

I think everyone is familiar with Station B. In fact, there are a lot of search results on the crawler website of Station B. However, what I read on paper is ultimately shallow, and I definitely know that I have to do it in detail, so I am here. In the end, the total amount of data crawled was 7.6 million items.
Preparation
First open station B, find a video on the homepage and click on it. For normal operation, open the developer tools. This time, the goal is to obtain video information by crawling the API provided by Station B without parsing the web page. The speed of parsing the web page is too slow and the IP address is easily blocked.
Check the JS option and F5 to refresh
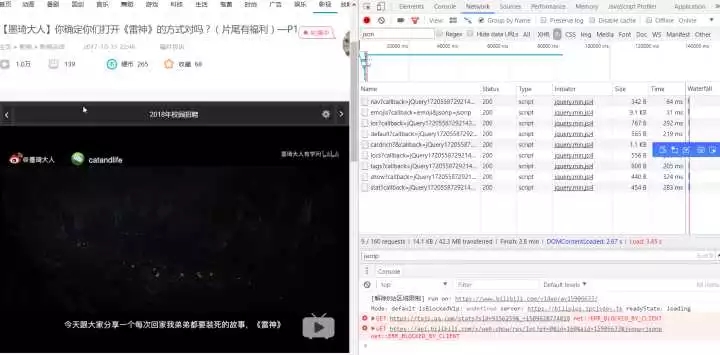
Found the api address
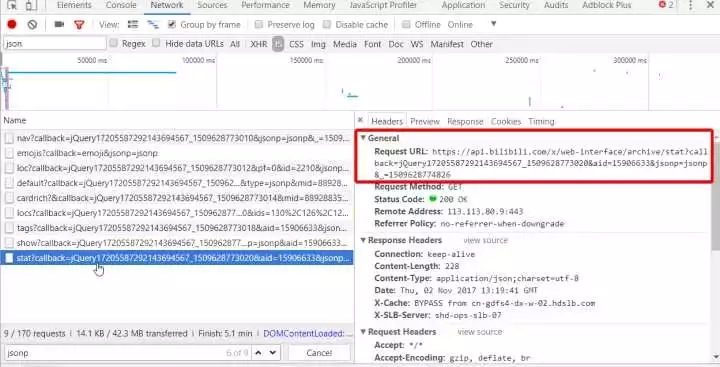
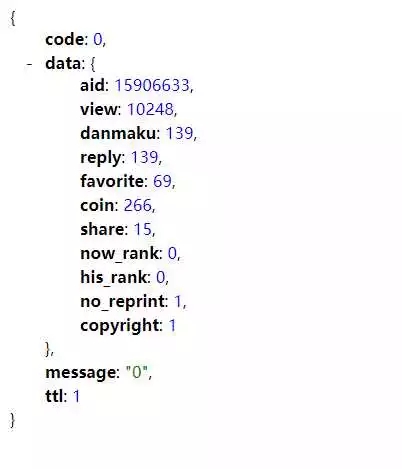
Copy it, remove unnecessary content, and get https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633 . Open it with a browser and you will get The following json data
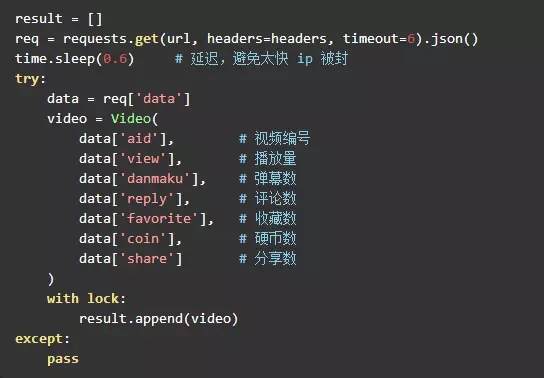
Hands-on coding
Okay, the code can be coded here. Data is obtained through continuous iteration of request. In order to make the crawler more efficient, multi-threading can be used.
Core code
Iterative crawling

The most important part of the entire project is about 20 lines of code, which is quite concise.
The running effect is roughly like this. The number is how many links have been crawled. In fact, the entire site information can be crawled in one or two days.
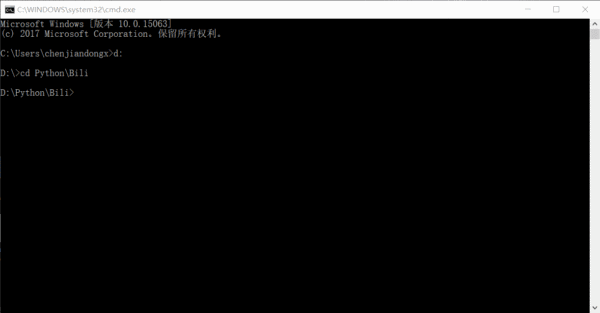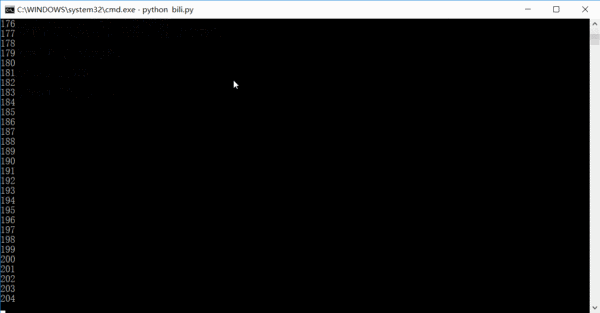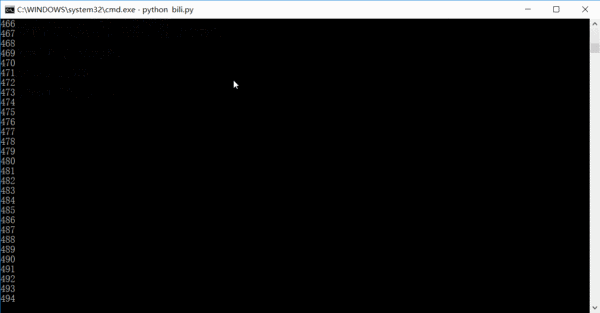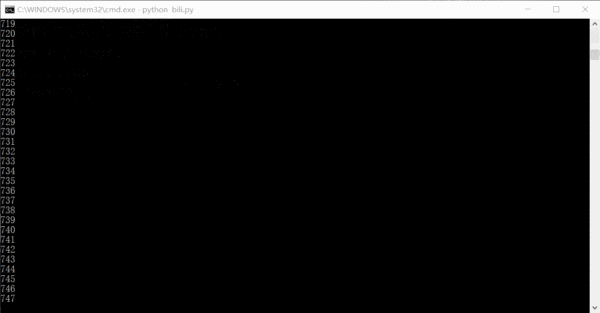
As for how to process it after crawling, it depends on your preference. I save it as a csv file first, and then summarize and insert it into the database.
Database Table
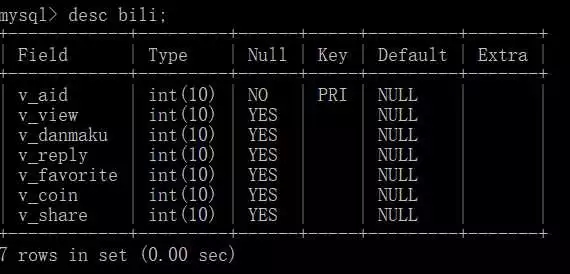
Since I crawled this content a few months ago, the data is actually lagging behind.
Total amount of data
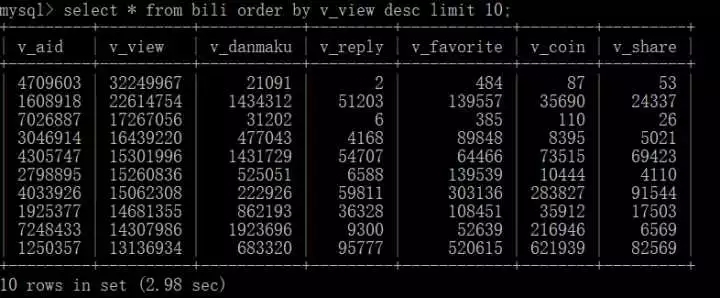
Query the top ten videos
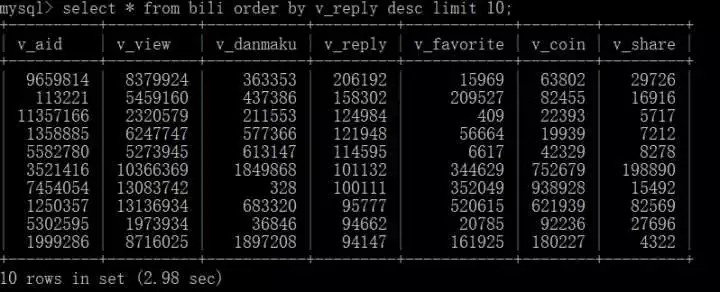
Check the top ten videos with the most replies
The above is the detailed content of Use Python to crawl the entire video information of station B. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



