
 Technology peripherals
AI
How to apply NLP large models to time series? A summary of the five categories of methods!
Technology peripherals
AI
How to apply NLP large models to time series? A summary of the five categories of methods!
How to apply NLP large models to time series? A summary of the five categories of methods!

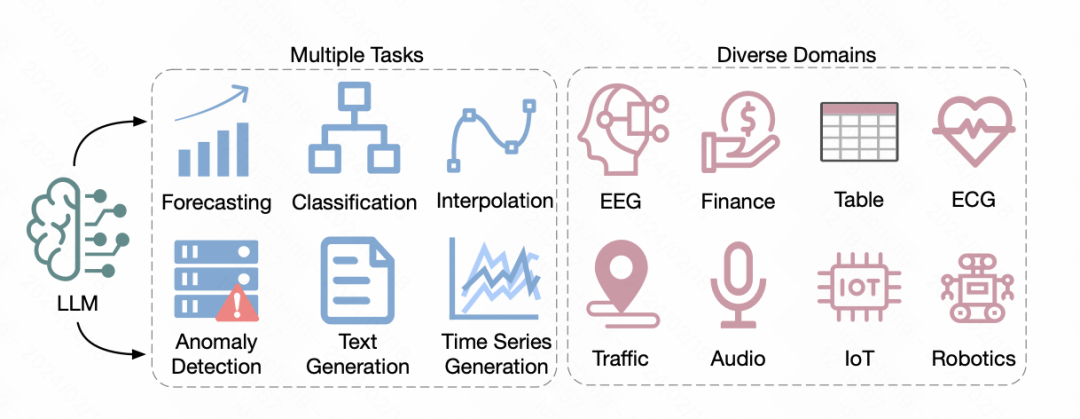
Recently, the University of California published a review article exploring methods of applying pre-trained large language models in the field of natural language processing to time series forecasting. This article summarizes the application of 5 different NLP large models in the time series field. Next, we will briefly introduce these 5 methods mentioned in this review.
 Picture
Picture
Paper title: Large Language Models for Time Series: A Survey
Download address: https://arxiv.org /pdf/2402.01801.pdf
 Picture
Picture
1. Prompt-based method
By directly using prompt method, the model can target Time series data for forecast output. In the previous prompt method, the basic idea was to pre-train a prompt text, fill it with time series data, and let the model generate prediction results. For example, when constructing text describing a time series task, fill in the time series data and let the model directly output prediction results.
 Picture
Picture
When processing time series, numbers are often regarded as part of the text, and the issue of tokenizing numbers has also attracted much attention. Some methods specifically add spaces between numbers to distinguish numbers more clearly and avoid unreasonable distinctions between numbers in dictionaries.
2. Discretization
This type of method discretizes time series and converts continuous values into discrete id results to adapt to the input form of large NLP models. For example, one approach is to map time series into discrete representations with the help of Vector Quantized-Variational AutoEncoder (VQ-VAE) technology. VQ-VAE is an autoencoder structure based on VAE. VAE maps the original input into a representation vector through the Encoder, and then restores the original data through the Decoder. VQ-VAE ensures that the intermediate generated representation vector is discretized. A dictionary is constructed based on this discretized representation vector to implement discretized mapping of time series data. Another method is based on K-means discretization, using the centroids generated by Kmeans to discretize the original time series. In addition, in some work, time series are also directly converted into text. For example, in some financial scenarios, daily price increases, price decreases and other information are directly converted into corresponding letter symbols as input to the large NLP model.
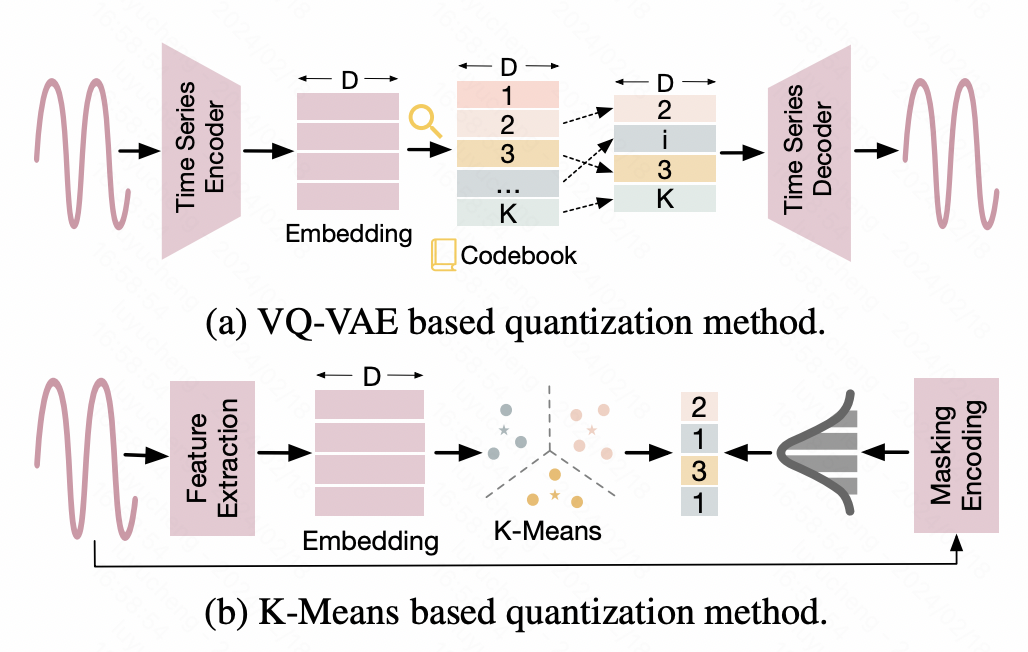 Picture
Picture
3. Time series-text alignment
This type of method relies on alignment technology in the multi-modal field to combine time The representation of the sequence is aligned to the text space, thereby achieving the goal of directly inputting time series data into the large NLP model.
In this type of method, some multi-modal alignment methods are widely used. The most typical one is multi-modal alignment based on contrastive learning. Similar to CLIP, a time series encoder and a large model are used to input the representation vectors of time series and text respectively, and then contrastive learning is used to shorten the distance between positive sample pairs. Aligning representations of time series and textual data in latent space.
Another method is finetune based on time series data, using the NLP large model as the backbone, and introducing additional network adaptation time series data on this basis. Among them, efficient cross-modal finetune methods such as LoRA are relatively common. They freeze most parameters of the backbone and finetune only a small number of parameters, or introduce a small number of adapter parameters for finetune to achieve multi-modal alignment.
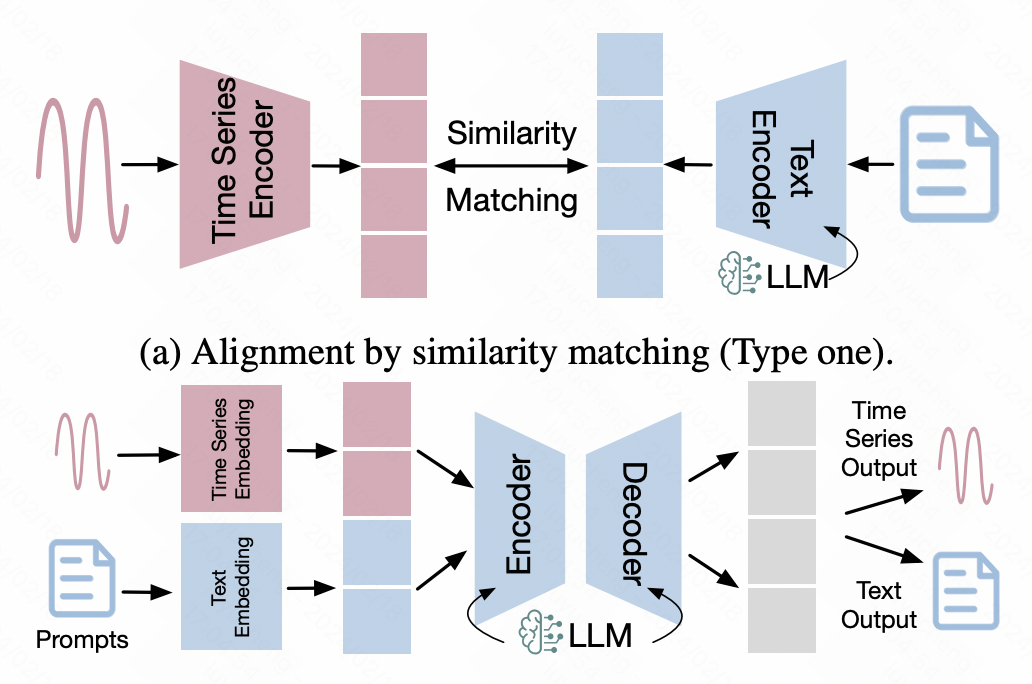 Picture
Picture
4. Introducing visual information
This method is relatively rare. It usually establishes a connection between time series and visual information. Then the multi-modal capabilities that have been studied in depth using images and text are introduced to extract effective features for downstream tasks. For example, ImageBind uniformly aligns the data of 6 modalities, including time series type data, to achieve the unification of large multi-modal models. Some models in the financial field convert stock prices into chart data, and then use CLIP to align images and texts to generate chart-related features for downstream time series tasks.
5. Large model tools
This type of method no longer improves the NLP large model, or transforms the time series data form for large model adaptation, but directly treats the NLP large model as a Tools for solving time series problems. For example, let the large model generate code to solve time series prediction and apply it to time series prediction; or let the large model call open source API to solve time series problems. Of course, this method is more biased toward practical applications.
Finally, the article summarizes the representative work and representative data sets of various methods:
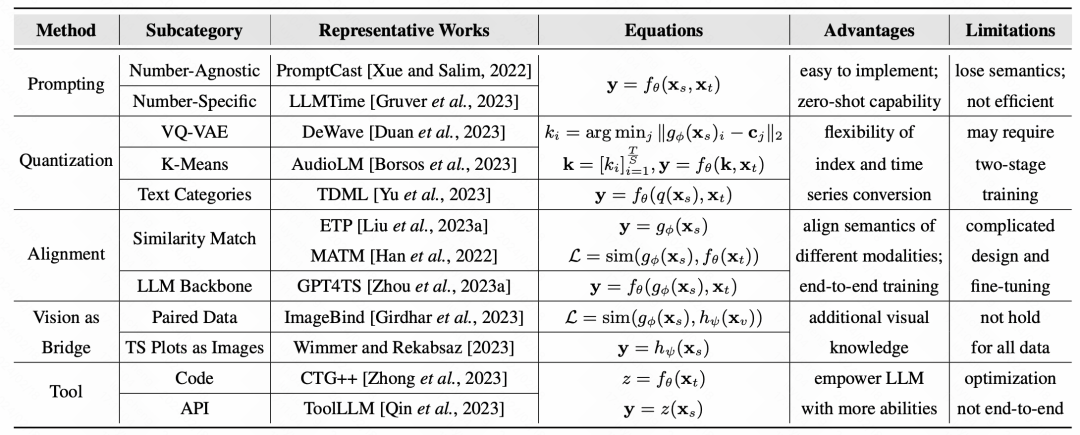 Pictures
Pictures
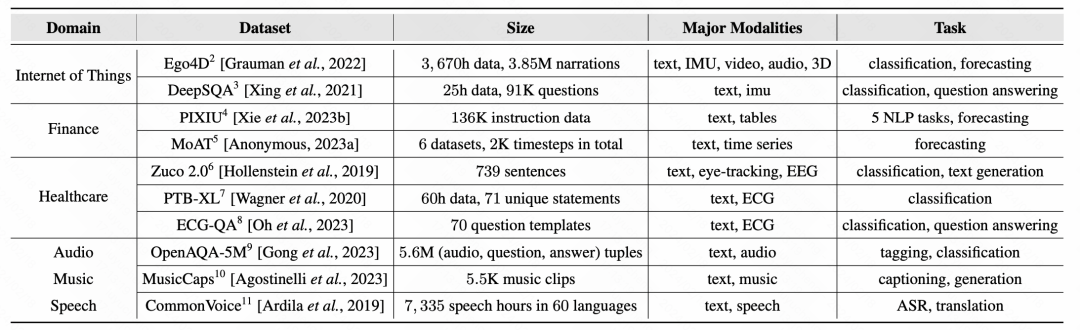 picture
picture
The above is the detailed content of How to apply NLP large models to time series? A summary of the five categories of methods!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 Time Series Forecasting NLP Large Model New Work: Automatically Generate Implicit Prompts for Time Series Forecasting
Mar 18, 2024 am 09:20 AM
Time Series Forecasting NLP Large Model New Work: Automatically Generate Implicit Prompts for Time Series Forecasting
Mar 18, 2024 am 09:20 AM
Today I would like to share a recent research work from the University of Connecticut that proposes a method to align time series data with large natural language processing (NLP) models on the latent space to improve the performance of time series forecasting. The key to this method is to use latent spatial hints (prompts) to enhance the accuracy of time series predictions. Paper title: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download address: https://arxiv.org/pdf/2403.05798v1.pdf 1. Large problem background model
 Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Product positioning of TensorRT-LLM TensorRT-LLM is a scalable inference solution developed by NVIDIA for large language models (LLM). It builds, compiles and executes calculation graphs based on the TensorRT deep learning compilation framework, and draws on the efficient Kernels implementation in FastTransformer. In addition, it utilizes NCCL for communication between devices. Developers can customize operators to meet specific needs based on technology development and demand differences, such as developing customized GEMM based on cutlass. TensorRT-LLM is NVIDIA's official inference solution, committed to providing high performance and continuously improving its practicality. TensorRT-LL
 Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
"High complexity, high fragmentation, and cross-domain" have always been the primary pain points on the road to digital and intelligent upgrading of the transportation industry. Recently, the "Qinling·Qinchuan Traffic Model" with a parameter scale of 100 billion, jointly built by China Vision, Xi'an Yanta District Government, and Xi'an Future Artificial Intelligence Computing Center, is oriented to the field of smart transportation and provides services to Xi'an and its surrounding areas. The region will create a fulcrum for smart transportation innovation. The "Qinling·Qinchuan Traffic Model" combines Xi'an's massive local traffic ecological data in open scenarios, the original advanced algorithm self-developed by China Science Vision, and the powerful computing power of Shengteng AI of Xi'an Future Artificial Intelligence Computing Center to provide road network monitoring, Smart transportation scenarios such as emergency command, maintenance management, and public travel bring about digital and intelligent changes. Traffic management has different characteristics in different cities, and the traffic on different roads
 Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
According to news on April 4, the Cyberspace Administration of China recently released a list of registered large models, and China Mobile’s “Jiutian Natural Language Interaction Large Model” was included in it, marking that China Mobile’s Jiutian AI large model can officially provide generative artificial intelligence services to the outside world. . China Mobile stated that this is the first large-scale model developed by a central enterprise to have passed both the national "Generative Artificial Intelligence Service Registration" and the "Domestic Deep Synthetic Service Algorithm Registration" dual registrations. According to reports, Jiutian’s natural language interaction large model has the characteristics of enhanced industry capabilities, security and credibility, and supports full-stack localization. It has formed various parameter versions such as 9 billion, 13.9 billion, 57 billion, and 100 billion, and can be flexibly deployed in Cloud, edge and end are different situations
 New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
If the test questions are too simple, both top students and poor students can get 90 points, and the gap cannot be widened... With the release of stronger models such as Claude3, Llama3 and even GPT-5 later, the industry is in urgent need of a more difficult and differentiated model Benchmarks. LMSYS, the organization behind the large model arena, launched the next generation benchmark, Arena-Hard, which attracted widespread attention. There is also the latest reference for the strength of the two fine-tuned versions of Llama3 instructions. Compared with MTBench, which had similar scores before, the Arena-Hard discrimination increased from 22.6% to 87.4%, which is stronger and weaker at a glance. Arena-Hard is built using real-time human data from the arena and has a consistency rate of 89.1% with human preferences.
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
