
 Technology peripherals
AI
To remove noise in fluorescence images in a self-supervised manner, the Tsinghua team developed the spatial redundancy denoising Transformer method
Technology peripherals
AI
To remove noise in fluorescence images in a self-supervised manner, the Tsinghua team developed the spatial redundancy denoising Transformer method
To remove noise in fluorescence images in a self-supervised manner, the Tsinghua team developed the spatial redundancy denoising Transformer method

High signal-to-noise ratio of fluorescence imaging is crucial for accurate visualization of biological phenomena, however, the noise issue remains one of the major challenges to imaging sensitivity.
The research team at Tsinghua University provides the spatial redundancy denoising Transformer (SRDTrans) to remove noise in fluorescence images in a self-supervised manner.
The team proposed a new sampling strategy to extract adjacent orthogonal training pairs based on spatial redundancy and eliminate the dependence on high imaging speed. In addition, they developed a lightweight spatiotemporal Transformer architecture capable of capturing distant dependencies and high-resolution features at low computational cost.
SRDTrans preserves high-frequency information without causing over-smoothing of structures or distortion of fluorescence traces. Furthermore, SRDTrans does not rely on specific imaging procedures and sample assumptions, making it suitable for expansion into various imaging modalities and biological applications.
The study was titled "Spatial redundancy transformer for self-supervised fluorescence image denoising" and was published in "Nature Computational Science" on December 11, 2023.

The rapid development of in vivo imaging technology allows researchers to observe biological structures and activities at the micron and even nanoscale. Fluorescence microscopy, as a popular imaging method, helps reveal new physiological and pathological mechanisms with its high spatiotemporal resolution and molecular specificity. The primary goal of fluorescence microscopy is to obtain clean, clear images that contain sufficient sample information to ensure the accuracy of downstream analysis and support confident conclusions.
However, due to the influence of various biophysical and biochemical factors, fluorescence imaging suffers from various limitations in practical operations. For example, the brightness, phototoxicity, and photobleaching of fluorophores can all have a negative impact on imaging results. In the case of photon limitation, the inherent photon shot noise can significantly reduce the signal-to-noise ratio (SNR) of the image, especially under low illumination and high-speed observation conditions. These factors make the quality and reliability of fluorescence imaging challenging and need to be overcome and optimized in practice.
A variety of methods have been proposed to remove noise in fluorescence images. Traditional denoising algorithms based on numerical filtering and mathematical optimization have unsatisfactory performance and limited applicability. In recent years, deep learning has shown remarkable achievements in the field of image denoising.
By iteratively training using ground truth (GT) datasets, deep neural networks are able to learn the mapping relationship between noisy images and their clean counterparts. The effectiveness of this supervision method mainly depends on the paired GT images.
Obtaining clean images with pixel-by-pixel registration is a huge challenge when observing the activity of living organisms because samples often undergo rapid dynamic changes. In order to alleviate this contradiction, some self-supervised methods have been proposed to achieve more applicable and practical denoising in fluorescence imaging.
In order to obtain better denoising performance, the ability to simultaneously extract global spatial information and long-range temporal correlation is crucial, and due to the locality of the convolution kernel, this is What neural networks (CNN) lack. In addition, the inherent spectral bias makes CNN tend to preferentially fit low-frequency features while ignoring high-frequency features, inevitably producing over-smooth denoising results.
The research team at Tsinghua University proposed the spatial redundancy denoising Transformer (SRDTrans) to solve these dilemmas.
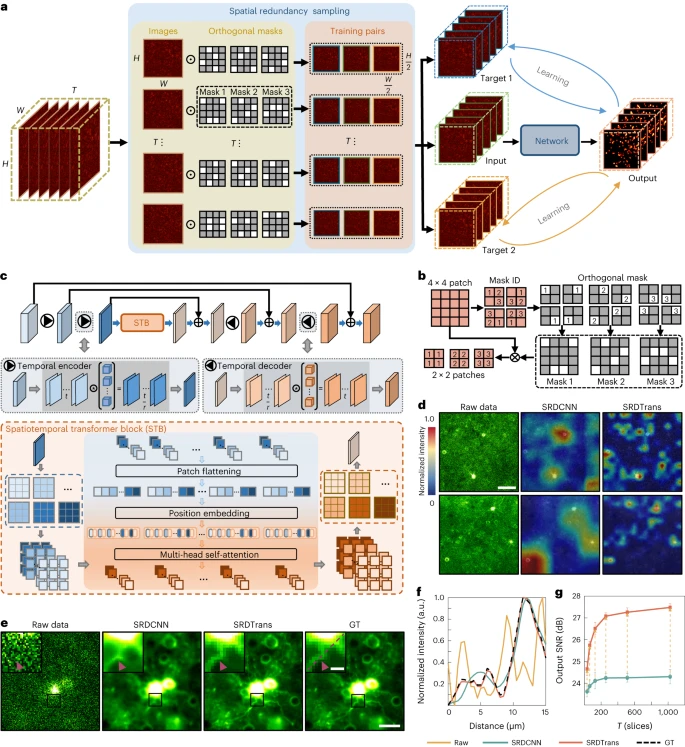
Figure: SRDTrans principle and performance evaluation. (Source: paper)
On the one hand, the researchers proposed a spatially redundant sampling strategy to extract three-dimensional (3D) training from raw time-lapse data in two orthogonal directions right.
This scheme does not rely on the similarity between two adjacent frames, so SRDTrans is suitable for very fast activities and extremely low imaging speeds, which is consistent with what the team previously proposed DeepCAD exploiting temporal redundancy is complementary.
Since SRDTrans does not rely on any assumptions about contrast mechanisms, noise models, sample dynamics and imaging speed. Therefore, it can be easily extended to other biological samples and imaging modalities, such as membrane voltage imaging, single protein detection, light sheet microscopy, confocal microscopy, light field microscopy, and super-resolution microscopy.
On the other hand, the researchers designed a lightweight spatiotemporal transformation network to fully exploit long-range correlation. The optimized feature interaction mechanism enables the model to obtain high-resolution features with a small number of parameters. Compared with classic CNN, the proposed SRDTrans has stronger global perception and high-frequency maintenance capabilities, and is able to reveal fine-grained spatiotemporal patterns that were previously difficult to discern.
The team demonstrated the superior noise reduction performance of SRDTrans in two representative applications. The first is single-molecule localization microscopy (SMLM), where adjacent frames are random subsets of fluorophores.
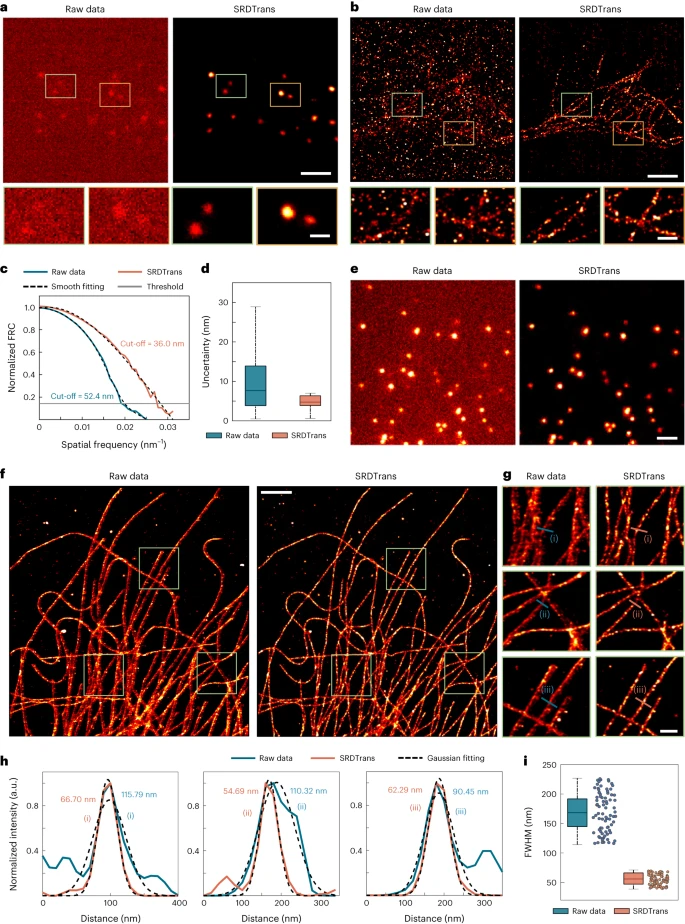
Figure: Applying SRDTrans to experimental SMLM data. (Source: Paper)
The other is two-photon calcium imaging of large 3D neuronal populations at volumetric velocities as low as 0.3Hz. Extensive qualitative and quantitative results demonstrate that SRDTrans can serve as an essential denoising tool for fluorescence imaging to observe a variety of cellular and subcellular phenomena.
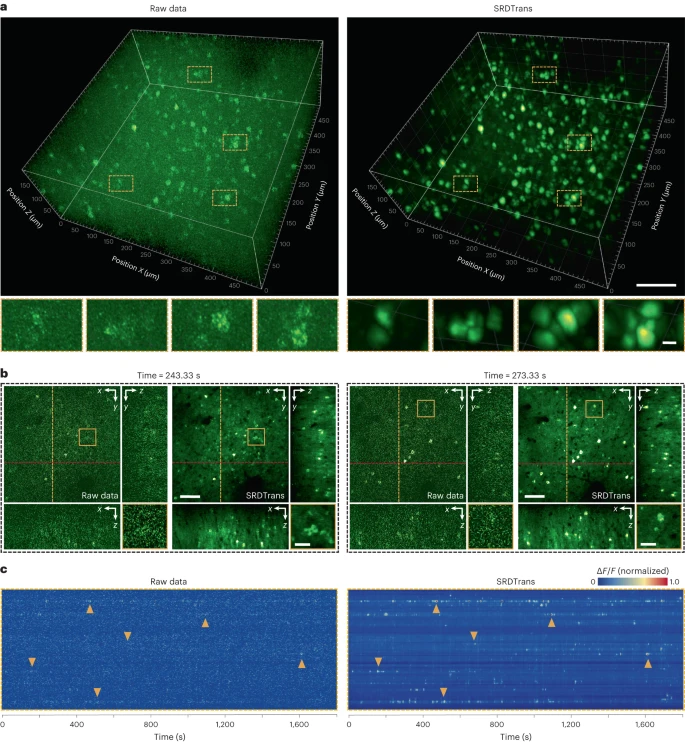
Figure: High-sensitivity calcium imaging of large neural volumes. (Source: paper)
SRDTrans also has some limitations, mainly in the basic assumption that adjacent pixels should have approximate structure. SRDTrans will fail if the spatial sampling rate is too low to provide sufficient redundancy. Another potential risk is the ability to generalize, as SRDTrans’ lightweight network architecture is better suited to specific tasks.
It is believed that training a specific model for specific data is the most reliable way to use deep learning for fluorescence image denoising. Therefore, new models should be trained to ensure optimal results when imaging parameters, modalities, and samples change.
As the development of fluorescent indicators moves toward faster kinetics, the imaging speed required to monitor biological dynamics at the millisecond level to record these rapid activities continues to grow. Obtaining sufficient sampling rates becomes increasingly challenging for denoising methods that rely on temporal redundancy. The team's perspective is to fill this gap by seeking to exploit spatial redundancy as an alternative to enable self-supervised denoising in more imaging applications.
Although the perfect case for spatially redundant sampling is a spatial sampling rate that is twice as high as diffraction-limited Nyquist sampling, thus ensuring that two adjacent pixels have nearly identical optical signals ; but in most cases, the endogenous similarity between the two spatially downsampled subsequences is sufficient to guide the training of the network.
However, this does not mean that the proposed spatial redundant sampling strategy can completely replace temporal redundant sampling, because ablation studies show that if equipped with the same network architecture, temporal redundancy Sampling enables better performance in high-speed imaging. The advantage of SRDTrans over DeepCAD at high imaging speeds is actually due to the Transformer architecture.
Generally speaking, spatial redundancy and temporal redundancy are two complementary sampling strategies that can achieve self-supervised training of fluorescence time-lapse imaging denoising networks. Which sampling strategy is used depends on which redundancy is greater in the data. It is worth noting that in many cases neither redundancy is sufficient to support current sampling strategies. The development of specific or more general self-supervised denoising methods will be of lasting value for fluorescence imaging.
Paper link: https://www.nature.com/articles/s43588-023-00568-2
The above is the detailed content of To remove noise in fluorescence images in a self-supervised manner, the Tsinghua team developed the spatial redundancy denoising Transformer method. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
