
 Backend Development
Python Tutorial
Learn the simple installation method of Scrapy and quickly develop crawler programs
Backend Development
Python Tutorial
Learn the simple installation method of Scrapy and quickly develop crawler programs
Learn the simple installation method of Scrapy and quickly develop crawler programs


Scrapy installation tutorial: Get started easily and quickly develop crawler programs
Introduction:
With the rapid development of the Internet, a large amount of data is continuously generated and updated. How to efficiently crawl the required data from the Internet has become a topic of concern to many developers. As an efficient, flexible and open source Python crawler framework, Scrapy provides developers with a solution to quickly develop crawler programs. This article will introduce the installation and use of Scrapy in detail, and give specific code examples.
1. Scrapy installation
To use Scrapy, you first need to install Scrapy's dependencies in the local environment. The following are the steps to install Scrapy:
- Installing Python
Scrapy is an open source framework based on the Python language, so you need to install Python first. You can download the latest version of Python from the official website (https://www.python.org/downloads/) and install it according to the operating system. -
Installing Scrapy
After the Python environment is set up, you can use the pip command to install Scrapy. Open a command line window and execute the following command to install Scrapy:pip install scrapy
Copy after loginIf the network environment is poor, you can consider using Python’s mirror source for installation, such as Douban source:
pip install scrapy -i https://pypi.douban.com/simple/
Copy after loginWaiting for installation After completion, you can execute the following command to verify whether Scrapy is installed successfully:
scrapy version
Copy after loginIf you can see the version information of Scrapy, it means Scrapy was installed successfully.
2. Steps to use Scrapy to develop a crawler program
Create a Scrapy project
Use the following command to create a Scrapy project in the specified directory :scrapy startproject myspider
Copy after loginThis will create a folder named "myspider" in the current directory with the following structure:
myspider/
- scrapy.cfg
- myspider/
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
spiders/
- __init__.py
Define Item
In Scrapy, Item is used to define the data structure that needs to be crawled. Open the "myspider/items.py" file and you can define the fields that need to be crawled, for example:import scrapy class MyItem(scrapy.Item): title = scrapy.Field() content = scrapy.Field() url = scrapy.Field()
Copy after loginWriting Spider
Spider is used in the Scrapy project to define how to crawl data s component. Open the "myspider/spiders" directory, create a new Python file, such as "my_spider.py", and write the following code:import scrapy from myspider.items import MyItem class MySpider(scrapy.Spider): name = 'myspider' start_urls = ['https://www.example.com'] def parse(self, response): for item in response.xpath('//div[@class="content"]'): my_item = MyItem() my_item['title'] = item.xpath('.//h2/text()').get() my_item['content'] = item.xpath('.//p/text()').get() my_item['url'] = response.url yield my_itemCopy after login- Configuring Pipeline
Pipeline is used to process crawlers. Data, such as storing to a database or writing to a file, etc. In the "myspider/pipelines.py" file, you can write the logic for processing data. - Configuration Settings
In the "myspider/settings.py" file, you can configure some parameters of Scrapy, such as User-Agent, download delay, etc. Run the crawler program
Enter the "myspider" directory on the command line and execute the following command to run the crawler program:scrapy crawl myspider
Copy after loginWait for the crawler program to complete. Get the captured data.
Conclusion:
Scrapy, as a powerful crawler framework, provides a solution for fast, flexible and efficient development of crawler programs. Through the introduction and specific code examples of this article, I believe readers can easily get started and quickly develop their own crawler programs. In practical applications, you can also conduct more in-depth learning and advanced applications of Scrapy according to specific needs.
The above is the detailed content of Learn the simple installation method of Scrapy and quickly develop crawler programs. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Reasons and solutions for scipy library installation failure
Feb 22, 2024 pm 06:27 PM
Reasons and solutions for scipy library installation failure
Feb 22, 2024 pm 06:27 PM
Reasons and solutions for scipy library installation failure, specific code examples are required When performing scientific calculations in Python, scipy is a very commonly used library, which provides many functions for numerical calculations, optimization, statistics, and signal processing. However, when installing the scipy library, sometimes you encounter some problems, causing the installation to fail. This article will explore the main reasons why scipy library installation fails and provide corresponding solutions. Installation of dependent packages failed. The scipy library depends on some other Python libraries, such as nu.
 CentOS7 various version image download addresses and version descriptions (including Everything version)
Feb 29, 2024 am 09:20 AM
CentOS7 various version image download addresses and version descriptions (including Everything version)
Feb 29, 2024 am 09:20 AM
When loading CentOS-7.0-1406, there are many optional versions. For ordinary users, they don’t know which one to choose. Here is a brief introduction: (1) CentOS-xxxx-LiveCD.ios and CentOS-xxxx- What is the difference between bin-DVD.iso? The former only has 700M, and the latter has 3.8G. The difference is not only in size, but the more essential difference is that CentOS-xxxx-LiveCD.ios can only be loaded into the memory and run, and cannot be installed. Only CentOS-xxx-bin-DVD1.iso can be installed on the hard disk. (2) CentOS-xxx-bin-DVD1.iso, Ce
 How to solve the problem of scipy library installation failure? Quick method sharing
Feb 19, 2024 pm 08:02 PM
How to solve the problem of scipy library installation failure? Quick method sharing
Feb 19, 2024 pm 08:02 PM
What should I do if the scipy library installation fails? Quick solution sharing, specific code examples are required scipy is a powerful Python library widely used in scientific computing, providing many functions for mathematical, scientific and engineering calculations. However, when installing scipy, sometimes you encounter some problems that cause the installation to fail. This article will introduce you to some common scipy installation failure problems, and provide corresponding solutions and specific sample codes. Problem 1: Missing dependent libraries. Before installing scipy, you need to install it first.
 Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
As a powerful deep learning framework, PyTorch is widely used in various machine learning projects. As a powerful Python integrated development environment, PyCharm can also provide good support when implementing deep learning tasks. This article will introduce in detail how to install PyTorch in PyCharm and provide specific code examples to help readers quickly get started using PyTorch for deep learning tasks. Step 1: Install PyCharm First, we need to make sure we have
 Efficient installation: tips and tricks to quickly install the pandas library
Feb 21, 2024 am 09:45 AM
Efficient installation: tips and tricks to quickly install the pandas library
Feb 21, 2024 am 09:45 AM
Efficient Installation: Tips and tricks for quickly installing the pandas library, requiring specific code examples Overview: Pandas is a powerful data processing and analysis tool that is very popular among Python developers. However, installing the pandas library may sometimes face some challenges, especially if the network conditions are poor. This article will introduce some tips and tricks to help you quickly install the pandas library, and provide specific code examples. Install using pip: pip is the official package manager for Python
 OpenCV installation tutorial: a must-read for PyCharm users
Feb 22, 2024 pm 09:21 PM
OpenCV installation tutorial: a must-read for PyCharm users
Feb 22, 2024 pm 09:21 PM
OpenCV is an open source library for computer vision and image processing, which is widely used in machine learning, image recognition, video processing and other fields. When developing using OpenCV, in order to better debug and run programs, many developers choose to use PyCharm, a powerful Python integrated development environment. This article will provide PyCharm users with an installation tutorial for OpenCV, with specific code examples. Step One: Install Python First, make sure you have Python installed
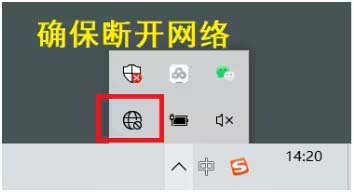 How to install solidworks2016-solidworks2016 installation tutorial
Mar 05, 2024 am 11:25 AM
How to install solidworks2016-solidworks2016 installation tutorial
Mar 05, 2024 am 11:25 AM
Recently, many friends have asked me how to install solidworks2016. Next, let us learn the installation tutorial of solidworks2016. I hope it can help everyone. 1. First, exit the anti-virus software and make sure to disconnect from the network (as shown in the picture). 2. Then right-click the installation package and select to extract to the SW2016 installation package (as shown in the picture). 3. Double-click to enter the decompressed folder. Right-click setup.exe and click Run as administrator (as shown in the picture). 4. Then click OK (as shown in the picture). 5. Then check [Single-machine installation (on this computer)] and click [Next] (as shown in the picture). 6. Then enter the serial number and click [Next] (as shown in the picture). 7.
 How to install NeXus desktop beautification-NeXus desktop beautification installation tutorial
Mar 04, 2024 am 11:30 AM
How to install NeXus desktop beautification-NeXus desktop beautification installation tutorial
Mar 04, 2024 am 11:30 AM
Friends, do you know how to install NeXus desktop beautification? Today I will explain the installation tutorial of NeXus desktop beautification. If you are interested, come and take a look with me. I hope it can help you. 1. Download the latest version of the Nexus desktop beautification plug-in software package from this site (as shown in the picture). 2. Unzip the Nexus desktop beautification plug-in software and run the file (as shown in the picture). 3. Double-click to open and enter the Nexus desktop beautification plug-in software interface. Please read the installation license agreement below carefully to see if you accept all the terms of the above license agreement. Click I agree and click Next (as shown in the picture). 4. Select the destination location. The software will be installed in the folder listed below. To select a different location and create a new path, click Next
