

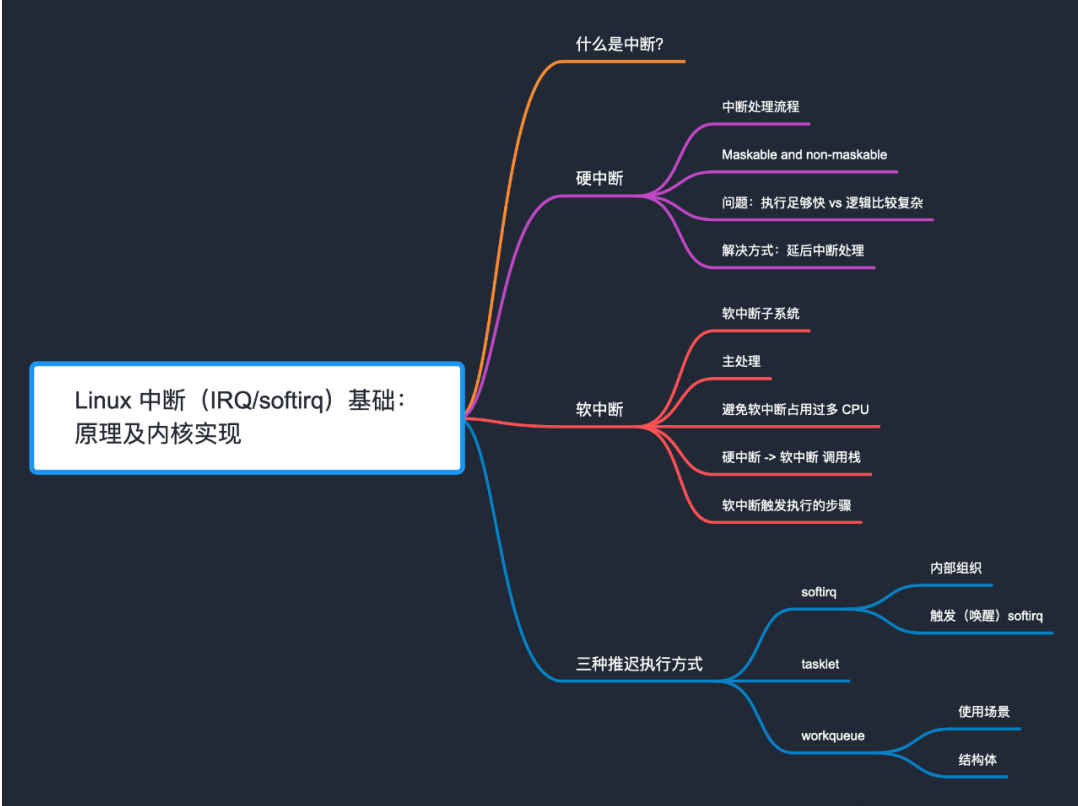
An important application scenario for interrupts (IRQs), especially softirqs, is to send and receive packets over the network, but this is not the only application scenario. This article has compiled the general basic knowledge of IRQ/softirq. These contents are not directly related to network packet sending and receiving, although the purpose of organizing this article is to better understand network sending and receiving packets.
CPU handles multiple tasks through time division multiplexing, including hardware tasks (such as disk reading and writing, keyboard input) and software tasks (such as network packet processing). At any time, a CPU can only handle one task. When a hardware or software task is not being executed at the moment, but it is expected to be processed immediately by the CPU, it will send an interrupt request to the CPU, hoping that the CPU will suspend the current work and process the task first. Interrupts notify the CPU in the form of events, so we often see the description "XX interrupt event will be triggered under XX conditions".
Two types:
Device that manages interrupts: Advanced Programmable Interrupt Controller (APIC).
Interruptions may occur at any time and must be handled immediately after they occur. Processing flow after receiving interrupt event:
Maskable interrupts can be masked (closed) and restored using sti/cli on x64_64:
static inline void native_irq_disable(void) {
asm volatile("cli": : :"memory"); // 清除 IF 标志位
}
static inline void native_irq_enable(void) {
asm volatile("sti": : :"memory"); // 设置 IF 标志位
}
During the masking period, this type of interrupt will no longer trigger new interrupt events. Most IRQs are of this type. Example: The network card's hardware for sending and receiving packets is interrupted.
Non-maskable interrupts cannot be masked, so they are more urgent in effect.
Two characteristics of IRQ handler:
There is an inherent contradiction here.
Traditionally, the way to resolve this inherent contradiction is to divide interrupt handling into two parts:
This method is called the postponed processing or delayed processing of the interrupt. It used to be the only way to defer, but not anymore. It is now a general term that refers to various ways of deferring interrupt processing. In this way, the interrupt is divided into two parts:
Linux 中的三种推迟中断(deferred interrupts):
后面会具体介绍。
软中断是一个内核子系统:
1、每个 CPU 上会初始化一个 ksoftirqd 内核线程,负责处理各种类型的 softirq 中断事件;
用 cgroup ls 或者 ps -ef 都能看到:
$ systemd-cgls -k | grep softirq # -k: include kernel threads in the output ├─ 12 [ksoftirqd/0] ├─ 19 [ksoftirqd/1] ├─ 24 [ksoftirqd/2] ...
2、软中断事件的 handler 提前注册到 softirq 子系统, 注册方式 open_softirq(softirq_id, handler)
例如,注册网卡收发包(RX/TX)软中断处理函数:
// net/core/dev.c open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action);
3、软中断占 CPU 的总开销:可以用 top 查看,里面 si 字段就是系统的软中断开销(第三行倒数第二个指标):
$ top -n1 | head -n3 top - 18:14:05 up 86 days, 23:45, 2 users, load average: 5.01, 5.56, 6.26 Tasks: 969 total, 2 running, 733 sleeping, 0 stopped, 2 zombie %Cpu(s): 13.9 us, 3.2 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
smpboot.c 类似于一个事件驱动的循环,里面会调度到 ksoftirqd 线程,执行 pending 的软中断。ksoftirqd 里面会进一步调用到 __do_softirq,
软中断方式的潜在影响:推迟执行部分(比如 softirq)可能会占用较长的时间,在这个时间段内, 用户空间线程只能等待。反映在 top 里面,就是 si 占比。
不过 softirq 调度循环对此也有改进,通过 budget 机制来避免 softirq 占用过久的 CPU 时间。
unsigned long end = jiffies + MAX_SOFTIRQ_TIME;
...
restart:
while ((softirq_bit = ffs(pending))) {
...
h->action(h); // 这里面其实也有机制,避免 softirq 占用太多 CPU
...
}
...
pending = local_softirq_pending();
if (pending) {
if (time_before(jiffies, end) && !need_resched() && --max_restart) // 避免 softirq 占用太多 CPU
goto restart;
}
...
前面提到,softirq 是一种推迟中断处理机制,将 IRQ 的大部分处理逻辑推迟到了这里执行。两条路径都会执行到 softirq 主处理逻辑 __do_softirq(),
1、CPU 调度到 ksoftirqd 线程时,会执行到 __do_softirq();
2、每次 IRQ handler 退出时:do_IRQ() -> ...。
do_IRQ() 是内核中最主要的 IRQ 处理方式。它执行结束时,会调用 exiting_irq(),这会展开成 irq_exit()。后者会检查是pending 的 softirq,有的话就唤醒:
// arch/x86/kernel/irq.c if (!in_interrupt() && local_softirq_pending()) invoke_softirq();
进而会使 CPU 执行到 __do_softirq()。
To summarize, each softirq goes through the following stages: 每个软中断会经过下面几个阶段:
open_softirq() 注册软中断处理函数;raise_softirq() 将一个软中断标记为 deferred interrupt,这会唤醒改软中断(但还没有开始处理);ksoftirqd 内核线程时,会将所有等待处理的 deferred interrupt(也就是 softirq)拿出来,执行对应的处理方法(softirq handler);以收包软中断为例, IRQ handler 并不执行 NAPI,只是触发它,在里面会执行到 raise NET_RX_SOFTIRQ;真正的执行在 softirq,里面会调用网卡的 poll() 方法收包。IRQ handler 中会调用 napi_schedule(),然后启动 NAPI poll(),
这里需要注意,虽然 IRQ handler 做的事情非常少,但是接下来处理这个包的 softirq 和 IRQ 在同一个 CPU 运行。这就是说,如果大量的包都放到了同一个 RX queue,那虽然 IRQ 的开销可能并不多,但这个 CPU 仍然会非常繁忙,都花在 softirq 上了。解决方式:RPS。它并不会降低延迟,只是将包重新分发:RXQ -> CPU。
前面提到,Linux 中的三种推迟中断执行的方式:
其中,
前面已经看到, Linux 在每个 CPU 上会创建一个 ksoftirqd 内核线程。
softirqs 是在 Linux 内核编译时就确定好的,例外网络收包对应的 NET_RX_SOFTIRQ 软中断。因此是一种静态机制。如果想加一种新 softirq 类型,就需要修改并重新编译内核。
在内部是用一个数组(或称向量)来管理的,每个软中断号对应一个 softirq handler。数组和注册:
// kernel/softirq.c
// NR_SOFTIRQS 是 enum softirq type 的最大值,在 5.10 中是 10,见下面
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
void open_softirq(int nr, void (*action)(struct softirq_action *)) {
softirq_vec[nr].action = action;
}
5.10 中所有类型的 softirq:
// include/linux/interrupt.h
enum {
HI_SOFTIRQ=0, // tasklet
TIMER_SOFTIRQ, // timer
NET_TX_SOFTIRQ, // networking
NET_RX_SOFTIRQ, // networking
BLOCK_SOFTIRQ, // IO
IRQ_POLL_SOFTIRQ,
TASKLET_SOFTIRQ, // tasklet
SCHED_SOFTIRQ, // schedule
HRTIMER_SOFTIRQ, // timer
RCU_SOFTIRQ, // lock
NR_SOFTIRQS
};
也就是在 cat /proc/softirqs 看到的哪些。
$ cat /proc/softirqs CPU0 CPU1 ... CPU46 CPU47 HI: 2 0 ... 0 1 TIMER: 443727 467971 ... 313696 270110 NET_TX: 57919 65998 ... 42287 54840 NET_RX: 28728 5262341 ... 81106 55244 BLOCK: 261 1564 ... 268986 463918 IRQ_POLL: 0 0 ... 0 0 TASKLET: 98 207 ... 129 122 SCHED: 1854427 1124268 ... 5154804 5332269 HRTIMER: 12224 68926 ... 25497 24272 RCU: 1469356 972856 ... 5961737 5917455
void raise_softirq(unsigned int nr) {
local_irq_save(flags); // 关闭 IRQ
raise_softirq_irqoff(nr); // 唤醒 ksoftirqd 线程(但执行不在这里,在 ksoftirqd 线程中)
local_irq_restore(flags); // 打开 IRQ
}
if (!in_interrupt())
wakeup_softirqd();
static void wakeup_softirqd(void) {
struct task_struct *tsk = __this_cpu_read(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
}
以收包软中断为例, IRQ handler 并不执行 NAPI,只是触发它,在里面会执行到 raise NET_RX_SOFTIRQ;真正的执行在 softirq,里面会调用网卡的 poll() 方法收包。IRQ handler 中会调用 napi_schedule(),然后启动 NAPI poll()。
如果对内核源码有一定了解就会发现,softirq 用到的地方非常少,原因之一就是上面提到的,它是静态编译的, 靠内置的 ksoftirqd 线程来调度内置的那 9 种 softirq。如果想新加一种,就得修改并重新编译内核, 所以开发成本非常高。
实际上,实现推迟执行的更常用方式 tasklet。它构建在 softirq 机制之上, 具体来说就是使用了上面提到的两种 softirq:
HI_SOFTIRQTASKLET_SOFTIRQ换句话说,tasklet 是可以在运行时(runtime)创建和初始化的 softirq,
void __init softirq_init(void) {
for_each_possible_cpu(cpu) {
per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head;
per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head;
}
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}
内核软中断子系统初始化了两个 per-cpu 变量:
struct tasklet_struct {
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
tasklet 再执行针对 list 的循环:
static void tasklet_action(struct softirq_action *a)
{
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));
local_irq_enable();
while (list) {
if (tasklet_trylock(t)) {
t->func(t->data);
tasklet_unlock(t);
}
...
}
}
tasklet 在内核中的使用非常广泛。不过,后面又出现了第三种方式:workqueue。
这也是一种推迟执行机制,与 tasklet 有点类似,但也有很大不同。
// Documentation/core-api/workqueue.rst: There are many cases where an asynchronous process execution context is needed and the workqueue (wq) API is the most commonly used mechanism for such cases. When such an asynchronous execution context is needed, a work item describing which function to execute is put on a queue. An independent thread serves as the asynchronous execution context. The queue is called workqueue and the thread is called worker. While there are work items on the workqueue the worker executes the functions associated with the work items one after the other. When there is no work item left on the workqueue the worker becomes idle. When a new work item gets queued, the worker begins executing again.
简单来说,workqueue 子系统提供了一个接口,通过这个接口可以创建内核线程来处理从其他地方 enqueue 过来的任务。这些内核线程就称为 worker threads,内置的 per-cpu worker threads:
$ systemd-cgls -k | grep kworker ├─ 5 [kworker/0:0H] ├─ 15 [kworker/1:0H] ├─ 20 [kworker/2:0H] ├─ 25 [kworker/3:0H]
// include/linux/workqueue.h
struct worker_pool {
spinlock_t lock;
int cpu;
int node;
int id;
unsigned int flags;
struct list_head worklist;
int nr_workers;
...
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
struct lockdep_map lockdep_map;
};
kworker 线程调度 workqueues,原理与 ksoftirqd 线程调度 softirqs 一样。但是我们可以为 workqueue 创建新的线程,而 softirq 则不行。
[1]Interrupts and Interrupt Handling: https://0xax.gitbooks.io/linux-insides/content/Interrupts/linux-interrupts-9.html
The above is the detailed content of Basics of Linux interrupts (IRQ/softirq): principles and kernel implementation. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



