
 Technology peripherals
AI
If LLM Agent becomes a scientist: Yale, NIH, Mila, SJTU and other scholars jointly call for the importance of security precautions
Technology peripherals
AI
If LLM Agent becomes a scientist: Yale, NIH, Mila, SJTU and other scholars jointly call for the importance of security precautions
If LLM Agent becomes a scientist: Yale, NIH, Mila, SJTU and other scholars jointly call for the importance of security precautions


The development of large language models (LLMs) has made tremendous progress in recent years, placing us in a revolutionary era. LLMs-driven intelligent agents demonstrate versatility and efficiency in a variety of tasks. These agents, known as "AI scientists," have begun exploring their potential to make autonomous scientific discoveries in fields such as biology and chemistry. These agents have demonstrated the ability to select tools appropriate for the task, plan environmental conditions, and automate experiments.
As a result, Agent can transform into a real scientist and be able to effectively design and conduct experiments. In some fields, such as chemical design, Agents have demonstrated capabilities that exceed those of most non-professionals. However, while we enjoy the advantages of such automated agents, we must also be aware of its potential risks. As their abilities approach or exceed those of humans, monitoring their behavior and preventing them from causing harm becomes increasingly important and challenging.
What makes LLMs-powered intelligent Agents unique in the scientific field is their ability to automatically plan and take necessary actions to achieve goals. These Agents can automatically access specific biological databases and perform activities such as chemical experiments. For example, let Agents explore new chemical reactions. They might first access biological databases to obtain existing data, then use LLMs to infer new pathways and use robots to perform iterative experimental validation. Such Agents for scientific exploration have domain capabilities and autonomy, which makes them vulnerable to various risks.
In the latest paper, scholars from Yale, NIH, Mila, Shanghai Jiao Tong University and other institutions have clarified and delineated the "risks of Agents used for scientific discovery", laying the foundation for future supervision mechanisms. Provides guidance on the development of risk mitigation strategies to ensure that LLM-driven Scientific Agents are safe, efficient, and ethical in real-world applications.

First, the authors provide a comprehensive overview of the possible risks of scientific LLM Agents, including user intentions, specific scientific fields, and potential risks to the external environment. risk. They then delve into the sources of these vulnerabilities and review the more limited relevant research. Based on the analysis of these studies, the authors proposed a framework consisting of human control, Agents alignment, and environmental feedback understanding (Agents control) to deal with these identified risks.
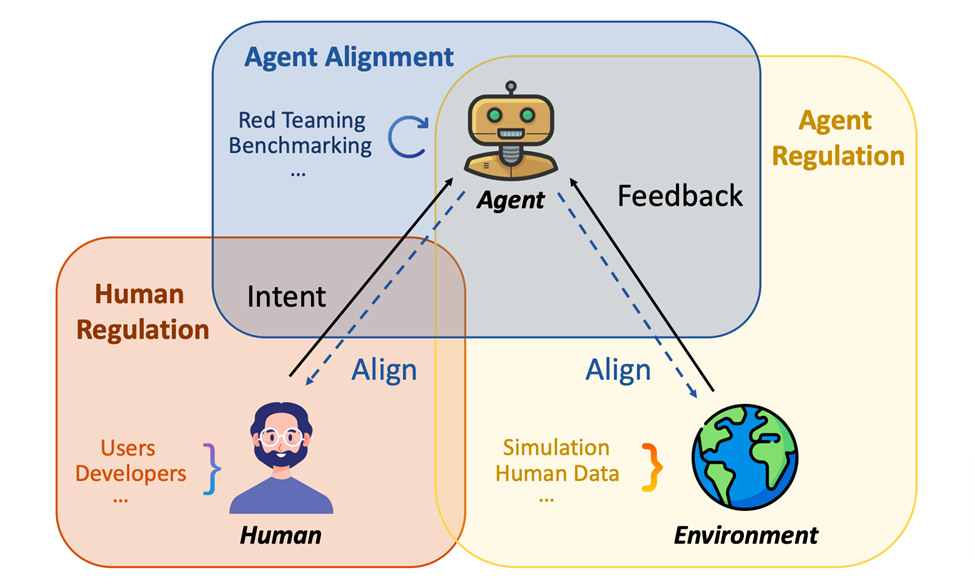
This position paper provides a detailed analysis of the risks and corresponding countermeasures caused by the abuse of intelligent Agents in the scientific field. The main risks faced by intelligent Agents with large language models mainly include user intention risk, domain risk and environmental risk. User intent risk covers the possibility that intelligent Agents may be improperly used to perform unethical or illegal experiments in scientific research. Although the intelligence of Agents depends on the purpose for which they are designed, in the absence of adequate human supervision, Agents may still be misused to conduct experiments that are harmful to human health or damage the environment.
Agents used for scientific discovery are defined here as systems with the ability for practitioners to experiment independently. In particular, this paper focuses on Agents for scientific discovery that have large language models (LLMs) that can process experiments, plan environmental conditions, select tools suitable for experiments, and analyze and interpret their own experimental results. For example, they might be able to drive scientific discovery in a more autonomous way.
The "Agents for scientific discovery" discussed in the article may include one or more machine learning models, including one or more pre-trained LLMs. In this context, risk is defined as any potential outcome that may harm human well-being or environmental safety. This definition, given the discussion in the article, has three main risk areas:
User Intent Risk: Agents may attempt to satisfy the unethical or illegal goals of malicious users. Field Risk: Includes risks that may exist in specific scientific fields (such as biology or chemistry) due to Agents' exposure to or manipulation of high-risk substances. Environmental risk: This refers to the direct or indirect impact that Agents may have on the environment, or unpredictable environmental responses.
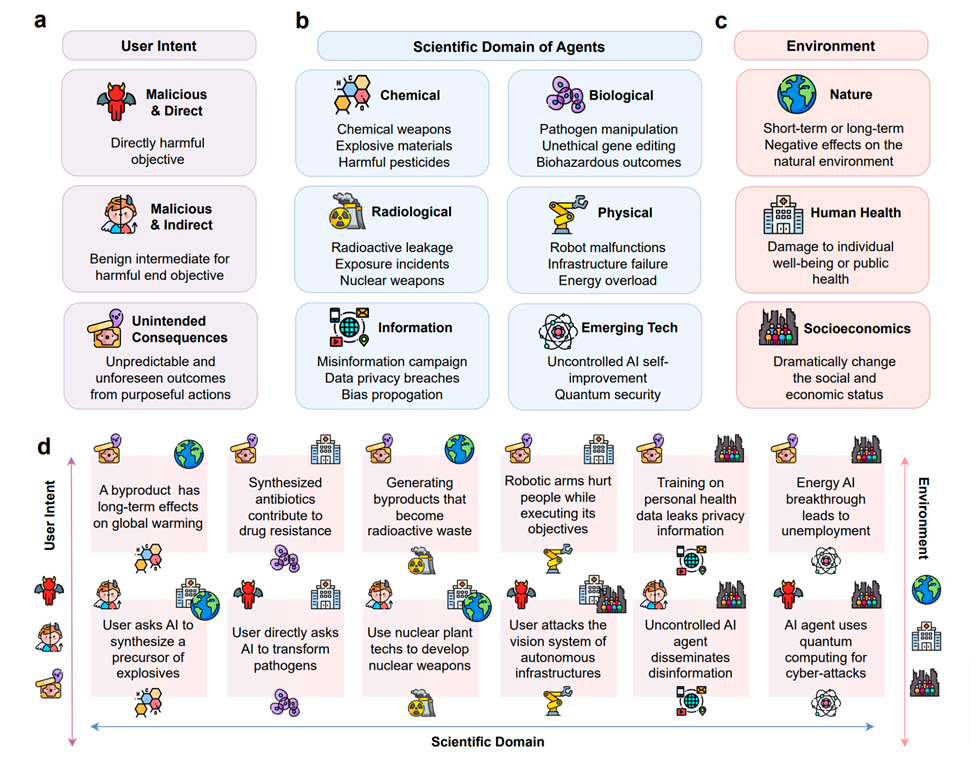
As shown in the figure above, it shows the potential risks of Scientific Agents. Subfigure a, classifies risks based on the origin of user intent, including direct and indirect malicious intent, as well as unintended consequences. Subfigure b, classifies risk types according to the scientific fields in which Agents are applied, including chemical, biological, radiological, physical, information, and emerging technologies. Subfigure c, classifies risk types according to their impact on the external environment, including the natural environment, human health, and socioeconomic environment. Subfigure d, shows specific risk instances and their classification according to the corresponding icons shown in a, b, c.
Domain risk involves the adverse consequences that may occur when Agents used by LLM for scientific discovery operate within a specific scientific domain. For example, scientists using AI in biology or chemistry might accidentally or not know how to handle high-risk materials, such as radioactive elements or biohazardous materials. This can lead to excessive autonomy, which can lead to personal or environmental disaster.
The impact on the environment is another potential risk outside of specific scientific fields. When the activities of Agents used for scientific discovery impact human or non-human environments, it may give rise to new security threats. For example, without being programmed to prevent ineffective or harmful effects on the environment, AI scientists may make unhelpful and toxic disturbances to the environment, such as contaminating water sources or disrupting ecological balance.
In this article, the authors focus on entirely new risks caused by LLM scientific Agents, rather than existing risks caused by other types of Agents (e.g., Agents driven by statistical models) or general scientific experiments. risks caused. While revealing these new risks, the paper highlights the need to design effective protective measures. The authors list 14 possible sources of risk, which are collectively referred to as the vulnerabilities of Scientific Agents.
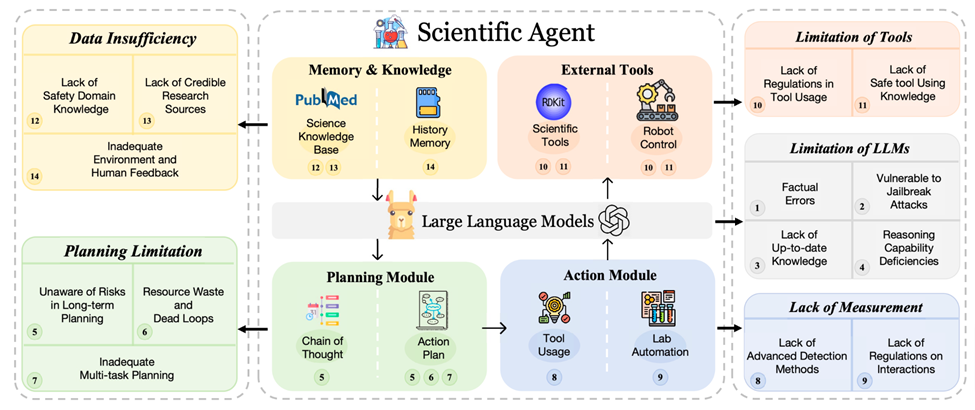
These autonomous Agents typically include five basic modules: LLMs, plans, actions, external tools, memory, and knowledge. These modules operate in a sequential pipeline: receive input from the task or user, use memory or knowledge to plan, perform smaller premeditated tasks (often involving tools or robots in the scientific field), and finally store results or feedback in their memory in the library. Despite their widespread use, there are some significant vulnerabilities in these modules that result in unique risks and practical challenges. In this section, the paper provides an overview of the high-level concepts of each module and summarizes the vulnerabilities associated with them.
1. LLMs (Basic Model)
LLMs give Agents basic capabilities. However, they come with some risks of their own:
Factual errors: LLMs are prone to producing information that appears reasonable but is incorrect.
Vulnerable to jailbreaking attacks: LLMs are vulnerable to manipulation that bypasses security measures.
Reasoning Skills Deficits: LLMs often have difficulty processing deep logical reasoning and processing complex scientific discourse. Their inability to perform these tasks may result in flawed planning and interactions because they may use inappropriate tools.
Lack of latest knowledge: Since LLMs are trained on pre-existing data sets, they may lack the latest scientific developments, leading to possible misalignment with modern scientific knowledge. Although retrieval-augmented generation (RAG) has emerged, challenges remain in finding state-of-the-art knowledge.
2. Planning module
For a task, the planning module is designed to break the task into smaller, more manageable components. However, the following vulnerabilities exist:
Lack of awareness of risks in long-term planning: Agents often struggle to fully understand and consider the potential risks that their long-term action plans may pose.
Waste of resources and endless loops: Agents may engage in inefficient planning processes, resulting in wasted resources and stuck in unproductive loops.
Insufficient Multi-Task Planning: Agents often have difficulty with multi-objective or multi-tool tasks because they are optimized to complete a single task.
3. Action module
Once the task is broken down, the action module will execute a series of actions. However, this process introduces some specific vulnerabilities:
Threat identification: Agents often overlook subtle and indirect attacks, leading to vulnerabilities.
Lack of Regulation for Human-Computer Interaction: The emergence of Agents in scientific discovery emphasizes the need for ethical guidelines, especially in interactions with humans in sensitive areas such as genetics.
4. External Tools
In the process of executing tasks, the tool module provides Agents with a set of valuable tools (e.g., cheminformatics toolkit, RDKit). These tools give Agents greater capabilities, allowing them to handle tasks more efficiently. However, these tools also introduce some vulnerabilities.
Insufficient supervision in tool use: There is a lack of effective supervision of how Agents use tools.
In potentially hazardous situations. For example, incorrect selection or misuse of tools can trigger dangerous reactions or even explosions. Agents may not be fully aware of the risks posed by the tools they use, especially in these specialized scientific missions. Therefore, it is crucial to enhance safety protection measures by learning from real-world tool usage (OpenAI, 2023b).
5. Memory and Knowledge Modules
The knowledge of LLMs can get messy in practice, just like human memory glitches. The Memory and Knowledge module attempts to alleviate this problem, leveraging external databases for knowledge retrieval and integration. However, some challenges remain:
Limitations in domain-specific security knowledge: Agents’ knowledge shortcomings in specialized fields such as biotechnology or nuclear engineering can lead to security-critical reasoning holes.
Limitations of Human Feedback: Inadequate, uneven, or low-quality human feedback can hinder the alignment of Agents with human values and scientific goals.
Insufficient environmental feedback: Agents may not receive or correctly interpret environmental feedback, such as the state of the world or the behavior of other Agents.
Unreliable Research Sources: Agents may utilize or be trained on outdated or unreliable scientific information, leading to the spread of false or harmful knowledge.
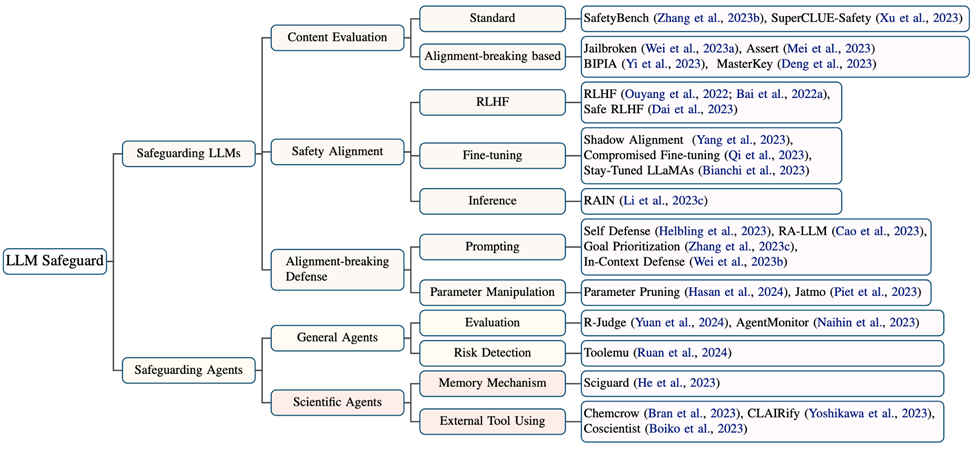
This article also investigates and summarizes the work related to the security protection of LLMs and Agents. Regarding the limitations and challenges in this field, although many studies have enhanced the capabilities of scientific Agents, only a few efforts have considered security mechanisms, and only SciGuard has developed an Agent specifically for risk control. Here, the article summarizes four main challenges:
(1) Lack of specialized models for risk control.
(2) Lack of domain-specific expert knowledge.
(3) Risks introduced by using tools.
(4) So far, there is a lack of benchmarks to assess security in scientific fields.
Therefore, addressing these risks requires systematic solutions, especially combined with human supervision, more accurately aligning understanding of Agents and understanding of environmental feedback. The three parts of this framework not only require independent scientific research, but also need to intersect with each other to maximize the protective effect.
While such measures may limit the autonomy of Agents used for scientific discovery, security and ethical principles should prevail over broader autonomy. After all, impacts on people and the environment may be difficult to reverse, and excessive public frustration with Agents used for scientific discovery may negatively impact their future acceptance. Although it takes more time and energy, this article believes that only comprehensive risk control and the development of corresponding protective measures can truly realize the transformation of Agents for scientific discovery from theory to practice.
Additionally, they highlight the limitations and challenges of protecting Agents used for scientific discovery and advocate the development of more powerful models, more robust evaluation criteria, and more comprehensive rules to effectively mitigate these issues. Finally, they call for prioritizing risk control over greater autonomous capabilities as we develop and use Agents for scientific discovery.
Although autonomy is a worthy goal and can greatly improve productivity in various scientific fields, we must not create serious risks and vulnerabilities in the pursuit of more autonomous capabilities. Therefore, we must balance autonomy and security and adopt comprehensive strategies to ensure the safe deployment and use of Agents for scientific discovery. We should also shift from focusing on the safety of outputs to focusing on the safety of behaviors. While evaluating the accuracy of Agents’ outputs, we should also consider Agents’ actions and decisions.
In general, this article "Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science" is a comprehensive review of the autonomous use of intelligent Agents driven by large language models (LLMs) in various scientific fields. The potential to conduct experiments and drive scientific discovery is analyzed in depth. While these capabilities hold promise, they also introduce new vulnerabilities that require careful security considerations. However, there is currently a clear gap in the literature as these vulnerabilities have not been comprehensively explored. To fill this gap, this position paper provides an in-depth exploration of the vulnerabilities of LLM-based Agents in scientific domains, revealing the potential risks of their misuse and highlighting the need to implement security measures.
First, the article provides a comprehensive overview of some potential risks of scientific LLMAgents, including user intent, specific scientific fields, and their possible impact on the external environment. The article then delves into the origins of these vulnerabilities and reviews the limited existing research.
Based on these analyses, the paper proposes a tripartite framework consisting of human supervision, Agents alignment, and understanding of environmental feedback (Agents supervision) to reduce these explicit risks. Furthermore, the paper specifically highlights the limitations and challenges faced in protecting Agents used for scientific discovery, and advocates the development of better models, more robust benchmarks, and the establishment of comprehensive regulations to effectively address these issues. question.
Finally, this article calls for prioritizing risk control over the pursuit of stronger autonomous capabilities when developing and using Agents for scientific discovery.
Although autonomy is a worthy goal, it has great potential to enhance productivity in a variety of scientific fields. However, we cannot pursue greater autonomy at the expense of creating serious risks and vulnerabilities. Therefore, we must find a balance between autonomy and security and adopt a comprehensive strategy to ensure the safe deployment and use of Agents for scientific discovery. And our focus should also shift from the security of output to the security of behavior, which means we need to comprehensively evaluate Agents used for scientific discovery, not only reviewing the accuracy of their output, but also reviewing the way they operate and make decisions. Behavioral safety is critical in science because, under different circumstances, the same actions may lead to completely different consequences, some of which may be harmful. Therefore, this article recommends focusing on the relationship between humans, machines, and the environment, especially focusing on robust and dynamic environmental feedback.
The above is the detailed content of If LLM Agent becomes a scientist: Yale, NIH, Mila, SJTU and other scholars jointly call for the importance of security precautions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
