uses 2D backbone to extract features of N pictures , and then directly obtains 3D features through simple projection and bilinear interpolation (in Parameterized space below), and finally optimize the 3D features through the 3D CNN network and output the prediction results. To train the model, the OccNeRF method generates a depth map of the current frame through volume rendering and introduces the previous and next frames to calculate the photometric loss. To introduce more timing information, OccNeRF uses an occupancy field to render multi-frame depth maps and calculate the loss function. At the same time, OccNeRF also renders 2D semantic maps simultaneously and is supervised by the Open Lexicon Semantic Segmentation Model.
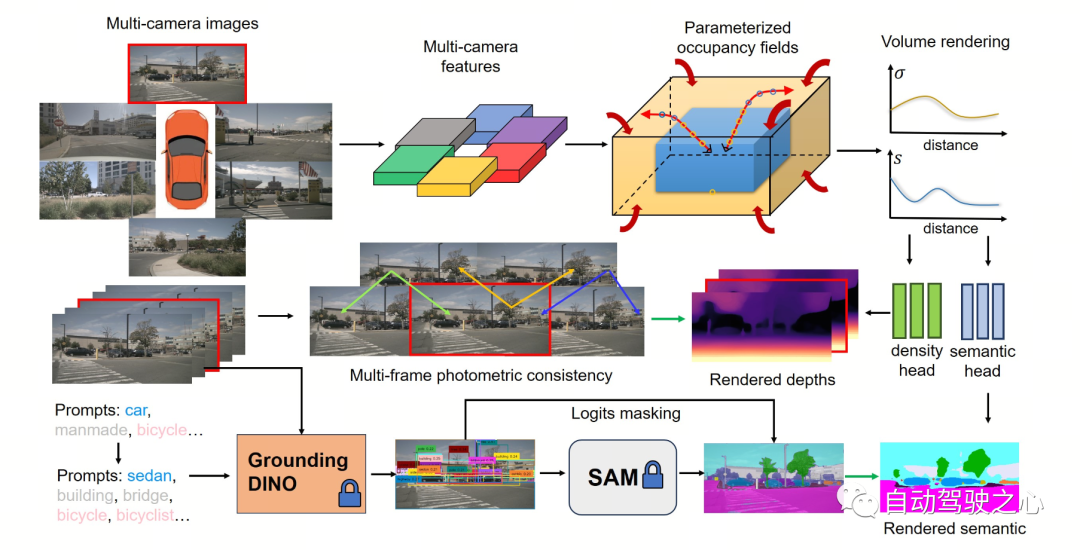 Parameterized Occupancy Fields
Parameterized Occupancy Fields
Parameterized Occupancy Fields are proposed to solve the
perception range gap between the camera and the occupied gridThis One question. Theoretically, cameras can capture objects at infinite distances, while previous occupancy prediction models only consider closer spaces (for example, within 40 m). In supervised methods, the model can learn to ignore distant objects based on supervision signals; in unsupervised methods, if only the near space is still considered, the presence of a large number of out-of-range objects in the image will have a negative impact on the optimization process. Influence. Based on this, OccNeRF adopts Parameterized Occupancy Fields to model an unlimited range of outdoor scenes.
The parameterization space in OccNeRF is divided into internal and external. The inner space is a linear mapping of the original coordinates, maintaining a high resolution; while the outer space represents an infinite range. Specifically, OccNeRF makes the following changes to the coordinates of the points in the 3D space:
where is the coordinate,, is an adjustable parameter, indicating the boundary value corresponding to the internal space. is also an adjustable parameter, indicating the proportion of the internal space occupied. When generating parameterized occupancy fields, OccNeRF first samples in the parameterized space, obtains the original coordinates through inverse transformation, then projects the original coordinates onto the image plane, and finally obtains the occupancy field through sampling and three-dimensional convolution.
Multi-frame Depth Estimation
In order to train the occupancy network, OccNeRF chooses to use volume rendering to convert occupancy into a depth map and supervise it through a photometric loss function. The sampling strategy is important when rendering depth maps. In the parameterized space, if you directly sample uniformly based on depth or parallax, the sampling points will be unevenly distributed in the internal or external space, which will affect the optimization process. Therefore, OccNeRF proposes to directly sample uniformly in the parameterized space under the premise that the camera center is close to the origin. Additionally, OccNeRF renders and supervises multi-frame depth maps while training.
The figure below visually demonstrates the advantages of using parameterized space representation. (The third line uses the parameterized space, and the second line does not.)

Semantic Label Generation
OccNeRF uses pre-trained GroundedSAM (Grounding DINO SAM) generates 2D semantic labels. In order to generate high-quality labels, OccNeRF adopts two strategies. One is cue word optimization, which replaces vague categories in nuScenes with precise descriptions. Three strategies are used in OccNeRF to optimize prompt words: ambiguous word replacement (car is replaced by sedan), word-to-word multi-word (manmade is replaced by building, billboard and bridge), and additional information is introduced (bicycle is replaced by bicycle, bicyclist). The second is to determine the category based on the confidence of the detection frame in Grounding DINO instead of the pixel-by-pixel confidence given by SAM. The semantic label effect generated by OccNeRF is as follows:
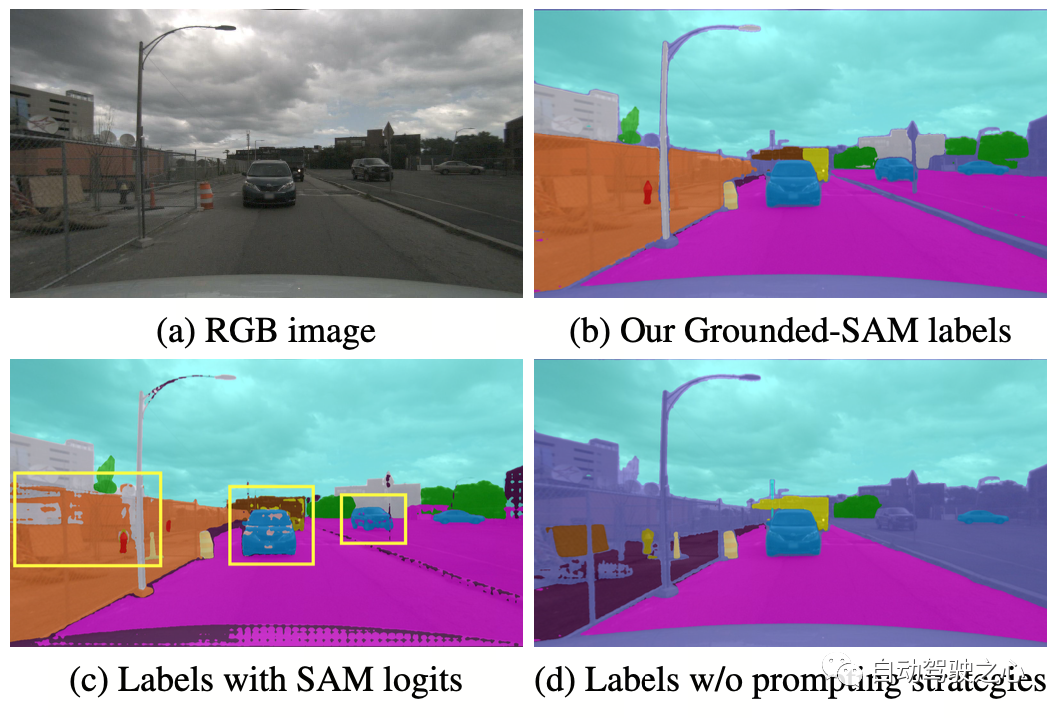
OccNeRF Experimental Results
OccNeRF conducted experiments on nuScenes and mainly completed many Perspective self-supervised depth estimation and 3D occupancy prediction tasks. Multi-view self-supervised depth estimationOccNeRF’s multi-view self-supervised depth estimation performance on nuScenes is shown in the table below. It can be seen that OccNeRF based on 3D modeling significantly surpasses the 2D method and also surpasses SimpleOcc, largely due to the unlimited spatial range that OccNeRF models for outdoor scenes.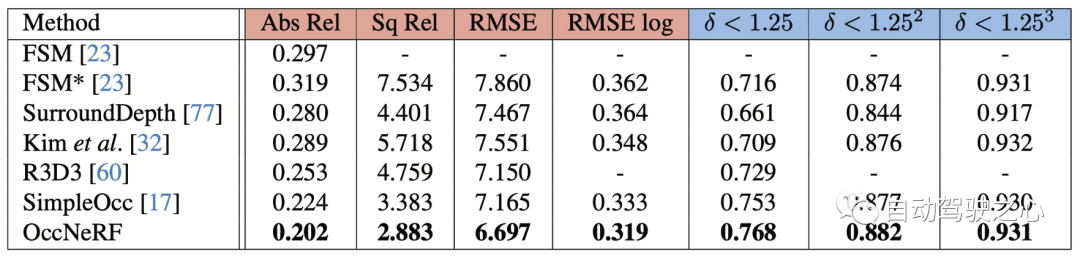

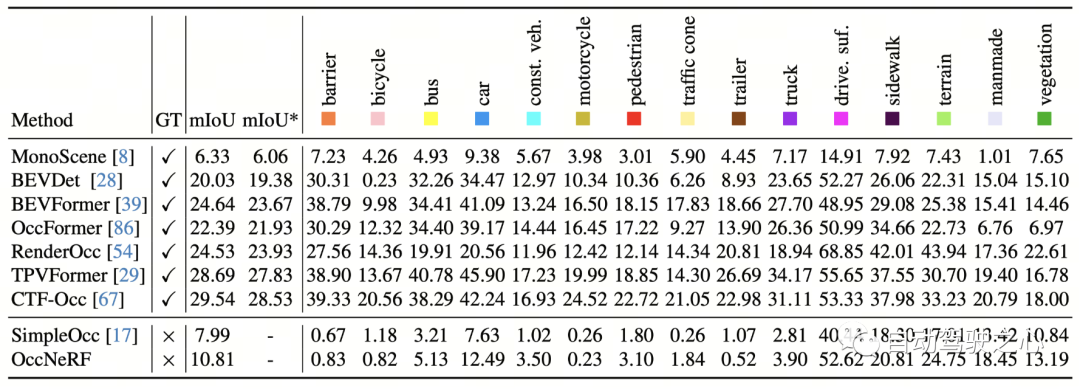

Summary
At a time when many car manufacturers are trying to remove LiDAR sensors, how to make good use of thousands of unlabeled image data is an important issue. And OccNeRF has brought us a valuable attempt.
The above is the detailed content of OccNeRF: No lidar data supervision required at all. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
