
 Technology peripherals
AI
You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.
Technology peripherals
AI
You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.
You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.

When it comes to the future of AI assistants, people can easily think of Jarvis, the AI assistant in the "Iron Man" series. Jarvis shows dazzling functions in the movie. He is not only Tony Stark's right-hand man, but also his bridge to communicate with advanced technology. With the emergence of large-scale models, the way humans use tools is undergoing revolutionary changes, and perhaps we are one step closer to a science fiction scenario. Imagine a multi-modal agent that can directly control the computers around us through keyboard and mouse like humans. How exciting this breakthrough will be.
AI Assistant Jarvis
The latest research from the School of Artificial Intelligence of Jilin University "ScreenAgent: A Vision Language Model-driven Computer Control Agent" shows that the imagination of using a visual large language model to directly control the computer GUI has become a reality. This study proposed the ScreenAgent model, which for the first time explored the direct control of computer mouse and keyboard through VLM Agent without the need for additional label assistance, achieving the goal of direct computer operation of large-scale models. In addition, ScreenAgent uses an automated "plan-execute-reflect" process to achieve continuous control of the GUI interface for the first time. This work explores and innovates human-computer interaction methods, and also open-sources resources including data sets, controllers, and training codes with precise positioning information.

- ##Paper address: https://arxiv.org/abs/2402.07945
- Project address: https://github.com/niuzaisheng/ScreenAgent
ScreenAgent is the user Provide convenient online entertainment, shopping, travel and reading experiences. It can also be used as a personal butler to help manage personal computers and achieve quick work. It becomes a powerful office assistant without any effort. Through practical effects, users can understand its functionality.
Take you to surf the Internet and achieve entertainment freedom
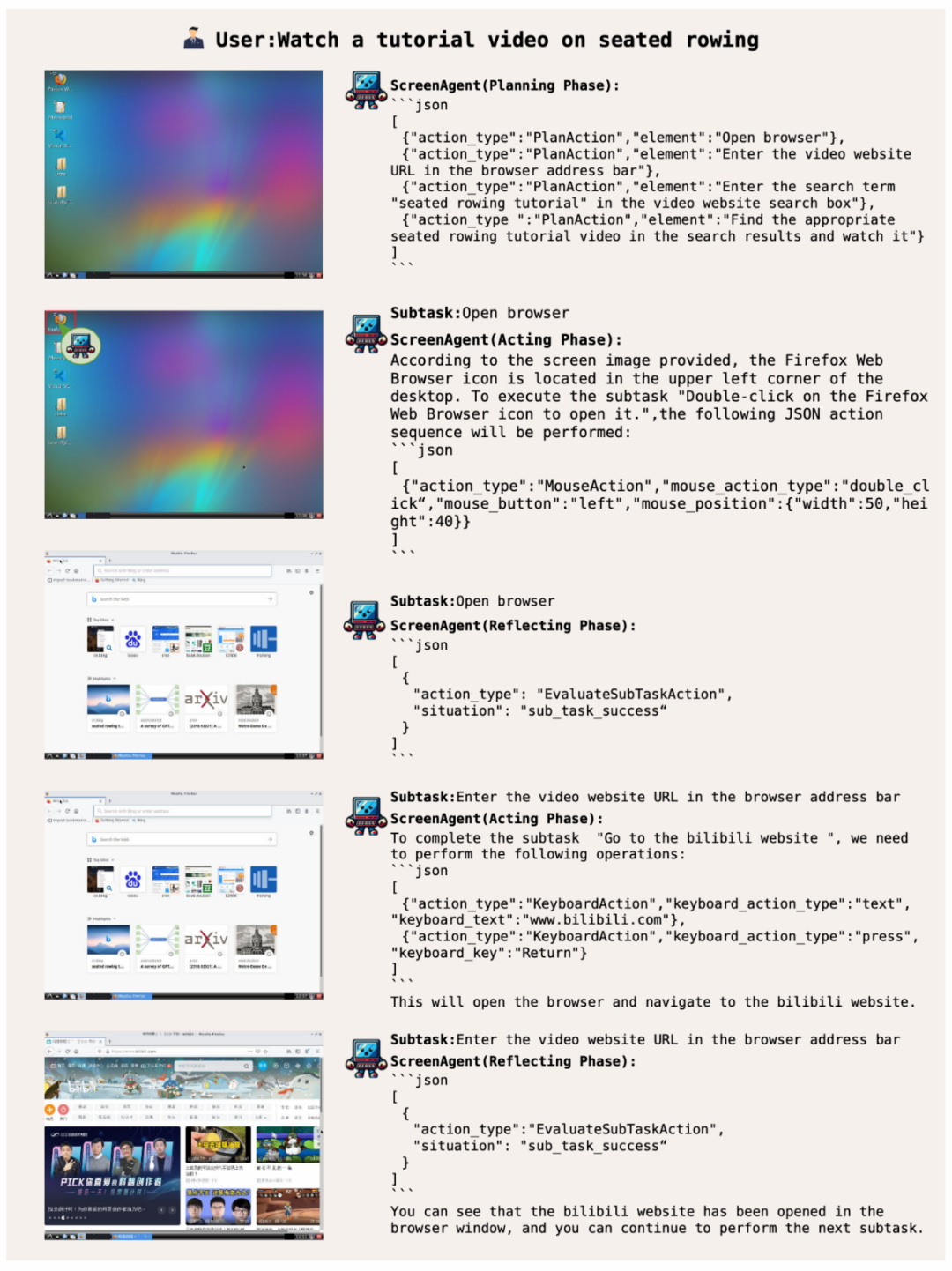
##ScreenAgent searches for and plays specified videos online based on user text descriptions :
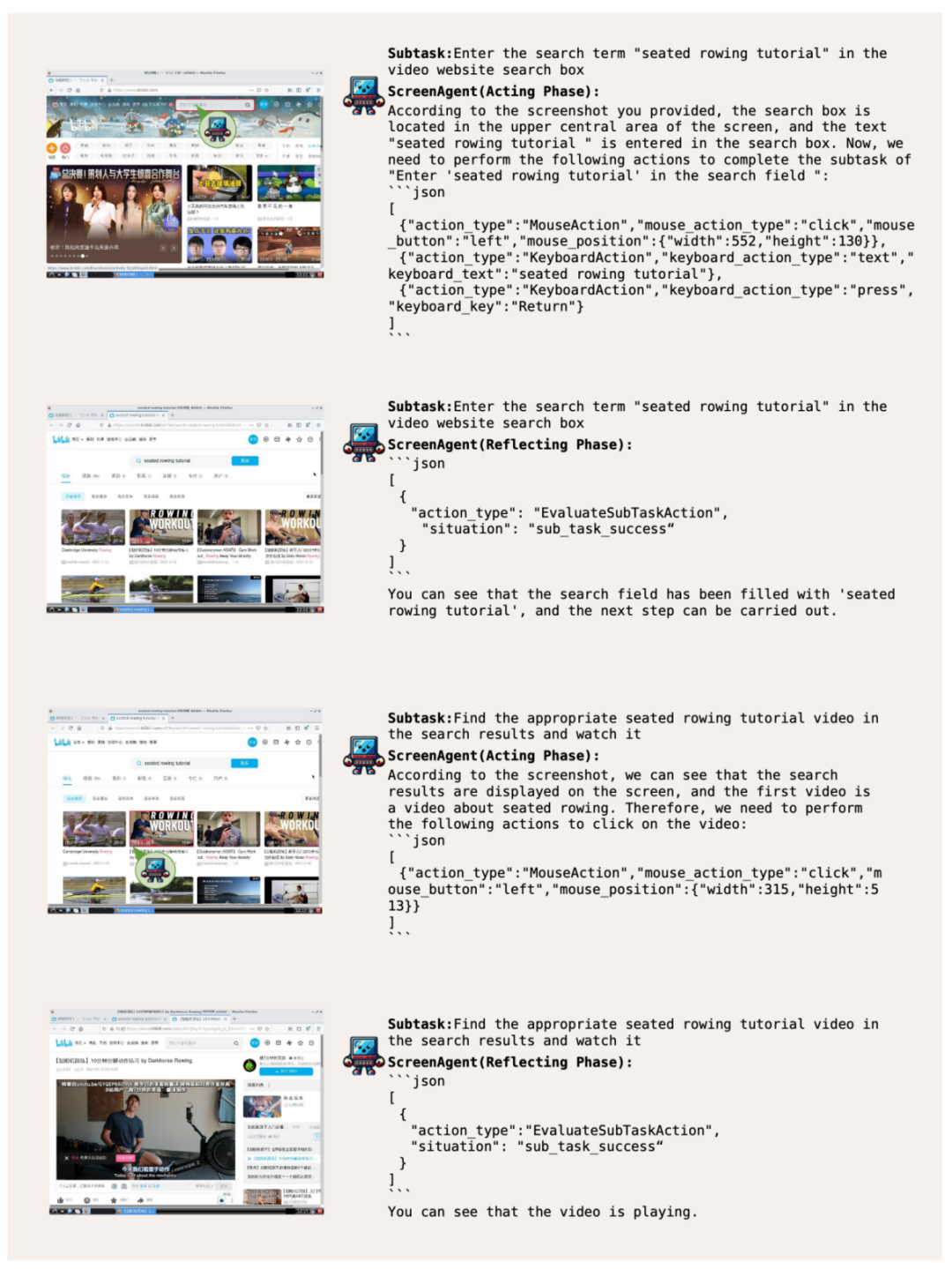
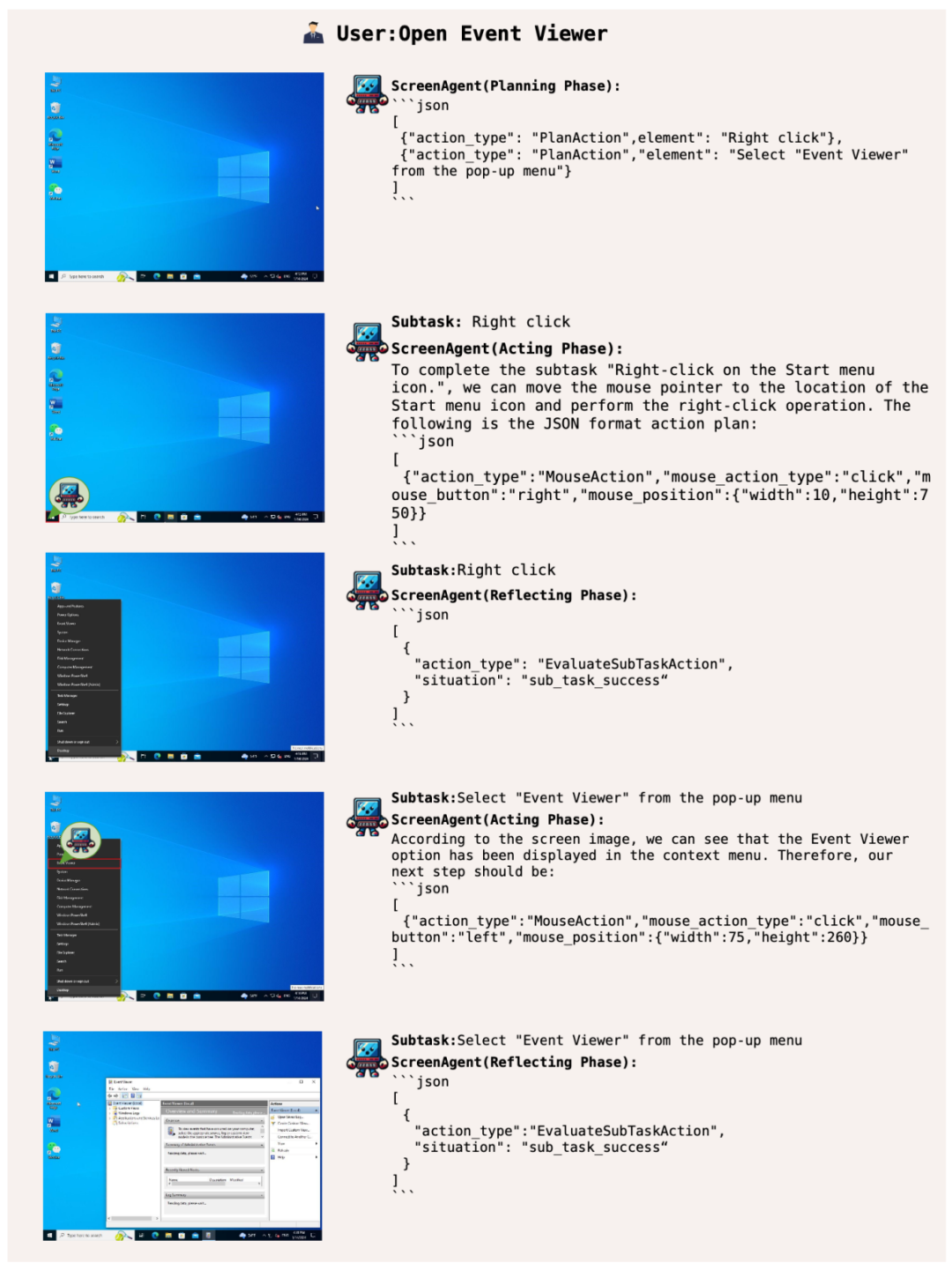
Let ScreenAgent open the Windows event viewer:
In addition, ScreenAgent can use office software. For example, according to the user text description, delete the PPT on the second page that is opened:
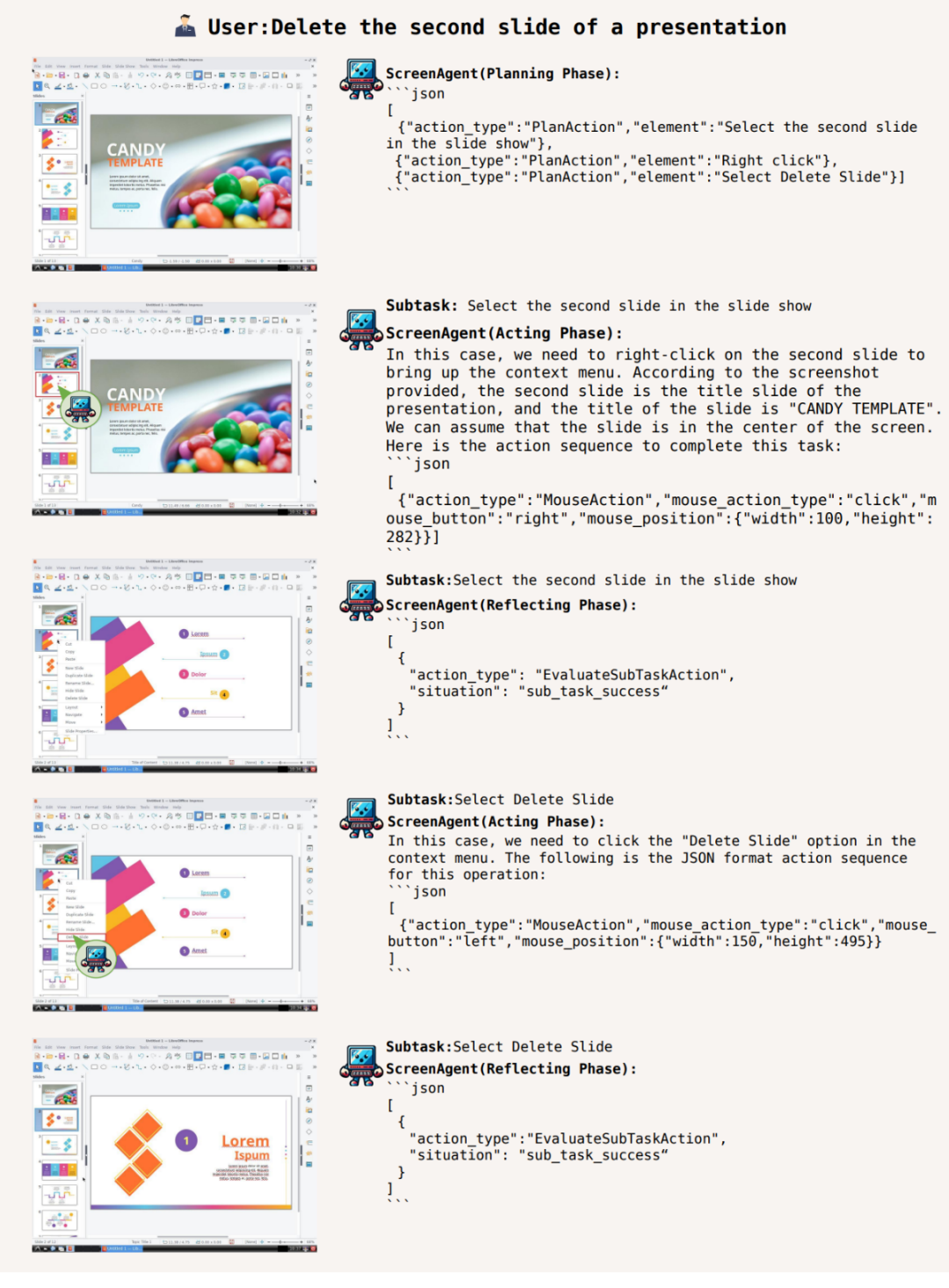
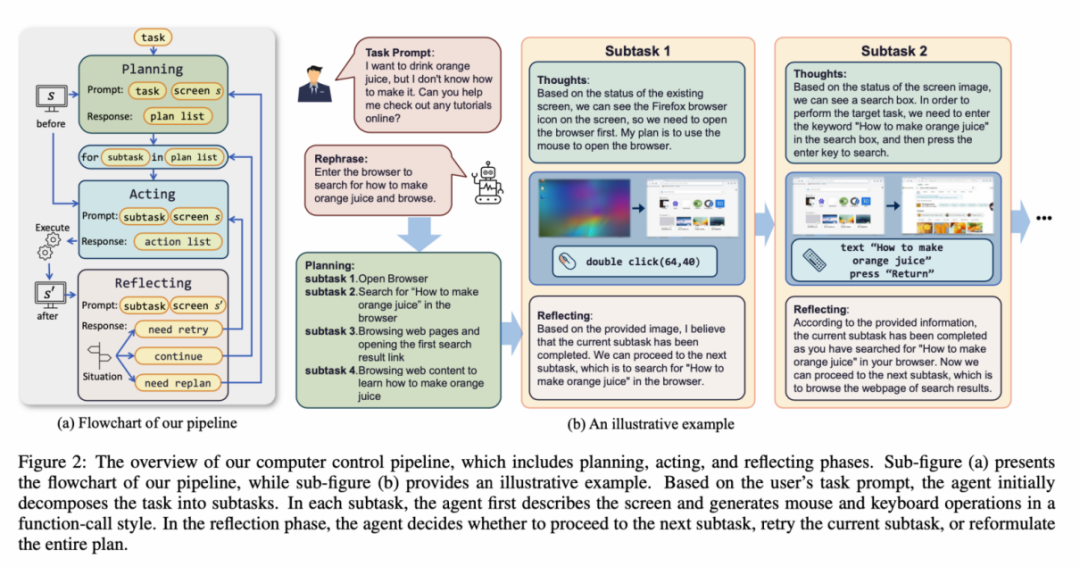
To complete a certain task, planning activities must be done before the task is executed. ScreenAgent can make plans based on the observed images and user needs before starting the task, for example:
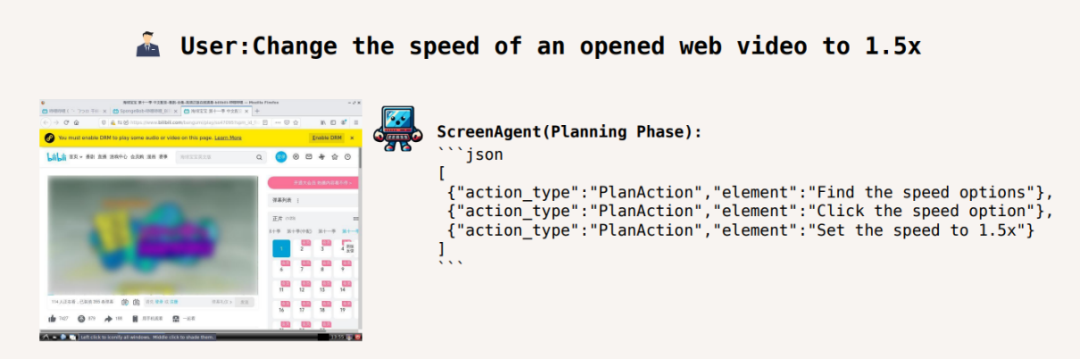
Adjust the video playback speed to 1.5 times:
 Search the price of second-hand Magotan cars on the 58 city website:
Search the price of second-hand Magotan cars on the 58 city website:
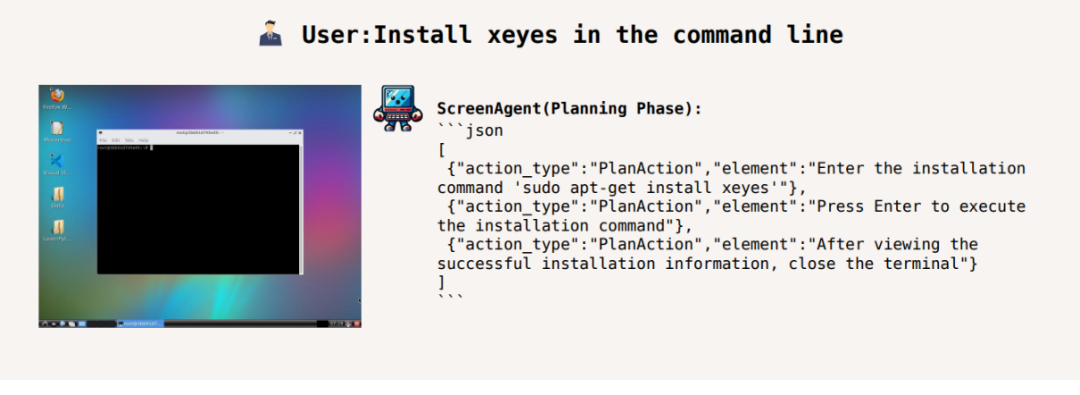
 In the command line Install xeyes:
In the command line Install xeyes:
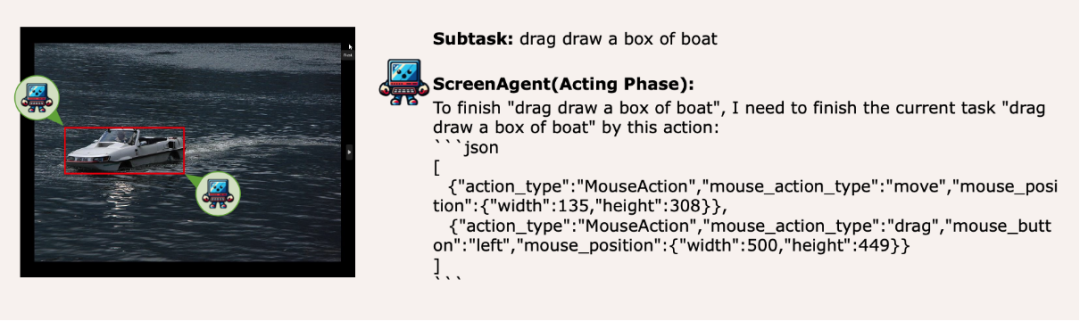
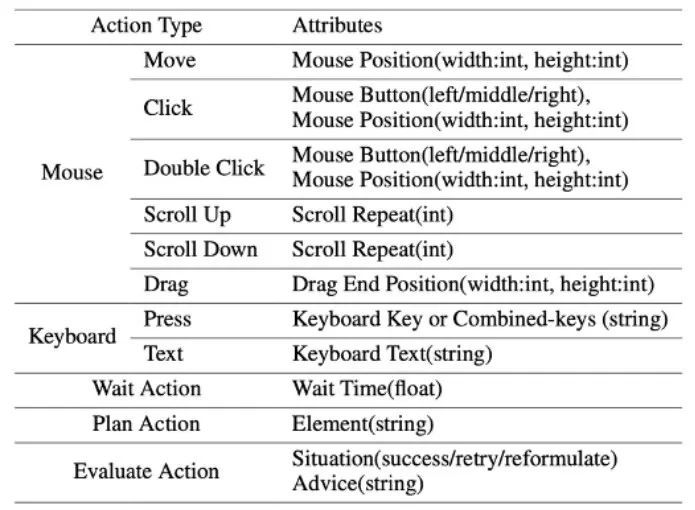
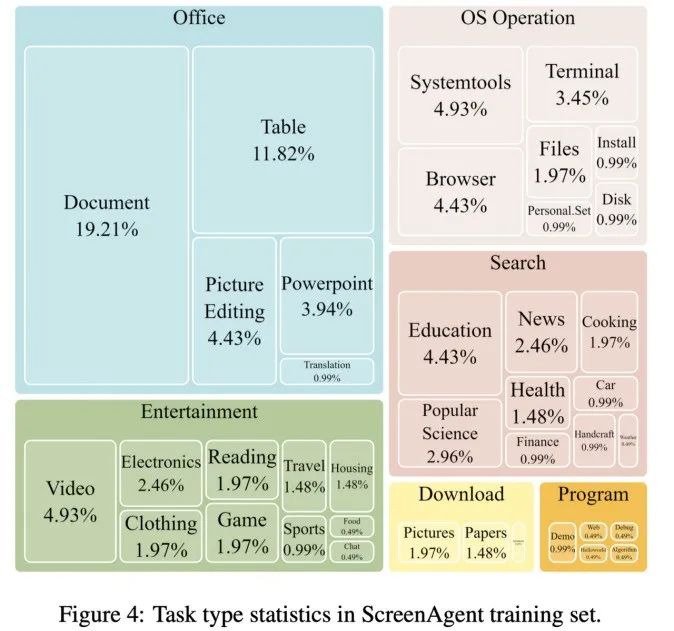
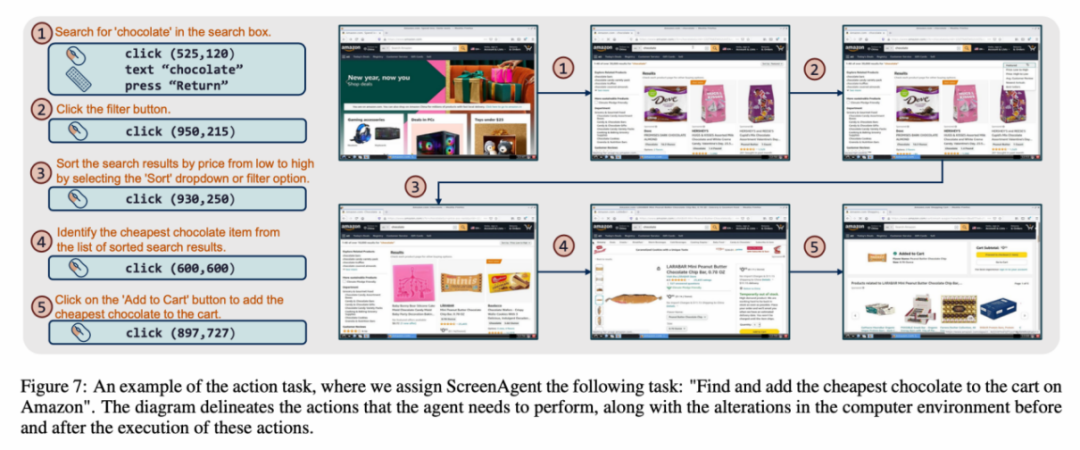
ScreenAgent also retains the ability to visually locate natural objects, and can draw a selection frame of an object by dragging the mouse: In fact, it is not a simple matter to teach the Agent to interact directly with the user graphical interface. It requires the Agent to have tasks at the same time Comprehensive abilities such as planning, image understanding, visual positioning, and tool use. There are certain compromises in existing models or interaction solutions. For example, models such as LLaVA-1.5 lack precise visual positioning capabilities on large-size images; GPT-4V has very strong mission planning, image understanding and OCR capabilities, but refuses to give Get precise coordinates. Existing solutions require manual annotation of additional digital labels on images, and allow the model to select UI elements that need to be clicked, such as Mobile-Agent, UFO and other projects; in addition, models such as CogAgent and Fuyu-8B can support high-resolution images It has input and precise visual positioning capabilities, but CogAgent lacks complete function calling capabilities, and Fuyu-8B lacks language capabilities. In order to solve the above problems, the article proposes to build a new environment for the visual language model agent (VLM Agent) to interact with the real computer screen. In this environment, the agent can observe screenshots and manipulate the graphical user interface by outputting mouse and keyboard actions. In order to guide the VLM Agent to continuously interact with the computer screen, the article constructs an operating process that includes "planning-execution-reflection". During the planning phase, the agent is asked to break down user tasks into subtasks. During the execution phase, the Agent will observe screenshots and give specific mouse and keyboard actions to perform the subtask. The controller will execute these actions and feedback the execution results to the Agent. During the reflection phase, the Agent observes the execution results, determines the current status, and chooses to continue execution, retry, or adjust the plan. This process continues until the task is completed. It is worth mentioning that ScreenAgent does not need to use any text recognition or icon recognition modules, and uses an end-to-end approach to train all the capabilities of the model. ScreenAgent environment refers to the VNC remote desktop connection protocol to design the Agent's action space, including the most basic mouse and keyboard operations, and mouse click operations. All require the Agent to give precise screen coordinates. Compared with calling specific APIs to complete tasks, this method is more general and can be applied to various desktop operating systems and applications such as Windows and Linux Desktop. In order to train the ScreenAgent model, the article is manually annotated with precise visual positioning information ScreenAgent data set. This data set covers a wide range of daily computer tasks, including file operations, web browsing, game entertainment and other scenarios in Windows and Linux Desktop environments. Each sample in the data set is a complete process for completing a task, including action descriptions, screenshots, and specific executed actions. For example, in the case of "adding the cheapest chocolate to the shopping cart" on the Amazon website, you need to first search for keywords in the search box, then use filters to sort prices, and finally add the cheapest items to the shopping cart. The entire dataset contains 273 complete task records. In the experimental analysis part, the author combined ScreenAgent with multiple existing VLM models Comparisons are made from various angles, mainly including two levels, instruction following ability and accuracy of fine-grained action prediction. The instruction following ability mainly tests whether the model can correctly output the action sequence and action type in JSON format. The accuracy of action attribute prediction compares whether the attribute value of each action is predicted correctly, such as the mouse click position, keyboard keys, etc. Instructions follow In terms of command following, the first task of the Agent is to output the correct tool function call according to the prompt word, that is, to output the correct JSON format. In this regard, both ScreenAgent and GPT-4V can follow the command very well. However, the original CogAgent lost the ability to output JSON due to the lack of data support in the form of API calls during visual fine-tuning training. The accuracy of action attribute prediction From the accuracy of action attributes In terms of performance, ScreenAgent has also reached a level comparable to GPT-4V. Notably, ScreenAgent far exceeds existing models in mouse click accuracy. This shows that visual fine-tuning effectively enhances the model's precise positioning ability. Furthermore, we also observe a clear gap between ScreenAgent and GPT-4V in mission planning, which highlights GPT-4V's common sense knowledge and mission planning capabilities. Proposed by the team of the School of Artificial Intelligence of Jilin University The ScreenAgent can control computers in the same way as humans, does not rely on other APIs or OCR models, and can be widely used in various software and operating systems. ScreenAgent can autonomously complete tasks given by the user under the control of the "plan-execution-reflection" process. In this way, users can see every step of task completion and better understand the Agent's behavioral thoughts. The article open sourced the control software, model training code, and data set. On this basis, you can explore more cutting-edge work towards general artificial intelligence, such as reinforcement learning under environmental feedback, Agent's active exploration of the open world, building world models, Agent skill libraries, etc. In addition, AI Agent-driven personal assistants have huge social value, such as helping people with limited limbs use computers, reducing human repetitive digital labor and popularizing computer education. In the future, maybe not everyone can become a superhero like Iron Man, but we may all have an exclusive Jarvis, an intelligent partner who can accompany, assist and guide us in our lives and work. Bringing more convenience and possibilities. 
Method
ScreenAgent Dataset
Experimental results
Conclusion
The above is the detailed content of You can get started with Windows and Office directly. It's so easy to operate a computer with a large model agent.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to view word documents in vscode How to view word documents in vscode
May 09, 2024 am 09:37 AM
How to view word documents in vscode How to view word documents in vscode
May 09, 2024 am 09:37 AM
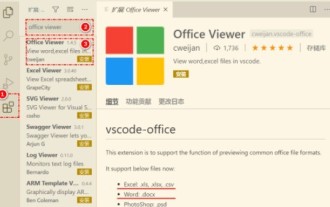
First, open the vscode software on the computer, click the [Extension] icon on the left, as shown in ① in the figure. Then, enter [officeviewer] in the search box of the extension interface, as shown in ② in the figure. Then, from the search Select [officeviewer] to install in the results, as shown in ③ in the figure. Finally, open the file, such as docx, pdf, etc., as shown below
 WPS and Office do not have Chinese fonts, and Chinese font names are displayed in English.
Jun 19, 2024 am 06:56 AM
WPS and Office do not have Chinese fonts, and Chinese font names are displayed in English.
Jun 19, 2024 am 06:56 AM
My friend's computer, all Chinese fonts such as imitation Song, Kai style, Xing Kai, Microsoft Yahei, etc. cannot be found in WPS and OFFICE. The editor below will tell you how to solve this problem. The fonts in the system are normal, but all fonts in the WPS font options are not available, only cloud fonts. OFFICE only has English fonts, not any Chinese fonts. After installing different versions of WPS, English fonts are available, but there is also no Chinese font. Solution: Control Panel → Categories → Clock, Language, and Region → Change Display Language → (Region and Language) Management → (Language for Non-Unicode Programs) Change System Regional Settings → Chinese (Simplified, China) → Restart. Control Panel, change the view mode in the upper right corner to "Category", Clock, Language and Region, change
 Xiaomi Mi Pad 6 series launches PC-level WPS Office in full quantity
Apr 25, 2024 pm 09:10 PM
Xiaomi Mi Pad 6 series launches PC-level WPS Office in full quantity
Apr 25, 2024 pm 09:10 PM
According to news from this site on April 25, Xiaomi officially announced today that Xiaomi Mi Pad 6, Mi Pad 6 Pro, Mi Pad 6 Max 14, and Mi Pad 6 S Pro now fully support PC-level WPSOffice. Among them, Xiaomi Mi Pad 6 Pro and Xiaomi Mi Pad 6 need to upgrade the system version to V816.0.4.0 and above before they can download WPSOfficePC from the Xiaomi App Store. WPSOfficePC adopts the same operation and layout as a computer, and paired with tablet keyboard accessories, it can improve office efficiency. According to the previous evaluation experience of this site, WPSOfficePC is significantly more efficient when editing documents, forms, presentations and other files. Moreover, various functions that are inconvenient to use on mobile terminals, such as text layout, picture insertion,
 3d rendering, computer configuration? What kind of computer is needed to design 3D rendering?
May 06, 2024 pm 06:25 PM
3d rendering, computer configuration? What kind of computer is needed to design 3D rendering?
May 06, 2024 pm 06:25 PM
3d rendering, computer configuration? 1 Computer configuration is very important for 3D rendering, and sufficient hardware performance is required to ensure rendering effect and speed. 23D rendering requires a lot of calculations and image processing, so it requires high-performance CPU, graphics card and memory. 3 It is recommended to configure at least one computer with at least 6 cores and 12 threads CPU, more than 16GB of memory and a high-performance graphics card to meet the higher 3D rendering needs. At the same time, you also need to pay attention to the computer's heat dissipation and power supply configuration to ensure the stable operation of the computer. What kind of computer is needed to design 3D rendering? I am also a designer, so I will give you a set of configurations (I will use it again) CPU: amd960t with 6 cores (or 1090t directly overclocked) Memory: 1333
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
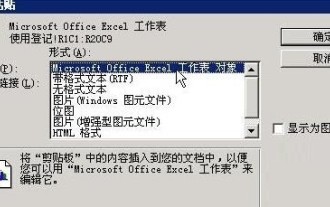 Detailed method of referencing Excel worksheet data in word documents
Apr 26, 2024 am 10:28 AM
Detailed method of referencing Excel worksheet data in word documents
Apr 26, 2024 am 10:28 AM
Method 1: When the entire table comes from an Excel worksheet, first select the data area that needs to be referenced in the word document in the Excel worksheet and perform a copy operation. Then run Word and click the [Edit] → [Paste Special] menu command to open the [Paste Special] dialog box. Select the [Microsoft Office Excel Worksheet Object] option in the [Form] list and click the [OK] button. Excel data referenced in this way can be edited using Excel. Method 2: When the data in the word document comes from a cell in the Excel worksheet, you can first copy the cell in the Excel worksheet, and then copy it in the Word document
