
 Technology peripherals
AI
ICLR 2024 | The first zero-order optimized deep learning framework, MSU and LLNL propose DeepZero
Technology peripherals
AI
ICLR 2024 | The first zero-order optimized deep learning framework, MSU and LLNL propose DeepZero
ICLR 2024 | The first zero-order optimized deep learning framework, MSU and LLNL propose DeepZero

This article is a study on improving the scalability of zero-order optimization. The code has been open source and the paper has been accepted by ICLR 2024.
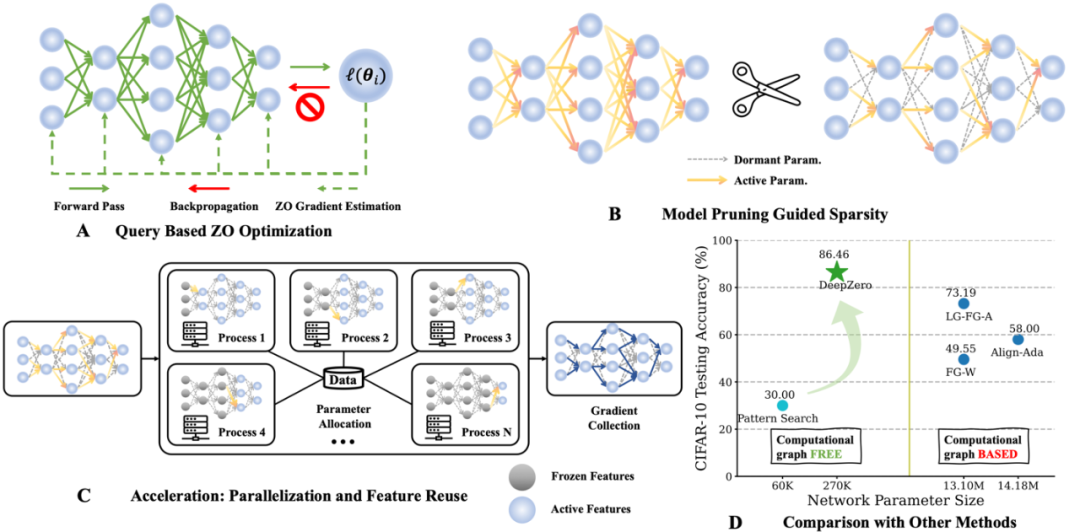
Today I’d like to introduce a paper titled “DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training” by Michigan State University and Lawrence Livermore National Laboratory collaboration is completed. This paper was recently accepted by the ICLR 2024 conference, and the research team has made the code open source. The main goal of this paper is to extend zero-order optimization techniques in deep learning model training. Zero-order optimization is an optimization method that does not rely on gradient information and can better handle high-dimensional parameter spaces and complex model structures. However, existing zero-order optimization methods face scale and efficiency challenges when dealing with deep learning models. To address these challenges, the research team proposed the DeepZero framework. This framework can efficiently handle the training of large-scale deep learning models by introducing new sampling strategies and adaptive adjustment mechanisms. DeepZero takes advantage of zero-order optimization and combines distributed computing and parallelization techniques to accelerate training over

Paper address: https://arxiv.org/abs/2310.02025
Project address: https://www.optml-group.com/posts/deepzero_iclr24
1. Background
Zeroth-Order (ZO) optimization has become a popular technology to solve machine learning (Machine Learning) problems, especially It is when the first-order (FO) information is difficult or impossible to obtain:
Physics and chemistry and other disciplines: Machine learning models may be related to Complex simulator or experimental interactions where the underlying system is not differentiable.
Black box learning scenario: When a deep learning (Deep Learning) model is integrated with a third-party API, such as adversarial attacks against the black box deep learning model and Defense, and black-box prompt learning of language model services.
Hardware limitations: The principle backpropagation mechanism used to calculate first-order gradients may not be supported when implementing deep learning models on hardware systems .
However, currently the scalability of zero-order optimization remains an unsolved problem: its use is mainly limited to relatively small-scale machine learning problems, such as sample-level adversarial attacks. generate. As the dimensionality of the problem increases, the accuracy and efficiency of traditional zero-order methods decrease. This is because the gradient estimate based on zero-order finite difference is a biased estimate of the first-order gradient, and the deviation is more obvious in high-dimensional space. These challenges motivate the core question discussed in this article: How to extend zero-order optimization so that it can train deep learning models?
2. Zero-order gradient estimation: RGE or CGE?
The zero-order optimizer interacts with the objective function only by submitting inputs and receiving corresponding function values. There are two main gradient estimation methods: Coordinate Gradient Estimation (CGE) and Random Gradient Estimation (RGE), as shown below:
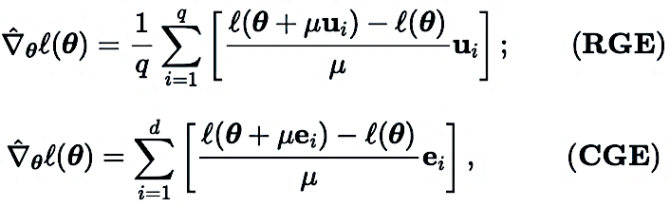
where 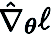 represents an estimate of the first-order gradient of the optimization variable
represents an estimate of the first-order gradient of the optimization variable 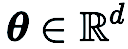 (e.g., model parameters of a neural network).
(e.g., model parameters of a neural network).
In (RGE), 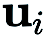 represents a random perturbation vector, for example, drawn from a standard Gaussian distribution;
represents a random perturbation vector, for example, drawn from a standard Gaussian distribution; 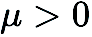 is the perturbation size (also known as smoothing parameter); q is used to obtain the finite difference Number of random directions.
is the perturbation size (also known as smoothing parameter); q is used to obtain the finite difference Number of random directions.
В (CGE) 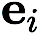 представляет стандартный базисный вектор,
представляет стандартный базисный вектор, 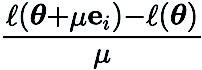 обеспечивает оценку конечной разности частной производной
обеспечивает оценку конечной разности частной производной 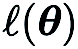 в соответствующих координатах.
в соответствующих координатах.
По сравнению с CGE, RGE позволяет сократить количество вычислений функций. Несмотря на высокую эффективность запросов, до сих пор неясно, сможет ли RGE обеспечить удовлетворительную точность при обучении глубоких моделей с нуля. С этой целью мы провели исследование, в ходе которого обучили небольшие сверточные нейронные сети (CNN) разного размера на CIFAR-10 с использованием RGE и CGE. Как показано на рисунке ниже, CGE может достичь точности тестирования, сравнимой с обучением оптимизации первого порядка, и значительно лучше, чем RGE, а также более эффективен по времени, чем RGE.
Основываясь на преимуществах CGE перед RGE с точки зрения точности и вычислительной эффективности, Мы выбираем CGE в качестве предпочтительного средства оценки градиента нулевого порядка. Однако сложность запросов CGE остается узким местом, поскольку она масштабируется с размером модели.
3. Фреймворк глубокого обучения нулевого порядка: DeepZero
Насколько нам известно, предыдущая работа не показала, что оптимизация ZO не эффективна при обучении глубоких нейронов сетей (DNN) Может существенно снизить эффективность работы. Чтобы преодолеть это препятствие, мы разработали DeepZero, принципиальную структуру глубокого обучения для оптимизации нулевого порядка, которая может расширить оптимизацию нулевого порядка до обучения нейронных сетей с нуля.
a) Отсечение модели нулевого порядка (ZO-GraSP): случайно инициализированная плотная нейронная сеть часто содержит высококачественную разреженную подсеть. Однако наиболее эффективные методы сокращения включают обучение модели в качестве промежуточного этапа. Следовательно, они не подходят для поиска разреженности посредством оптимизации нулевого порядка. Для решения вышеуказанных проблем нас вдохновил метод сокращения без обучения, называемый сокращением инициализации. Среди таких методов было выбрано сохранение градиентного сигнала (GraSP), которое представляет собой метод определения априорной разреженности нейронных сетей путем случайной инициализации градиентного потока сети.
b) Разреженный градиент: Чтобы сохранить преимущества точности обучения плотных моделей, в CGE мы включаем разреженность градиента вместо разреженности веса. Это гарантирует, что мы обучаем плотную модель в весовом пространстве, а не разреженную модель. В частности, мы используем ZO-GraSP для определения послойных коэффициентов сокращения (LPR), которые могут отражать сжимаемость DNN, а затем оптимизация нулевого порядка может обучаться плотно путем непрерывного итеративного обновления весов некоторых параметров модели. коэффициент градиента определяется LPR. c)
Повторное использование функций: Поскольку CGE искажает каждый параметр поэлементно, он может повторно использовать функции непосредственно перед слоем возмущения и вместо этого выполнять оставшиеся операции прямого распространения начиная с входного слоя. Эмпирически, CGE с повторным использованием функций может сократить время обучения более чем в 2 раза. d)
Первый проход: CGE поддерживает распараллеливание обучения модели. Это свойство развязки позволяет масштабировать прямое распространение между распределенными машинами, значительно увеличивая скорость обучения нулевого порядка.
4.Экспериментальный анализа) Классификация изображений
На наборе данных CIFAR-10 обучаем DeepZero ResNet -20 сравнивается с двумя вариантами, обученными с помощью оптимизации первого порядка:
(1) Dense ResNet-20, обученный с помощью оптимизации первого порядка
(2) Dense ResNet-20, полученный первым - оптимизация порядка Оптимизированное обучение разреженного ResNet-20
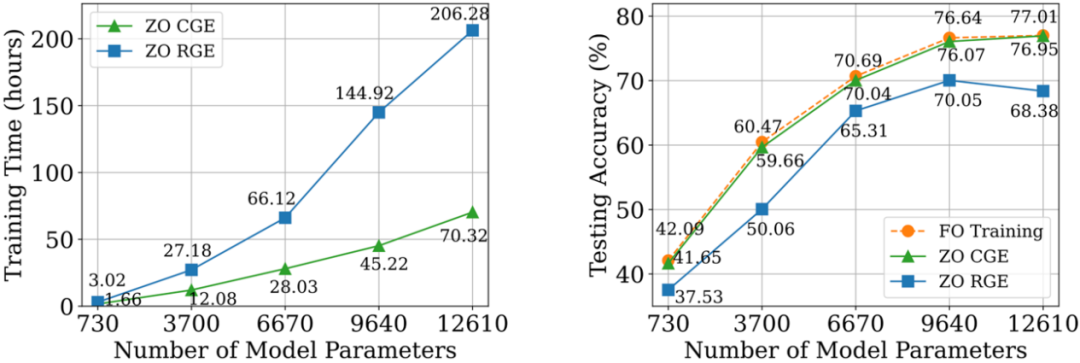
, полученного с помощью FO-GraSP, показано на рисунке ниже. Хотя в интервале разреженности от 80% до 99%, по сравнению с (1), модель, обученная с помощью DeepZero по-прежнему точный градусный разрыв. Это подчеркивает проблемы оптимизации ZO для глубокого обучения моделей, где желательны реализации с высокой разреженностью. Стоит отметить, что DeepZero превосходит (2) в интервале разрежённости от 90% до 99%,
демонстрируя превосходство разрежённости градиента над разрежённостью веса в DeepZero.
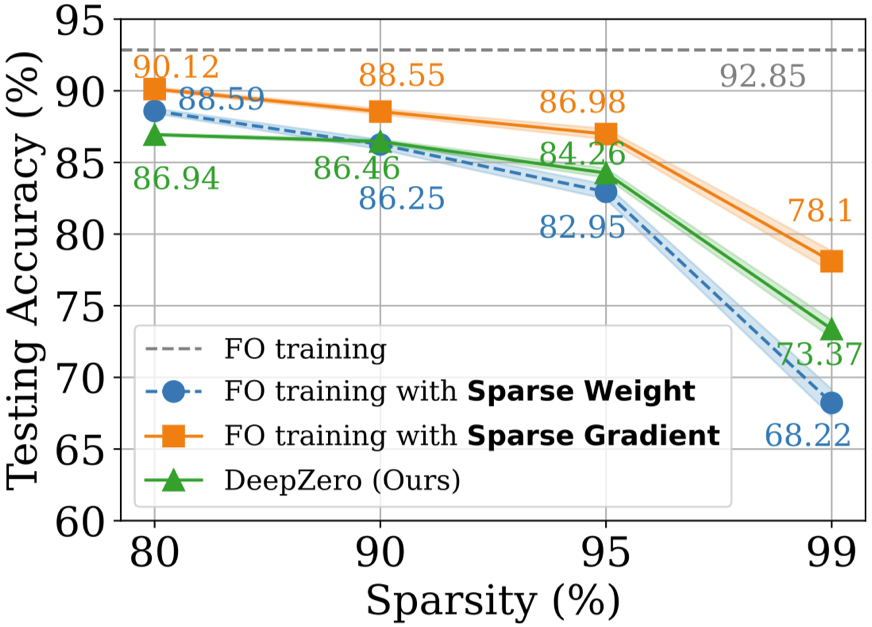
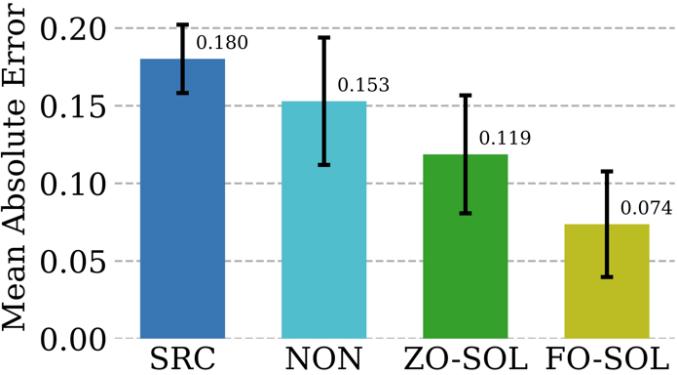
Проблема защиты «черного ящика» возникает, когда владелец модели не желает делиться деталями модели с защитником. Это создает проблему для существующих алгоритмов повышения надежности, которые напрямую улучшают модели белого ящика с использованием обучения оптимизации первого порядка. Чтобы преодолеть эту проблему, предлагается ZO-AE-DS, который вводит автоэнкодер (AE) между защитной операцией сглаживания шума белого ящика (DS) и классификатором изображений черного ящика для решения задач обучения ZO Dimensional. ZO-AE-DS имеет тот недостаток, что его трудно масштабировать до наборов данных с высоким разрешением (например, ImageNet), поскольку использование AE ставит под угрозу точность изображений, вводимых в классификатор изображений черного ящика, и приводит к снижению производительности защиты. Напротив, DeepZero может напрямую изучать защитные операции , интегрированные с классификатором черного ящика, без необходимости использования автокодировщика. Как показано в таблице ниже, DeepZero неизменно превосходит ZO-AE-DS по всем входным радиусам возмущений с точки зрения сертифицированной точности (CA). #c) Глубокое обучение в сочетании с моделированием Численные методы незаменимы при моделировании физической информации, но они сами существуют Есть проблемы: дискретизация неизбежно приводит к числовым ошибкам. Возможность исправления нейронных сетей посредством циклического интерактивного обучения с помощью итеративного решателя уравнений в частных производных (PDE) называется решателем в цикле (SOL). В то время как существующая работа сосредоточена на использовании или разработке дифференцируемых симуляторов для обучения моделей, мы расширяем SOL, используя DeepZero, чтобы обеспечить возможность использования с недифференцируемыми симуляторами или симуляторами черного ящика. В следующей таблице сравниваются характеристики исправления ошибок теста ZO-SOL (реализованного DeepZero) с тремя различными дифференцируемыми методами:
#####################################################) В этом документе представлена структура глубокого обучения оптимизации нулевого порядка (DeepZero) для глубокого обучения сети. ). В частности, DeepZero объединяет оценку градиента координат, разреженность градиента, возникающую за счет сокращения модели нулевого порядка, повторное использование функций и распараллеливание переднего прохода в единый процесс обучения. Используя эти инновации, DeepZero продемонстрировал эффективность и результативность в решении задач, включая классификацию изображений и различные практические сценарии глубокого обучения «черный ящик». Кроме того, исследуется применимость DeepZero в других областях, таких как приложения, включающие недифференцируемые физические объекты, и обучение на устройствах, где не поддерживаются вычислительные графики и вычисления обратного распространения ошибки. #########Знакомство с автором#########Чжан Имэн, аспирантка в области компьютерных наук в лаборатории OPTML Мичиганского государственного университета, ее исследовательские интересы включают генеративный искусственный интеллект, мультимодальность. , Компьютерное зрение, Безопасный ИИ, Эффективный ИИ. ###
The above is the detailed content of ICLR 2024 | The first zero-order optimized deep learning framework, MSU and LLNL propose DeepZero. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, the father of reinforcement learning, will attend! Yan Shuicheng, Sergey Levine and DeepMind scientists will give keynote speeches
Aug 22, 2024 pm 08:02 PM
Conference Introduction With the rapid development of science and technology, artificial intelligence has become an important force in promoting social progress. In this era, we are fortunate to witness and participate in the innovation and application of Distributed Artificial Intelligence (DAI). Distributed artificial intelligence is an important branch of the field of artificial intelligence, which has attracted more and more attention in recent years. Agents based on large language models (LLM) have suddenly emerged. By combining the powerful language understanding and generation capabilities of large models, they have shown great potential in natural language interaction, knowledge reasoning, task planning, etc. AIAgent is taking over the big language model and has become a hot topic in the current AI circle. Au
