

Linux memory being eaten

This is the difference between Windows and Linux in memory management. At first glance, the Linux system eats our memory (Linux ate my ram), but in fact this is also the characteristic of its memory management.

The following is the result of using the free command to view the memory of our laboratory file server. The -m option indicates using MB as the unit:

The second line of output indicates the system memory usage:
Mem: total (total) = 3920MB,
used (used) = 1938MB,
free (free) = 1982MB,
shared (shared memory) = 0MB,
buffers = 497MB,
cached = 1235MB
Note: The first four items are relatively easy to understand. There are no suitable words to translate buffer and cache. The difference between them is:
- A buffer is something that has yet to be “written” to disk.
- A cache is something that has been “read” from the disk and stored for later use.
That is, the buffer is used to store data to be output to the disk, and the cache is the data that is read from the disk and stored in the memory for future use. They are introduced to provide IO performance.
The third line of output indicates what is obtained based on the second line -/buffers/cache:
– buffers/cache used = Mem used – buffers – cached = 1938MB – 497MB – 1235MB = 205MB
buffers/cache free = Mem free buffers cached = 1982MB 497MB 1235MB = 3714MB
The third line of output indicates the use of swap partition:
Swap:total = 4095MB
used(used)= 0MB
free(free)= 4095MB
Since the system currently has sufficient memory, the swap partition is not used.
The third line of the output results above may be more difficult to understand. Why should this line of data be shown to the user? What does the memory usage minus the system buffer/cached memory mean? The system free memory plus buffer/ What does cached memory mean?
We divide memory into three categories, with different names for its usage from the perspective of users and operating systems:
Something in the above table represents the memory of "buffers/cached" in the free command. This memory is indeed used from the perspective of the operating system, but if the user wants to use it, this memory can be recycled quickly. It is used by user programs, so this memory should be classified as idle from the user's perspective.
Go back to the results output by the free command again. The results output in the third line should be understandable. The numbers in this line represent the system memory usage from the user's perspective. Therefore, if you use the top or free command to check how much memory is left in the system, you should actually add the free memory to the buffer/cached memory. That is the actual free memory of the system.
Linux memory management has made a lot of careful designs. In addition to caching dentry (used in VFS to accelerate the conversion of file path names to inodes), it also adopts two main Cache methods: Buffer Cache and Page Cache. The purpose is In order to improve disk IO performance. Data read from a slow block device is temporarily held in memory. Even if the data is no longer needed at that time, the next time the application accesses the data, it can be read directly from memory, thus bypassing the slow speed. block devices, thus improving the overall performance of the system.
Linux will make full use of these free memories. The design idea is that if the memory is free, it is better to use it to cache more data. The next time the program accesses the data again, the speed will be faster. If the program wants to use memory and the memory in the system is When it is insufficient, instead of using the swap partition, part of the cache is quickly recycled and left for user programs to use.
Therefore, it can be seen that buffers/cached is really beneficial and harmless. The real disadvantage may give users the illusion that Linux consumes memory!
In fact, it is not the case. Linux has not eaten up your memory. As long as the swap partition has not been used and your memory is running low, you should feel lucky because Linux caches a large amount of data. Maybe you can use it next time. Benefit.
The following experiments are used to verify the above conclusion:
We read a large file one after another and compare the practices of reading twice:
1. First generate a 1G large file
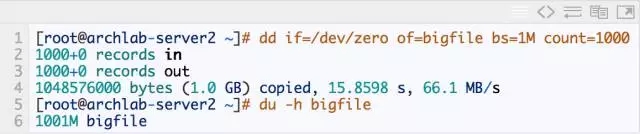
2. Clear cache

3. Read this file and test the time it takes
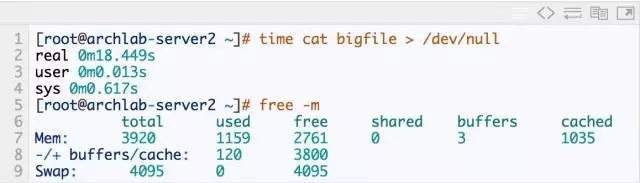
4. Read the file again and test the time it takes

As can be seen from the above, the first time reading this 1G file took about 18s, and the second time it was read again, it only took 0.3s, a full 60 times improvement!
The above is the detailed content of Linux memory being eaten. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 Linux Architecture: Unveiling the 5 Basic Components
Apr 20, 2025 am 12:04 AM
Linux Architecture: Unveiling the 5 Basic Components
Apr 20, 2025 am 12:04 AM
The five basic components of the Linux system are: 1. Kernel, 2. System library, 3. System utilities, 4. Graphical user interface, 5. Applications. The kernel manages hardware resources, the system library provides precompiled functions, system utilities are used for system management, the GUI provides visual interaction, and applications use these components to implement functions.
 vscode terminal usage tutorial
Apr 15, 2025 pm 10:09 PM
vscode terminal usage tutorial
Apr 15, 2025 pm 10:09 PM
vscode built-in terminal is a development tool that allows running commands and scripts within the editor to simplify the development process. How to use vscode terminal: Open the terminal with the shortcut key (Ctrl/Cmd). Enter a command or run the script. Use hotkeys (such as Ctrl L to clear the terminal). Change the working directory (such as the cd command). Advanced features include debug mode, automatic code snippet completion, and interactive command history.
 How to check the warehouse address of git
Apr 17, 2025 pm 01:54 PM
How to check the warehouse address of git
Apr 17, 2025 pm 01:54 PM
To view the Git repository address, perform the following steps: 1. Open the command line and navigate to the repository directory; 2. Run the "git remote -v" command; 3. View the repository name in the output and its corresponding address.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
Although Notepad cannot run Java code directly, it can be achieved by using other tools: using the command line compiler (javac) to generate a bytecode file (filename.class). Use the Java interpreter (java) to interpret bytecode, execute the code, and output the result.
 What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
The main uses of Linux include: 1. Server operating system, 2. Embedded system, 3. Desktop operating system, 4. Development and testing environment. Linux excels in these areas, providing stability, security and efficient development tools.
 How to run sublime after writing the code
Apr 16, 2025 am 08:51 AM
How to run sublime after writing the code
Apr 16, 2025 am 08:51 AM
There are six ways to run code in Sublime: through hotkeys, menus, build systems, command lines, set default build systems, and custom build commands, and run individual files/projects by right-clicking on projects/files. The build system availability depends on the installation of Sublime Text.
