

A brief analysis of linux group scheduling

Linux system is an operating system that supports concurrent execution of multi-tasks. It can run multiple processes at the same time, thereby improving system utilization and efficiency. However, in order for a Linux system to achieve optimal performance, it is necessary to understand and master its process scheduling method. Process scheduling refers to the function of the operating system that dynamically allocates processor resources to different processes based on certain algorithms and strategies to achieve concurrent execution of multiple tasks. There are many process scheduling methods in Linux systems, one of which is group scheduling. Group scheduling is a group-based process scheduling method that allows different process groups to share processor resources in a certain proportion, thereby achieving a balance between fairness and efficiency. This article will briefly analyze the Linux group scheduling method, including the principle, implementation, configuration, advantages and disadvantages of group scheduling.
cgroup and group scheduling
The Linux kernel implements the control group function (cgroup, since linux 2.6.24), which can support grouping processes and then dividing various resources by group. For example: group-1 has 30% CPU and 50% disk IO, group-2 has 10% CPU and 20% disk IO, and so on. Please refer to cgroup related articles for details.
cgroup supports the division of many types of resources, and CPU resources are one of them, which leads to group scheduling.
In the Linux kernel, the traditional scheduler is scheduled based on processes. Assume that users A and B share a machine, which is mainly used to compile programs. We may hope that A and B can share CPU resources fairly, but if user A uses make -j8 (8 threads parallel make), and user B uses make directly (assuming that their make programs use the default priority) , user A's make program will generate 8 times the number of processes as user B, thus occupying (roughly) 8 times the CPU of user B. Because the scheduler is based on processes, the more processes user A has, the greater the probability of being scheduled, and the more competitive it is against the CPU.
How to ensure that users A and B share the CPU fairly? Group scheduling can do this. The processes belonging to users A and B are divided into one group each. The scheduler will first select one group from the two groups, and then select a process from the selected group to execute. If the two groups have the same probability of being selected, then users A and B will each occupy about 50% of the CPU.
Related data structures
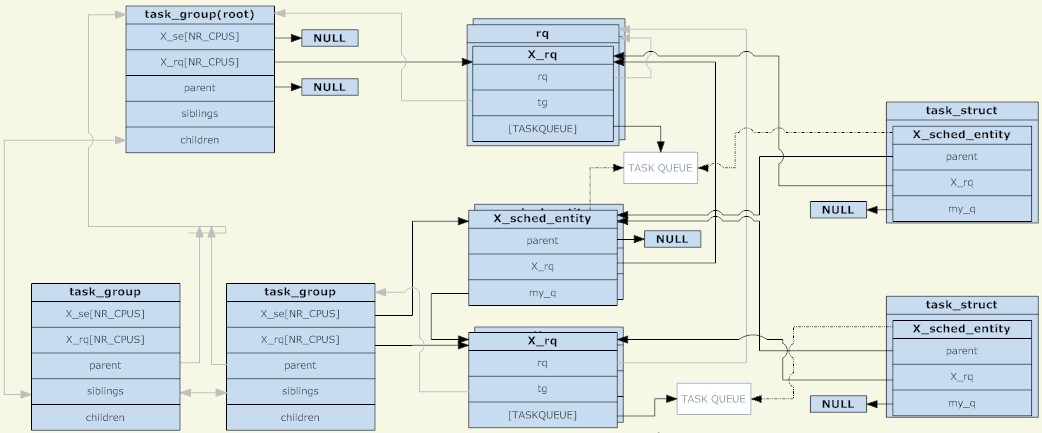
In the Linux kernel, the task_group structure is used to manage group scheduling groups. All existing task_groups form a tree structure (corresponding to the directory structure of cgroup).
A task_group can contain processes with any scheduling category (specifically, real-time processes and ordinary processes), so task_group needs to provide a set of scheduling structures for each scheduling strategy. The set of scheduling structures mentioned here mainly includes two parts, the scheduling entity and the run queue (both are shared per CPU). The scheduling entity will be added to the run queue. For a task_group, its scheduling entity will be added to the run queue of its parent task_group.
Why is there such a thing as a scheduling entity? Because there are two types of scheduled objects: task_group and task, an abstract structure is needed to represent them. If the scheduling entity represents a task_group, its my_q field points to the run queue corresponding to this scheduling group; otherwise, the my_q field is NULL and the scheduling entity represents a task. The opposite of my_q in the scheduling entity is The run queue of the parent node, which is the run queue where this scheduling entity should be placed.
So, the scheduling entity and the run queue form another tree structure. Each of its non-leaf nodes corresponds to the tree structure of task_group, and the leaf nodes correspond to specific tasks. Just like processes in non-TASK_RUNNING state will not be put into the run queue, if there is no process in the TASK_RUNNING state in a group, this group (corresponding scheduling entity) will not be put into its upper-level run queue. To be clear, as long as the scheduling group is created, its corresponding task_group will definitely exist in the tree structure composed of task_group; and whether its corresponding scheduling entity exists in the tree structure composed of the run queue and the scheduling entity depends on Whether there is a process in TASK_RUNNING state in this group.
The task_group as the root node has no scheduling entity. The scheduler always starts from its run queue to select the next scheduling entity (the root node must be the first one selected, and there are no other candidates, so the root node Nodes do not require scheduling entities). The run queue corresponding to the root node task_group is packaged in an rq structure, which in addition to the specific run queue, also contains some global statistical information and other fields.
When scheduling occurs, the scheduler selects a scheduling entity from the run queue of the root task_group. If this scheduling entity represents a task_group, the scheduler needs to continue to select a scheduling entity from the run queue corresponding to this group. This recursion continues until a process is selected. Unless the run queue of the root task_group is empty, a process will definitely be found by recursing. Because if the run queue corresponding to a task_group is empty, its corresponding scheduling entity will not be added to the run queue corresponding to its parent node.
Finally, for a task_group, its scheduling entity and run queue are shared per CPU, and a scheduling entity (corresponding to task_group) will only be added to the run queue corresponding to the same CPU. For a task, there is only one copy of the scheduling entity (not divided by CPU). The load balancing function of the scheduler may move the scheduling entity (corresponding to the task) from the run queue corresponding to different CPUs.
Group scheduling policy
The main data structure of group scheduling has been clarified, but there is still a very important issue here. We know that tasks have their corresponding priorities (static priority or dynamic priority), and the scheduler selects processes in the run queue based on priority. So, since task_group and task are both abstracted into scheduling entities and accept the same scheduling, how should the priority of task_group be defined? This question needs to be answered specifically by the scheduling category (different scheduling categories have different priority definitions), specifically rt (real-time scheduling) and cfs (completely fair scheduling).
Group scheduling of real-time processes
As can be seen from the article "A Brief Analysis of Linux Process Scheduling", a real-time process is a process that has real-time requirements for the CPU. Its priority is related to specific tasks and is completely defined by the user. The scheduler will always choose the highest priority real-time process to run.
When it comes to group scheduling, the priority of the group is defined as "the priority of the highest priority process in the group." For example, if there are three processes in the group with priorities 10, 20, and 30, the priority of the group is 10 (the smaller the value, the greater the priority).
The priority of the group is defined in this way, which leads to an interesting phenomenon. When a task is enqueued or dequeued, all its ancestor nodes must be dequeued first, and then re-enqueued from bottom to top. Because the priority of a group node depends on its child nodes, the enqueuing and dequeuing of tasks will affect each of its ancestor nodes.
So, when the scheduler selects the scheduling entity from the task_group of the root node, it can always find the highest priority among all real-time processes in the TASK_RUNNING state along the correct path. This implementation seems natural, but if you think about it carefully, what is the point of grouping real-time processes in this way? Regardless of grouping or not, what the scheduler has to do is "select the one with the highest priority among all real-time processes in the TASK_RUNNING state." There seems to be something missing here...
Now we need to introduce the two proc files in the Linux system: /proc/sys/kernel/sched_rt_period_us and /proc/sys/kernel/sched_rt_runtime_us. These two files stipulate that within a period with sched_rt_period_us as a period, the sum of the running time of all real-time processes shall not exceed sched_rt_runtime_us. The default values of these two files are 1s and 0.95s, which means that every second is a cycle. In this cycle, the total running time of all real-time processes does not exceed 0.95 seconds, and the remaining at least 0.05 seconds will be reserved for ordinary processes. In other words, the real-time process occupies no more than 95% of the CPU. Before these two files appeared, there was no limit to the running time of real-time processes. If there were always real-time processes in the TASK_RUNNING state, ordinary processes would never be able to run. Equivalent to sched_rt_runtime_us is equal to sched_rt_period_us.
Why are there two variables, sched_rt_runtime_us and sched_rt_period_us? Isn't it possible to directly use a variable that represents the percentage of CPU usage? I think this is because many real-time processes are actually doing something periodically, such as a voice program sending a voice packet every 20ms, a video program refreshing a frame every 40ms, and so on. Periods are important, and just using a macro CPU occupancy ratio cannot accurately describe real-time process needs.
The grouping of real-time processes expands the concepts of sched_rt_runtime_us and sched_rt_period_us. Each task_group has its own sched_rt_runtime_us and sched_rt_period_us, ensuring that the processes in its own group can only run sched_rt_runtime_us at most within the period of sched_rt_period_us. Much time. The CPU occupancy ratio is sched_rt_runtime_us/sched_rt_period_us.
For the task_group of the root node, its sched_rt_runtime_us and sched_rt_period_us are equal to the values in the above two proc files. For a task_group node, assuming that there are n scheduling subgroups and m processes in the TASK_RUNNING state, its CPU occupancy ratio is A, and the CPU occupancy ratio of these n subgroups is B, then B must be less than or equal to A. , and the remaining CPU time of A-B will be allocated to the m processes in the TASK_RUNNING state. (What is discussed here is the CPU occupancy ratio, because each scheduling group may have different cycle values.)
In order to implement the logic of sched_rt_runtime_us and sched_rt_period_us, when the kernel updates the running time of the process (such as a time update triggered by a periodic clock interrupt), it will add the corresponding runtime to the scheduling entity of the current process and all its ancestor nodes. . If a scheduling entity reaches the time limited by sched_rt_runtime_us, it will be removed from the corresponding run queue and the corresponding rt_rq will be set to the throttled state. In this state, the scheduling entity corresponding to rt_rq will not enter the run queue again. Each rt_rq maintains a periodic timer with a timing period of sched_rt_period_us. Each time the timer is triggered, its corresponding callback function will subtract a sched_rt_period_us unit value from the runtime of rt_rq (but keep the runtime not less than 0), and then restore rt_rq from the throttled state.
There is another question. As mentioned earlier, by default, the running time of real-time processes in the system does not exceed 0.95 seconds per second. If the actual demand for the CPU by the real-time process is less than 0.95 seconds (greater than or equal to 0 seconds and less than 0.95 seconds), the remaining time will be allocated to ordinary processes. And if the real-time process's CPU demand is greater than 0.95 seconds, it can only run for 0.95 seconds, and the remaining 0.05 seconds will be allocated to other ordinary processes. However, what if no ordinary process needs to use the CPU during these 0.05 seconds (ordinary processes that have no TASK_RUNNING state)? In this case, since the ordinary process has no demand for the CPU, can the real-time process run for more than 0.95 seconds? cannot. In the remaining 0.05 seconds, the kernel would rather keep the CPU idle than let the real-time process use it. It can be seen that sched_rt_runtime_us and sched_rt_period_us are very mandatory.
Finally, there is the issue of multiple CPUs. As mentioned earlier, for each task_group, its scheduling entity and run queue are maintained per CPU. The sched_rt_runtime_us and sched_rt_period_us act on the scheduling entity, so if there are N CPUs in the system, the upper limit of the actual CPU occupied by the real-time process is N*sched_rt_runtime_us/sched_rt_period_us. That is, the real-time process can only run for 0.95 seconds, despite the default limit of one second. But for a real-time process, if the CPU has two cores, it can still meet its demand for occupying 100% of the CPU (such as executing an infinite loop). Then, it stands to reason that 100% of the CPU occupied by this real-time process should be composed of two parts (each CPU occupies a part, but no more than 95%). But in fact, in order to avoid a series of problems such as context switching and cache invalidation caused by process migration between CPUs, the scheduling entity on one CPU can borrow time from the corresponding scheduling entity on another CPU. The result is that macroscopically, it not only meets the limitations of sched_rt_runtime_us, but also avoids process migration.
Group scheduling of ordinary processes
At the beginning of the article, it was mentioned that two users A and B can equally share the CPU demand even if the number of processes is different. However, the group scheduling strategy for real-time processes above does not seem to be relevant to this. In fact, this is a common What group scheduling of processes does.
Compared with real-time processes, group scheduling of ordinary processes is not so particular. A group is treated as almost the same entity as a process. It has its own static priority, and the scheduler dynamically adjusts its priority. For a group, the priority of the processes in the group does not affect the priority of the group. The priority of these processes is only considered when the group is selected by the scheduler.
In order to set the priority of the group, each task_group has a shares parameter (in parallel with the two parameters sched_rt_runtime_us and sched_rt_period_us mentioned earlier). Shares are not priorities, but the weight of the scheduling entity (this is how the CFS scheduler plays). There is a one-to-one correspondence between this weight and priority. The priority of an ordinary process will also be converted into the weight of its corresponding scheduling entity, so it can be said that shares represent the priority.
The default value of shares is the same as the weight corresponding to the default priority of an ordinary process. So by default, the group and process share the CPU equally.
Example
(Environment: ubuntu 10.04, kernel 2.6.32, Intel Core2 dual core)
Mount a cgroup that only divides CPU resources, and create two subgroups grp_a and grp_b:
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
Open three shells respectively, join grp_a in the first one, and grp_b in the last two:
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
The above is the detailed content of A brief analysis of linux group scheduling. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to start apache
Apr 13, 2025 pm 01:06 PM
How to start apache
Apr 13, 2025 pm 01:06 PM
The steps to start Apache are as follows: Install Apache (command: sudo apt-get install apache2 or download it from the official website) Start Apache (Linux: sudo systemctl start apache2; Windows: Right-click the "Apache2.4" service and select "Start") Check whether it has been started (Linux: sudo systemctl status apache2; Windows: Check the status of the "Apache2.4" service in the service manager) Enable boot automatically (optional, Linux: sudo systemctl
 What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
When the Apache 80 port is occupied, the solution is as follows: find out the process that occupies the port and close it. Check the firewall settings to make sure Apache is not blocked. If the above method does not work, please reconfigure Apache to use a different port. Restart the Apache service.
 How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
This article describes how to effectively monitor the SSL performance of Nginx servers on Debian systems. We will use NginxExporter to export Nginx status data to Prometheus and then visually display it through Grafana. Step 1: Configuring Nginx First, we need to enable the stub_status module in the Nginx configuration file to obtain the status information of Nginx. Add the following snippet in your Nginx configuration file (usually located in /etc/nginx/nginx.conf or its include file): location/nginx_status{stub_status
 How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
This article introduces two methods of configuring a recycling bin in a Debian system: a graphical interface and a command line. Method 1: Use the Nautilus graphical interface to open the file manager: Find and start the Nautilus file manager (usually called "File") in the desktop or application menu. Find the Recycle Bin: Look for the Recycle Bin folder in the left navigation bar. If it is not found, try clicking "Other Location" or "Computer" to search. Configure Recycle Bin properties: Right-click "Recycle Bin" and select "Properties". In the Properties window, you can adjust the following settings: Maximum Size: Limit the disk space available in the Recycle Bin. Retention time: Set the preservation before the file is automatically deleted in the recycling bin
 How to restart the apache server
Apr 13, 2025 pm 01:12 PM
How to restart the apache server
Apr 13, 2025 pm 01:12 PM
To restart the Apache server, follow these steps: Linux/macOS: Run sudo systemctl restart apache2. Windows: Run net stop Apache2.4 and then net start Apache2.4. Run netstat -a | findstr 80 to check the server status.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to solve the problem that apache cannot be started
Apr 13, 2025 pm 01:21 PM
How to solve the problem that apache cannot be started
Apr 13, 2025 pm 01:21 PM
Apache cannot start because the following reasons may be: Configuration file syntax error. Conflict with other application ports. Permissions issue. Out of memory. Process deadlock. Daemon failure. SELinux permissions issues. Firewall problem. Software conflict.
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
