
 Computer Tutorials
Computer Knowledge
How awesome is Pingora! Super popular web server surpasses Nginx
Computer Tutorials
Computer Knowledge
How awesome is Pingora! Super popular web server surpasses Nginx
How awesome is Pingora! Super popular web server surpasses Nginx

We’re excited to introduce Pingora, our new HTTP proxy built on Rust. Processing more than 1 trillion requests per day, improving performance and bringing new capabilities to Cloudflare customers while requiring only one-third of the CPU and memory resources of the original proxy infrastructure.
As Cloudflare continues to scale, we have found that NGINX's processing power can no longer meet our needs. While it performed well over the years, over time we realized it had limitations in meeting the challenges at our scale. Therefore, we felt it was necessary to build some new solutions to meet our performance and functionality needs.
Cloudflare customers and users use the Cloudflare global network as a proxy between HTTP clients and servers. We have had many discussions, developed many technologies and implemented new protocols such as QUIC and HTTP/2 optimizations to improve the efficiency of browsers and other user agents connecting to our network.
Today we will focus on another related aspect of this equation: proxy services, which are responsible for managing the traffic between our network and Internet servers. This proxy service provides support and power for our CDN, Workers fetch, Tunnel, Stream, R2 and many other features and products.
Let’s delve into why we decided to upgrade our legacy service and explore the development process of the Pingora system. This system is designed specifically for Cloudflare's customer use cases and scale.
Why build another proxy
In recent years, we have encountered some limitations when using NGINX. For some limitations, we have optimized or adopted methods to bypass them. However, there are some limitations that are more challenging.
Architectural limitations hurt performance
NGINX worker (process) architecture [4] has operational flaws for our use case, which hurts our performance and efficiency.
First of all, in NGINX, each request can only be processed by a single worker. This results in load imbalance among all CPU cores [5], resulting in slowdowns [6].
Due to this request process locking effect, requests that perform CPU-intensive or blocking IO tasks may slow down other requests. As these blog posts point out, we've invested a lot of time in solving these problems.
The most critical issue for our use case is connection reuse, when our machine establishes a TCP connection with the origin server that proxies the HTTP request. By reusing connections from a connection pool, you can skip the TCP and TLS handshakes required for new connections, thus speeding up the TTFB (time to first byte) of requests.
However, the NGINX connection pool [9] corresponds to a single worker. When a request reaches a worker, it can only reuse connections within that worker. As we add more NGINX workers to scale, our connection reuse gets worse because connections are spread across more isolated pools across all processes. This results in slower TTFB and more connections to maintain, which consumes our and our customers' resources (and money). 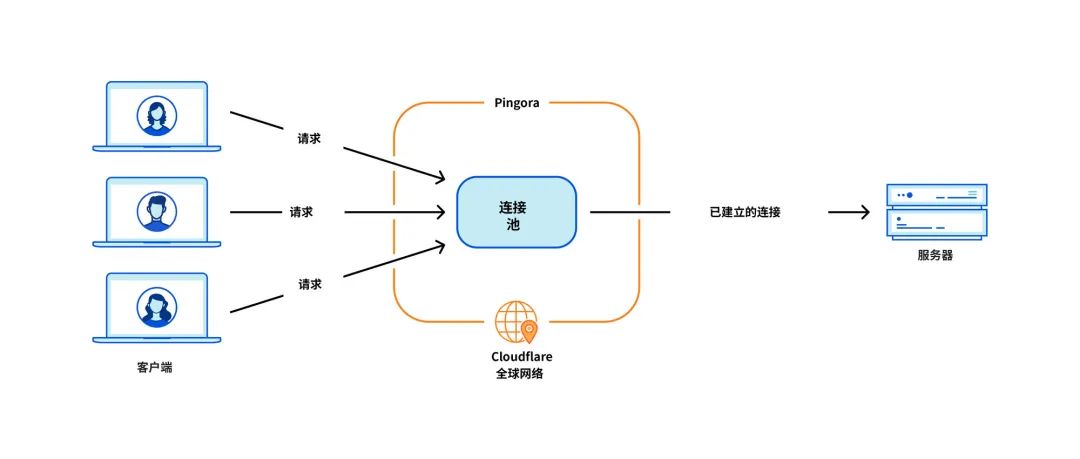
As mentioned in past blog posts, we have provided workarounds for some of these issues. But if we can solve the fundamental problem: the worker/process model, we will solve all these problems naturally.
Some types of functions are difficult to add
NGINX is a great web server, load balancer or simple gateway. But Cloudflare does much more than that. We used to build all the functionality we needed around NGINX, but trying to avoid too many divergences from the NGINX upstream codebase wasn't easy.
For example, when retrying a request/request failure[10], sometimes we want to send the request to a different origin server with a different set of request headers. But NGINX doesn't allow this. In this case, we need to spend time and effort to work around the limitations of NGINX.
At the same time, the programming languages we are forced to use do not help alleviate these difficulties. NGINX is written purely in C, which is not memory safe by design. Using a 3rd party code base like this is very error prone. Even for experienced engineers, it is easy to fall into memory safety problems [11], and we want to avoid these problems as much as possible.
Another language we use to complement C is Lua. It's less risky, but also less performant. Furthermore, when dealing with complex Lua code and business logic, we often find ourselves missing static typing [12].
Moreover, the NGINX community is not very active, and development is often done “behind closed doors” [13].
Choose to build our own
Over the past few years, as our customer base and feature set have continued to grow, we have continued to evaluate three options:
Over the past several years, we have evaluated these options every quarter. There is no obvious formula for deciding which option is best. Over the course of a few years, we continued to take the path of least resistance and continued to enhance NGINX. However, in some cases, the ROI of building your own agency may seem more worthwhile. We called upon to build an agent from scratch and started designing our dream agent application.
Pingora Project
Design Decision
In order to build a fast, efficient, and secure proxy that serves millions of requests per second, we had to first make some important design decisions.
We chose Rust[16] as the language of the project because it can do what C can do in a memory-safe way without affecting performance.
Although there are some great off-the-shelf 3rd party HTTP libraries, such as hyper[17], we chose to build our own because we wanted to maximize flexibility in handling HTTP traffic and ensure that we could follow our own Innovate at the pace.
At Cloudflare, we handle traffic for the entire internet. We have to support a lot of weird and non-RFC compliant cases of HTTP traffic. This is a common dilemma in the HTTP community and the Web, where difficult choices need to be made between strictly following the HTTP specification and adapting to the nuances of the broader ecosystem of potential legacy clients or servers.
HTTP status code is defined in RFC 9110 as a three-digit integer [18], which is usually expected to be in the range of 100 to 599. Hyper is one such implementation. However, many servers support the use of status codes between 599 and 999. We created a question [19] for this feature that explores various sides of the debate. While the hyper team did eventually accept this change, they had good reasons for rejecting such a request, and this was just one of many cases of non-compliance we needed to support.
In order to meet Cloudflare's position in the HTTP ecosystem, we need a robust, tolerant, customizable HTTP library that can survive the various risk environments of the Internet and support various non-compliant use cases . The best way to guarantee this is to implement our own architecture.
The next design decision concerns our workload scheduling system. We choose multithreading over multiprocessing [20] to easily share resources, especially connection pooling. We believe that work stealing [21] also needs to be implemented to avoid certain categories of performance issues mentioned above. The Tokio asynchronous runtime results in a perfect fit [22] for our needs.
Finally, we want our projects to be intuitive and developer-friendly. What we are building is not a final product but should be extensible as a platform as more features are built on top of it. We decided to implement a programmable interface based on “request lifecycle” events similar to NGINX/OpenResty[23]. For example, the Request Filter stage allows developers to run code to modify or deny requests when request headers are received. With this design, we can clearly separate our business logic and common proxy logic. Developers previously working on NGINX can easily switch to Pingora and quickly become more productive.
Pingora is faster in production
Let’s fast forward to now. Pingora handles almost all HTTP requests that require interaction with the origin server (such as cache misses), and we collect a lot of performance data in the process.
First, let’s see how Pingora speeds up our customers’ traffic. Overall traffic on Pingora shows a median TTFB reduction of 5ms and a 95th percentile reduction of 80ms. It's not because we run the code faster. Even our old service can handle requests in the sub-millisecond range.
The time savings comes from our new architecture, which shares connections across all threads. This means better connection reuse and less time spent on TCP and TLS handshakes.
Across all customers, Pingora has only one-third new connections per second compared to the old service. For one major customer, it increased connection reuse from 87.1% to 99.92%, which reduced new connections by 160x. To put it into perspective, by switching to Pingora, we saved our customers and users 434 years of handshakes every day.
More features
Having a developer-friendly interface that is familiar to engineers while removing previous limitations allows us to develop more features faster. Core features like new protocols serve as the building blocks for how we deliver more to our customers.
For example, we were able to add HTTP/2 upstream support to Pingora without significant roadblocks. This enables us to make gRPC available to our customers shortly[24]. Adding the same functionality to NGINX would require more engineering effort and may not be possible [25].
Recently, we announced the launch of Cache Reserve[26], in which Pingora uses R2 storage as the cache layer. As we add more features to Pingora, we are able to offer new products that were not previously feasible.
More efficient
In a production environment, Pingora consumes approximately 70% less CPU and 67% less memory under the same traffic load compared to our old service. The savings come from several factors.
Our Rust code runs more efficiently [28] than the old Lua code [27]. On top of that, there are also efficiency differences in their architecture. For example, in NGINX/OpenResty, when Lua code wants to access an HTTP header, it must read it from an NGINX C structure, allocate a Lua string, and then copy it into a Lua string. Afterwards, Lua also garbage collects its new strings. In Pingora, it's just a straight string access.
The multi-threaded model also makes sharing data across requests more efficient. NGINX also has shared memory, but due to implementation limitations, each shared memory access must use a mutex, and only strings and numbers can be put into shared memory. In Pingora, most shared items can be directly accessed through shared references behind atomic reference counters [29].
As mentioned above, another important part of the CPU savings is the reduction of new connections. The TLS handshake is obviously more expensive than just sending and receiving data over an established connection.
safer
At our scale, releasing features quickly and securely is difficult. It is difficult to predict every edge case that may occur in a distributed environment handling millions of requests per second. Fuzz testing and static analysis can only alleviate so much. Rust's memory-safe semantics protect us from undefined behavior and give us confidence that our services will run correctly.
With these guarantees, we can focus more on how our service changes will interact with other services or customer sources. We were able to develop features at a higher cadence without being saddled with memory safety and hard-to-diagnose crashes.
When a crash does occur, engineers need to take the time to diagnose how it occurred and what caused it. Since Pingora was founded, we've served hundreds of billions of requests and have yet to crash due to our service code.
In fact, Pingora crashes are so rare that when we encounter one, we usually find unrelated problems. Recently, we discovered a kernel bug [30] shortly after our service started crashing. We've also discovered hardware issues on some machines that in the past ruled out rare memory errors caused by our software, even after significant debugging was nearly impossible.
Summarize
In summary, we have built a faster, more efficient, and more versatile in-house agent that serves as a platform for our current and future products.
We'll later cover more technical details about the problems and application optimizations we faced, as well as the lessons we learned from building Pingora and rolling it out to support important parts of the Internet. We will also introduce our open source initiatives.
This article is reproduced from CloudFlare blog, written by Yuchen Wu & Andrew Hauck
Link: https://blog.cloudflare.com/zh-cn/how-we-built-pingora-the-proxy-that-connects-cloudflare-to-the-internet-zh-cn/
The above is the detailed content of How awesome is Pingora! Super popular web server surpasses Nginx. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 How to allow external network access to tomcat server
Apr 21, 2024 am 07:22 AM
How to allow external network access to tomcat server
Apr 21, 2024 am 07:22 AM
To allow the Tomcat server to access the external network, you need to: modify the Tomcat configuration file to allow external connections. Add a firewall rule to allow access to the Tomcat server port. Create a DNS record pointing the domain name to the Tomcat server public IP. Optional: Use a reverse proxy to improve security and performance. Optional: Set up HTTPS for increased security.
 How to run thinkphp
Apr 09, 2024 pm 05:39 PM
How to run thinkphp
Apr 09, 2024 pm 05:39 PM
Steps to run ThinkPHP Framework locally: Download and unzip ThinkPHP Framework to a local directory. Create a virtual host (optional) pointing to the ThinkPHP root directory. Configure database connection parameters. Start the web server. Initialize the ThinkPHP application. Access the ThinkPHP application URL and run it.
 Welcome to nginx!How to solve it?
Apr 17, 2024 am 05:12 AM
Welcome to nginx!How to solve it?
Apr 17, 2024 am 05:12 AM
To solve the "Welcome to nginx!" error, you need to check the virtual host configuration, enable the virtual host, reload Nginx, if the virtual host configuration file cannot be found, create a default page and reload Nginx, then the error message will disappear and the website will be normal show.
 How to communicate between docker containers
Apr 07, 2024 pm 06:24 PM
How to communicate between docker containers
Apr 07, 2024 pm 06:24 PM
There are five methods for container communication in the Docker environment: shared network, Docker Compose, network proxy, shared volume, and message queue. Depending on your isolation and security needs, choose the most appropriate communication method, such as leveraging Docker Compose to simplify connections or using a network proxy to increase isolation.
 How to register phpmyadmin
Apr 07, 2024 pm 02:45 PM
How to register phpmyadmin
Apr 07, 2024 pm 02:45 PM
To register for phpMyAdmin, you need to first create a MySQL user and grant permissions to it, then download, install and configure phpMyAdmin, and finally log in to phpMyAdmin to manage the database.
 How to deploy nodejs project to server
Apr 21, 2024 am 04:40 AM
How to deploy nodejs project to server
Apr 21, 2024 am 04:40 AM
Server deployment steps for a Node.js project: Prepare the deployment environment: obtain server access, install Node.js, set up a Git repository. Build the application: Use npm run build to generate deployable code and dependencies. Upload code to the server: via Git or File Transfer Protocol. Install dependencies: SSH into the server and use npm install to install application dependencies. Start the application: Use a command such as node index.js to start the application, or use a process manager such as pm2. Configure a reverse proxy (optional): Use a reverse proxy such as Nginx or Apache to route traffic to your application
 How to generate URL from html file
Apr 21, 2024 pm 12:57 PM
How to generate URL from html file
Apr 21, 2024 pm 12:57 PM
Converting an HTML file to a URL requires a web server, which involves the following steps: Obtain a web server. Set up a web server. Upload HTML file. Create a domain name. Route the request.
 What to do if the installation of phpmyadmin fails
Apr 07, 2024 pm 03:15 PM
What to do if the installation of phpmyadmin fails
Apr 07, 2024 pm 03:15 PM
Troubleshooting steps for failed phpMyAdmin installation: Check system requirements (PHP version, MySQL version, web server); enable PHP extensions (mysqli, pdo_mysql, mbstring, token_get_all); check configuration file settings (host, port, username, password); Check file permissions (directory ownership, file permissions); check firewall settings (whitelist web server ports); view error logs (/var/log/apache2/error.log or /var/log/nginx/error.log); seek Technical support (phpMyAdmin
