

10 pictures to help you gain insight into the current situation of the LRT track

Author: Crypto Koryo
Compiled by: Frank, Foresight News
The TVL of Liquidity Recollateralized Token (LRT) has reached $3.6 billion, which is undoubtedly the most promising in 2024 one of the narratives.
So, what exactly are the re-staking addresses doing? How do they allocate funds? Where Farming? Which LRT protocols are most commonly used?
In order to solve these problems, this article will use 10 exclusive charts to introduce and analyze the behavior of re-pledged addresses from a comprehensive perspective (Note: All data comes from the "LRT whales" dashboard on Dune) .
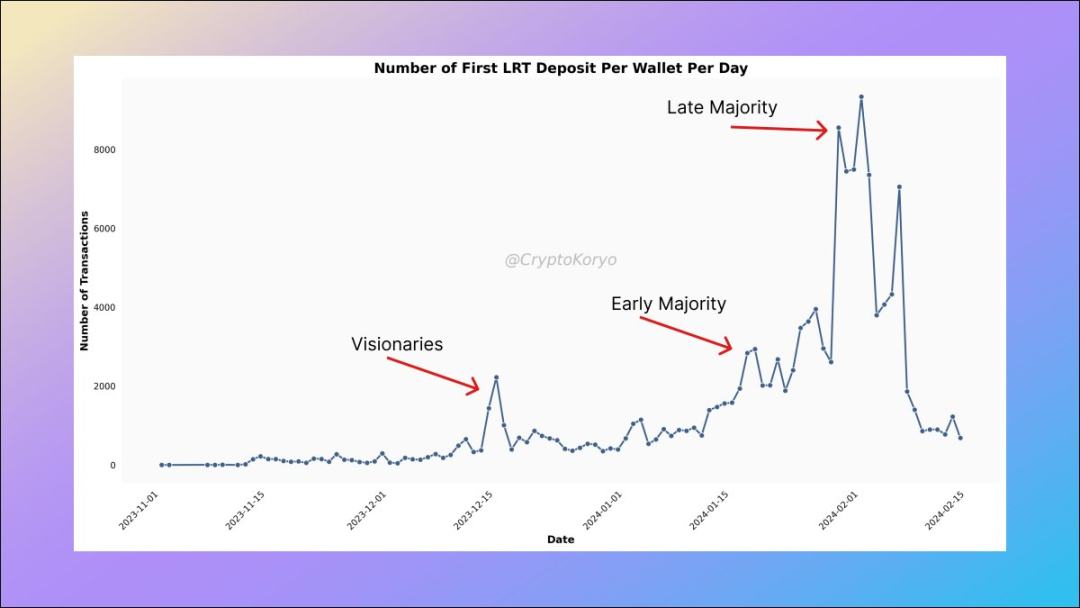
1. First deposit address category of LRT protocol
View the LRT deposit addresses in all related protocols, as well as their first LRT deposit, We will find a clear trend, that is, there are three main groups among them.
- Visionaries - December 2023;
- Early Majority - late January 2024;
- Late Majority - Early January 2024;
BTW, this is a very common pattern that can be seen early in the development of many protocols/narratives .
2. Total number of LRT deposit addresses and deposit strategy
So far, about 140,000 wallet addresses have deposited funds into the LRT protocol.
How many protocols do they deposit, and how much do they deposit on average (median)? The vast majority of people have made deposits in more than 1 protocol, and the deposit amount is less than 1 ETH.
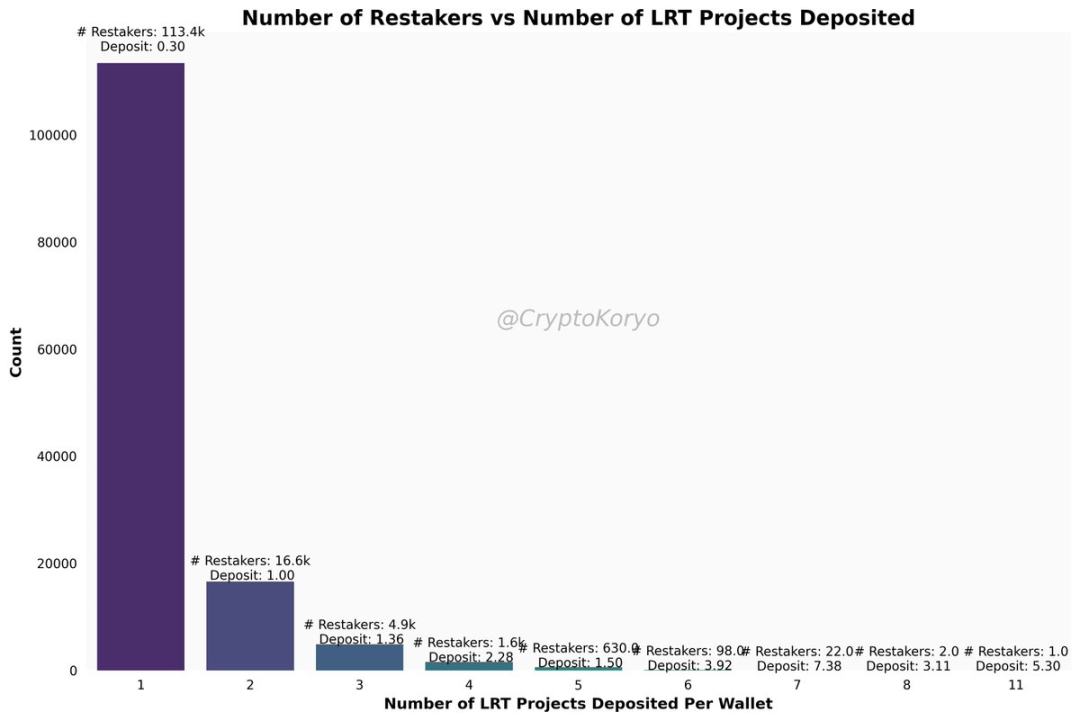
Some ambushing airdrop farmers are depositing as much as they can into the LRT protocol - although this is only a minority and not the most popular farming strategy.
Among them, a certain address starting with 0xd6d3 has been deposited in all 11 LRT protocols.
3. Deposit amount of re-pledge address
How much money is deposited in the re-pledge address?
If we exclude the top 5% of whales by deposit amount, we will find that the vast majority of wallet addresses have deposit amounts of less than 2 ETH - these wallets are ambushing EigenLayer related airdrops and maximizing their promotion number of points.
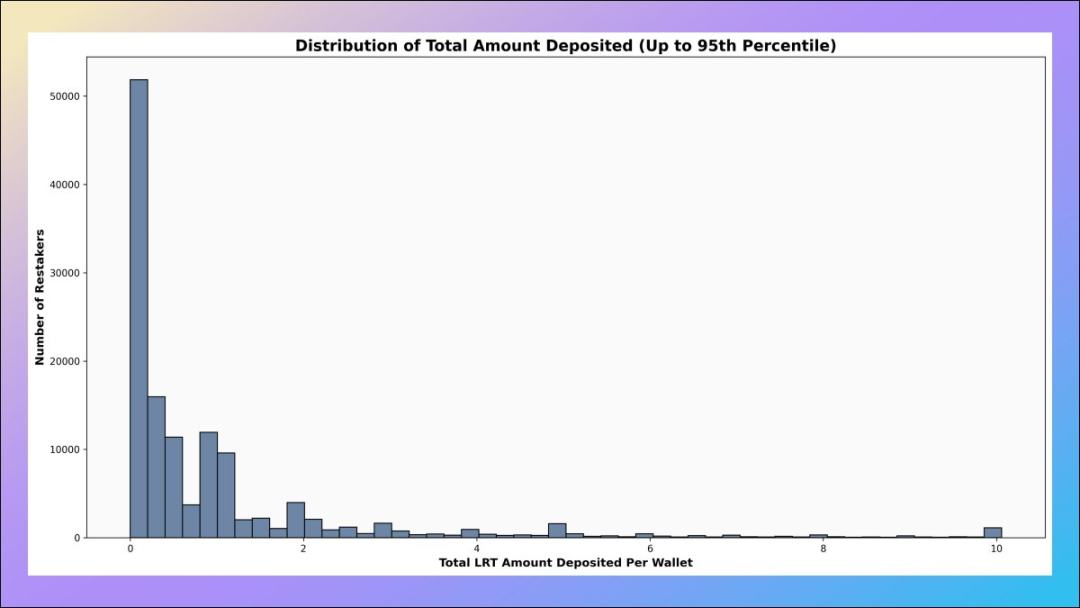
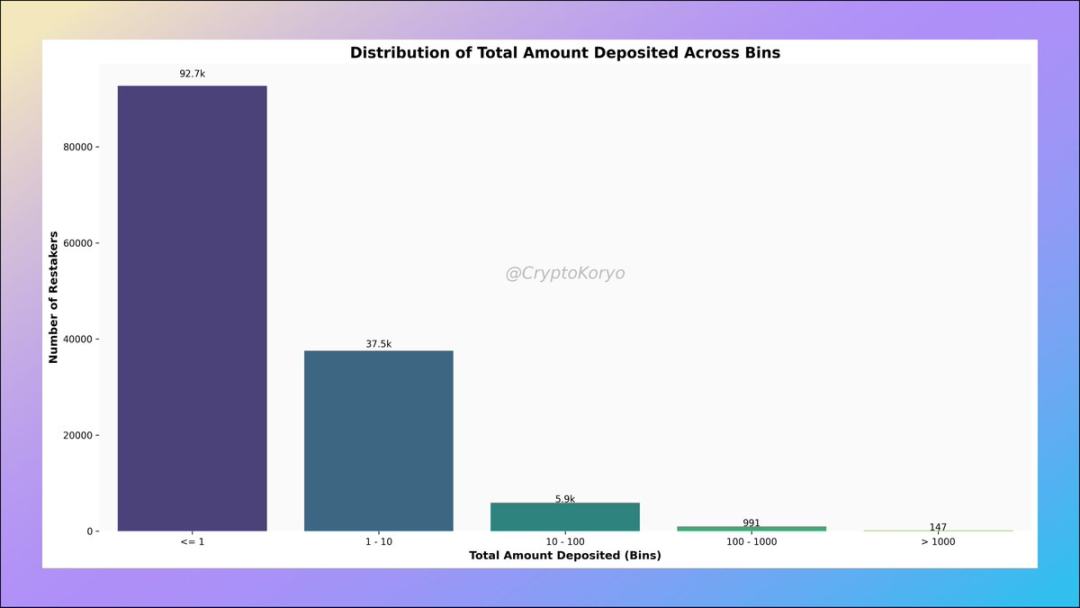
4. Number of addresses in each deposit amount range
Among them, there are 147 wallet addresses that have deposited more than 1,000 ETH into the LRT protocol. Some of these are wallets associated with individual protocols, and there are addresses like analytico.eth that split funds into multiple LRT protocols.
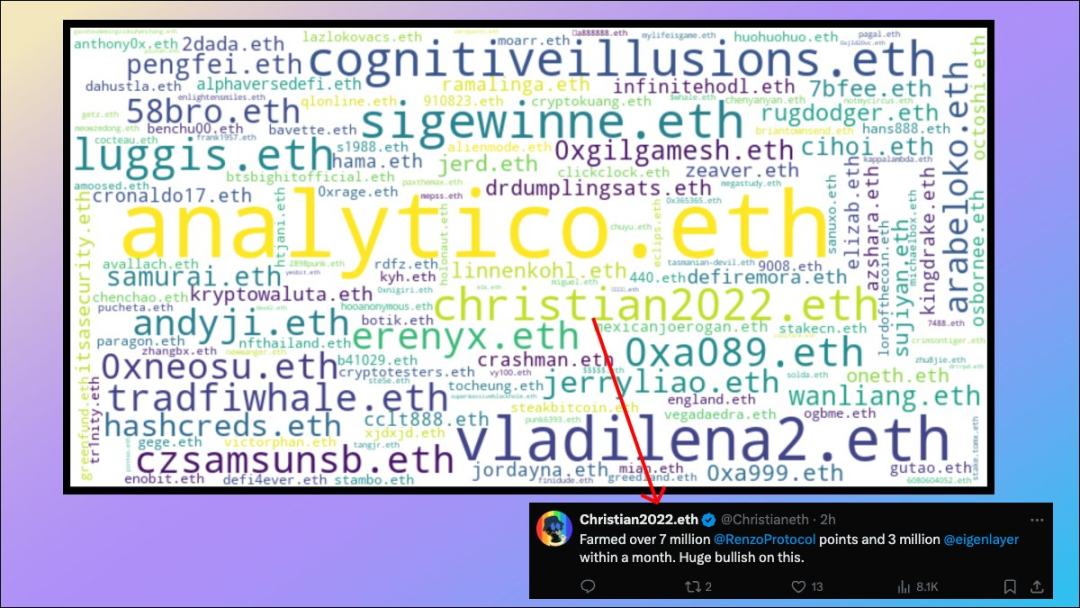
5. ENS word cloud of re-staking address
If you pay attention to the LRT narrative, you should be familiar with the ENS names of some of the LRT whales (size and Proportional to the total deposit amount):
- analytico.eth
- vladilena2.eth
- Christian2022
- luggis.eth
- czsamsunsb.eth
- 58bro.eth
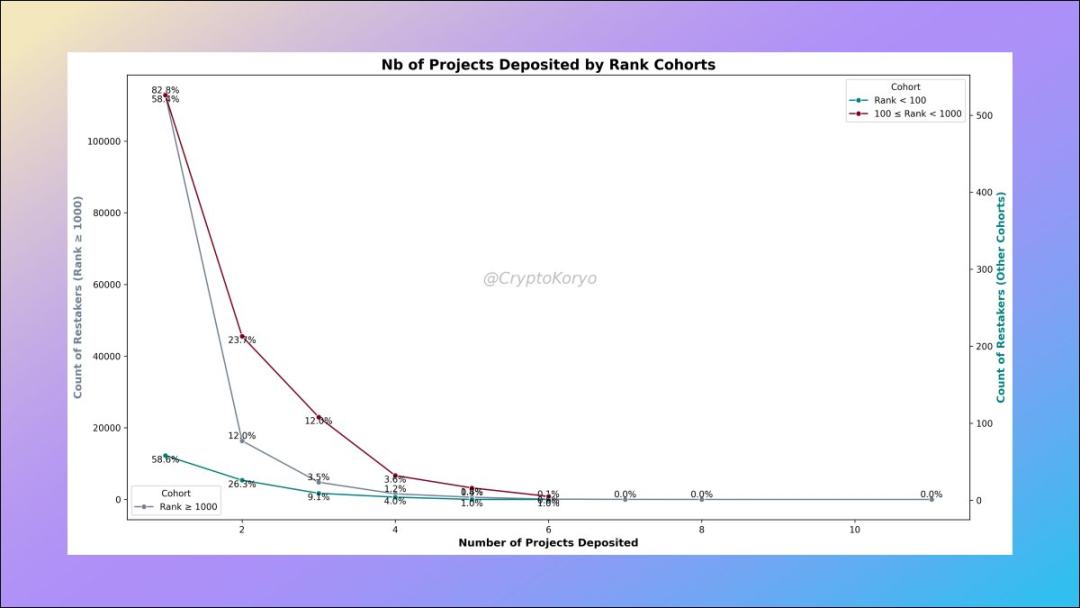
6. Research on addresses ranked by deposit amount
We can rank the addresses according to the total deposit amount Rank the LRT deposit addresses and then define different groups based on the rankings.
We observe that wallet addresses ranked >1000 generally deposit into more protocols, while 94% of wallet addresses ranked
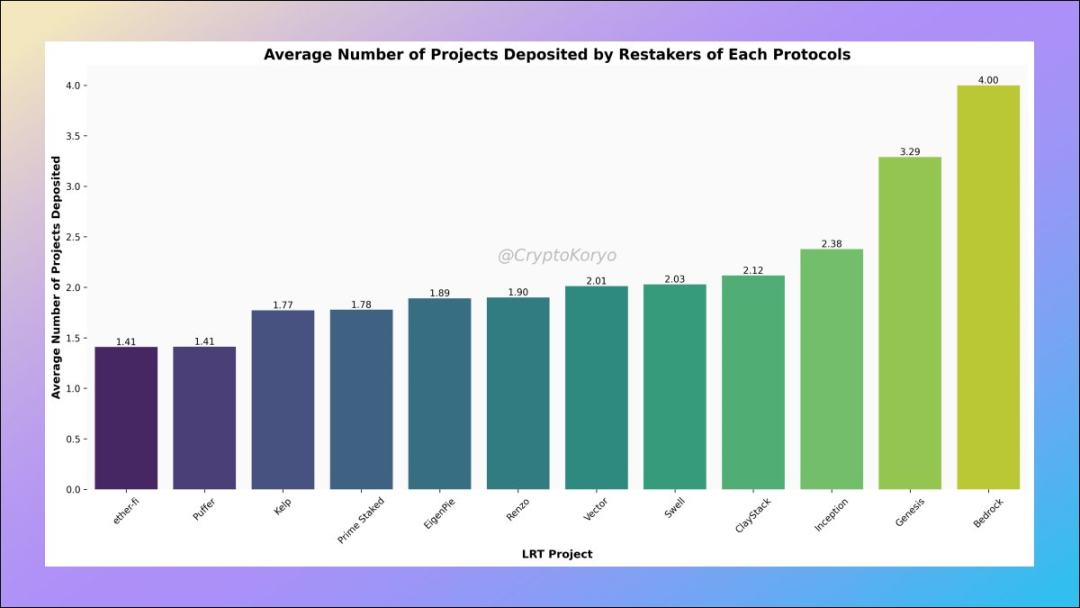
7.Protocol Loyalty
On average, users who deposited to ether.fi and Puffer only rescheduled on 1.41 protocols (on average) staking, which shows their confidence in both protocols.
However, users depositing into smaller protocols like Bedrock, Genesis, and Inception are indeed decentralized farming and diversifying their bets.
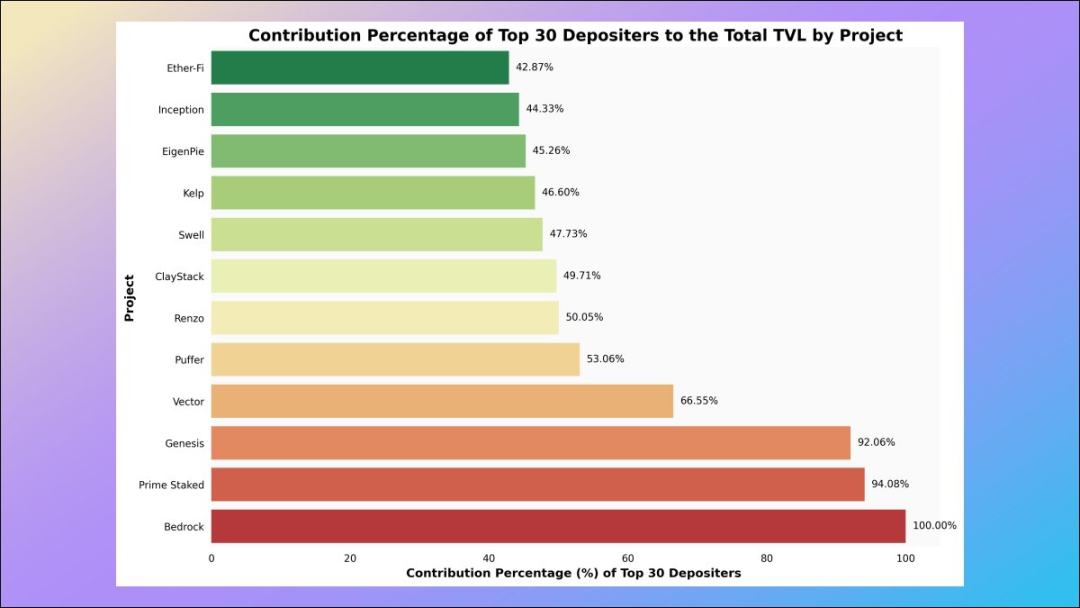
8. Contribution of giant whales
This is a very interesting place, we can study how much of the total TVL of each LST protocol comes from the top 30 Name deposit address - the lower this ratio, the healthier and more decentralized the liquidity of the corresponding LST protocol.
And TVL’s largest LRT protocol, ether.fi, ranks first in the degree of decentralization measured by this data!
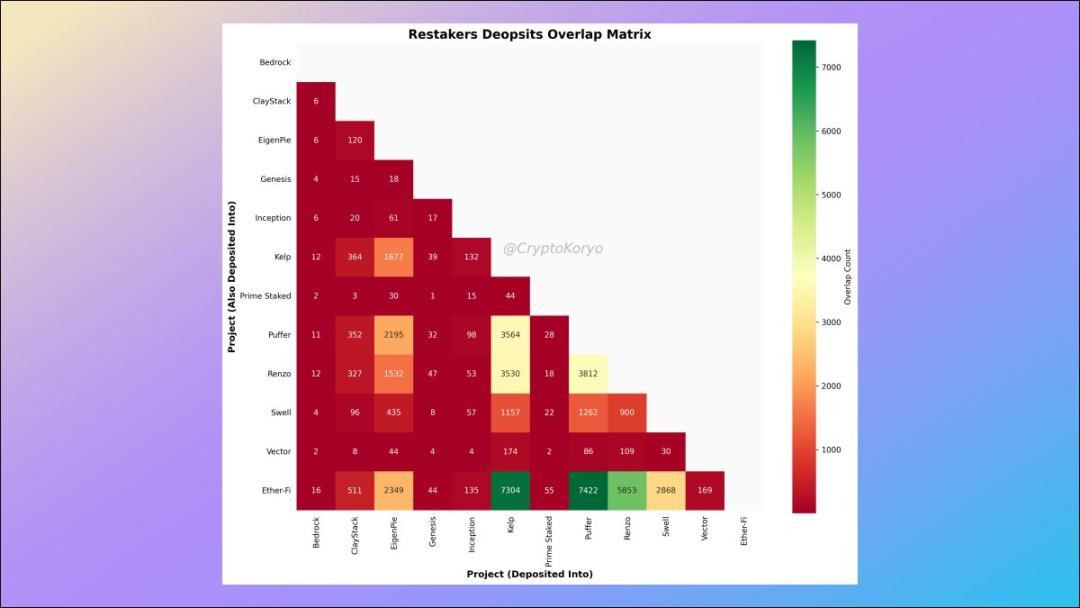
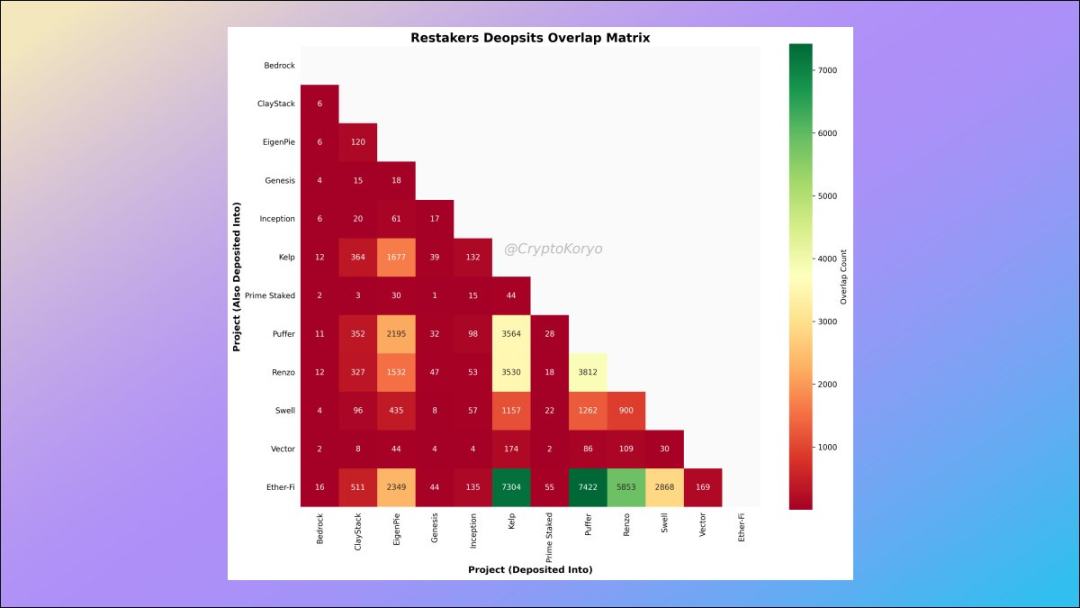
9. Relevance matrix of LRT protocols
What other LST protocols are commonly used by depositors of a certain LST protocol?
The data shows that ether.fi depositors also tend to deposit to Kelp and Puffer (and vice versa), so there are some interesting correlations here.
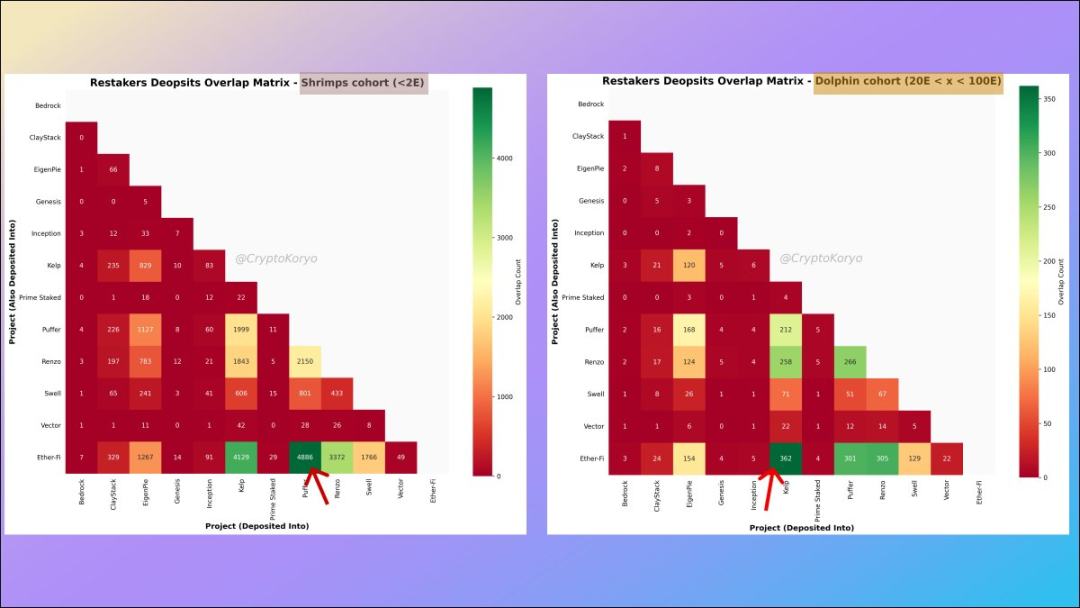
10. LRT protocol correlation matrix for different deposit addresses
We can define different groups and conduct a deeper analysis.
For the Shrimp queue (total deposit amount less than 2 ETH), the most popular LRT associated protocols are ether.fi and Puffer, but for the Dolphin queue (between 20 and 100 ETH) Generally speaking, the most popular LRT associated protocols are ether.fi and Kelp.
The above is the detailed content of 10 pictures to help you gain insight into the current situation of the LRT track. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 How to use Prim's algorithm in C++
Sep 20, 2023 pm 12:31 PM
How to use Prim's algorithm in C++
Sep 20, 2023 pm 12:31 PM
Title: Use of Prim algorithm and code examples in C++ Introduction: Prim algorithm is a commonly used minimum spanning tree algorithm, mainly used to solve the minimum spanning tree problem in graph theory. In C++, Prim's algorithm can be used effectively through reasonable data structures and algorithm implementation. This article will introduce how to use Prim's algorithm in C++ and provide specific code examples. 1. Introduction to Prim algorithm Prim algorithm is a greedy algorithm. It starts from a vertex and gradually expands the vertex set of the minimum spanning tree until it contains
 How to implement graph topological sorting algorithm using java
Sep 19, 2023 pm 03:19 PM
How to implement graph topological sorting algorithm using java
Sep 19, 2023 pm 03:19 PM
How to use Java to implement a topological sorting algorithm for graphs Introduction: Graph is a very common data structure and has a wide range of applications in the field of computer science. The topological sorting algorithm is a classic algorithm in graph theory that can sort a directed acyclic graph (DAG) to determine the dependencies between nodes in the graph. This article will introduce how to use the Java programming language to implement the topological sorting algorithm of the graph, and come with specific Java code examples. 1. Define the data structure of the graph. Before implementing the topological sorting algorithm, we first need to define
 How to use java to implement the Hamiltonian cycle algorithm of graphs
Sep 21, 2023 am 09:03 AM
How to use java to implement the Hamiltonian cycle algorithm of graphs
Sep 21, 2023 am 09:03 AM
How to use Java to implement the Hamiltonian cycle algorithm for graphs. A Hamiltonian cycle is a computational problem in graph theory, which is to find a closed path containing all vertices in a given graph. In this article, we will introduce in detail how to implement the Hamiltonian cycle algorithm using the Java programming language and provide corresponding code examples. Graph Representation First, we need to represent the graph using an appropriate data structure. In Java, we can represent graphs using adjacency matrices or adjacency linked lists. Here we choose to use an adjacency matrix to represent the graph. Define a file called
 How to set up two pictures to animate at the same time in PPT
Mar 26, 2024 pm 08:40 PM
How to set up two pictures to animate at the same time in PPT
Mar 26, 2024 pm 08:40 PM
1. Double-click to open the test document. 2. After clicking the job to create the first ppt document, click Insert--Picture--From File in the menu. 3. Select the file we inserted and click Insert. 4. Insert another one in the same way, and drag and adjust the two pictures to the appropriate position. 5. Select two pictures at the same time, right-click - Group - Group, so that the two pictures become one. 6. Select the merged graphic, right-click - Customize animation. 7. Click Add Effect, select an effect, and click OK. When you look at the PPT, you will find that the two pictures are moving together.
 In-depth exploration of the application and implementation methods of non-linear data structures of trees and graphs in Java
Dec 26, 2023 am 10:22 AM
In-depth exploration of the application and implementation methods of non-linear data structures of trees and graphs in Java
Dec 26, 2023 am 10:22 AM
Understanding Trees and Graphs in Java: Exploring Applications and Implementations of Nonlinear Data Structures Introduction In computer science, data structures are the way data is stored, organized, and managed in computers. Data structures can be divided into linear data structures and non-linear data structures. Trees and graphs are the two most commonly used types of nonlinear data structures. This article will focus on the concepts, applications and implementation of trees and graphs in Java, and give specific code examples. The Concept and Application of Tree A tree is an abstract data type, a collection of nodes and edges. Each node of the tree contains a number
 How to use java to implement the Euler cycle algorithm of graphs
Sep 19, 2023 am 09:01 AM
How to use java to implement the Euler cycle algorithm of graphs
Sep 19, 2023 am 09:01 AM
How to use Java to implement the Euler cycle algorithm for graphs? Euler circuit is a classic graph theory problem. Its essence is to find a path that can pass through each edge in the graph once and only once, and finally return to the starting node. This article will introduce how to use Java language to implement the Euler cycle algorithm of graphs, and provide specific code examples. 1. Graph representation method Before implementing the Euler loop algorithm, you first need to choose a suitable graph representation method. Common representations include adjacency matrices and adjacency lists. In this article, we will use adjacency lists to
 How to use java to implement the strongly connected component algorithm of graphs
Sep 21, 2023 am 11:09 AM
How to use java to implement the strongly connected component algorithm of graphs
Sep 21, 2023 am 11:09 AM
How to use Java to implement the strongly connected component algorithm of graphs Introduction: Graph is a commonly used data structure in computer science, and it can help us solve many practical problems. In a graph, a connected component refers to a set of vertices in the graph that have mutually reachable paths. A strongly connected component means that there is a bidirectional path between any two vertices in a directed graph. This article will introduce how to use Java to implement the strongly connected component algorithm of graphs to help readers better understand the connectivity of graphs. 1. Graph representation In Java, we can use adjacency matrix or adjacency
 Find the number of sink nodes in a graph using C++
Sep 01, 2023 pm 07:25 PM
Find the number of sink nodes in a graph using C++
Sep 01, 2023 pm 07:25 PM
In this article, we describe important information for solving the number of sink nodes in a graph. In this problem, we have a directed acyclic graph with N nodes (1 to N) and M edges. The goal is to find out how many sink nodes there are in a given graph. A sink node is a node that does not generate any outgoing edges. Here is a simple example - Input:n=4,m=2Edges[]={{2,3},{4,3}}Output:2 Simple way to find the solution In this method we will iterate The edges of the graph, push the different elements from the set pointed to by the edge into it, and then subtract the size of the set from the total number of nodes that exist. Example#include<bits/stdc++.h>usingnamespa