
 System Tutorial
LINUX
Understand the four major IO scheduling algorithms of the Linux kernel in one article
System Tutorial
LINUX
Understand the four major IO scheduling algorithms of the Linux kernel in one article
Understand the four major IO scheduling algorithms of the Linux kernel in one article

The Linux kernel contains 4 types of IO schedulers, namely Noop IO scheduler, Anticipatory IO scheduler, Deadline IO scheduler and CFQ IO scheduler.
Normally, disk read and write delays are caused by the movement of the disk head to the cylinder. In order to solve this delay, the kernel mainly adopts two strategies: caching and IO scheduling algorithms.
Scheduling algorithm concept
- When a block of data is written to or read from the device, the request is placed in a queue waiting for completion.
- Each block device has its own queue.
- The I/O scheduler is responsible for maintaining the order of these queues to utilize the media more efficiently. The I/O scheduler turns unordered I/O operations into ordered I/O operations.
- Before scheduling, the kernel must first determine how many requests there are in the queue.
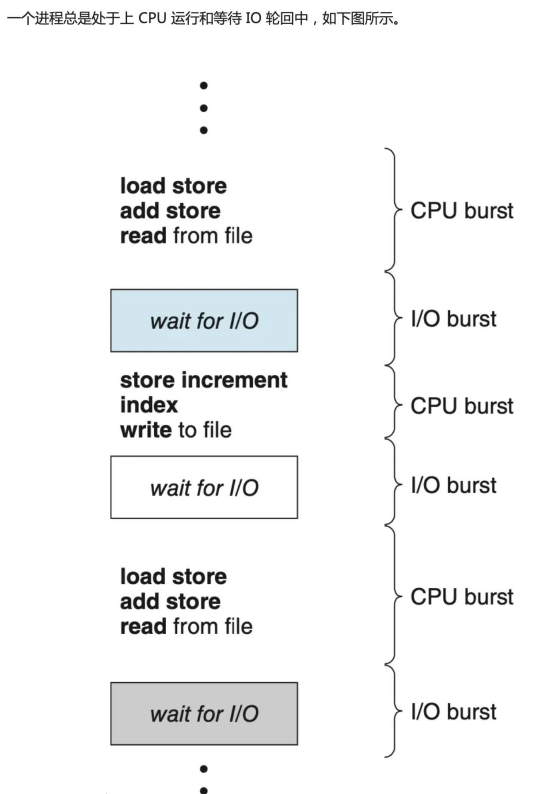
IO Scheduler
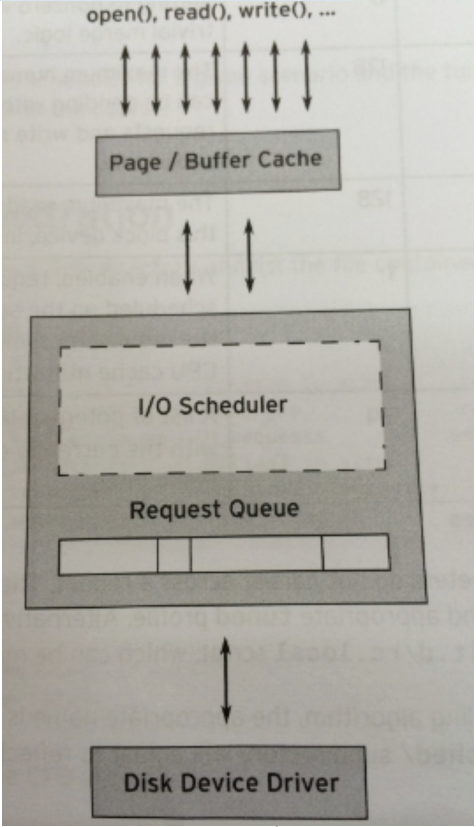
The IO scheduler (IO Scheduler) is the method used by the operating system to determine the order in which IO operations are submitted on block devices. There are two purposes of existence, one is to improve IO throughput, and the other is to reduce IO response time.
However, IO throughput and IO response time are often contradictory. In order to balance the two as much as possible, the IO scheduler provides a variety of scheduling algorithms to adapt to different IO request scenarios. Among them, the most beneficial algorithm for random reading and writing scenarios such as databases is DEANLINE.
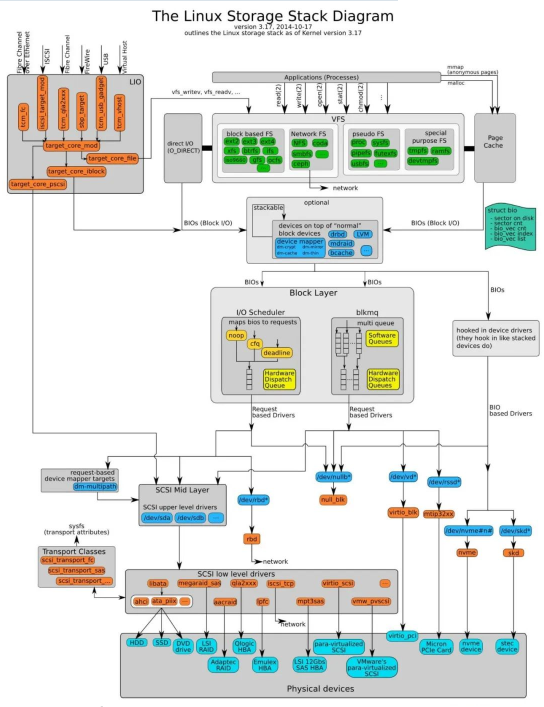
The location of the IO scheduler in the kernel stack is as follows:
The most tragic thing about block devices is disk rotation, which is a very time-consuming process. Each block device or partition of a block device corresponds to its own request queue (request_queue), and each request queue can choose an I/O scheduler to coordinate the submitted requests.
The basic purpose of the I/O scheduler is to arrange requests according to their corresponding sector numbers on the block device to reduce head movement and improve efficiency. Requests in each device's request queue will be responded to in order.
In fact, in addition to this queue, each scheduler itself maintains a different number of queues to process submitted requests, and the request at the front of the queue will be moved to the request queue in due course. response.

The function of IO scheduler is mainly to reduce the need for disk rotation. Mainly achieved through 2 ways:
- merge
- Sort
Each device will have its own corresponding request queue, and all requests will be on the request queue before being processed. When a new request comes, if it is found that the location of this request is adjacent to a previous request, then it can be merged into one request.
If the merge cannot be found, it will be sorted according to the rotation direction of the disk. Usually the role of the IO scheduler is to perform merging and sorting without affecting the processing time of a single request too much.
1、NOOP
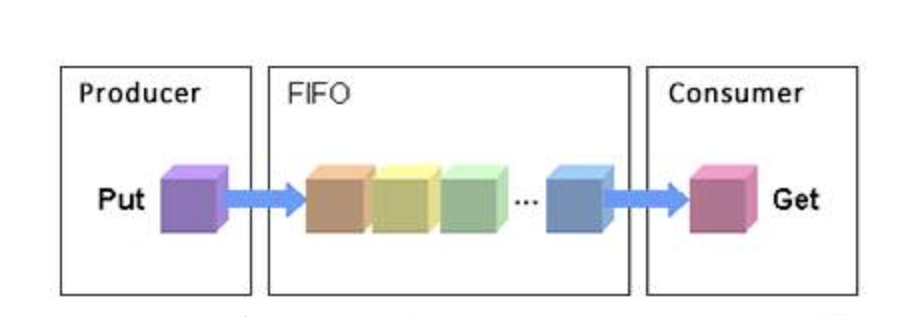
FIFO
- What is noop? Noop is an input and output scheduling algorithm. NOOP, No Operation. Do nothing and process requests one by one. This method is actually simpler and more effective. The problem is that there are too many disk seeks, which is unacceptable for traditional disks. But it's OK for SSD disks, because SSD disks don't need to rotate.
- Another name for noop is also called the elevator scheduling algorithm.
- What is the principle of noop?
Put the input and output requests into a FIFO queue, and then execute the input and output requests in the queue in order: when a new request comes:
-
If it can be merged, merge it
-
If it cannot be merged, it will try to sort. If the requests on the queue are already very old, this new request cannot jump into the queue and can only be placed at the end. Otherwise, insert it into the appropriate position
-
If it cannot be merged and there is no suitable position for insertion, it will be placed at the end of the request queue.
-
Applicable scene
4.1 In the scenario where you do not want to modify the order of input and output requests;
4.2 Devices with more intelligent scheduling algorithms under input and output, such as NAS storage devices;
4.3 The input and output requests of the upper-layer application have been carefully optimized;
4.4 Non-rotating head disk devices, such as SSD disks
2. CFQ (Completely Fair Queuing, completely fair queuing)
CFQ (Completely Fair Queuing) algorithm, as the name suggests, is an absolutely fair algorithm. It attempts to allocate a request queue and a time slice to all processes competing for the right to use the block device. Within the time slice assigned to the process by the scheduler, the process can send its read and write requests to the underlying block device. When the process's time slice is consumed After completion, the process's request queue will be suspended, waiting for scheduling.
The time slice of each process and the queue length of each process depend on the IO priority of the process. Each process will have an IO priority, and the CFQ scheduler will use it as one of the factors to consider to determine When the process's request queue can acquire the right to use the block device.
IO priorities can be divided into three categories from high to low:
RT(real time)
BE(best try)
IDLE(idle)
RT and BE can be further divided into 8 sub-priorities. You can view and modify it through ionice. The higher the priority, the earlier it is processed, the more time slices are used for this process, and the more requests can be processed at one time.
In fact, we already know that the fairness of the CFQ scheduler is for the process, and only synchronous requests (read or syn write) exist for the process, and they will be put into the process's own request queue. All asynchronous requests with the same priority, no matter which process they come from, will be put into a common queue. There are a total of 8 (RT) 8 (BE) 1 (IDLE) = 17 asynchronous request queues.
Starting from Linux 2.6.18, CFQ is used as the default IO scheduling algorithm. For general-purpose servers, CFQ is a better choice. The specific scheduling algorithm to use must be selected based on sufficient benchmarks based on specific business scenarios, and cannot be decided solely by other people's words.
3、DEADLINE
DEADLINE is based on CFQ and solves the extreme situation of IO request starvation.
In addition to the IO sorting queue that CFQ itself has, DEADLINE additionally provides FIFO queues for read IO and write IO.
The maximum waiting time for reading the FIFO queue is 500ms, and the maximum waiting time for writing the FIFO queue is 5s (of course these parameters can be set manually).
The priority of IO requests in the FIFO queue is higher than that in the CFQ queue, and the priority of the read FIFO queue is higher than the priority of the write FIFO queue. Priority can be expressed as follows:
“
FIFO(Read) > FIFO(Write) > CFQ
”
The deadline algorithm guarantees the minimum delay time for a given IO request. From this understanding, it should be very suitable for DSS applications.
deadline is actually an improvement on Elevator:
\1. Avoid some requests that cannot be processed for too long.
\2. Treat read operations and write operations differently.
deadline IO maintains 3 queues. The first queue is the same as Elevator, trying to sort according to physical location. The second queue and the third queue are both sorted by time. The difference is that one is a read operation and the other is a write operation.
Deadline IO distinguishes between reading and writing because the designer believes that if the application sends a read request, it will generally block there and wait until the result is returned. The write request is not usually the application request to write to the memory, and then the background process writes it back to the disk. Applications generally do not wait until writing is completed before continuing. So read requests should have higher priority than write requests.
Under this design, each new request will be placed in the first queue first. The algorithm is the same as that of Elevator, and will also be added to the end of the read or write queue. In this way, we first process some requests from the first queue, and at the same time detect whether the first few requests in the second/third queue have been waiting for too long. If they have exceeded a threshold, they will be processed. This threshold is 5ms for read requests and 5s for write requests.
Personally, I think it is best not to use this kind of partition for recording database change logs, such as Oracle's online log, mysql's binlog, etc. Because this type of write request usually calls fsync. If the writing cannot be completed, it will also greatly affect the application performance.
4、ANTICIPATORY
The focus of CFQ and DEADLINE is to satisfy scattered IO requests. For continuous IO requests, such as sequential reading, there is no optimization.
In order to meet the scenario of mixed random IO and sequential IO, Linux also supports the ANTICIPATORY scheduling algorithm. Based on DEADLINE, ANTICIPATORY sets a 6ms waiting time window for each read IO. If the OS receives a read IO request from an adjacent location within these 6ms, it can be satisfied immediately.
summary
The choice of IO scheduler algorithm depends on both hardware characteristics and application scenarios.
On traditional SAS disks, CFQ, DEADLINE, and ANTICIPATORY are all good choices; for dedicated database servers, DEADLINE's throughput and response time perform well.
However, on emerging solid-state drives such as SSD and Fusion IO, the simplest NOOP may be the best algorithm, because the optimization of the other three algorithms is based on shortening the seek time, and solid-state drives have no so-called seek time. channel time and IO response time is very short.
The above is the detailed content of Understand the four major IO scheduling algorithms of the Linux kernel in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
The key differences between CentOS and Ubuntu are: origin (CentOS originates from Red Hat, for enterprises; Ubuntu originates from Debian, for individuals), package management (CentOS uses yum, focusing on stability; Ubuntu uses apt, for high update frequency), support cycle (CentOS provides 10 years of support, Ubuntu provides 5 years of LTS support), community support (CentOS focuses on stability, Ubuntu provides a wide range of tutorials and documents), uses (CentOS is biased towards servers, Ubuntu is suitable for servers and desktops), other differences include installation simplicity (CentOS is thin)
 Centos stops maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos stops maintenance 2024
Apr 14, 2025 pm 08:39 PM
CentOS will be shut down in 2024 because its upstream distribution, RHEL 8, has been shut down. This shutdown will affect the CentOS 8 system, preventing it from continuing to receive updates. Users should plan for migration, and recommended options include CentOS Stream, AlmaLinux, and Rocky Linux to keep the system safe and stable.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 How to install centos
Apr 14, 2025 pm 09:03 PM
How to install centos
Apr 14, 2025 pm 09:03 PM
CentOS installation steps: Download the ISO image and burn bootable media; boot and select the installation source; select the language and keyboard layout; configure the network; partition the hard disk; set the system clock; create the root user; select the software package; start the installation; restart and boot from the hard disk after the installation is completed.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How to mount hard disk in centos
Apr 14, 2025 pm 08:15 PM
How to mount hard disk in centos
Apr 14, 2025 pm 08:15 PM
CentOS hard disk mount is divided into the following steps: determine the hard disk device name (/dev/sdX); create a mount point (it is recommended to use /mnt/newdisk); execute the mount command (mount /dev/sdX1 /mnt/newdisk); edit the /etc/fstab file to add a permanent mount configuration; use the umount command to uninstall the device to ensure that no process uses the device.
 What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
After CentOS is stopped, users can take the following measures to deal with it: Select a compatible distribution: such as AlmaLinux, Rocky Linux, and CentOS Stream. Migrate to commercial distributions: such as Red Hat Enterprise Linux, Oracle Linux. Upgrade to CentOS 9 Stream: Rolling distribution, providing the latest technology. Select other Linux distributions: such as Ubuntu, Debian. Evaluate other options such as containers, virtual machines, or cloud platforms.
