
 System Tutorial
LINUX
Detailed explanation of Linux multi-threaded programming locks: how to avoid contention and deadlock
System Tutorial
LINUX
Detailed explanation of Linux multi-threaded programming locks: how to avoid contention and deadlock
Detailed explanation of Linux multi-threaded programming locks: how to avoid contention and deadlock

In Linux multi-threaded programming, locks are a very important mechanism that can avoid competition and deadlock between threads. However, if locks are used incorrectly, performance degradation and erratic behavior can result. This article will introduce common lock types in Linux, how to use them correctly, and how to avoid problems such as contention and deadlock.
In programming, the concept of object mutex lock is introduced to ensure the integrity of shared data operations. Each object corresponds to a mark called a "mutex lock", which is used to ensure that only one thread can access the object at any time. The mutex lock mechanism implemented by Linux includes POSIX mutex locks and kernel mutex locks. This article mainly talks about POSIX mutex locks, that is, inter-thread mutex locks.
Semaphores are used for multi-thread and multi-task synchronization. When one thread completes a certain action, it tells other threads through the semaphore, and other threads then perform certain actions (when everyone is in sem_wait, they block there ). Mutex locks are used for multi-thread and multi-task mutual exclusion. If one thread occupies a certain resource, other threads cannot access it. Until this thread is unlocked, other threads can start to use this resource. For example, access to global variables sometimes requires locking and unlocking after the operation is completed. Sometimes locks and semaphores are used at the same time"
That is to say, the semaphore does not necessarily lock a certain resource, but a process concept. For example: there are two threads A and B. The B thread has to wait for the A thread to complete a certain task before proceeding with the following. Step, this task does not necessarily involve locking a certain resource, but can also perform some calculations or data processing. The thread mutex is the concept of "locking a certain resource". During the lock period, other threads cannot operate on the protected data. In some cases the two are interchangeable.
The difference between the two:
Scope
Semaphore: inter-process or inter-thread (linux only between threads)
Mutex lock: inter-thread
When locked
Semaphore: As long as the value of the semaphore is greater than 0, other threads can sem_wait successfully. After success, the value of the semaphore is reduced by one. If the value is not greater than 0, sem_wait blocks until the value is increased by one after sem_post is released. In a word, the value of the semaphore>=0.
Mutex lock: As long as it is locked, no other thread can access the protected resource. If there is no lock, the resource is obtained successfully, otherwise it blocks and waits for the resource to be available. In a word, the vlaue of a thread mutex can be negative.
Multithreading
A thread is the smallest unit that runs independently in a computer and occupies very little system resources when running. Compared with multi-process, multi-process has some advantages that multi-process does not have. The most important thing is: for multi-threading, it can save resources more than multi-process.
Thread creation
In Linux, the newly created thread is not in the original process, but the system calls clone() through a system call. The system copies a process that is exactly the same as the original process and executes the thread function in this process.
In Linux, the thread is created through the function pthread_create() function:
pthread_create()
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*st
in:
Thread represents a pointer of type pthread_t;
attr is used to specify some attributes of the thread;
start_routine represents a function pointer, which is a thread calling function;
arg represents the parameters passed to the thread calling function.
When the thread is created successfully, the function pthread_create() returns 0. If the return value is not 0, it means that the thread creation failed. For thread attributes, they are defined in the structure pthread_attr_t.
The thread creation process is as follows:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
printf("this is a new thread, thread ID is %u\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, NULL) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
return 0;
}
In the above code, the pthread_self() function is used. The function of this function is to obtain the thread ID of this thread. sleep() in the main function is used to put the main process in a waiting state to allow thread execution to complete. The final execution effect is as follows:
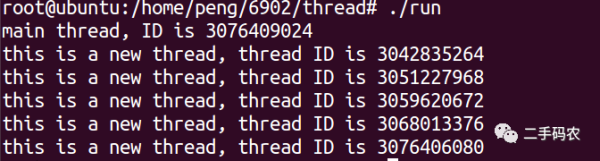
So, how to use arg to pass parameters to sub-threads? The specific implementation is as follows:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
free(id);
return 0;
}
The final execution effect is shown in the figure below:
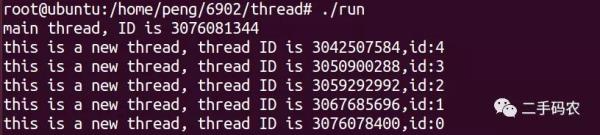
What will happen if the main process ends early? As shown in the following code:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
sleep(2);
printf("thread %u is done!\n", newthid);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
//sleep(2);
free(pt);
free(id);
return 0;
}
At this time, the main process ends early and the process will recycle resources. At this time, the threads will exit execution. The running results are as follows:

Thread hangs
In the above implementation process, in order to enable the main thread to wait for each sub-thread to complete execution before exiting, the free() function is used. In Linux multi-threading, the pthread_join() function can also be used to wait. For other threads, the specific form of the function is:
int pthread_join(pthread_t thread, void **retval);
The function pthread_join() is used to wait for the end of a thread, and its call will be suspended.
一个线程仅允许一个线程使用pthread_join()等待它的终止。
如需要在主线程中等待每一个子线程的结束,如下述代码所示:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
printf("thread %u is done\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的执行效果如下所示:
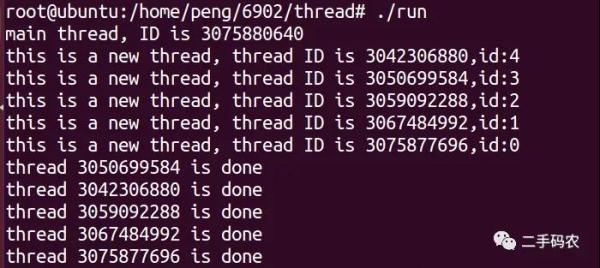
注:在编译的时候需要链接libpthread.a:
g++ xx.c -lpthread -o xx
互斥锁mutex
多线程的问题引入
多线程的最大的特点是资源的共享,但是,当多个线程同时去操作(同时去改变)一个临界资源时,会破坏临界资源。如利用多线程同时写一个文件:
#include
#include
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
执行以上的代码,我们会发现,得到的结果是混乱的,出现上述的最主要的原因是,我们在编写多线程代码的过程中,每一个线程都尝试去写同一个文件,这样便出现了上述的问题,这便是共享资源的同步问题,在Linux编程中,线程同步的处理方法包括:信号量,互斥锁和条件变量。
互斥锁
互斥锁是通过锁的机制来实现线程间的同步问题。互斥锁的基本流程为:
初始化一个互斥锁:pthread_mutex_init()函数
加锁:pthread_mutex_lock()函数或者pthread_mutex_trylock()函数
对共享资源的操作
解锁:pthread_mutex_unlock()函数
注销互斥锁:pthread_mutex_destory()函数
其中,在加锁过程中,pthread_mutex_lock()函数和pthread_mutex_trylock()函数的过程略有不同:
当使用pthread_mutex_lock()函数进行加锁时,若此时已经被锁,则尝试加锁的线程会被阻塞,直到互斥锁被其他线程释放,当pthread_mutex_lock()函数有返回值时,说明加锁成功;
而使用pthread_mutex_trylock()函数进行加锁时,若此时已经被锁,则会返回EBUSY的错误码。
同时,解锁的过程中,也需要满足两个条件:
解锁前,互斥锁必须处于锁定状态;
必须由加锁的线程进行解锁。
当互斥锁使用完成后,必须进行清除。
有了以上的准备,我们重新实现上述的多线程写操作,其实现代码如下所示:
#include
#include
pthread_mutex_t mutex;
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 加锁
if (pthread_mutex_lock(&mutex) != 0){
fprintf(stdout, "lock error!\n");
}
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
// 解锁
pthread_mutex_unlock(&mutex);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
// 初始化互斥锁
if (pthread_mutex_init(&mutex, NULL) != 0){
// 互斥锁初始化失败
free(pt);
free(id);
return 1;
}
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的结果为:
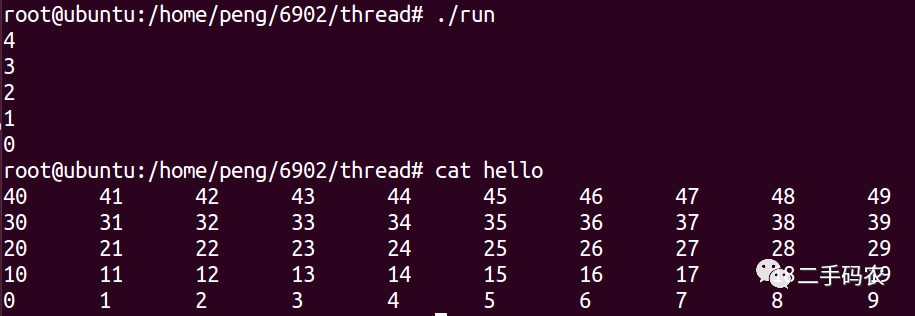
通过本文的介绍,您应该已经了解了Linux多线程编程中的常见锁类型、正确使用锁的方法以及如何避免竞争和死锁等问题。锁机制是多线程编程中必不可少的一部分,掌握它们可以使您的代码更加健壮和可靠。在实际应用中,应该根据具体情况选择合适的锁类型,并遵循最佳实践,以确保程序的高性能和可靠性。
The above is the detailed content of Detailed explanation of Linux multi-threaded programming locks: how to avoid contention and deadlock. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 How to view the docker process
Apr 15, 2025 am 11:48 AM
How to view the docker process
Apr 15, 2025 am 11:48 AM
Docker process viewing method: 1. Docker CLI command: docker ps; 2. Systemd CLI command: systemctl status docker; 3. Docker Compose CLI command: docker-compose ps; 4. Process Explorer (Windows); 5. /proc directory (Linux).
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
The reasons for the installation of VS Code extensions may be: network instability, insufficient permissions, system compatibility issues, VS Code version is too old, antivirus software or firewall interference. By checking network connections, permissions, log files, updating VS Code, disabling security software, and restarting VS Code or computers, you can gradually troubleshoot and resolve issues.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
The main uses of Linux include: 1. Server operating system, 2. Embedded system, 3. Desktop operating system, 4. Development and testing environment. Linux excels in these areas, providing stability, security and efficient development tools.
 How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
Although Notepad cannot run Java code directly, it can be achieved by using other tools: using the command line compiler (javac) to generate a bytecode file (filename.class). Use the Java interpreter (java) to interpret bytecode, execute the code, and output the result.
 How to use VSCode
Apr 15, 2025 pm 11:21 PM
How to use VSCode
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCode) is a cross-platform, open source and free code editor developed by Microsoft. It is known for its lightweight, scalability and support for a wide range of programming languages. To install VSCode, please visit the official website to download and run the installer. When using VSCode, you can create new projects, edit code, debug code, navigate projects, expand VSCode, and manage settings. VSCode is available for Windows, macOS, and Linux, supports multiple programming languages and provides various extensions through Marketplace. Its advantages include lightweight, scalability, extensive language support, rich features and version
