
 Technology peripherals
AI
'Smart Emergence' of Speech Generation: 100,000 Hours of Data Training, Amazon Offers 1 Billion Parameters BASE TTS
Technology peripherals
AI
'Smart Emergence' of Speech Generation: 100,000 Hours of Data Training, Amazon Offers 1 Billion Parameters BASE TTS
'Smart Emergence' of Speech Generation: 100,000 Hours of Data Training, Amazon Offers 1 Billion Parameters BASE TTS

With the rapid development of generative deep learning models, natural language processing (NLP) and computer vision (CV) have undergone significant changes. From the previous supervised models that required specialized training, to a general model that only requires simple and clear instructions to complete various tasks. This transformation provides us with a more efficient and flexible solution.
In the world of speech processing and text-to-speech (TTS), a transformation is happening. By leveraging thousands of hours of data, the model brings the synthesis closer and closer to real human speech.
In a recent study, Amazon officially launched BASE TTS, increasing the parameter scale of the TTS model to an unprecedented level of 1 billion.

Paper title: BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Paper link: https://arxiv.org/pdf/2402.08093.pdf
BASE TTS is a large multi-language, multi-speaker TTS ( LTTS) system. It used about 100,000 hours of public domain speech data for training, which is twice as much as VALL-E, which had the highest amount of training data before. Inspired by the successful experience of LLM, BASE TTS treats TTS as the problem of next token prediction and combines it with a large amount of training data to achieve powerful multi-language and multi-speaker capabilities.
The main contributions of this article are summarized as follows:
The proposed BASE TTS is currently the largest TTS model with 1 billion parameters and is based on data consisting of 100,000 hours of public domain voice data set for training. Through subjective evaluation, BASE TTS outperforms the public LTTS baseline model in performance.
This article shows how to improve BASE TTS's ability to render appropriate prosody for complex text by extending it to larger data sets and model sizes. In order to evaluate the text understanding and rendering capabilities of large-scale TTS models, the researchers developed an "emergent capability" test set and reported the performance of different variants of BASE TTS on this benchmark. The results show that as the size of the data set and the number of parameters increase, the quality of BASE TTS is gradually improved.
3. A new discrete speech representation based on the WavLM SSL model is proposed, aiming to capture only the phonological and prosodic information of the speech signal. These representations outperform baseline quantization methods, allowing them to be decoded into high-quality waveforms by simple, fast, and streaming decoders despite high compression levels (only 400 bit/s).
Next, let’s look at the paper details.
BASE TTS model
Similar to recent speech modeling work, researchers have adopted an LLM-based approach to handle TTS tasks. Text is fed into a Transformer-based autoregressive model that predicts discrete audio representations (called speech codes), which are then decoded into waveforms by a separately trained decoder consisting of linear and convolutional layers.
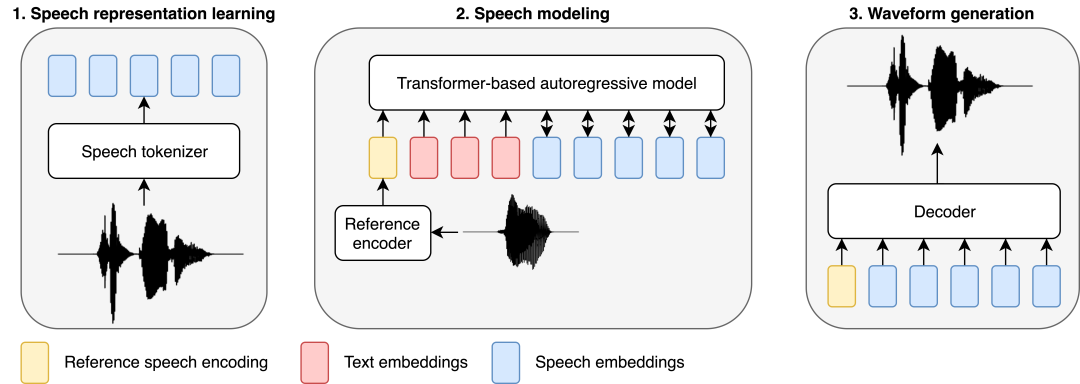
BASE TTS is designed to simulate the joint distribution of text tokens followed by discrete speech representations, which researchers call speech encoding. Discretization of speech by audio codecs is central to the design, as this enables direct application of methods developed for LLM, which is the basis for recent research results in LTTS. Specifically, we model speech coding using a decoding autoregressive Transformer with a cross-entropy training objective. Although simple, this goal can capture the complex probability distribution of expressive speech, thereby mitigating the over-smoothing problem seen in early neural TTS systems. As an implicit language model, once large enough variants are trained on enough data, BASE TTS will also make a qualitative leap in prosody rendering.
Discrete Language Representation
Discrete representation is the basis for LLM's success, but identifying compact and informative representations in speech is not as obvious as in text. Previously, There is also less exploration. For BASE TTS, researchers first tried to use the VQ-VAE baseline (Section 2.2.1), which is based on an autoencoder architecture to reconstruct the mel spectrogram through discrete bottlenecks. VQ-VAE has become a successful paradigm for speech and image representation, especially as a modeling unit for TTS.
The researchers also introduced a new method for learning speech representation through WavLM-based speech coding (Section 2.2.2). In this approach, researchers discretize features extracted from the WavLM SSL model to reconstruct mel spectrograms. The researchers applied an additional loss function to facilitate speaker separation and compressed the generated speech codes using Byte-Pair Encoding (BPE) to reduce sequence length, enabling the use of the Transformer for longer audio Modeling.
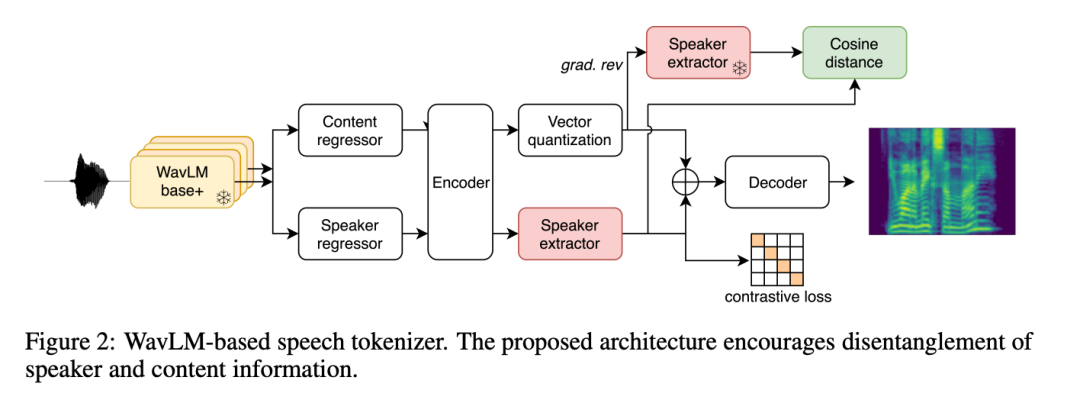
Both representations are compressed (325 bits/s and 400 bits/s respectively) to enable more efficient autoregressive modeling compared to popular audio codecs. Based on this level of compression, the next goal is to remove information from the speech code that can be reconstructed during decoding (speaker, audio noise, etc.) to ensure that the capacity of the speech code is mainly used to encode phonetic and prosodic information.
Autoregressive Speech Modeling (SpeechGPT)
The researchers trained an autoregressive model "SpeechGPT" with GPT-2 architecture, which is used to predict text and reference Speech-conditioned speech coding. The reference speech condition consisted of randomly selected utterances from the same speaker, which were encoded as fixed-size embeddings. Reference speech embeddings, text and speech encodings are concatenated into a sequence modeled by a Transformer-based autoregressive model. We use separate positional embeddings and separate prediction heads for text and speech. They trained an autoregressive model from scratch without pre-training on text. In order to preserve text information to guide onomatopoeia, SpeechGPT is also trained with the aim of predicting the next token of the text part of the input sequence, so the SpeechGPT part is a text-only LM. A lower weight is adopted here for text loss compared to speech loss.
Waveform generation
In addition, the researchers specified a separate speech coder-to-waveform decoder (called the "speech codec") responsible for reconstructing the speaker Identity and recording conditions. To make the model more scalable, they replaced the LSTM layer with a convolutional layer to decode the intermediate representation. Research shows that this convolution-based speech codec is computationally efficient, reducing overall system synthesis time by more than 70% compared to diffusion-based baseline decoders.
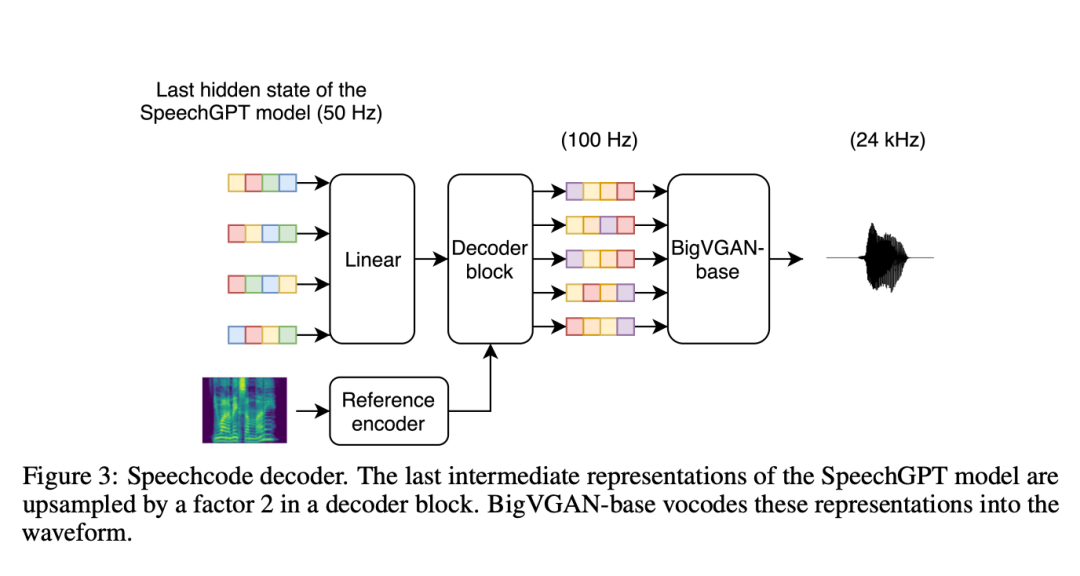
The researchers also pointed out that in fact the input of the speech codec is not the speech encoding, but the last hidden state of the autoregressive Transformer. This was done because the dense latent representations in previous TortoiseTTS methods provide richer information than a single phonetic code. During the training process, the researchers input text and target code into the trained SpeechGPT (parameter freezing), and then adjusted the decoder based on the final hidden state. Inputting the last hidden state of SpeechGPT helps improve the segmentation and acoustic quality of speech, but also ties the decoder to a specific version of SpeechGPT. This complicates experiments because it forces the two components to always be built sequentially. This limitation needs to be addressed in future work.
Experimental Evaluation
The researchers explored how scaling affects the model’s ability to produce appropriate prosody and expression for challenging text input, which is consistent with LLM through data and Parameter scaling "emerges" new capabilities in a similar way. To test whether this hypothesis also applies to LTTS, the researchers proposed an assessment scheme to evaluate potential emergent abilities in TTS, identifying seven challenging categories: compound nouns, emotions, foreign words, paralanguage, and punctuation. , issues and syntactic complexity.
Multiple experiments verified the structure, quality, function and computing performance of BASE TTS:
First, the researchers compared the autoencoder-based and WavLM-based The quality of the model achieved by speech coding.
We then evaluated two approaches to acoustic decoding of speech codes: diffusion-based decoders and speech codecs.
After completing these structural ablations, we evaluated the emergent capabilities of BASE TTS across 3 variations of dataset size and model parameters, as well as by language experts.
In addition, the researchers conducted subjective MUSHRA tests to measure naturalness, as well as automated intelligibility and speaker similarity measures, and reported results on other open source text-to-speech models. Voice quality comparison.
VQ-VAE speech coding vs. WavLM speech coding
In order to comprehensively test the quality and versatility of the two voice tokenization methods, research Researchers conducted the MUSHRA assessment on 6 American English and 4 Spanish speakers. In terms of mean MUSHRA scores in English, the VQ-VAE and WavLM-based systems were comparable (VQ-VAE: 74.8 vs WavLM: 74.7). However, for Spanish, the WavLM-based model is statistically significantly better than the VQ-VAE model (VQ-VAE: 73.3 vs WavLM: 74.7). Note that the English data makes up approximately 90% of the dataset, while the Spanish data only makes up 2%.
Table 3 shows the results by speaker:
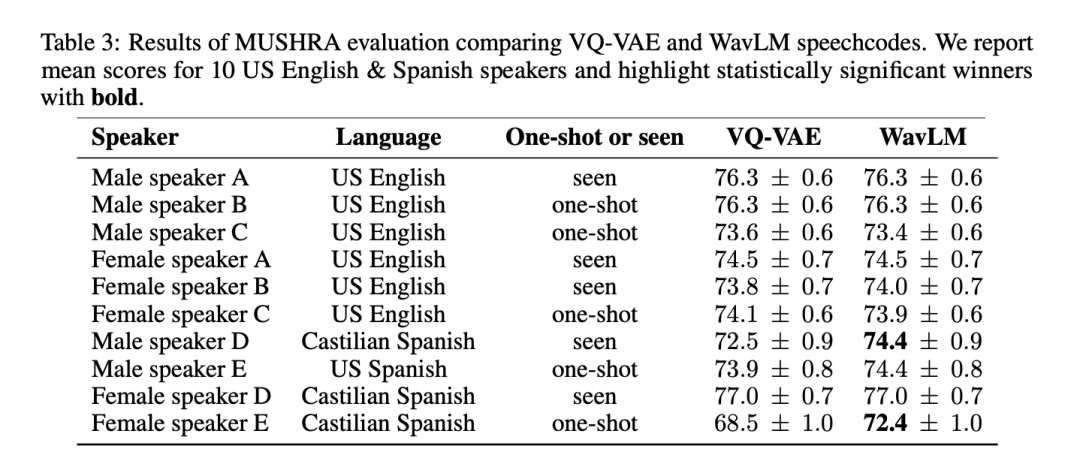
Since the WavLM-based system performs at least as well as or better than the VQ-VAE baseline, The researchers used it to represent BASE TTS in further experiments.
Diffusion-based decoder vs. speech code decoder
As mentioned above, BASE TTS simplifies the diffusion-based baseline decoder by proposing an end-to-end speech codec. The method is fluent and improves inference speed by 3 times. To ensure that this approach does not degrade quality, the proposed speech codec was evaluated against baselines. Table 4 lists the results of the MUSHRA evaluation on 4 English-speaking Americans and 2 Spanish-speaking people:
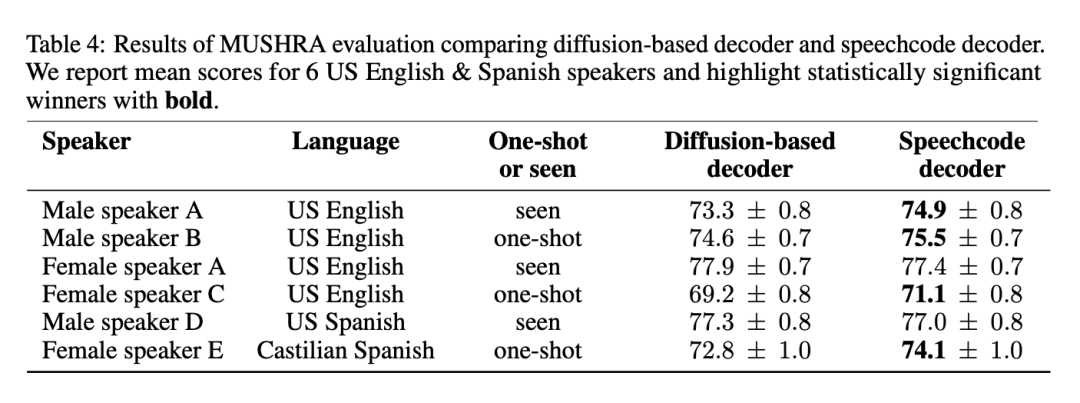
The results show that the speech codec is The preferred method because it does not reduce quality and, for most speeches, improves quality while providing faster inference. The researchers also stated that combining two powerful generative models for speech modeling is redundant and can be simplified by abandoning the diffusion decoder.
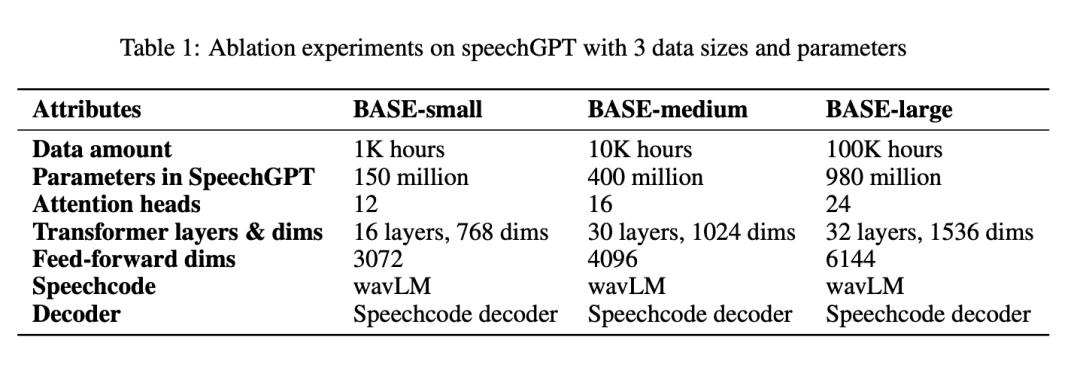
Emergent Capacity: Ablation of Data and Model Size
Table 1 reports all parameters by BASE-small, BASE-medium, and BASE-large systems:
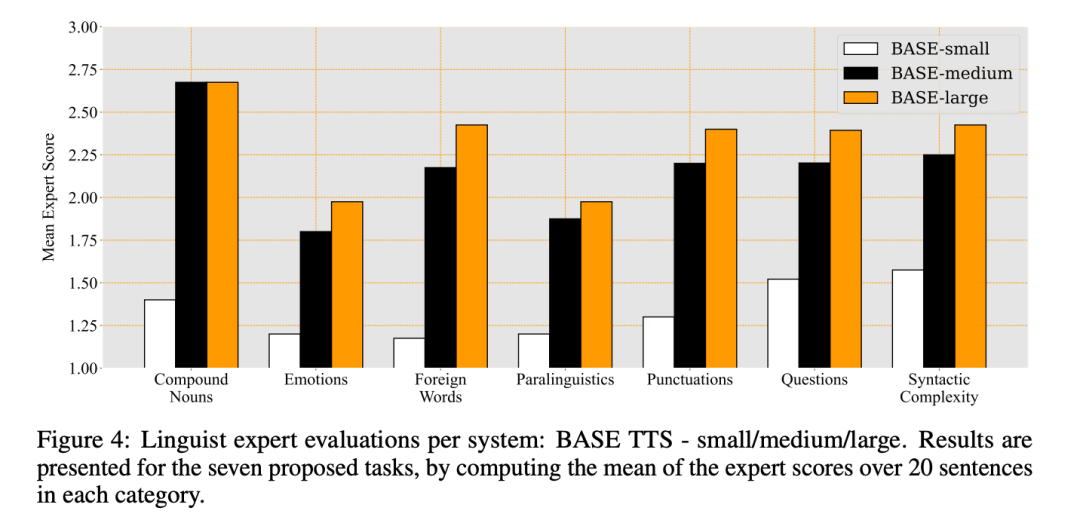
The language expert judgment results of the three systems and the average score of each category are shown in Figure 4:
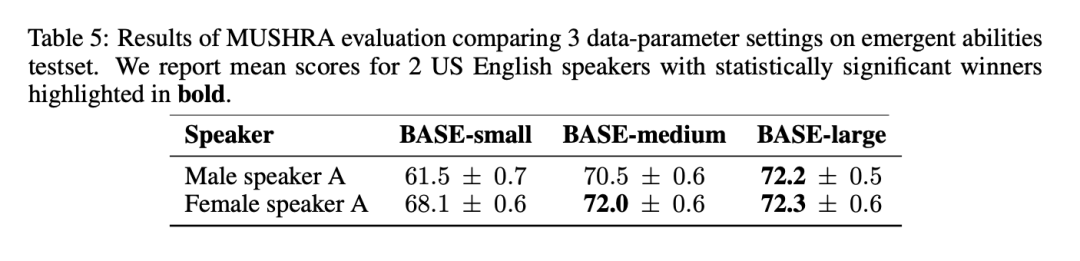
In the table In the MUSHRA results of 5, it can be noticed that the naturalness of speech is significantly improved from BASE-small to BASE-medium, but the improvement from BASE-medium to BASE-large is smaller:
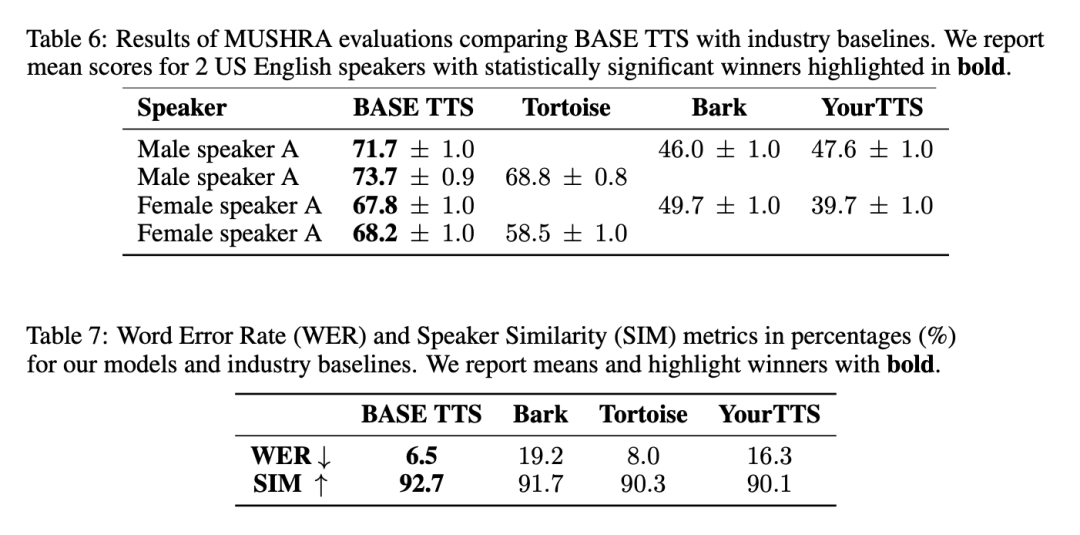
BASE TTS vs. industry baseline
Generally speaking, the speech generated by BASE TTS is the most natural, has the least misalignment with the input text, and is most similar to the reference speaker’s speech. The relevant results are shown in Table 6 and Table 7:
#Synthesis efficiency improvement brought by the speech codec
Speech coding The decoder is capable of streaming, i.e. generating speech incrementally. Combining this capability with autoregressive SpeechGPT, the system can achieve first-byte latency as low as 100 milliseconds — enough to produce intelligible speech with just a few decoded speech codes.
This minimal latency is in sharp contrast to diffusion-based decoders, which require the entire speech sequence (one or more sentences) to be generated in one go, with first-byte latency equal to the total generation time.
Additionally, the researchers observed that the speech codec made the entire system computationally more efficient by a factor of 3 compared to the diffusion baseline. They ran a benchmark that generated 1000 statements of approximately 20 seconds duration with a batch size of 1 on an NVIDIA® V100 GPU. On average, a billion-parameter SpeechGPT using a diffusion decoder takes 69.1 seconds to complete synthesis, while the same SpeechGPT using a speech codec only takes 17.8 seconds.
For more research details, please refer to the original paper.
The above is the detailed content of 'Smart Emergence' of Speech Generation: 100,000 Hours of Data Training, Amazon Offers 1 Billion Parameters BASE TTS. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 AI in use | Microsoft CEO's crazy Amway AI game tortured me thousands of times
Aug 14, 2024 am 12:00 AM
AI in use | Microsoft CEO's crazy Amway AI game tortured me thousands of times
Aug 14, 2024 am 12:00 AM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Oh my God, AI has really become a genius. Recently, it has become a hot topic that it is difficult to distinguish the authenticity of AI-generated pictures. (For details, please go to: AI in use | Become an AI beauty in three steps, and be beaten back to your original shape by AI in a second) In addition to the popular AI Google lady on the Internet, various FLUX generators have emerged on social platforms
