

In Linux systems, memory management is one of the most important parts of the operating system. It is responsible for allocating limited physical memory to multiple processes and providing an abstraction of virtual memory so that each process has its own address space and can protect and share memory. This article will introduce the principles and methods of Linux memory management, including concepts such as virtual memory, physical memory, logical memory, and linear memory, as well as the basic model, system calls, and implementation methods of Linux memory management.
This article is based on 32-bit machines and talks about some memory management knowledge points.
Virtual address is also called linear address. Linux does not use a segmentation mechanism, so logical address and virtual address (linear address) (In user mode, kernel mode logical address specifically refers to the address before linear offset mentioned below) are the same concept. There is no need to mention the physical address. Most of the kernel's virtual address and physical address only differ by a linear offset. The virtual address and physical address of user space are mapped using multi-level page tables, but they are still called linear addresses.
In the x86 structure, Linux kernel virtualThe address space is divided into 0~3G as user space and 3~4G as kernel space (note that the linear address that the kernel can use is only 1G). The kernel virtual space (3G~4G) is divided into three types of areas:
ZONE_DMA 16MB starting after 3G
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
Since the virtual and physical addresses of the kernel only differ by one offset: physical address = logical address – 0xC0000000. Therefore, if the 1G kernel space is completely used for linear mapping, obviously the physical memory can only access the 1G range, which is obviously unreasonable. HIGHMEM is to solve this problem. It has specially opened a area that does not require linear mapping and can be flexibly customized to access an area of physical memory above 1G. I grabbed a picture from the Internet,
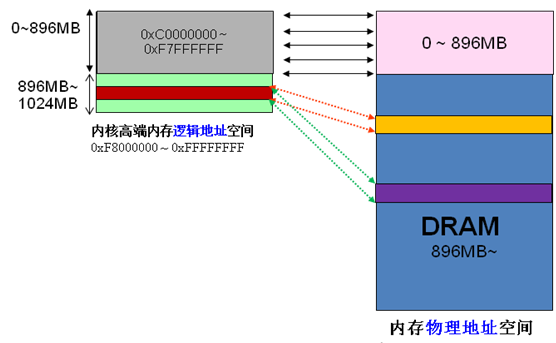
The division of high-end memory is as shown below,
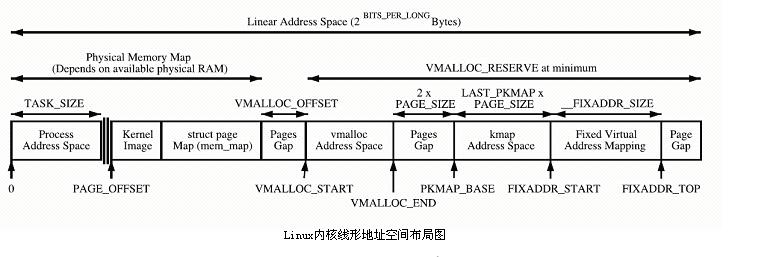
The kernel directly maps the space PAGE_OFFSET~VMALLOC_START, kmalloc and __get_free_page() allocate the pages here. Both use the slab allocator to directly allocate physical pages and then convert them into logical addresses (physical addresses are continuous). Suitable for allocating small segments of memory. This area contains resources such as the kernel image and the physical page frame table mem_map.
Kernel dynamic mapping space VMALLOC_START~VMALLOC_END is used by vmalloc and has a large representable space.
Kernel permanent mapping space PKMAP_BASE ~ FIXADDR_START, kmap
Kernel temporary mapping space FIXADDR_START~FIXADDR_TOP, kmap_atomic
The Buddy algorithm solves the problem of external fragmentation. The kernel manages the available pages in each zone, arranges them into a linked list queue according to the power of 2 (order) size, and stores them in the free_area array.
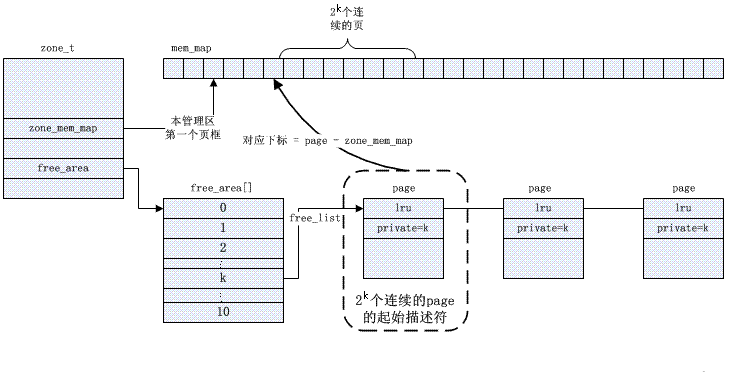
The specific buddy management is based on bitmap, and its algorithm for allocating and recycling pages is described as follows,
Buddy algorithm example description:
Assume that our system memory only has ***16****** pages****RAM*. Because RAM only has 16 pages, we only need to use four levels (orders) of buddy bitmaps (because the maximum contiguous memory size is ******16****** pages* **),As shown below.
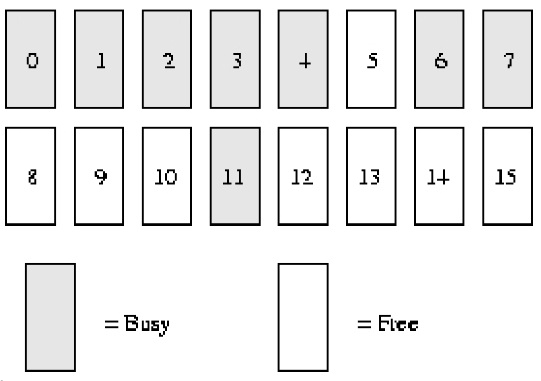

order(0) bimap has 8 bits (*** pages can have up to ******16****** pages, so ******16/ 2***)
order(1) bimap has 4 bits (***order******(******0******)******bimap**** **There are ******8****** ******bit****** bits***, so 8/2);
That is, the first block of order (1) consists of *** two page frames ****page1* *** and ******page2*****Composed with *order (1) Block 2 consists of two page frames ****page3* *** and ******page4** ****, there is a ******bit**** bit*
between these two blocksorder(2) bimap has 2 bits (***order******(******1******)******bimap**** **There are******4************bit******digits***, so 4/2)
order(3) bimap has 1 bit (***order******(******2******)******bimap**** **There are ******4****** ******bit****** bits***, so 2/2)
In order(0), the first bit represents the first ****2****** pages***, and the second bit represents the next 2 pages. And so on. Because page 4 has been allocated and page 5 is free, the third bit is 1.
Also in order(1), the reason bit3 is 1 is that one partner is completely idle (pages 8 and 9), but its corresponding partner (pages 10 and 11) is not so, so when the page is recycled in the future, you can merge.
Allocation process
***When we need the free page block of ******order****** (******1******), *** perform the following steps :
1. The initial free linked list is:
order(0): 5, 10
order(1): 8 [8,9]
order(2): 12 [12,13,14,15]
order(3):
2. From the free linked list above, we can see that there is * a free page block on the order (1) linked list. Allocate it to the user and delete it from the linked list. *
3. When we need another order(1) block, we also start scanning from the order(1) free list.
4. If there is no free page block *** on ***order****** (******1******), then we will go to a higher level ( order), order(2).
5. At this time (there is no free page block on ***order****** (******1*****)*) there is a free page block , the block starts on page 12. The page block is split into two slightly smaller order (1) page blocks, [12, 13] and [14, 15]. [14, 15] The page block is added to the order****** (******1*****) free linked list *, and ## at the same time #[12******,******13]****The page block is returned to the user. *
6. The final free linked list is:
order(0): 5, 10
order(1): 14 [14,15]
order(2):
order(3):
Recycling process
***When we recycle page ******11****** (******order 0****), the following steps will be performed: *
***1******, ****** found in ******order****** (******0******) The bit ****representing page ******11****** in the partner bitmap is calculated using the following public notation: *
*index =* *page_idx >> (order 1)*
*= 11 >> (0 1)*
*= 5*
2. Check the above step to calculate the value of the corresponding bit in the bitmap. If the bit value is 1, there is an idle partner close to us. The value of Bit5 is 1 (note that it starts from bit0, Bit5 is the 6th bit) because its partner page 10 is free.3. Now we reset the value of this bit to 0, because the two partners (page 10 and page 11) are completely idle at this time.
4. We remove page 10 from the order(0) free list.
5. At this time, we perform further operations on the 2 free pages (pages 10 and 11, order (1)).
6. The new free page starts from page 10, so we find its index in the partner bitmap of order(1) to see if there is an idle partner for further merging operations. Using the calculated company from step one, we get bit 2 (digit 3).
7. Bit 2 (order(1) bitmap) is also 1 because its partner page blocks (pages 8 and 9) are free.
8. Reset the value of bit2 (order(1) bitmap), and then delete the free page block in the order(1) linked list.
9. Now we merge into free blocks of 4 page sizes (starting from page 8), thus entering another level. Find the bit value corresponding to the partner bitmap in order (2), which is bit1, and the value is 1. It needs to be further merged (the reason is the same as above).
10. Remove the free page block (starting from page 12) from the oder(2) linked list, and then further merge the page block with the page block obtained by the previous merger. Now we get a block of free pages starting from page 8 and of size 8 pages.
11. We enter another level, order (3). Its bit index is 0, and its value is also 0. This means that the corresponding partners are not all free, so there is no possibility of further merging. We only set this bit to 1, and then put the merged free page blocks into the order(3) free linked list.
12. Finally we get a free block of 8 pages,

buddy’s efforts to avoid internal fragmentation
The fragmentation of physical memory has always been one of the weaknesses of the Linux operating system. Although many solutions have been proposed, no method can completely solve it. Memory buddy allocation is one of the solutions. We know that disk files also have fragmentation problems, but fragmentation of disk files will only slow down the reading and writing speed of the system and will not cause functional errors. Moreover, we can also fragment the disk without affecting the function of the disk. tidy. Physical memory fragmentation is completely different. Physical memory and the operating system are so closely integrated that it is difficult for us to move physical memory during runtime (at this point, disk fragmentation is much easier; in fact, mel gorman has The memory compaction patch has been submitted, but it has not yet been received by the mainline kernel). Therefore, the solution direction is mainly focused on preventing debris. During the development of the 2.6.24 kernel, kernel functionality to prevent fragmentation was added to the mainline kernel. Before understanding the basic principles of anti-fragmentation, first classify the memory pages:
\1. Unmoveable pages: The location in the memory must be fixed and cannot be moved to other places. Most pages allocated by the core kernel fall into this category.
\2. Reclaimable page reclaimable: It cannot be moved directly, but it can be recycled, because the page can also be reconstructed from some sources. For example, the data of the mapping file belongs to this category, and kswapd will recycle it periodically according to certain rules. This type of page.
\3. Movable page movable: can be moved at will. Pages belonging to user space applications belong to this type of page. They are mapped through the page table, so we only need to update the page table entries and copy the data to the new location. Of course, it should be noted that a page may be used by multiple Process sharing corresponds to multiple page table entries.
The way to prevent fragmentation is to put these three types of pages on different linked lists to prevent different types of pages from interfering with each other. Consider the situation where an immovable page is located in the middle of a movable page. After we move or recycle these pages, this immovable page prevents us from obtaining larger continuous physical free space.
In addition, Each zone has its own deactivated net page queue, corresponding to two cross-zone global queues, the deactivated dirty page queue and the active queue. These queues are linked through the lru pointer of the page structure.
Thinking: What is the meaning of the deactivation queue (see
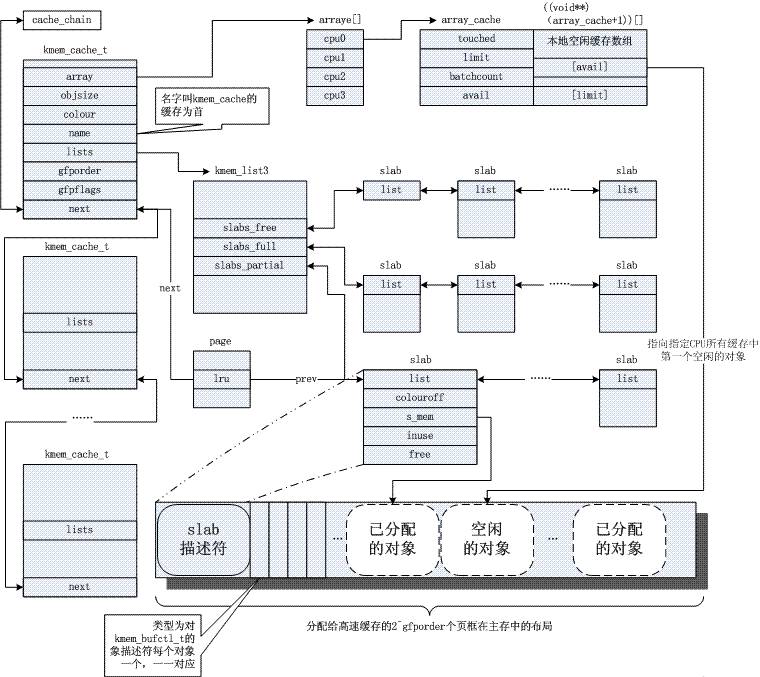
slab allocator: solving internal fragmentation problem
The kernel often relies on the allocation of small objects, which will be allocated countless times during the system life cycle. The slab cache allocator provides this functionality by caching objects of similar size (much smaller than 1page), thus avoiding the common internal fragmentation problem. Here is a picture for now. Regarding its principle, please refer to the common reference 3. Obviously, the slab mechanism is based on the buddy algorithm, and the former is a refinement of the latter.
4. Page recycling/focus mechanism
About the use of the page
In some previous articles, we learned that the Linux kernel allocates pages in many situations.
1. The kernel code may call functions such as alloc_pages to directly allocate pages from the partner system that manages physical pages (free_area free list on the management zone) (see "A Brief Analysis of Linux Kernel Memory Management"). For example: the driver may allocate cache in this way; when creating a process, the kernel also allocates two consecutive pages in this way as the thread_info structure and kernel stack of the process; and so on. Allocating pages from the partner system is the most basic page allocation method, and other memory allocations are based on this method;
2. Many objects in the kernel are managed using the slab mechanism (see "A Brief Analysis of Linux Slub Allocator"). Slab is equivalent to an object pool, which "formats" pages into "objects" and stores them in the pool for human use. When there are insufficient objects in the slab, the slab mechanism will automatically allocate pages from the partner system and "format" them into new objects;
3. Disk cache (see "A Brief Analysis of Reading and Writing Linux Kernel Files"). When reading and writing files, pages are allocated from the partner system and used for disk cache, and then the file data on the disk is loaded into the corresponding disk cache page;
4. Memory mapping. The so-called memory mapping here actually refers to mapping memory pages to user space for use by user processes. Each vma in the task_struct->mm structure of the process represents a mapping, and the real implementation of the mapping is that after the user program accesses the corresponding memory address, the page caused by the page fault exception is allocated and the page table is updated. (See "A Brief Analysis of Linux Kernel Memory Management");
Brief introduction to page recycling
When there is page allocation, there will be page recycling. Page recycling methods can generally be divided into two types:
One is active release. Just like the user program releases the memory once allocated through the malloc function through the free function, the user of the page clearly knows when the page will be used and when it is no longer needed.
The first two allocation methods mentioned above are generally actively released by the kernel program. For pages allocated directly from the partner system, they are actively released by the user using functions such as free_pages. After the page is released, it is directly released to the partner system; objects allocated from the slab (using the kmem_cache_alloc function) are also released by the user. Actively released (using kmem_cache_free function).
Another way to recycle pages is to recycle them through the page frame recycling algorithm (PFRA) provided by the Linux kernel. Users of the page generally treat the page as some kind of cache to improve the operating efficiency of the system. It is good that the cache always exists, but if the cache is gone, it will not cause any errors, only the efficiency will be affected. The user of the page does not know clearly when these cached pages are best retained and when they are best recycled, which is left to the PFRA to take care of.
Simply put, what PFRA has to do is to recycle these pages that can be recycled. In order to prevent the system from getting into page shortage, PFRA will be called periodically in the kernel thread. Or because the system is already page-starved, the kernel execution process trying to allocate pages cannot get the required pages and calls PFRA synchronously.
The latter two allocation methods mentioned above are generally recycled by PFRA (or synchronously recycled by processes such as deleting files and process exits).
PFRA recycling general page
For the first two page allocation methods mentioned above (direct page allocation and object allocation through slab), it may also be necessary to recycle through PFRA.
Users of the page can register a callback function with PFRA (using the register_shrink function). These callback functions are then called by PFRA at appropriate times to trigger the recycling of corresponding pages or objects.
One of the more typical ones is the recycling of dentry. Dentry is an object allocated by slab and used to represent the directory structure of the virtual file system. When the reference count of the dentry is reduced to 0, the dentry is not released directly, but is cached in an LRU linked list for subsequent use. (See "A Brief Analysis of Linux Kernel Virtual File System".)
The dentry in this LRU linked list eventually needs to be recycled, so when the virtual file system is initialized, register_shrinker is called to register the recycling function shrink_dcache_memory.
The superblock objects of all file systems in the system are stored in a linked list. The shrink_dcache_memory function scans this linked list, obtains the LRU of unused dentry of each superblock, and then reclaims some of the oldest dentry from it. As the dentry is released, the corresponding inode will be dereferenced, which may also cause the inode to be released.
After the inode is released, it is also placed in an unused linked list. During initialization, the virtual file system also calls register_shrinker to register the callback function shrink_icache_memory to recycle these unused inodes, so that the disk cache associated with the inode will also be released.
In addition, as the system runs, there may be many idle objects in the slab (for example, after the peak usage of a certain object has passed). The cache_reap function in PFRA is used to recycle these redundant idle objects. If some idle objects can be restored to a page, this page can be released back to the partner system;
What the cache_reap function does is simple to say. All kmem_cache structures storing object pools in the system are connected into a linked list. The cache_reap function scans each object pool, then looks for pages that can be recycled, and recycles them. (Of course, the actual process is a bit more complicated.)
About memory mapping
As mentioned earlier, disk cache and memory mapping are generally recycled by PFRA. PFRA's recycling of the two is very similar. In fact, the disk cache is likely to be mapped to user space. The following is a brief introduction to memory mapping:
Memory mapping is divided into file mapping and anonymous mapping.
File mapping means that the vma representing this mapping corresponds to a certain area in a file. This mapping method is relatively rarely used explicitly by user-mode programs. User-mode programs are generally accustomed to opening a file and then reading/writing the file.
In fact, the user program can also use the mmap system call to map a certain part of a file to memory (corresponding to a vma), and then read and write the file by accessing memory. Although user programs rarely use this method, user processes are full of such mappings: the executable code (including executable files and lib library files) being executed by the process is mapped in this way.
In the article "A Brief Analysis of Linux Kernel File Reading and Writing", we did not discuss the implementation of file mapping. In fact, file mapping directly maps the pages in the disk cache of the file to user space (it can be seen that the pages mapped by the file are a subset of the disk cache pages), and users can read and write them with 0 copies. When using read/write, a copy will occur between user space memory and disk cache.
Anonymous mapping is relative to file mapping, which means that the vma of this mapping does not correspond to a file. For ordinary memory allocation in user space (heap space, stack space), they all belong to anonymous mapping.
Obviously, multiple processes may map to the same file through their own file mappings (for example, most processes map the so file of the libc library); what about anonymous mapping? In fact, multiple processes may map to the same physical memory through their own anonymous mappings. This situation is caused by the parent-child process sharing the original physical memory (copy-on-write) after fork.
File mapping is divided into shared mapping and private mapping. During private mapping, if the process writes to the mapped address space, the disk cache corresponding to the mapping will not be written directly. Instead, copy the original content and then write the copy, and the corresponding page mapping of the current process will be switched to this copy (copy-on-write). In other words, the write operation is visible only to you. For shared mappings, write operations will affect the disk cache and are visible to everyone.
Which pages **** should be recycled
As for recycling, disk cache pages (including file-mapped pages) can be discarded and recycled. But if the page is dirty, it must be written back to disk before being discarded.
The anonymously mapped pages cannot be discarded, because the pages contain data that is being used by the user program, and the data cannot be restored after being discarded. In contrast, the data in disk cache pages itself is saved on disk and can be reproduced.
Therefore, if you want to recycle anonymously mapped pages, you have to dump the data on the pages to disk first. This is page swap (swap). Obviously, the cost of page swapping is relatively higher.
Anonymously mapped pages can be swapped to a swap file or swap partition on the disk (a partition is a device, and a device is also a file. So it is collectively referred to as a swap file below).
So, unless the page is reserved or locked (the page flag PG_reserved/PG_locked is set. In some cases, the kernel needs to temporarily reserve the page to avoid being recycled), all disk cache pages can be Recycling, all anonymous mapped pages are exchangeable.
Although there are many pages that can be recycled, it is obvious that PFRA should recycle/swap as little as possible (because these pages need to be restored from disk, which requires a lot of cost). Therefore, PFRA only reclaims/exchanges a portion of rarely used pages when necessary, and the number of pages reclaimed each time is an empirical value: 32.
So, all these disk cache pages and anonymous mapping pages are placed in a set of LRUs. (Actually, each zone has a set of such LRUs, and pages are placed in the LRUs of their corresponding zones.)
A group of LRUs consists of several pairs of linked lists, including linked lists of disk cache pages (including file mapping pages), linked lists of anonymous mapping pages, etc. A pair of linked lists is actually two linked lists: active and inactive. The former is the recently used page and the latter is the recently unused page.
When recycling pages, PFRA has to do two things. One is to move the least recently used page in the active linked list to the inactive linked list. The other is to try to recycle the least recently used page in the inactive linked list.
Determine the least recently used
Now there is a question, how to determine which pages in the active/inactive list are the least recently used?
One approach is to sort, and when a page is accessed, move it to the tail of the linked list (assuming recycling starts at the head). But this means that the position of the page in the linked list may be moved frequently, and it must be locked before moving (there may be multiple CPUs accessing it at the same time), which has a great impact on efficiency.
The Linux kernel uses the method of marking and ordering. When a page moves between the active and inactive linked lists, it is always placed at the end of the linked list (same as above, assuming recycling starts from the head).
When pages are not moved between linked lists, their order is not adjusted. Instead, the access tag is used to indicate whether the page has just been accessed. If a page with an access tag set in the inactive linked list is accessed again, it will be moved to the active linked list and the access tag will be cleared. (In fact, in order to avoid access conflicts, the page does not move directly from the inactive linked list to the active linked list, but there is a pagevec intermediate structure used as a buffer to avoid locking the linked list.)
There are two types of access tags on the page. One is the PG_referenced tag placed in page->flags, which is set when the page is accessed. For pages in the disk cache (not mapped), the user process accesses them through system calls such as read and write. The system call code will set the PG_referenced flag of the corresponding page.
For memory-mapped pages, user processes can access them directly (without going through the kernel), so the access flag in this case is not set by the kernel, but by mmu. After mapping the virtual address to a physical address, mmu will set an accessed flag on the corresponding page table entry to indicate that the page has been accessed. (In the same way, mmu will place a dirty flag on the page table entry corresponding to the page being written, indicating that the page is a dirty page.)
The access tag of the page (including the above two tags) will be cleared during the process of page recycling by PFRA, because the access tag obviously should have a validity period, and the running cycle of PFRA represents this validity period. The PG_referenced mark in page->flags can be cleared directly, while the accessed bit in the page table entry can only be cleared after finding its corresponding page table entry through the page (see "Reverse Mapping" below).
So, how does the recycling process scan the LRU linked list?
Since there are multiple groups of LRUs (there are multiple zones in the system, and each zone has multiple groups of LRUs), if PFRA scans all LRUs for each recycling to find the pages that are most worthy of recycling, the efficiency of the recycling algorithm will be obvious Less than ideal.
The scanning method used by the Linux kernel PFRA is to define a scanning priority, and use this priority to calculate the number of pages that should be scanned on each LRU. The entire recycling algorithm starts with the lowest priority, scans the least recently used pages in each LRU, and then attempts to reclaim them. If a sufficient number of pages have been recycled after one scan, the recycling process ends. Otherwise, increase the priority and rescan until a sufficient number of pages have been reclaimed. And if a sufficient number of pages cannot be recycled, the priority will be increased to the maximum, that is, all pages will be scanned. At this time, even if the number of recycled pages is still insufficient, the recycling process will end.
Every time an LRU is scanned, the number of pages corresponding to the current priority is obtained from the active linked list and the inactive linked list, and then these pages are processed: if the page cannot be recycled (such as being reserved or locked), then Put back the head of the corresponding linked list (same as above, assuming recycling starts from the head); otherwise, if the access flag of the page is set, clear the flag and put the page back to the end of the corresponding linked list (same as above, assuming recycling starts from the head); Otherwise, the page will be moved from the active linked list to the inactive linked list, or recycled from the inactive linked list.
The scanned pages are determined based on whether the access flag is set or not. So how is this access tag set? There are two ways. One is that when the user accesses the file through system calls such as read/write, the kernel operates the pages in the disk cache and sets the access flags of these pages (set in the page structure); the other is that the process directly accesses the file. When a page has been mapped, mmu will automatically add an access tag (set in the pte of the page table) to the corresponding page table entry. The judgment about the access tag is based on these two pieces of information. (Given a page, there may be multiple PTEs referencing it. How to know whether these PTEs have access tags set? Then you need to find these PTEs through reverse mapping. This will be discussed below.)
PFRA does not tend to recycle anonymously mapped pages from the active linked list, because the memory used by user processes is generally relatively small, and recycling requires swapping, which is costly. Therefore, when there is a lot of remaining memory and a small proportion of anonymous mapping, the pages in the active linked list corresponding to the anonymous mapping will not be recycled. (And if the page has been placed in the inactive list, you don’t have to worry about it anymore.)
Reverse mapping
Like this, during the process of page recycling handled by PFRA, some pages in the LRU's inactive list may be about to be recycled.
If the page is not mapped, it can be recycled directly to the partner system (for dirty pages, write them back first and then recycle them). Otherwise, there is still one troublesome thing to deal with. Because a certain page table entry of the user process is referencing this page, before the page is recycled, the page table entry that refers to it must be given an explanation.
So, the question arises, how does the kernel know which page table entries are referenced by this page? To do this, the kernel establishes a reverse mapping from pages to page table entries.
The vma corresponding to a mapped page can be found through reverse mapping, and the corresponding page table can be found through vma->vm_mm->pgd. Then get the virtual address of the page through page->index. Then find the corresponding page table entry from the page table through the virtual address. (The accessed tag in the page table entry mentioned earlier is achieved through reverse mapping.)
In the page structure corresponding to the page, if the lowest bit of page->mapping is set, it is an anonymous mapping page, and page->mapping points to an anon_vma structure; otherwise, it is a file mapping page, and page->mapping is the address_space corresponding to the file. structure. (Obviously, when the anon_vma structure and address_space structure are allocated, the addresses must be aligned, at least the lowest bit must be 0.)
For anonymously mapped pages, the anon_vma structure serves as a linked list header, connecting all vmas mapping this page through the vma->anon_vma_node linked list pointer. Whenever a page is (anonymously) mapped to a user space, the corresponding vma is added to this linked list.
For file-mapped pages, the address_space structure not only maintains a radix tree for storing disk cache pages, but also maintains a priority search tree for all vmas mapped to the file. Because these VMAs mapped by files do not necessarily map the entire file, it is possible that only a part of the file is mapped. Therefore, in addition to indexing all mapped vmas, this priority search tree also needs to know which areas of the file are mapped to which vmas. Whenever a page (file) is mapped to a user space, the corresponding vma is added to this priority search tree. Therefore, given a page on the disk cache, the position of the page in the file can be obtained through page->index, and all vmas mapped to this page can be found through the priority search tree.
In the above two steps, the magical page->index does two things, getting the virtual address of the page and getting the location of the page in the file disk cache.
vma->vm_start records the first virtual address of the vma, vma->vm_pgoff records the offset of the vma in the corresponding mapping file (or shared memory), and page->index records the page in the file (or shared memory) offset in .
The offset of the page in vma can be obtained through vma->vm_pgoff and page->index, and the virtual address of the page can be obtained by adding vma->vm_start; and the page in the file disk cache can be obtained through page->index. s position.
Page swap in and out
After finding the page table entry that references the page to be recycled, for file mapping, the page table entry that references the page can be cleared directly. When the user accesses this address again, a page fault exception is triggered. The exception handling code will reallocate a page and read the corresponding data from the disk (maybe, the page is already in the corresponding disk cache. Because other processes have accessed it first). This is the same as the first time the page is accessed after mapping;
For anonymous mapping, the page is first written back to the swap file, and then the index of the page in the swap file must be recorded in the page table entry.
There is a present bit in the page table entry. If this bit is cleared, the mmu considers the page table entry invalid. When the page table entry is invalid, other bits are not cared by mmu and can be used to store other information. They are used here to store the index of the page in the swap file (actually the swap file number, the index number in the swap file).
The process of swapping anonymously mapped pages to the swap file (the swap-out process) is very similar to the process of writing dirty pages in the disk cache back to the file.
The swap file also has its corresponding address_space structure. When swapping out, anonymously mapped pages are first placed in the disk cache corresponding to this address_space, and then written back to the swap file just like dirty pages are written back. After the writeback is completed, the page is released (remember, our purpose is to release the page).
So why not just write the page back to the swap file instead of going through the disk cache? Because this page may have been mapped multiple times, it is impossible to modify the corresponding page table entries in the page tables of all user processes at once (modify them to the index of the page in the swap file), so during the process of the page being released , the page is temporarily placed on the disk cache.
Not all modifications to page table entries are successful (for example, the page was accessed again before the modification, so there is no need to recycle the page now), so the time it takes for the page to be placed in the disk cache may also be very long. long.
Similarly, the process of reading anonymously mapped pages from the swap file (the swap-in process) is also very similar to the process of reading file data.
First go to the corresponding disk cache to see if the page is there. If not, then read it in the swap file. The data in the file is also read into the disk cache, and then the corresponding page table entry in the user process's page table will be rewritten to point directly to this page.
This page may not be fetched from the disk cache immediately, because if there are other user processes that are also mapped to this page (their corresponding page table entries have been modified to index into the swap file), they can also reference it here. . The page cannot be fetched from the disk cache until no other page table entries refer to the swap file index.
The final kill
As mentioned earlier, PFRA may have scanned all LRUs and still not been able to reclaim the required pages. Similarly, pages may not be recycled in slab, dentry cache, inode cache, etc.
At this time, what if a certain piece of kernel code must obtain a page (without a page, the system may crash)? PFRA had no choice but to resort to the last resort - OOM (out of memory). The so-called OOM is to find the least important process and then kill it. Relieve system pressure by releasing the memory pages occupied by this process.
5. Memory management architecture
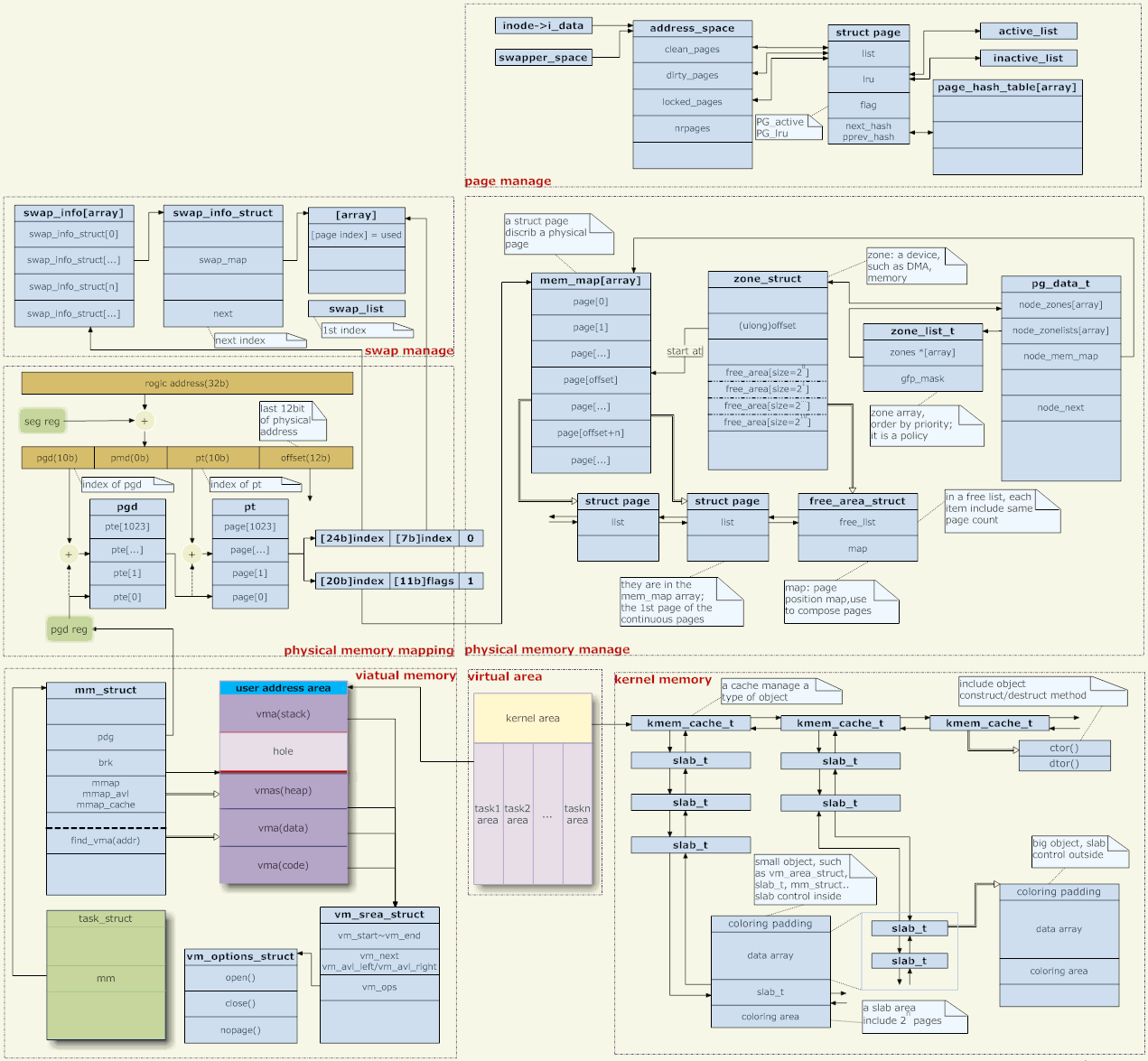
Say a few words about the picture above,
Address mapping
The Linux kernel uses page memory management. The memory address given by the application is a virtual address. It needs to go through several levels of page table level-by-level transformations before it becomes Real physical address.
Think about it, address mapping is still a scary thing. When accessing a memory space represented by a virtual address, several memory accesses are required to obtain the page table entries used for conversion in each level of the page table (the page table is stored in the memory) before the mapping can be completed. In other words, to implement a memory access, the memory is actually accessed N 1 times (N = page table level), and N addition operations need to be performed.
Therefore, address mapping must be supported by hardware, and mmu (memory management unit) is this hardware. And a cache is needed to save the page table. This cache is the TLB (Translation lookaside buffer).
Despite this, address mapping still has considerable overhead. Assuming that the cache access speed is 10 times that of the memory, the hit rate is 40%, and the page table has three levels, then on average one virtual address access consumes about two physical memory access times.
Therefore, some embedded hardware may abandon the use of mmu. Such hardware can run VxWorks (a very efficient embedded real-time operating system), Linux (Linux also has a compilation option to disable mmu), and other systems.
But the advantages of using mmu are also great, the most important one is security considerations. Each process has an independent virtual address space and does not interfere with each other. After giving up address mapping, all programs will run in the same address space. Therefore, on a machine without mmu, a process's out-of-bounds memory access may cause inexplicable errors in other processes, or even cause the kernel to crash.
On the issue of address mapping, the kernel only provides page tables, and the actual conversion is completed by the hardware. So how does the kernel generate these page tables? This has two aspects, the management of virtual address space and the management of physical memory. (In fact, only user-mode address mapping needs to be managed, and kernel-mode address mapping is hard-coded.)
Virtual address management
Each process corresponds to a task structure, which points to an mm structure, which is the memory manager of the process. (For threads, each thread also has a task structure, but they all point to the same mm, so the address space is shared.)
mm->pgd points to the memory containing the page table. Each process has its own mm, and each mm has its own page table. Therefore, when the process is scheduled, the page table is switched (generally there is a CPU register to save the address of the page table, such as CR3 under X86, and page table switching is to change the value of the register). Therefore, the address spaces of each process do not affect each other (because the page tables are different, of course you cannot access other people's address spaces. Except for shared memory, this is deliberately so that different page tables can access the same physical address. ).
The user program's operations on memory (allocation, recycling, mapping, etc.) are all operations on mm, specifically operations on the vma (virtual memory space) on mm. These vma represent various areas of the process space, such as heap, stack, code area, data area, various mapping areas, etc.
The user program's operations on memory will not directly affect the page table, let alone the allocation of physical memory. For example, if malloc succeeds, it only changes a certain vma. The page table will not change, and the allocation of physical memory will not change.
Suppose the user allocates memory and then accesses this memory. Since the relevant mapping is not recorded in the page table, the CPU generates a page fault exception. The kernel catches the exception and checks whether the address where the exception occurred exists in a legal vma. If it is not, give the process a "segmentation fault" and let it crash; if it is, allocate a physical page and establish a mapping for it.
Physical Memory Management
So how is physical memory allocated?
First of all, Linux supports NUMA (non-homogeneous storage architecture), and the first level of physical memory management is media management. The pg_data_t structure describes the medium. Generally speaking, our memory management medium is only memory, and it is uniform, so it can simply be considered that there is only one pg_data_t object in the system.
There are several zones under each medium. Generally there are three, DMA, NORMAL and HIGH.
DMA: Because the DMA bus of some hardware systems is narrower than the system bus, only a part of the address space can be used for DMA. This part of the address is managed in the DMA area (this is a high-end product);
HIGH: High-end memory. In a 32-bit system, the address space is 4G. The kernel stipulates that the range of 3~4G is the kernel space, and 0~3G is the user space (each user process has such a large virtual space) (Figure: middle bottom). As mentioned earlier, the kernel's address mapping is hard-coded, which means that the corresponding page table of 3~4G is hard-coded, and it is mapped to the physical address 0~1G. (In fact, 1G is not mapped, only 896M is mapped. The remaining space is left to map physical addresses larger than 1G, and this part is obviously not hard-coded). Therefore, physical addresses greater than 896M do not have hard-coded page tables to correspond to them, and the kernel cannot directly access them (a mapping must be established). They are called high-end memory (of course, if the machine memory is less than 896M, there is no high-end memory. If it is a 64-bit machine, there is no high-end memory, because the address space is very large, and the space belonging to the kernel is more than 1G);
NORMAL: Memory that does not belong to DMA or HIGH is called NORMAL.
The zone_list above the zone represents the allocation strategy, that is, the zone priority when allocating memory. A kind of memory allocation is often not only allocated in one zone. For example, when allocating a page for the kernel to use, the highest priority is to allocate it from NORMAL. If that doesn't work, allocate it from DMA (HIGH doesn't work because it hasn't been allocated yet). Establish mapping), which is an allocation strategy.
Each memory medium maintains a mem_map, and a corresponding page structure is established for each physical page in the medium to manage physical memory.
Each zone records its starting position on mem_map. And the free pages in this zone are connected through free_area. The allocation of physical memory comes from here. If you remove the page from free_area, it is allocated. (The memory allocation of the kernel is different from that of the user process. The user's use of memory will be supervised by the kernel, and improper use will cause a "segmentation fault"; while the kernel is unsupervised and can only rely on consciousness. Don't use pages that you have not picked from free_area. )
[Establish address mapping]
When the kernel needs physical memory, in many cases the entire page is allocated. To do this, just pick a page from the mem_map above. For example, the kernel mentioned earlier captures page fault exceptions, and then needs to allocate a page to establish mapping.
Speaking of this, there will be a question. When the kernel allocates pages and establishes address mapping, does the kernel use virtual addresses or physical addresses? First of all, the addresses accessed by the kernel code are virtual addresses, because the CPU instructions receive virtual addresses (address mapping is transparent to CPU instructions). However, when establishing address mapping, the content filled in by the kernel in the page table is the physical address, because the goal of address mapping is to obtain the physical address.
So, how does the kernel get this physical address? In fact, as mentioned above, the pages in mem_map are established based on physical memory, and each page corresponds to a physical page.
So we can say that the mapping of virtual addresses is completed by the page structure here, and they give the final physical address. However, the page structure is obviously managed through virtual addresses (as mentioned before, CPU instructions receive virtual addresses). So, the page structure implements other people's virtual address mapping, who will implement the page structure's own virtual address mapping? No one can achieve it.
This leads to a problem mentioned earlier. The page table entries in the kernel space are hard-coded. When the kernel is initialized, the address mapping has been hard-coded in the kernel's address space. The page structure obviously exists in the kernel space, so its address mapping problem has been solved by "hard-coding".
Since the page table entries in the kernel space are hard-coded, another problem arises. The memory in the NORMAL (or DMA) area may be mapped to both kernel space and user space. Being mapped to kernel space is obvious because this mapping is hard-coded. These pages may also be mapped to user space, which is possible in the page missing exception scenario mentioned earlier. Pages mapped to user space should be obtained first from the HIGH area, because these memories are inconvenient for the kernel to access, so it is best to give them to user space. However, the HIGH area may be exhausted, or there may be no HIGH area in the system due to insufficient physical memory on the device. Therefore, mapping the NORMAL area to user space is inevitable.
However, there is no problem that the memory in the NORMAL area is mapped to both kernel space and user space, because if a page is being used by the kernel, the corresponding page should have been removed from the free_area, so the page fault exception handling code will no longer This page is mapped to user space. The same is true in reverse. The page mapped to user space has naturally been removed from free_area, and the kernel will no longer use this page.
Kernel space management
In addition to using the entire page of memory, sometimes the kernel also needs to allocate a space of any size just like the user program uses malloc. This function is implemented by the slab system.
Slab is equivalent to establishing an object pool for some structural objects commonly used in the kernel, such as the pool corresponding to the task structure, the pool corresponding to the mm structure, and so on.
Slab also maintains general object pools, such as "32-byte size" object pool, "64-byte size" object pool, etc. The commonly used kmalloc function in the kernel (similar to user-mode malloc) is allocated in these general object pools.
In addition to the memory space actually used by the object, slab also has its corresponding control structure. There are two ways to organize it. If the object is larger, the control structure uses a special page to save it; if the object is smaller, the control structure uses the same page as the object space.
In addition to slab, Linux 2.6 also introduced mempool (memory pool). The intention is: we do not want certain objects to fail to be allocated due to insufficient memory, so we allocate several in advance and store them in mempool. Under normal circumstances, the resources in mempool will not be touched when allocating objects, and will be allocated through slab as usual. When the system memory is in short supply and it is no longer possible to allocate memory through slab, the contents of the mempool will be used.
Page swap in and out(Picture: upper right)
Page swapping in and out is another very complex system. Swapping out memory pages to disk and mapping disk files to memory are two very similar processes (the motivation behind swapping out memory pages to disk is to load them back into memory from disk in the future). So swap reuses some mechanisms of the file subsystem.
Swapping pages in and out is a very CPU and IO-intensive matter, but due to the historical reason that memory is expensive, we have to use disks to expand memory. But now that memory is getting cheaper, we can easily install several gigabytes of memory and then shut down the swap system. Therefore, the implementation of swap is really difficult to explore, so I won’t go into details here. (See also: "A Brief Analysis of Linux Kernel Page Recycling")
[User Space Memory Management]
Malloc is a library function of libc, and user programs generally use it (or similar functions) to allocate memory space.
There are two ways for libc to allocate memory. One is to adjust the size of the heap, and the other is to mmap a new virtual memory area (the heap is also a vma).
In the kernel, the heap is a vma with a fixed end and a retractable end (picture: middle left). The scalable end is adjusted through the brk system call. Libc manages the heap space. When the user calls malloc to allocate memory, libc tries to allocate it from the existing heap. If the heap space is not enough, increase the heap space through brk.
When the user frees the allocated space, libc may reduce the heap space through brk. However, it is easy to increase the heap space but difficult to reduce it. Consider a situation where the user space has continuously allocated 10 blocks of memory, and the first 9 blocks have been freed. At this time, even if the 10th block that is not free is only 1 byte in size, libc cannot reduce the heap size. Because only one end of the pile can be expanded and contracted, and the middle cannot be hollowed out. The 10th block of memory occupies the scalable end of the heap. The size of the heap cannot be reduced, and related resources cannot be returned to the kernel.
When the user mallocs a large memory, libc will map a new vma through the mmap system call. Because heap size adjustment and space management are still troublesome, it will be more convenient to rebuild a vma (the free problem mentioned above is also one of the reasons).
So why not always mmap a new vma during malloc? First, for the allocation and recycling of small spaces, the heap space managed by libc can already meet the needs, and there is no need to make system calls every time. And vma is based on page, and the minimum is to allocate one page; second, too many vma will reduce system performance. Page fault exceptions, creation and destruction of vma, heap space resizing, etc. all require operations on vma. You need to find the vma (or those) that need to be operated among all vma in the current process. Too many vmas will inevitably lead to performance degradation. (When the process has fewer VMAs, the kernel uses a linked list to manage VMAs; when there are more VMAs, a red-black tree is used instead.)
[User’s stack]
Like the heap, the stack is also a vma (picture: middle left). This vma is fixed at one end and extendable at the other end (note, it cannot be contracted). This vma is special. There is no system call like brk to stretch this vma. It is stretched automatically.
When the virtual address accessed by the user exceeds this vma, the kernel will automatically increase the vma when handling page fault exceptions. The kernel will check the current stack register (such as ESP), and the virtual address accessed cannot exceed ESP plus n (n is the maximum number of bytes that the CPU push instruction can push onto the stack at one time). In other words, the kernel uses ESP as a benchmark to check whether the access is out of bounds.
However, the value of ESP can be freely read and written by user-mode programs. What if the user program adjusts ESP and makes the stack very large? There is a set of configurations about process restrictions in the kernel, including the stack size configuration. The stack can only be so large, and if it is larger, an error will occur.
For a process, the stack can generally be stretched relatively large (eg: 8MB). But what about threads?
First, what is going on with the thread stack? As mentioned earlier, the mm of a thread shares its parent process. Although the stack is a vma in mm, the thread cannot share this vma with its parent process (two running entities obviously do not need to share a stack). Therefore, when the thread is created, the thread library creates a new vma through mmap as the thread's stack (generally larger than: 2M).
It can be seen that the thread's stack is not a real stack in a sense. It is a fixed area and has a very limited capacity.
Through this article, you should have a basic understanding of Linux memory management. It is an effective way to convert and allocate virtual memory and physical memory, and can adapt to the diverse needs of Linux systems. Of course, memory management is not static. It needs to be customized and modified according to the specific hardware platform and kernel version. In short, memory management is an indispensable component in the Linux system and is worthy of your in-depth study and mastery.
The above is the detailed content of Linux memory management: how to convert and allocate virtual memory and physical memory. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



