
 Technology peripherals
AI
The effect is explosive! OpenAI's first video generation model released, smooth and high-definition in 1 minute, netizens: The entire industry is RIP
Technology peripherals
AI
The effect is explosive! OpenAI's first video generation model released, smooth and high-definition in 1 minute, netizens: The entire industry is RIP
The effect is explosive! OpenAI's first video generation model released, smooth and high-definition in 1 minute, netizens: The entire industry is RIP

Just now, Ultraman released OpenAI’s first video generation modelSora.
Perfectly inherits the image quality and command-following capabilities of DALL·E 3, and can generate high-definition videos up to 1 minute long.
#AI imagined the Spring Festival of the Year of the Dragon, with red flags waving and huge crowds of people.
Many children watched the dragon dance team curiously, and some people took out their mobile phones to record people's different behaviors.

The streets of Tokyo after the rain, the wet groundReflectionThe neon light and shadow effects are comparable to RTX ON.

# The window of the moving train is occasionally blocked, and the reflection of the characters in the car briefly appears, which is very stunning.

You can also watch a Hollywood blockbuster-like movie trailer:

Vertical screen super close-up perspective Below, this lizard is full of details:

Netizens called the game over and lost their jobs:

Some people have even begun to "mourn" an entire industry:
AI understands the physical world in motion
OpenAI stated that it is teaching AI understands and simulates the physical world in motion, with the goal of training models to help people solve problems that require real-world interaction
Generating videos based on text prompts is just one step in the entire plan.

Currently Sora can generate complex scenes with multiple characters and specific movements. It can not only understand the user's prompts The requirements presented in , also understand how these objects exist in the physical world.
Sora can also create multiple shots within a single video and rely on a deep understanding of language to accurately interpret cue words, preserving character and visual style.
Beautiful, snowy Tokyo is bustling with people. The camera moves through bustling city streets, following several people enjoying a beautiful snowy day and shopping at nearby stalls. The gorgeous cherry blossom petals flutter in the wind along with the snowflakes.
OpenAI is not shy about Sora's current weaknesses, pointing out that it may have difficulty accurately simulating the physical principles of complex scenes, and may not be able to understand cause-and-effect relationships.
For example, "Five gray wolf cubs were playing and chasing each other on a remote gravel road." The number of wolves will change, and some will appear or disappear out of thin air.

The model may also obfuscate the spatial details of the cue , such as confusing left and right, and may be difficult to Precisely describe events that occur over time, such as following a specific camera trajectory. For example, in the prompt word "The basketball passes through the basket and then explodes", the basketball is not blocked by the basket correctly.
 In terms of technology, OpenAI has not disclosed much at present. A brief introduction is as follows:
In terms of technology, OpenAI has not disclosed much at present. A brief introduction is as follows:
Sora is a diffusion model, starting from noise, it can generate the entire video at once or extend the length of the video,
The key is that Generate predictions for multiple frames at once, ensuring that the subject of the picture remains unchanged even if it temporarily leaves the field of view.
Similar to the GPT model, Sora uses the Transformer architecture, which is highly scalable.
In terms of data, OpenAI represents videos and images as patches, similar to tokens in GPT.
With this unified data representation, models can be trained on a wider range of visual data than before, covering different sustained Time, resolution and aspect ratio.
Sora is built on past research on the DALL·E and GPT models. It uses DALL·E 3's restatement prompt word technology to generate highly descriptive annotations for visual training data, so it can more faithfully follow the user's textual instructions.
In addition to being able to generate videos based solely on textual instructions, the model is also able to take existing static images and generate videos from them, accurately animate the image content and pay attention to small details.
The model can also take existing video and expand it or fill in missing frames, see the technical paper for more information (to be released later) .
Sora is the foundation for models that can understand and simulate the real world. OpenAI believes that this feature will become an important milestone in achieving AGI.
Ultraman takes orders online
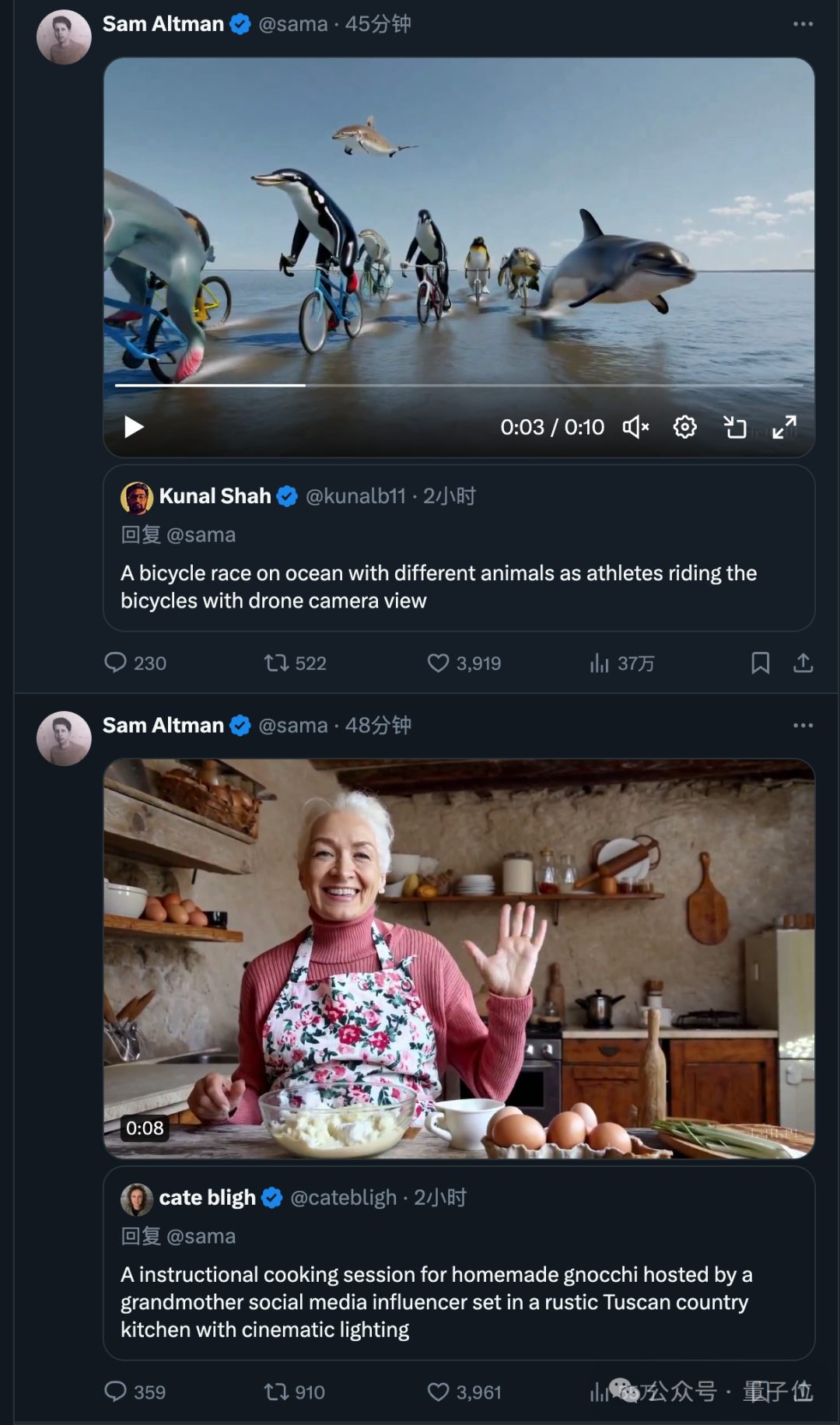
Currently, some visual artists, designers and filmmakers (as well as OpenAI employees) have gained access to Sora.
They began to publish new works continuously, and Ultraman also started taking orders online.
Bring your prompt word @sama, and you may receive a generated video reply.
The above is the detailed content of The effect is explosive! OpenAI's first video generation model released, smooth and high-definition in 1 minute, netizens: The entire industry is RIP. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
