
 Technology peripherals
AI
RAG or fine-tuning? Microsoft has released a guide to the construction process of large model applications in specific fields
Technology peripherals
AI
RAG or fine-tuning? Microsoft has released a guide to the construction process of large model applications in specific fields
RAG or fine-tuning? Microsoft has released a guide to the construction process of large model applications in specific fields

Retrieval Enhanced Generation (RAG) and fine-tuning (Fine-tuning) are two common methods to improve the performance of large language models, so which method is better? Which is more efficient when building applications in a specific domain? This paper from Microsoft is for your reference when choosing.
When building large language model applications, two approaches are often used to incorporate proprietary and domain-specific data: retrieval enhancement generation and fine-tuning. Retrieval-enhanced generation enhances the model's generation capabilities by introducing external data, while fine-tuning incorporates additional knowledge into the model itself. However, our understanding of the advantages and disadvantages of these two approaches is insufficient.
This article introduces a new focus proposed by Microsoft researchers, which is to create AI assistants with specific context and adaptive response capabilities for the agricultural industry. By introducing a comprehensive large language model process, high-quality, industry-specific questions and answers can be generated. The process consists of a systematic series of steps, starting with the identification and collection of relevant documents covering a wide range of agricultural topics. These documents are then cleaned and structured to generate meaningful question-answer pairs using the basic GPT model. Finally, the generated question-answer pairs are evaluated and filtered based on their quality. This approach provides the agricultural industry with a powerful tool that can provide accurate and practical information to help farmers and related practitioners better deal with various issues and challenges.
This article aims to create valuable knowledge resources for the agricultural industry, using agriculture as a case study. Its ultimate goal is to contribute to the development of LLM in the agricultural sector.

Paper address: https://arxiv.org/pdf/2401.08406.pdf
Paper Title: RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
The goal of this article process is to generate domain-specific questions that meet the needs of specific industry professionals and stakeholders and answers. In this industry, the answers expected from AI assistants should be based on relevant industry-specific factors.
This article deals with agricultural research and the goal is to generate answers in this specific field. The starting point of the study is therefore an agricultural dataset, which is fed into three main components: Question generation, retrieval enhancement generation and fine-tuning process. Question-answer generation creates question-answer pairs based on the information in the agricultural dataset, and retrieval-augmented generation uses it as a knowledge source. The generated data is refined and used to fine-tune multiple models, the quality of which is assessed through a set of proposed metrics. Through this comprehensive approach, harness the power of large language models to benefit the agricultural industry and other stakeholders.
This article has made some special contributions to the understanding of large language models in the agricultural field. These contributions can be summarized as follows:
1, Comprehensive evaluation of LLMs: This article Large language models, including LlaMa2-13B, GPT-4 and Vicuna, are extensively evaluated to answer agriculture-related questions. A benchmark dataset from major agricultural producing countries was used for the evaluation. In this analysis, GPT-4 consistently outperforms other models, but the costs associated with its fine-tuning and inference need to be considered.
2. The impact of retrieval technology and fine-tuning on performance: This article studies the impact of retrieval technology and fine-tuning on the performance of LLMs. Research has found that both retrieval enhancement generation and fine-tuning are effective techniques to improve the performance of LLMs.
3. The impact of potential applications of LLMs in different industries: For those who want to establish the process of applying RAG and fine-tuning technology in LLMs, this article has taken a pioneering step and Promotes innovation and collaboration across multiple industries.
Method
Part 2 of this article details the methodology adopted, including the data acquisition process, information extraction process, question and answer generation, and fine-tuning of the model. The methodology revolves around a process designed to generate and evaluate question-answer pairs for building domain-specific assistants, as shown in Figure 1 below.
The process begins with data acquisition, which includes obtaining data from a variety of high-quality repositories, such as government agencies, scientific knowledge databases, and using proprietary data.
After completing the data acquisition, the process continues to extract information from the collected documents. This step is crucial as it involves parsing complex and unstructured PDF files to recover their content and structure. Figure 2 below shows an example of a PDF file from the dataset.

The next component of the process is question and answer generation. The goal here is to generate context-based, high-quality questions that accurately reflect the content of the extracted text. This method adopts a framework to control the structural composition of input and output, thereby enhancing the overall effect of the response generated by the language model.
The process then generates answers to the formulated questions. The approach adopted here leverages retrieval-enhanced generation, combining the capabilities of retrieval and generation mechanisms to create high-quality answers.
Finally, the process fine-tunes the model through Q&A. The optimization process uses methods such as low-rank adjustment (LoRA) to ensure a comprehensive understanding of the content and context of scientific literature, making it a valuable resource in various fields or industries.
Dataset
The study evaluates the generated language model with fine-tuning and retrieval enhancement, using a context-relevant question and answer dataset derived from Three major crop-producing countries: the United States, Brazil and India. In the case of this article, agriculture is used as the industrial background. The available data vary widely in format and content, ranging from regulatory documents to scientific reports to agronomic examinations to knowledge databases.
This article gathered information from publicly available online documents, manuals, and reports from the U.S. Department of Agriculture, state agricultural and consumer service agencies, and others.
Available documents include federal regulatory and policy information on crop and livestock management, diseases and best practices, quality assurance and export regulations, assistance program details, and insurance and pricing guidance. The data collected totals more than 23,000 PDF files containing more than 50 million tokens, covering 44 U.S. states. The researchers downloaded and preprocessed these files to extract textual information that could be used as input to the question and answer generation process.
To benchmark and evaluate the model, this paper uses documents related to the state of Washington, which includes 573 files containing more than 2 million tokens. Listing 5 below shows an example of the content in these files.

Metrics
The main purpose of this section is to establish a comprehensive set of metrics with the purpose of guiding the question and answer generation process Quality assessment, especially of fine-tuning and retrieval enhancement generation methods.
When developing metrics, several key factors must be considered. First, the subjectivity inherent in question quality poses significant challenges.
Secondly, metrics must take into account the relevance of the problem and the dependence of practicality on context.
Third, the diversity and novelty of generated questions need to be evaluated. A strong question generation system should be able to generate a wide range of questions covering all aspects of given content. However, quantifying diversity and novelty can be challenging, as it involves assessing the uniqueness of questions and their similarity to content, other generated questions.
Finally, good questions should be able to be answered based on the content provided. Assessing whether a question can be accurately answered using available information requires a deep understanding of the content and the ability to identify relevant information to answer the question.
These metrics play an integral role in ensuring that the answers provided by the model answer the question accurately, relevantly, and effectively. However, there is a significant lack of metrics specifically designed to assess question quality.
Aware of this lack, this paper focuses on developing metrics designed to assess question quality. Given the critical role of questions in driving meaningful conversations and generating useful answers, ensuring the quality of your questions is just as important as ensuring the quality of your answers.
The metric developed in this article aims to fill the gap in previous research in this area and provide a means of comprehensively assessing question quality, which will have a significant impact on the progress of the question and answer generation process.
Problem Evaluation
The metrics developed in this paper to evaluate the problem are as follows:
Relevance
Global correlation
Coverage
Overlap
diversity
Detail level
Fluency
Answer evaluation
Because large language models tend to generate long, detailed, and informative conversational responses, it is challenging to evaluate the answers they generate.
This article uses AzureML model evaluation, employing the following metrics to compare the generated answers to the actual situation:
Consistency: Given the context , compare the consistency between actual conditions and predictions.
Relevance: Measures how effectively an answer answers the main aspects of the question in context.
Authenticity: Defines whether the answer logically fits the information contained in the context and provides an integer score to determine the authenticity of the answer.
Model Evaluation
To evaluate different fine-tuned models, this article uses GPT-4 as the evaluator. About 270 question and answer pairs were generated from agricultural documents using GPT-4 as a real-world dataset. For each fine-tuned model and retrieval-augmented generative model, answers to these questions are generated.
This article evaluates LLMs on several different metrics:
Evaluation with Guidelines: For each Q&A pair , this paper prompts GPT-4 to generate an evaluation guide listing what the correct answer should contain. GPT-4 was then prompted to score each answer on a scale from 0 to 1 based on the criteria in the evaluation guide. Here's an example:
Succinctness: A rubric was created describing what concise and lengthy answers might contain. Based on this rubric, actual situation answers and LLM answer prompts GPT-4 is asked to be rated on a scale of 1 to 5.
Correctness: This article creates a rubric that describes what a complete, partially correct, or incorrect answer should contain. Based on this rubric, actual situation answers and LLM answer prompts GPT-4 is asked for a correct, incorrect or partially correct rating.
Experiments
The experiments in this article are divided into several independent experiments, each of which focuses on question and answer generation and evaluation, and retrieval enhancement. Specific aspects of generation and fine-tuning.
These experiments explore the following areas:
Q&A quality
Contextual research
Model to metric calculation
Comparison between combined generation and separate generation
Retrieve ablation studies
Fine-tuning
Question and Answer Quality
This experiment evaluated three large language models, namely GPT-3, GPT-3.5 and GPT- 4. Quality of generated question-answer pairs under different context settings. Quality assessment is based on multiple metrics, including relevance, coverage, overlap, and diversity.
Context Research
This experiment studies the impact of different context settings on the performance of model generated question and answer. It evaluates the generated question-answer pairs under three context settings: no context, context, and external context. An example is provided in Table 12.

In the context-free setting, GPT-4 has the highest coverage and size tips among the three models, indicating that it can cover more text parts, but The resulting questions are more lengthy. However, the three models have similar numerical values for variety, overlap, relevance, and fluency.
When context is included, GPT-3.5 has a slight increase in coverage compared to GPT-3, while GPT-4 maintains the highest coverage. For Size Prompt, GPT-4 has the largest value, indicating its ability to generate more lengthy questions and answers.
In terms of diversity and overlap, the three models perform similarly. For relevance and fluency, GPT-4 slightly increases compared to other models.
In external context settings, there is a similar situation.
Additionally, when looking at each model, the context-free setting appears to provide the best balance for GPT-4 in terms of average coverage, diversity, overlap, relevance, and fluency, but the resulting question-answer pairs Shorter. The context setting resulted in longer question-answer pairs and a slight decrease in other metrics except size. The external context setting produced the longest question-answer pairs but maintained average coverage and slightly increased average relevance and fluency.
Overall, for GPT-4, the context-free setting appears to provide the best balance in terms of average coverage, diversity, overlap, relevance, and fluency, but generates shorter answers. Contextual settings resulted in longer prompts and slight decreases in other metrics. The external context setting generated the longest prompts but maintained average coverage and slightly increased average relevance and fluency.
The choice between these three will therefore depend on the specific requirements of the task. If the length of the prompt is not considered, external context may be the best choice due to higher relevance and fluency scores.
Model to Metric Computation
This experiment compares the performance of GPT-3.5 and GPT-4 in computing the metric used to evaluate the quality of question-answer pairs.
Overall, while GPT-4 generally rates the generated question-answer pairs as more fluent and contextually authentic, they are less diverse and less relevant than the ratings of GPT-3.5. These perspectives are critical to understanding how different models perceive and evaluate the quality of generated content.
Comparison between combined generation and separate generation
This experiment explores the advantages and disadvantages between generating questions and answers separately and generating questions and answers in combination, and focuses on the Comparison of token usage efficiency.
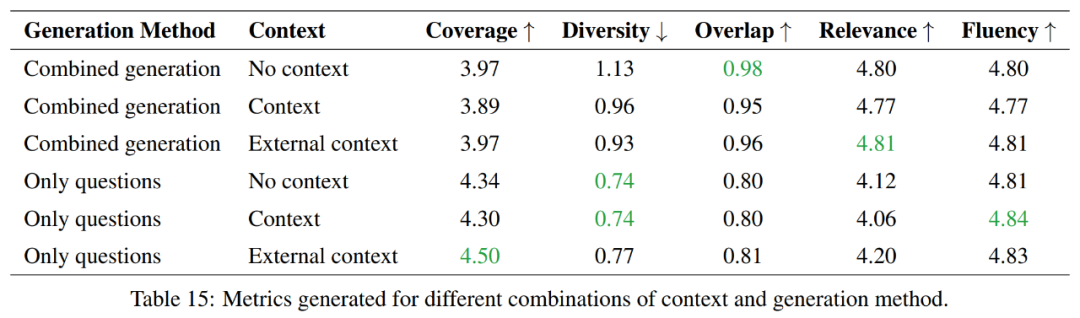
Overall, question generation-only methods provide better coverage and lower diversity, while combined generation methods score higher in terms of overlap and correlation. In terms of fluency, both methods perform similarly. The choice between these two methods will therefore depend on the specific requirements of the task.
If the goal is to cover more information and maintain more diversity, then a question-generating-only approach will be preferred. However, if a high degree of overlap with the source material is to be maintained, then a combined generation approach would be a better choice.
Retrieval ablation study
This experiment evaluates the retrieval capabilities generated by retrieval enhancement, a method that enhances the inherent knowledge of LLMs by providing additional context during question answering. Methods.
This paper studies the impact of the number of retrieved fragments (i.e. top-k) on the results and presents the results in Table 16. By considering more fragments, retrieval-enhanced generation is able to recover the original excerpts more consistently.
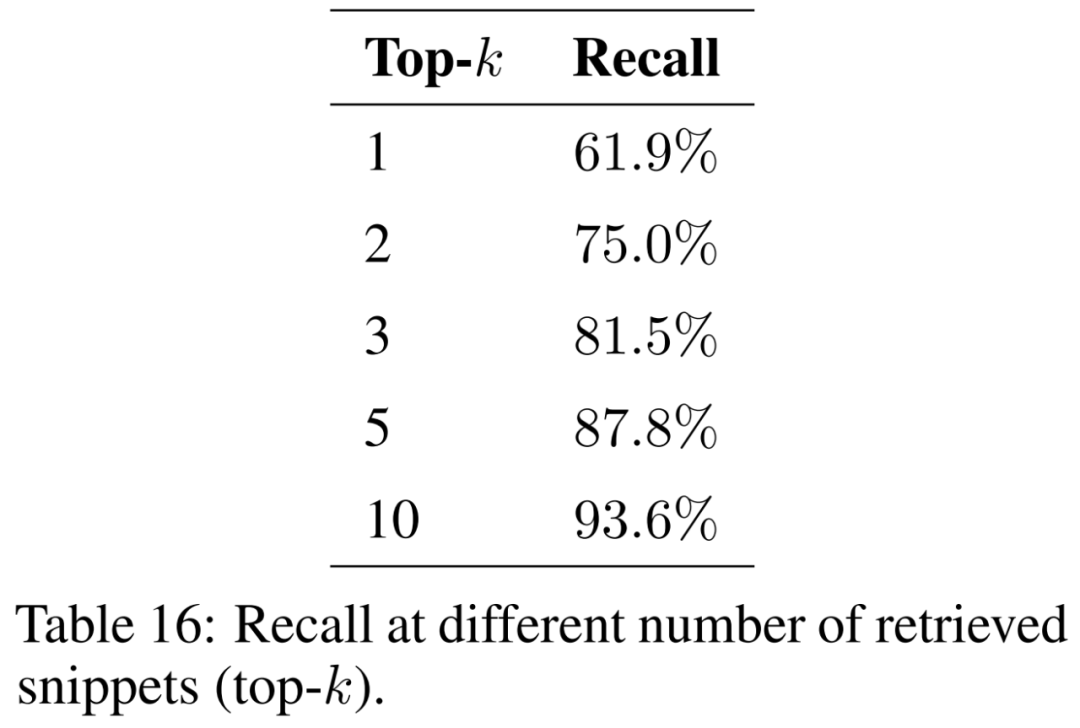
To ensure that the model can handle questions from a variety of geographical contexts and phenomena, the corpus of supporting documents needs to be expanded to cover a variety of topics. It is expected that the size of the index will increase as more documents are considered. This may increase the number of collisions between similar segments during retrieval, hindering the ability to recover relevant information for the input question and reducing recall.
Fine-tuning
This experiment evaluates the performance difference between the fine-tuned model and the basic instruction fine-tuned model. The goal is to understand the potential of fine-tuning to help models learn new knowledge.
For the base model, this article evaluates the open source models Llama2-13B-chat and Vicuna-13B-v1.5-16k. These two models are relatively small and represent an interesting trade-off between computation and performance. Both models are fine-tuned versions of Llama2-13B, using different methods.
Llama2-13B-chat performs instruction fine-tuning via supervised fine-tuning and reinforcement learning. Vicuna-13B-v1.5-16k is a fine-tuned version of the instruction via supervised fine-tuning on the ShareGPT dataset. Additionally, this paper evaluates base GPT-4 as a larger, more expensive, and more powerful alternative.
For the fine-tuned model, this paper fine-tunes Llama2-13B directly on agricultural data in order to compare its performance with similar models fine-tuned for more general tasks. This paper also fine-tunes GPT-4 to evaluate whether fine-tuning is still helpful on very large models. The results of the assessment with guidelines are shown in Table 18.
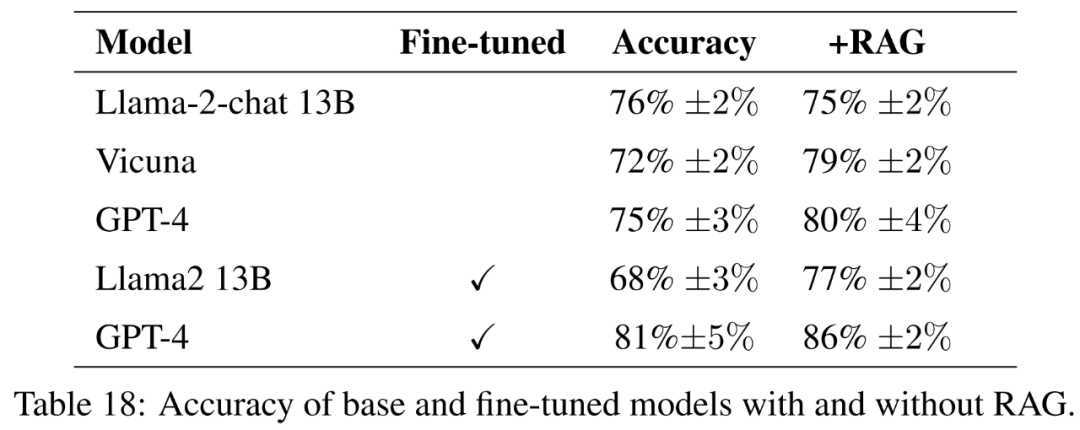
#To fully measure the quality of responses, in addition to accuracy, this article also evaluates the simplicity of responses.
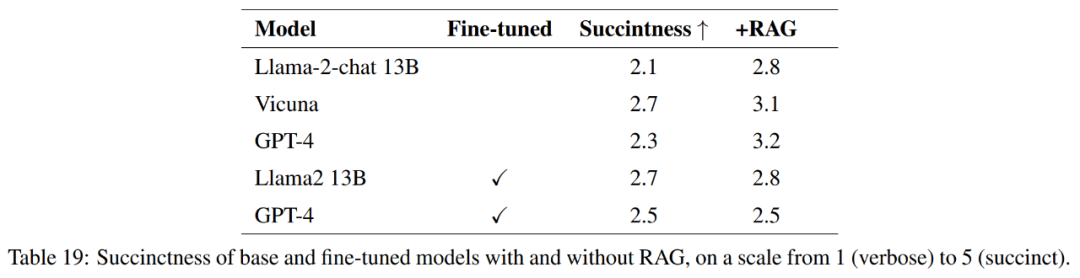
#As shown in Table 21, these models do not always provide a complete answer to the question. For example, some responses noted soil erosion as a problem but did not mention air quality.
Overall, the best performing models in terms of accurately and concisely answering reference answers are Vicuna retrieval-enhanced generation, GPT-4 retrieval-enhanced generation, GPT-4 fine-tuning, and GPT-4 fine-tuning retrieval Enhanced generation. These models offer a balanced blend of accuracy, simplicity, and depth of information.
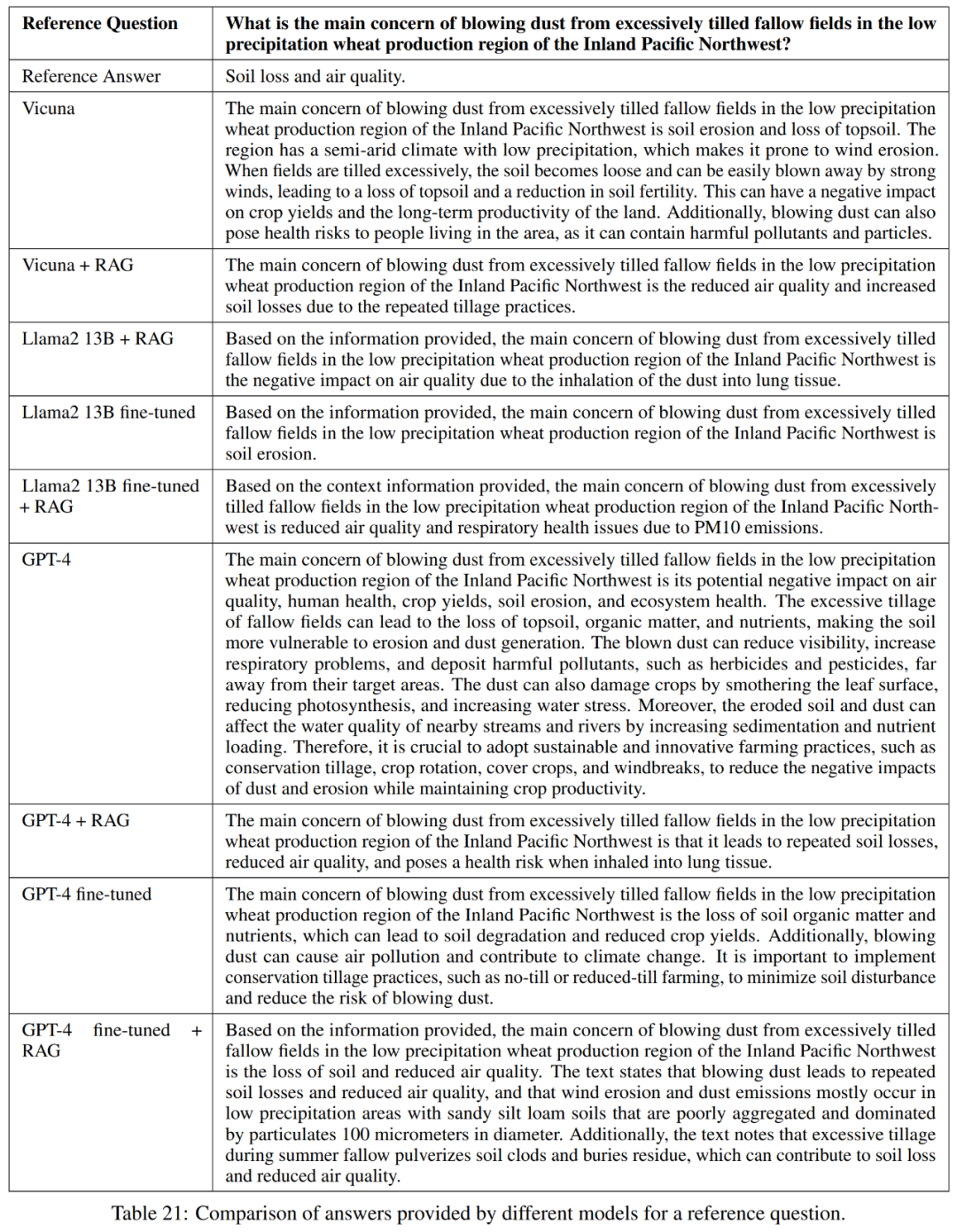
Knowledge discovery
The research goal of this paper is to explore the potential of fine-tuning to help GPT-4 learn new knowledge, which is useful for applications Research is crucial.
To test this, this article selected questions that were similar in at least three of the 50 U.S. states. The cosine similarity of the embeddings was then calculated and a list of 1000 such questions was identified. These questions are removed from the training set, and fine-tuning and fine-tuning with retrieval-enhanced generation are used to evaluate whether GPT-4 is able to learn new knowledge based on the similarities between different states.
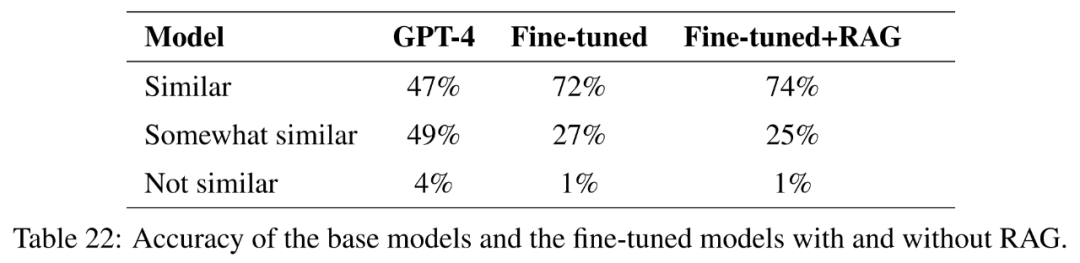
For more experimental results, please refer to the original paper.
The above is the detailed content of RAG or fine-tuning? Microsoft has released a guide to the construction process of large model applications in specific fields. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
The first mechanical claw! Yuanluobao appeared at the 2024 World Robot Conference and released the first chess robot that can enter the home
Aug 21, 2024 pm 07:33 PM
On August 21, the 2024 World Robot Conference was grandly held in Beijing. SenseTime's home robot brand "Yuanluobot SenseRobot" has unveiled its entire family of products, and recently released the Yuanluobot AI chess-playing robot - Chess Professional Edition (hereinafter referred to as "Yuanluobot SenseRobot"), becoming the world's first A chess robot for the home. As the third chess-playing robot product of Yuanluobo, the new Guoxiang robot has undergone a large number of special technical upgrades and innovations in AI and engineering machinery. For the first time, it has realized the ability to pick up three-dimensional chess pieces through mechanical claws on a home robot, and perform human-machine Functions such as chess playing, everyone playing chess, notation review, etc.
 Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
Claude has become lazy too! Netizen: Learn to give yourself a holiday
Sep 02, 2024 pm 01:56 PM
The start of school is about to begin, and it’s not just the students who are about to start the new semester who should take care of themselves, but also the large AI models. Some time ago, Reddit was filled with netizens complaining that Claude was getting lazy. "Its level has dropped a lot, it often pauses, and even the output becomes very short. In the first week of release, it could translate a full 4-page document at once, but now it can't even output half a page!" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ in a post titled "Totally disappointed with Claude", full of
 At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference, this domestic robot carrying 'the hope of future elderly care' was surrounded
Aug 22, 2024 pm 10:35 PM
At the World Robot Conference being held in Beijing, the display of humanoid robots has become the absolute focus of the scene. At the Stardust Intelligent booth, the AI robot assistant S1 performed three major performances of dulcimer, martial arts, and calligraphy in one exhibition area, capable of both literary and martial arts. , attracted a large number of professional audiences and media. The elegant playing on the elastic strings allows the S1 to demonstrate fine operation and absolute control with speed, strength and precision. CCTV News conducted a special report on the imitation learning and intelligent control behind "Calligraphy". Company founder Lai Jie explained that behind the silky movements, the hardware side pursues the best force control and the most human-like body indicators (speed, load) etc.), but on the AI side, the real movement data of people is collected, allowing the robot to become stronger when it encounters a strong situation and learn to evolve quickly. And agile
 Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Li Feifei's team proposed ReKep to give robots spatial intelligence and integrate GPT-4o
Sep 03, 2024 pm 05:18 PM
Deep integration of vision and robot learning. When two robot hands work together smoothly to fold clothes, pour tea, and pack shoes, coupled with the 1X humanoid robot NEO that has been making headlines recently, you may have a feeling: we seem to be entering the age of robots. In fact, these silky movements are the product of advanced robotic technology + exquisite frame design + multi-modal large models. We know that useful robots often require complex and exquisite interactions with the environment, and the environment can be represented as constraints in the spatial and temporal domains. For example, if you want a robot to pour tea, the robot first needs to grasp the handle of the teapot and keep it upright without spilling the tea, then move it smoothly until the mouth of the pot is aligned with the mouth of the cup, and then tilt the teapot at a certain angle. . this
 ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 Awards Announced: One of the Best Papers on Oracle Deciphering by HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
At this ACL conference, contributors have gained a lot. The six-day ACL2024 is being held in Bangkok, Thailand. ACL is the top international conference in the field of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and is held annually. ACL has always ranked first in academic influence in the field of NLP, and it is also a CCF-A recommended conference. This year's ACL conference is the 62nd and has received more than 400 cutting-edge works in the field of NLP. Yesterday afternoon, the conference announced the best paper and other awards. This time, there are 7 Best Paper Awards (two unpublished), 1 Best Theme Paper Award, and 35 Outstanding Paper Awards. The conference also awarded 3 Resource Paper Awards (ResourceAward) and Social Impact Award (
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
