

As soon as Sora came out, it instantly became a top trend, and the popularity of the topic only increased.
The powerful ability to generate realistic videos has made many people exclaim that "reality no longer exists."
Even, the OpenAI technical report revealed that Sora can deeply understand the physical world in motion and can be called a true "world model."

And Turing giant LeCun, who has always focused on "world model" as a research focus, has also been involved in this debate.
The reason is that netizens dug up the views expressed by LeCun at the WGS Summit a few days ago: "In terms of AI video, we don't know what to do."
He believes that generating realistic videos based solely on text prompts is not equivalent to the model understanding the physical world. The approach to generating video is very different from models of the world based on causal predictions.

Next, LeCun explained in more detail:
Although the types of videos one can imagine There are many, but the video generation system only needs to create "one" reasonable sample to be successful.
For a real video, there are relatively few reasonable follow-up development paths. It is difficult to generate representative parts of these possibilities, especially under specific action conditions. Much more.
Furthermore, generating follow-up content for these videos is not only expensive, but virtually pointless.
A more ideal approach is to generate an "abstract representation" of those subsequent contents, removing scene details that are irrelevant to the actions we may take.
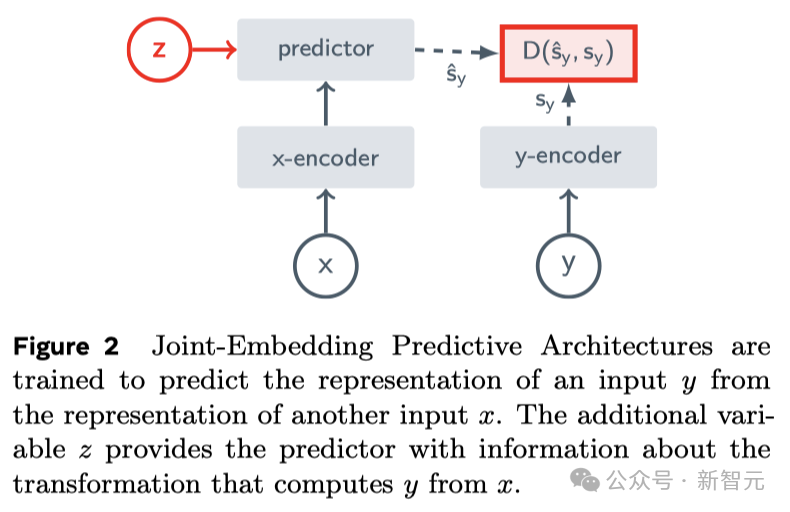
This is the core idea of JEPA (Joint Embedding Prediction Architecture). It is not generative, but predicts in the representation space.
Then, he used his own research on VICReg, I-JEPA, V-JEPA and the work of others to prove:
and reconstructed pixels Compared with generative architectures, such as Variational AE, Masked AE, Denoising AE, etc., the "joint embedding architecture" can produce better visual input Express.
When using the learned representations as input to a supervised head in downstream tasks (without fine-tuning the backbone), joint embedding architectures outperform generative architectures.
On the day the Sora model was released, Meta launched a new unsupervised "video prediction model" - V-JEPA.
Since LeCun first mentioned JEPA in 2022, I-JEPA and V-JEPA have strong prediction capabilities based on images and videos respectively.
It claims to be able to see the world in a "human way of understanding" and generate occluded parts through abstract and efficient prediction.

Paper address: https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual- representations-from-video/
V-JEPA will say "tear the paper in half" when seeing the action in the video below.

#For another example, if part of the video being viewed on a notebook is blocked, V-JEPA can make different predictions about the contents of the notebook.

It is worth mentioning that this is the superpower that V-JEPA acquired after watching 2 million videos.
Experimental results show that only through video feature prediction learning, we can obtain "efficient visual representation" that is widely applicable to various tasks based on action and appearance judgment, and there is no need to modify the model Make any adjustments to the parameters.
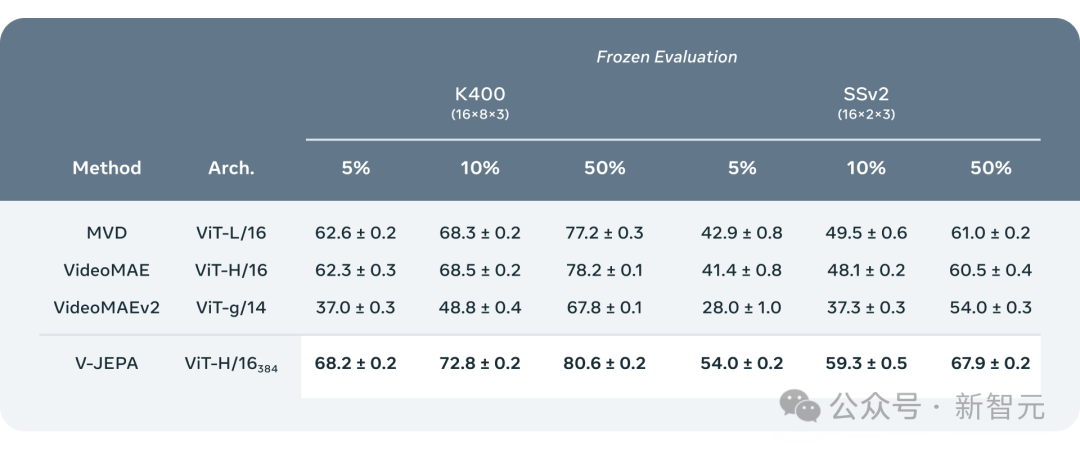
ViT-H/16 based on V-JEPA training achieved high scores of 81.9%, 72.2% and 77.9% on Kinetics-400, SSv2 and ImageNet1K benchmarks respectively.
Human beings are concerned about the world around them Understanding of the world, especially in the early stages of life, is largely gained through observation.
Take Newton's "Third Law of Motion" as an example. Even a baby or cat can naturally move something after pushing it off the table many times and observing the result. Realize: Any object at a high place will eventually fall.
This kind of understanding does not require long-term guidance or reading a large number of books.
As you can see, your inner world model—a situational understanding based on your mind’s understanding of the world—can anticipate these outcomes and is extremely effective.
Yann LeCun said that V-JEPA is a key step towards a deeper understanding of the world, aiming to enable machines to reason and plan more broadly.

In 2022, he first proposed the Joint Embedding Prediction Architecture (JEPA).
Our goal is to build advanced machine intelligence (AMI) that can learn like humans do, learning, adapting and planning efficiently by building an intrinsic model of the world around it. to solve complex tasks.

and generative AI model Sora Completely different, V-JEPA is a "non-generative model".
It learns by predicting hidden or missing parts of the video in an abstract space representation.
This is similar to the Image Joint Embedding Prediction Architecture (I-JEPA), which learns by comparing abstract representations of images rather than directly comparing "pixels".
Unlike those generative methods that try to reconstruct every missing pixel, V-JEPA is able to discard information that is difficult to predict. This approach achieves 1.5 in training and sample efficiency. -6x improvement.
V-JEPA adopts a self-supervised learning method and relies entirely on unlabeled data for pre-training.
After only pre-training, it can fine-tune the model to fit the specific task by labeling the data.
As a result, this architecture is more efficient than previous models, both in terms of the number of labeled samples required and the investment in learning from unlabeled data.
When using V-JEPA, the researchers blocked most of the video and only showed a very small part of the "context."
Then the predictor is asked to fill in the missing content—not with specific pixels, but with a more abstract description that fills in the representation space.
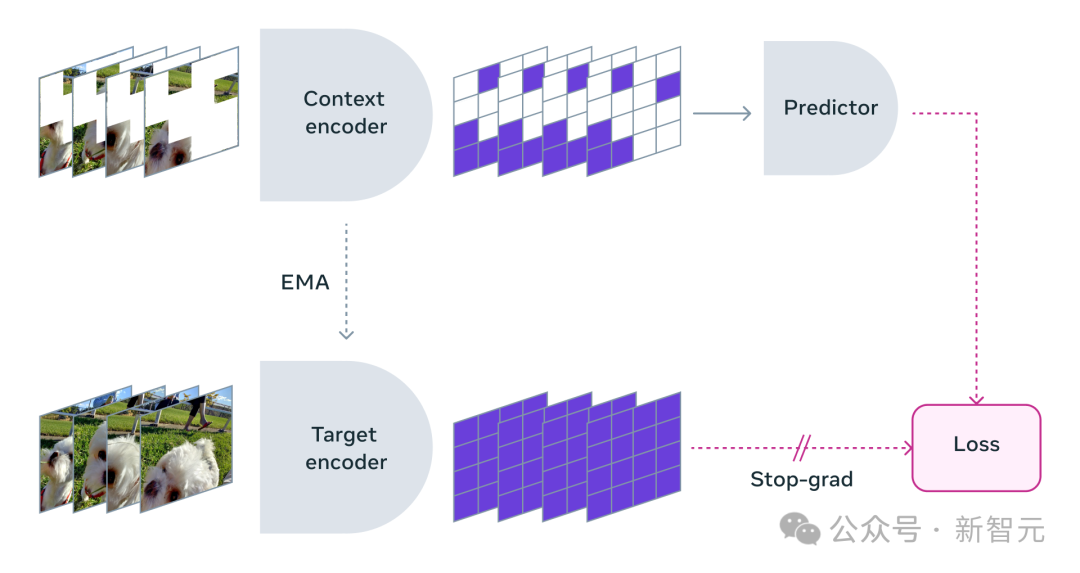
V-JEPA trains the visual encoder by predicting the hidden spatio-temporal regions in the learned latent space
#V-JEPA is not designed to understand specific types of actions.
Instead, it learned a lot about how the world works by applying self-supervised learning on various videos.
Meta researchers also carefully designed a masking strategy:
If you do not block most areas of the video, but just randomly select some small fragments, this will make the learning task too simple, causing the model to be unable to learn complex information about the world.
Again, it’s important to note that in most videos, things evolve over time.
If you only mask a small part of the video in a short period of time so that the model can see what happened before and after, it will also reduce the learning difficulty and make it difficult for the model to learn interesting content. .
Therefore, the researchers took the approach of simultaneously masking parts of the video in space and time, forcing the model to learn and understand the scene.
Prediction in an abstract representation space is critical because it allows the model to focus on high-level aspects of the video content concepts without having to worry about details that are often unimportant to completing the task.
After all, if a video showed a tree, you probably wouldn't care about the tiny movements of each leaf.
What really excites Meta researchers is that V-JEPA is the first video model to perform well on "frozen evaluation".
Freezing means that after all self-supervised pre-training is completed on the encoder and predictor, it will no longer be modified.
When we need the model to learn new skills, we just add a small, specialized layer or network on top of it, which is efficient and fast.
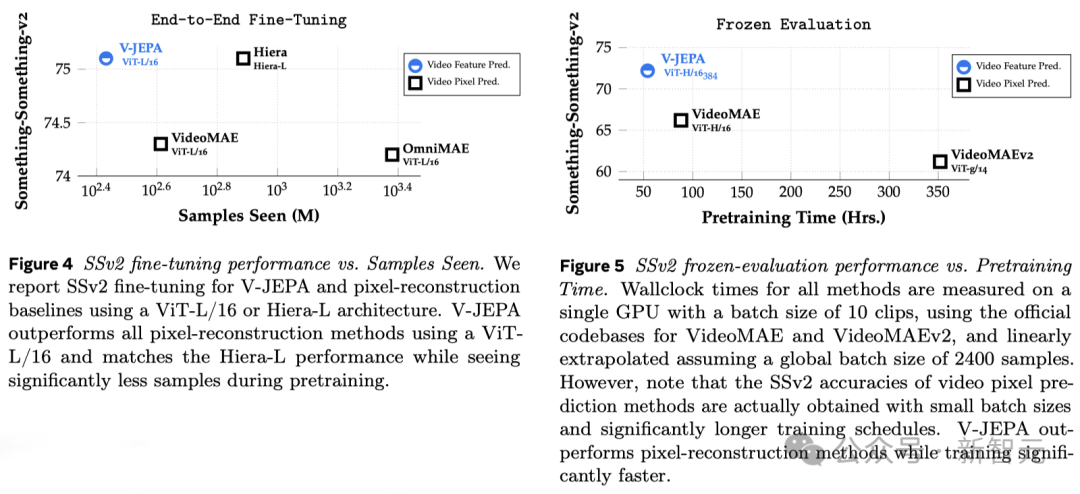
Previous research also required comprehensive fine-tuning, that is, after pre-training the model, in order to make the model perform on tasks such as fine-grained action recognition Excellent, any parameters or weights of the model need to be fine-tuned.
To put it bluntly, the fine-tuned model can only focus on a certain task and cannot adapt to other tasks.
If you want the model to learn different tasks, you must change the data and make specialized adjustments to the entire model.
V-JEPA’s research shows that it is possible to pre-train the model in one go without relying on any labeled data, and then use the model for multiple different tasks, such as action classification, fine-grained Object interactive recognition and activity positioning open up new possibilities.

- Few-sample frozen evaluation
## The researchers compared V-JEPA with other video processing models, paying particular attention to performance when the data is less annotated.
They selected two data sets, Kinetics-400 and Something-Something-v2, and adjusted the proportion of labeled samples used for training (5%, 10% and 50% respectively) , to observe the performance of the model in processing videos.
To ensure the reliability of the results, 3 independent tests were conducted at each ratio, and the average and standard deviation were calculated.
The results show that V-JEPA is better than other models in annotation usage efficiency, especially when the available annotation samples for each category are reduced, the difference between V-JEPA and other models The performance gap is even more obvious.

Although the "V" of V-JEPA stands for video, but so far it has mainly focused on analyzing the "visual elements" of video.
Obviously, Meta’s next step in research is to introduce a multi-modal method that can simultaneously process “visual and audio information” in videos.
As a proof-of-concept model, V-JEPA excels at identifying subtle object interactions in videos.
For example, being able to distinguish whether someone is putting down the pen, picking up the pen, or pretending to put down the pen but not actually putting it down.
However, this high-level motion recognition works well for short video clips (a few seconds to 10 seconds).
Therefore, another focus of the next step of research is how to make the model plan and predict over a longer time span.
So far, Meta researchers using V-JEPA have mainly focused on "perception" - —Understand the real-time situation of the world around you by analyzing video streams.
In this joint embedding prediction architecture, the predictor acts as a preliminary "physical world model" that can tell us generally what is happening in the video.
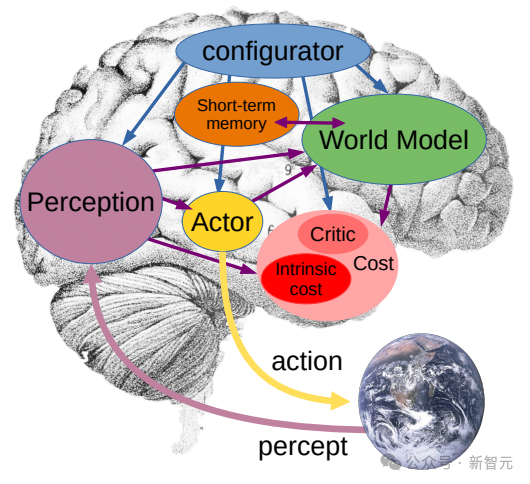
Meta’s next goal is to show how this predictor or world model can be used for planning and continuous decision-making.
We already know that the JEPA model can be trained by observing videos, much like a baby observing the world, and can learn a lot without strong supervision.
In this way, the model can quickly learn new tasks and recognize different actions using only a small amount of labeled data.
In the long run, V-JEPA’s strong situational understanding will be of great significance to the development of embodied AI technology and future augmented reality (AR) glasses in future applications.
Now think about it, if Apple Vision Pro can be blessed by the "world model", it will be even more invincible.
Obviously, LeCun is not optimistic about generative AI.

"Hear the advice of someone who has been trying to train a "world model" for presentation and planning."
Perplexity AI’s CEO says:
Sora is amazing, but not yet Get ready to model physics accurately. And the author of Sora was very smart and mentioned this in the technical report section of the blog, such as broken glass cannot be modeled well.
It is obvious that in the short term, reasoning based on such a complex world simulation cannot be run immediately on a home robot.
In fact, a very important nuance that many people fail to understand is:
Generating interesting-looking content in text or video does not mean (nor does it require) that it "understands" the content it generates. An agent model capable of reasoning based on understanding must, definitely, be outside of large models or diffusion models.

But some netizens said, "This is not the way humans learn."
"We only remember something unique about our past experiences, losing all the details. We can also model (create representations of) the environment anytime and anywhere because we perceive it .The most important part of intelligence is generalization."

There are also claims that it is still an embedding of the interpolated latent space, and so far you cannot build a "world model" this way.

Can Sora and V-JEPA really understand the world? What do you think?
The above is the detailed content of LeCun angrily accused Sora of not being able to understand the physical world! Meta's first AI video 'World Model' V-JEPA. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



