

The Fork() function is one of the most commonly used system calls in Linux systems. It is used to create a new process, which is a child process of the calling process. The characteristic of the fork() function is that it is only called once but returns twice, respectively in the parent process and the child process. The return value of the fork() function is different and can be used to distinguish the parent process and the child process. In this article, we will introduce the principles and usage of the fork() function, including the meaning of the return value, the characteristics of the child process, the synchronization and communication of the parent-child process, etc., and give examples of their usage and precautions.
A process, including code, data and resources allocated to the process. The fork() function creates a process that is almost identical to the original process through a system call, that is, the two processes can do exactly the same thing, but if the initial parameters or passed-in variables are different, the two processes can also do different things. .
After a process calls the fork() function, the system first allocates resources to the new process, such as space for storing data and code. Then copy all the values of the original process to the new process, except for a few values that are different from the values of the original process. It is equivalent to cloning oneself.
Let’s take a look at an example:
1. /*
2. \* fork_test.c
3. \* version 1
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main ()
10. {
11. pid_t fpid; //fpid表示fork函数返回的值
12. int count=0;
13. fpid=fork();
14. if (fpid printf("error in fork!");
16. else if (fpid == 0) {
17. printf("i am the child process, my process id is %d/n",getpid());
18. printf("我是爹的儿子/n");//对某些人来说中文看着更直白。
19. count++;
20. }
21. else {
22. printf("i am the parent process, my process id is %d/n",getpid());
23. printf("我是孩子他爹/n");
24. count++;
25. }
26. printf("统计结果是: %d/n",count);
27. return 0;
28. }
The running result is:
i am the child process, my process id is 5574
I am my father's son
The statistical result is: 1
i am the parent process, my process id is 5573
I am the child’s father
The statistical result is: 1
Before the statement fpid=fork(), only one process is executing this code, but after this statement, it becomes two processes. The two processes are almost identical and will be executed. The next statements are all if(fpid
Why are the fpids of the two processes different? This is related to the characteristics of the fork function.
One of the wonderful things about the fork call is that it is only called once, but can return twice. It may have three different return values:
1) In the parent process, fork returns the process ID of the newly created child process;
2) In the child process, fork returns 0;
3) If an error occurs, fork returns a negative value;
After the fork function is executed, if the new process is successfully created, two processes will appear, one is the child process and the other is the parent process. In the child process, the fork function returns 0. In the parent process, fork returns the process ID of the newly created child process. We can use the value returned by fork to determine whether the current process is a child process or a parent process.
Quote a netizen to explain why the value of fpid is different in the father and son processes. "In fact, it is equivalent to a linked list. The processes form a linked list. The fpid of the parent process (p means point) points to the process ID of the child process. Because the child process has no child processes, its fpid is 0.
Fork errors may occur for two reasons:
1) The current number of processes has reached the upper limit specified by the system. At this time, the value of errno is set to EAGAIN.
2) The system has insufficient memory, and the value of errno is set to ENOMEM.
After the new process is successfully created, two basically identical processes will appear in the system. There is no fixed order in which the two processes are executed. Which process is executed first depends on the process scheduling policy of the system.
Each process has a unique (different) process identifier (process ID), which can be obtained through the getpid() function, and a variable that records the pid of the parent process, and the value of the variable can be obtained through the getppid() function.
After the fork execution is completed, two processes appear,
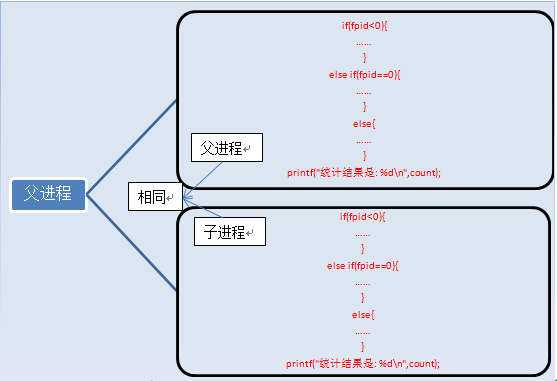
Some people say that the contents of the two processes are exactly the same, but the printed results are different. That is because of the judgment conditions. What is listed above are only the codes and instructions of the processes, as well as variables.
After executing fork, the variables of process 1 are count=0, fpid! =0 (parent process). The variables of process 2 are count=0 and fpid=0 (child process). The variables of these two processes are independent and exist in different addresses. They are not shared. This should be noted. It can be said that we use fpid to identify and operate the parent and child processes.
Some people may also wonder why the code is not copied from #include. This is because fork copies the current situation of the process. When executing fork, the process has already completed int count=0;
fork only copies the next code to be executed to the new process.
2. Fork advanced knowledge
Let’s take a look at the code first:
1. /*
2. \* fork_test.c
3. \* version 2
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main(void)
10. {
11. int i=0;
12. printf("i son/pa ppid pid fpid/n");
13. //ppid指当前进程的父进程pid
14. //pid指当前进程的pid,
15. //fpid指fork返回给当前进程的值
16. for(i=0;iif(fpid==0)
19. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
20. else
21. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
22. }
23. return 0;
24. }
The running result is:
i son/pa ppid pid fpid 0 parent 2043 3224 3225 0 child 3224 3225 0 1 parent 2043 3224 3226 1 parent 3224 3225 3227 1 child 1 3227 0 1 child 1 3226 0
This code is quite interesting, let’s analyze it carefully:
Step 1: In the parent process, the instruction is executed into the for loop, i=0, and then fork is executed. After the fork is executed, two processes appear in the system, namely p3224 and p3225 (I will use pxxxx to represent the process ID later) is the process of xxxx). You can see that the parent process of parent process p3224 is p2043, and the parent process of child process p3225 happens to be p3224. We use a linked list to represent this relationship:
p2043->p3224->p3225
第一次fork后,p3224(父进程)的变量为i=0,fpid=3225(fork函数在父进程中返向子进程id),代码内容为:
1. for(i=0;iif(fpid==0)
4. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
5. else
6. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
7. }
8. return 0;
p3225(子进程)的变量为i=0,fpid=0(fork函数在子进程中返回0),代码内容为:
1. for(i=0;iif(fpid==0)
4. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
5. else
6. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
7. }
8. return 0;
所以打印出结果:
0 parent 2043 3224 3225
0 child 3224 3225 0
第二步:假设父进程p3224先执行,当进入下一个循环时,i=1,接着执行fork,系统中又新增一个进程p3226,对于此时的父进程,
p2043->p3224(当前进程)->p3226(被创建的子进程)。
对于子进程p3225,执行完第一次循环后,i=1,接着执行fork,系统中新增一个进程p3227,对于此进程,p3224->p3225(当前进程)->p3227(被创建的子进程)。
从输出可以看到p3225原来是p3224的子进程,现在变成p3227的父进程。父子是相对的,这个大家应该容易理解。只要当前进程执行了fork,该进程就变成了父进程了,就打印出了parent。
所以打印出结果是:
1 parent 2043 3224 3226
1 parent 3224 3225 3227
第三步:第二步创建了两个进程p3226,p3227,这两个进程执行完printf函数后就结束了,因为这两个进程无法进入第三次循环,无法fork,该执行return 0;了,其他进程也是如此。
以下是p3226,p3227打印出的结果:
1 child 1 3227 0
1 child 1 3226 0
细心的读者可能注意到p3226,p3227的父进程难道不该是p3224和p3225吗,怎么会是1呢?这里得讲到进程的创建和死亡的过程,在p3224和p3225执行完第二个循环后,main函数就该退出了,也即进程该死亡了,因为它已经做完所有事情了。p3224和p3225死亡后,p3226,p3227就没有父进程了,这在操作系统是不被允许的,所以p3226,p3227的父进程就被置为p1了,p1是永远不会死亡的,至于为什么,这里先不介绍,留到“三、fork高阶知识”讲。
总结一下,这个程序执行的流程如下:
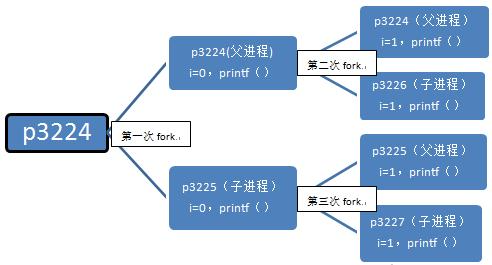
这个程序最终产生了3个子进程,执行过6次printf()函数。
我们再来看一份代码:
1. /*
2. \* fork_test.c
3. \* version 3
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main(void)
10. {
11. int i=0;
12. for(i=0;iif(fpid==0)
15. printf("son/n");
16. else
17. printf("father/n");
18. }
19. return 0;
20.
21. }
它的执行结果是:
father son father father father father son son father son son son father son
这里就不做详细解释了,只做一个大概的分析。
for i=0 1 2 father father father son son father son son father father son son father son
其中每一行分别代表一个进程的运行打印结果。
总结一下规律,对于这种N次循环的情况,执行printf函数的次数为2*(1+2+4+……+2N-1)次,创建的子进程数为1+2+4+……+2N-1个。
(感谢gao_jiawei网友指出的错误,原本我的结论是“执行printf函数的次数为2*(1+2+4+……+2N)次,创建的子进程数为1+2+4+……+2N ”,这是错的)
网上有人说N次循环产生2*(1+2+4+……+2N)个进程,这个说法是不对的,希望大家需要注意。
同时,大家如果想测一下一个程序中到底创建了几个子进程,最好的方法就是调用printf函数打印该进程的pid,也即调用printf(“%d/n”,getpid());或者通过printf(“+/n”);
来判断产生了几个进程。有人想通过调用printf(“+”);来统计创建了几个进程,这是不妥当的。具体原因我来分析。
老规矩,大家看一下下面的代码:
1. /*
2. \* fork_test.c
3. \* version 4
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main() {
10. pid_t fpid;//fpid表示fork函数返回的值
11. //printf("fork!");
12. printf("fork!/n");
13. fpid = fork();
14. if (fpid printf("error in fork!");
16. else if (fpid == 0)
17. printf("I am the child process, my process id is %d/n", getpid());
18. else
19. printf("I am the parent process, my process id is %d/n", getpid());
20. return 0;
21. }
执行结果如下:
fork!
I am the parent process, my process id is 3361
I am the child process, my process id is 3362
如果把语句printf("fork!/n");注释掉,执行printf("fork!");
则新的程序的执行结果是:
fork!I am the parent process, my process id is 3298 fork!I am the child process, my process id is 3299
程序的唯一的区别就在于一个/n回车符号,为什么结果会相差这么大呢?
这就跟printf的缓冲机制有关了,printf某些内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里了,并没有实际的写到屏幕上。
但是,只要看到有/n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf(“fork!”)后,“fork!”仅仅被放到了缓冲里,程序运行到fork时缓冲里面的“fork!” 被子进程复制过去了。因此在子进程度stdout
缓冲里面就也有了fork! 。所以,你最终看到的会是fork! 被printf了2次!!!!
而运行printf(“fork! /n”)后,“fork!”被立即打印到了屏幕上,之后fork到的子进程里的stdout缓冲里不会有fork! 内容。因此你看到的结果会是fork! 被printf了1次!!!!
所以说printf(“+”);不能正确地反应进程的数量。
大家看了这么多可能有点疲倦吧,不过我还得贴最后一份代码来进一步分析fork函数。
1. \#include
2. \#include
3. int main(int argc, char* argv[])
4. {
5. fork();
6. fork() && fork() || fork();
7. fork();
8. return 0;
9. }
问题是不算main这个进程自身,程序到底创建了多少个进程。
为了解答这个问题,我们先做一下弊,先用程序验证一下,到此有多少个进程。
1. \#include
2. int main(int argc, char* argv[])
3. {
4. fork();
5. fork() && fork() || fork();
6. fork();
7. printf("+/n");
8. }
答案是总共20个进程,除去main进程,还有19个进程。
我们再来仔细分析一下,为什么是还有19个进程。
第一个fork和最后一个fork肯定是会执行的。
主要在中间3个fork上,可以画一个图进行描述。
这里就需要注意&&和||运算符。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。
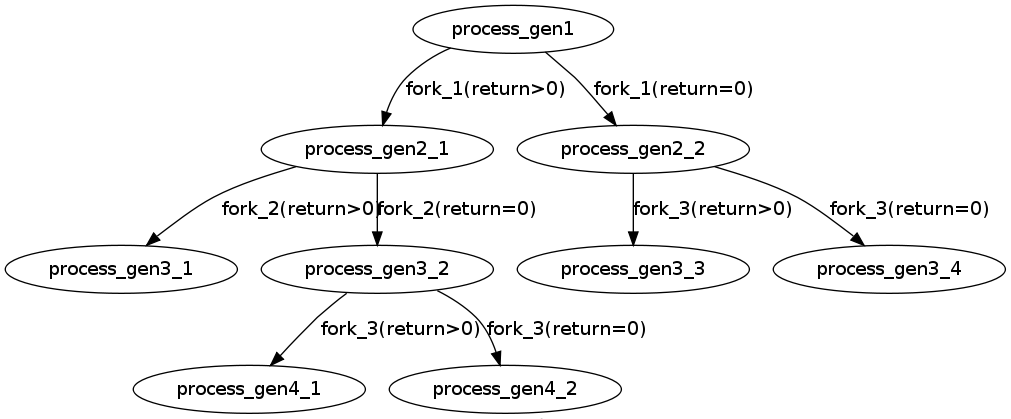
加上前面的fork和最后的fork,总共4*5=20个进程,除去main主进程,就是19个进程了。
三、fork高阶知识
<code style="display: -webkit-box;font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;border-radius: 0px;font-size: 12px">这一块我主要就fork函数讲一下操作系统进程的创建、死亡和调度等。因为时间和精力限制,我先写到这里,下次找个时间我争取把剩下的内容补齐。 </code>
通过本文,我们了解了fork()函数的原理和用法,它可以用来实现多进程编程,提高程序的并发性和效率。我们应该根据实际需求选择合适的fork()函数,并遵循一些基本原则,如检查返回值是否正确,处理僵尸进程,使用信号或管道进行同步和通信等。fork()函数是Linux系统中最强大的系统调用之一,它可以实现多种复杂的功能和特性,也可以提升程序的灵活性和可扩展性。希望本文能够对你有所帮助和启发。
The above is the detailed content of Multi-process programming in Linux systems: Detailed explanation of fork() function. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



