
 System Tutorial
LINUX
Linux process group scheduling mechanism: how to group and schedule processes
System Tutorial
LINUX
Linux process group scheduling mechanism: how to group and schedule processes
Linux process group scheduling mechanism: how to group and schedule processes

Process group is a way to classify and manage processes in Linux systems. It can put processes with the same characteristics or relationships together to form a logical unit. The function of the process group is to facilitate the control, communication and resource allocation of processes to improve the efficiency and security of the system. Process group scheduling is a mechanism for scheduling process groups in Linux systems. It can allocate appropriate CPU time and resources based on the attributes and needs of the process group, thereby improving the concurrency and responsiveness of the system. But, do you really understand the Linux process group scheduling mechanism? Do you know how to create and manage process groups in Linux? Do you know how to use and configure the process group scheduling mechanism under Linux? This article will introduce you to the relevant knowledge of the Linux process group scheduling mechanism in detail, allowing you to better use and understand this powerful kernel function under Linux.

Another magical process scheduling problem was encountered. During the system restart process, it was found that the system hung and was reset after 30 seconds. The real cause of the system reset was the system restarted by the hardware watchdog, not the original system. Normal reboot process. The reset time of the hardware dog record is pushed forward by 30 seconds when the dog is not fed. When analyzing the serial port record log, the log at that time printed a sentence: "sched: RT throttling activated".
It can be seen from the linux-3.0.101-0.7.17 version kernel code that sched_rt_runtime_exceeded prints this sentence. In the kernel process group scheduling process, real-time process scheduling is restricted by rt_rq->rt_throttled. Let’s talk about the process group scheduling mechanism in Linux in detail below.
Process group scheduling mechanism
Group scheduling is a concept in cgroup, which refers to treating N processes as a whole and participating in the scheduling process in the system. This is reflected in the example: Task A has 8 processes or threads, and task B has 2 processes or threads. Threads, if there are still other processes or threads, it is necessary to control the CPU usage of task A to not be higher than 40%, the CPU usage of task B to not be higher than 40%, and the occupancy of other tasks to not be less than 20%, then There are cgroup threshold settings, cgroup A is set to 200, cgroup B is set to 200, and other tasks default to 100, thus realizing the CPU control function.
In the kernel, process groups are managed by task_group, and many of the contents involved are cgroup control mechanisms. In addition, the development unit is being written. Here we refer to the part that focuses on group scheduling. See the following comments for details.
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
//普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
//公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
There are two types of scheduling units, namely ordinary scheduling units and real-time process scheduling units.
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
//当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
//当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq *my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
Let’s take a look at the scheduling queue, because the options that need to be explained for real-time scheduling and ordinary scheduling queues are similar. Take the real-time queue as an example:
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};
Through the analysis of the above three structures, the following picture can be obtained (click to enlarge the picture):
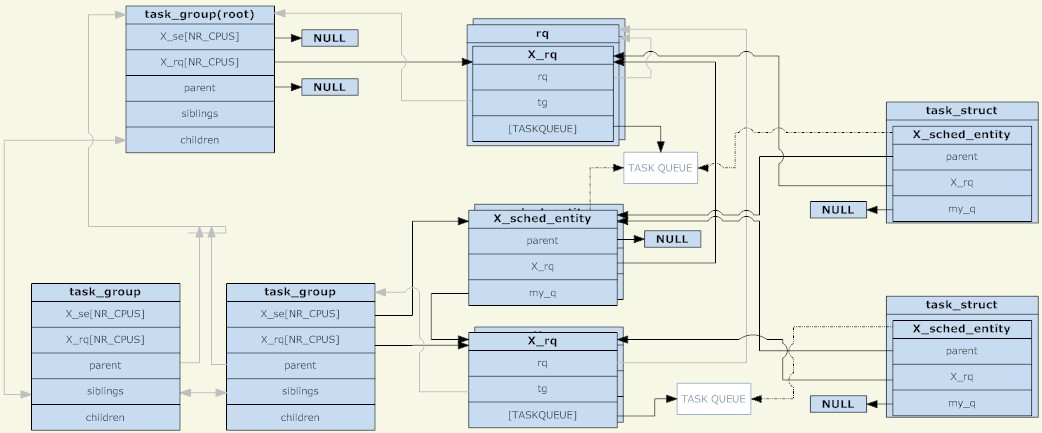
task_group
As can be seen from the figure, the scheduling unit and the scheduling queue are combined into a tree node, which is another separate tree structure. However, it should be noted that the scheduling unit will only operate when there is a TASK_RUNNING process in the scheduling unit. is placed in the dispatch queue.
Another point is that before there was group scheduling, there was only one scheduling queue on each CPU. At that time, it could be understood that all processes were in one scheduling group. Now, each scheduling group has a scheduling queue on each CPU. During the scheduling process, the system originally selected a process to run. Currently, it selects a scheduling unit to run. When scheduling occurs, the schedule process starts from the root_task_group and looks for the scheduling unit determined by the scheduling policy. When the scheduling unit is task_group, it enters the task_group. The run queue selects a suitable scheduling unit and finally finds a suitable task scheduling unit. The whole process is a tree traversal. The task_group with the TASK_RUNNING process is the node of the tree, and the task scheduling unit is the leaf of the tree.
Group process scheduling policy
The purpose of group process scheduling is no different from the original, which is to complete real-time process scheduling and ordinary process scheduling, that is, rt and cfs scheduling.
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
The above is the detailed content of Linux process group scheduling mechanism: how to group and schedule processes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 How to view the docker process
Apr 15, 2025 am 11:48 AM
How to view the docker process
Apr 15, 2025 am 11:48 AM
Docker process viewing method: 1. Docker CLI command: docker ps; 2. Systemd CLI command: systemctl status docker; 3. Docker Compose CLI command: docker-compose ps; 4. Process Explorer (Windows); 5. /proc directory (Linux).
 What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
Troubleshooting steps for failed Docker image build: Check Dockerfile syntax and dependency version. Check if the build context contains the required source code and dependencies. View the build log for error details. Use the --target option to build a hierarchical phase to identify failure points. Make sure to use the latest version of Docker engine. Build the image with --t [image-name]:debug mode to debug the problem. Check disk space and make sure it is sufficient. Disable SELinux to prevent interference with the build process. Ask community platforms for help, provide Dockerfiles and build log descriptions for more specific suggestions.
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
The reasons for the installation of VS Code extensions may be: network instability, insufficient permissions, system compatibility issues, VS Code version is too old, antivirus software or firewall interference. By checking network connections, permissions, log files, updating VS Code, disabling security software, and restarting VS Code or computers, you can gradually troubleshoot and resolve issues.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 How to back up vscode settings and extensions
Apr 15, 2025 pm 05:18 PM
How to back up vscode settings and extensions
Apr 15, 2025 pm 05:18 PM
How to back up VS Code configurations and extensions? Manually backup the settings file: Copy the key JSON files (settings.json, keybindings.json, extensions.json) to a safe location. Take advantage of VS Code synchronization: enable synchronization with your GitHub account to automatically back up all relevant settings and extensions. Use third-party tools: Back up configurations with reliable tools and provide richer features such as version control and incremental backups.
