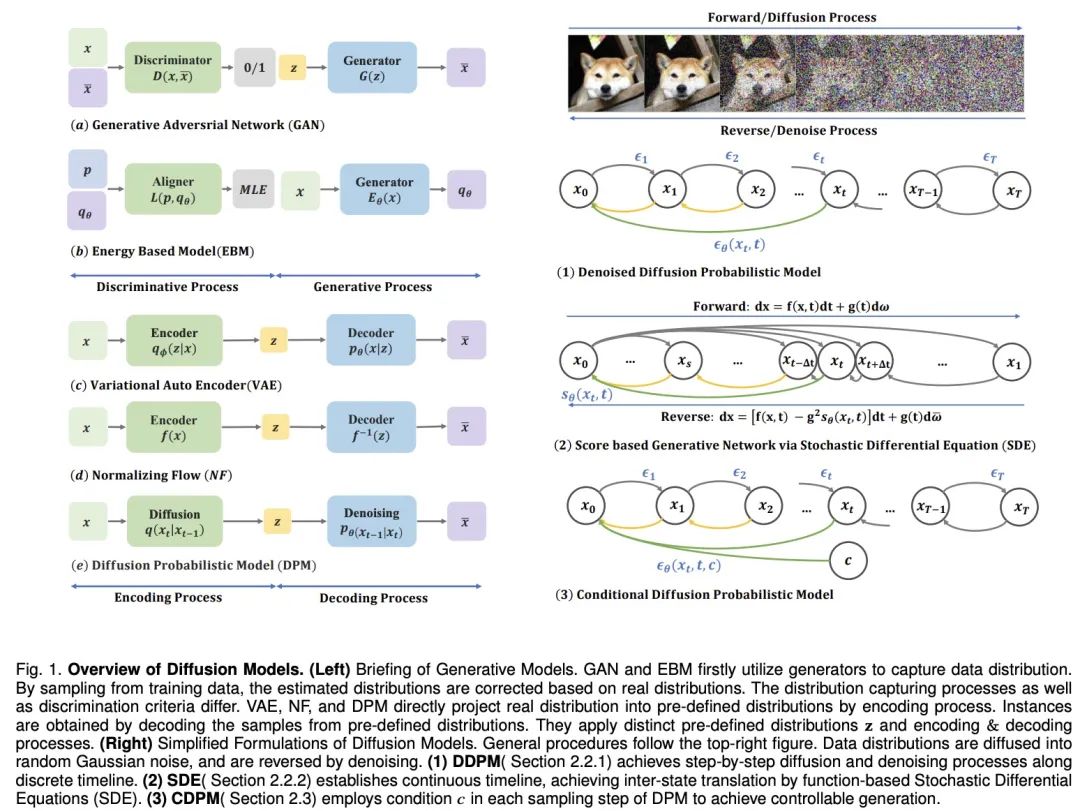
To enable machines to imitate human imagination, deep generative models have made significant progress. These models can create realistic samples, especially the diffusion model, which performs well in multiple areas. The diffusion model solves the limitations of other models, such as the posterior distribution alignment problem of VAEs, the instability of GANs, the computational complexity of EBMs, and the network constraint problem of NFs. Therefore, diffusion models have attracted much attention in aspects such as computer vision and natural language processing. The diffusion model consists of two processes: the forward process and the reverse process. The forward process transforms the data into a simple prior distribution, while the backward process reverses this change and uses a trained neural network to simulate differential equations to generate the data. Compared with other models, the diffusion model provides a more stable training target and better generation results. 
However, the sampling process of the diffusion model is accompanied by repeated reasoning and evaluation. This process faces challenges such as instability, high-dimensional computational requirements, and complex likelihood optimization. Researchers have proposed various solutions for this purpose, such as improving ODE/SDE solvers and adopting model distillation strategies to accelerate sampling, as well as new forward processes to improve stability and reduce dimensionality. Recently, Hong Kong Chinese Language and Literature, Westlake University, MIT, and Zhijiang Laboratory published a review paper titled "A Survey on Generative Diffusion Models" on IEEE TKDE. Recent advances in diffusion models are discussed in four aspects: sampling acceleration, process design, likelihood optimization, and distribution bridging. The review also provides an in-depth look at the success of diffusion models in different application areas such as image synthesis, video generation, 3D modeling, medical analysis, and text generation. Through these application cases, the practicality and potential of the diffusion model in the real world are demonstrated.
- Paper address: https://arxiv.org/pdf/2209.02646.pdf
- Project address: https://github.com/chq1155/ A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
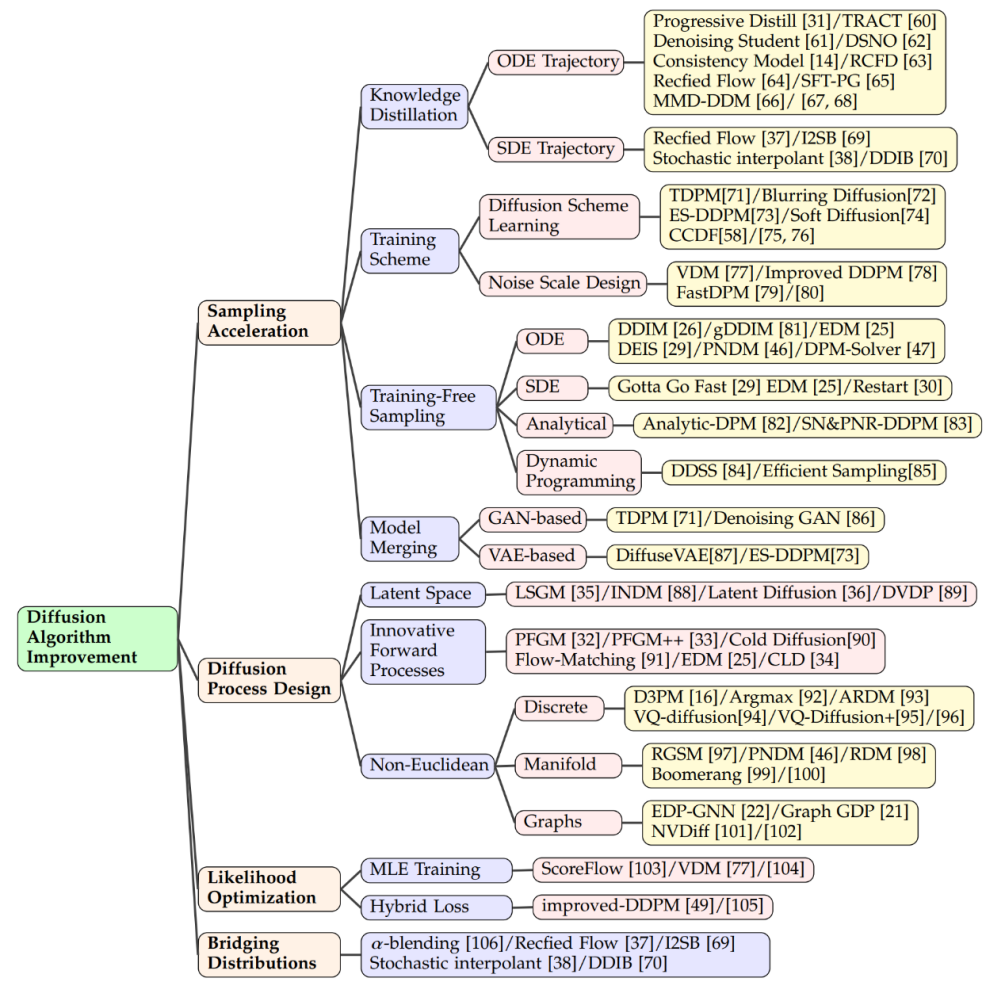
In the field of diffusion models, one of the key technologies to improve sampling speed is knowledge distillation. This process involves extracting knowledge from a large, complex model and transferring it to a smaller, more efficient model. For example, by using knowledge distillation, we can simplify the sampling trajectory of the model so that the target distribution is approximated with greater efficiency at each step. Salimans et al. adopted an ordinary differential equation (ODE)-based approach to optimize these trajectories, while other researchers developed techniques to estimate clean data directly from noisy samples, thus speeding up the process at time point T.
Improving the training method is also boosting sampling A method of efficiency. Some research focuses on learning new diffusion schemes, where the data is no longer simply spiked with Gaussian noise, but mapped to the latent space through more complex methods. Some of these methods focus on optimizing the inverse decoding process, such as adjusting the depth of encoding, while others explore new noise scale designs so that the addition of noise is no longer static, but becomes a variable that can be modified during the training process. learned parameters.
In addition to training new models To improve efficiency, there are also some techniques dedicated to accelerating the sampling process of already pre-trained diffusion models. ODE acceleration is one such technique that uses ODEs to describe the diffusion process, allowing sampling to proceed faster. For example, DDIM is a method that utilizes ODE for sampling, and subsequent research has introduced more efficient ODE solvers, such as PNDM and EDM, to further improve the sampling speed. Combined with other generative models
In addition, there are Researchers have proposed analytical methods to speed up sampling. These methods try to find an analytical solution that can directly recover clean data from noisy data without iteration. These methods include Analytic-DPM and its improved version Analytic-DPM, which provide a fast and accurate sampling strategy. Diffusion process design
Latent spatial diffusion models such as LSGM and INDM combine VAE or normalized flow models to optimize the codec through a shared weighted denoising fractional matching loss and diffusion models, such that the optimization of ELBO or log-likelihood aims to build a latent space that is easy to learn and generate samples. For example, Stable Diffusion first uses a VAE to learn a latent space and then trains a diffusion model to accept text input. DVDP dynamically adjusts the orthogonal components of pixel space during image perturbation. The forward process of innovation
In order to improve the generation Model efficiency and strength, researchers explore new forward process designs. The Poisson field generation model treats the data as charges, directing a simple distribution to the data distribution along the electric field lines, which provides more powerful backsampling than traditional diffusion models. PFGM further takes this concept into high-dimensional variables. The critically damped Langevin diffusion model of Dockhorn et al. simplifies the learning of fractional functions of conditional velocity distributions using velocity variables in Hamiltonian dynamics.
In discrete In the diffusion model of spatial data (such as text, categorical data), D3PM defines the forward process of discrete space. Based on this method, research has been extended to language text generation, graph segmentation and lossless compression. In multimodal challenges, vector quantized data is converted into codes, showing superior results. Manifold data in Riemannian manifolds, such as robotics and protein modeling, require diffusion sampling to be incorporated into the Riemannian manifold. Combinations of graph neural networks and diffusion theory, such as EDP-GNN and GraphGDP, process graph data to capture permutation invariance. Likelihood Optimization
Although the diffusion model optimizes ELBO, the likelihood optimization remains a challenge, especially for continuous-time diffusion models. Methods such as ScoreFlow and variational diffusion models (VDM) establish the connection between MLE training and DSM objectives, in which Girsanov's theorem plays a key role. The improved denoising diffusion probabilistic model (DDPM) proposes a hybrid learning objective that combines variational lower bounds and DSM, as well as a simple reparameterization technique.Performance of diffusion model when converting Gaussian distribution to complex distribution Excellent, but has challenges when connecting arbitrary distributions. Alpha-hybrid methods create deterministic bridges by iteratively mixing and mixing. Correction flow adds additional steps to correct the bridge path. Another method is to realize the connection between two distributions through ODE, and the method of Schrödinger bridge or Gaussian distribution as the intermediate connection point is also under investigation.
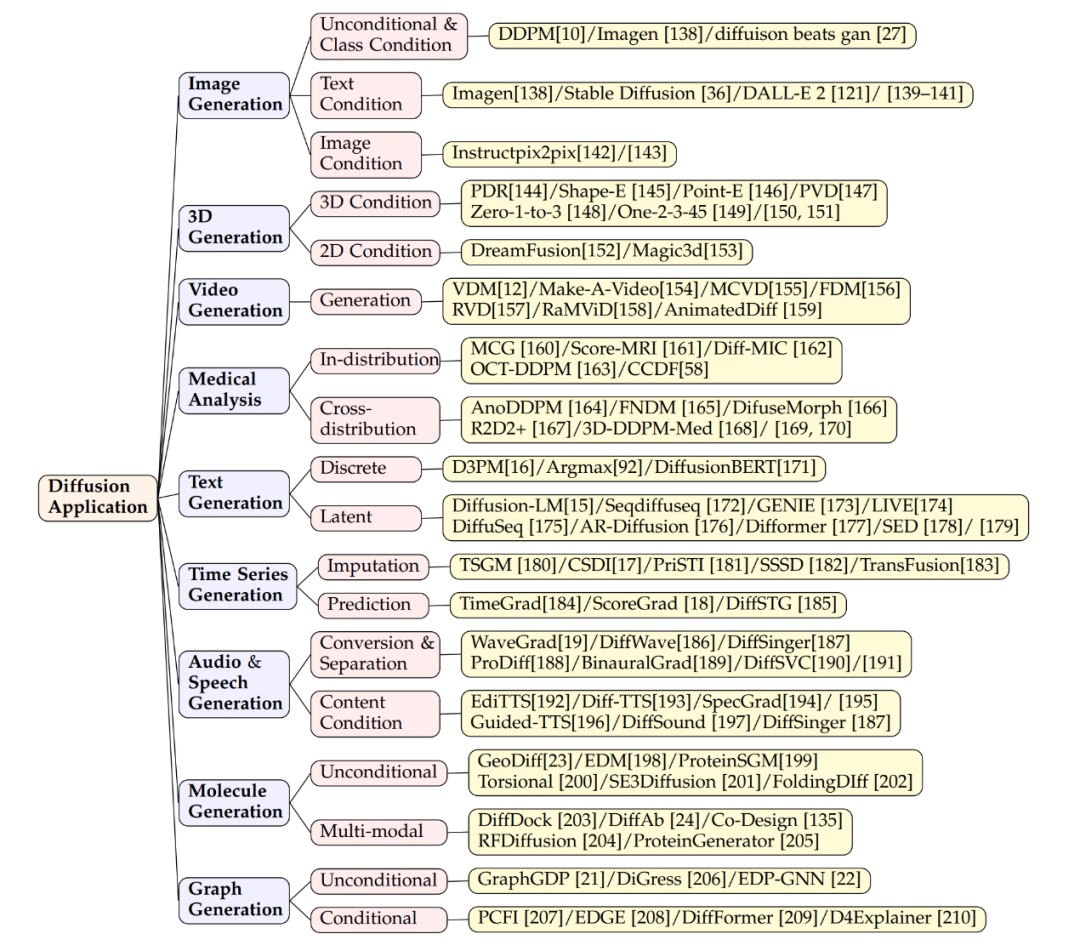
Diffusion The model has been very successful in image generation, not only generating ordinary images but also completing complex tasks such as converting text into images. Models such as Imagen, Stable Diffusion and DALL-E 2 demonstrate great skill in this regard. They use a diffusion model structure, combined with cross-attention layer techniques, to integrate text information into generated images. In addition to generating new images, these models can edit images without requiring retraining. Editing is achieved by adjusting across attention layers (keys, values, attention matrices). For example, adding new concepts by adjusting feature maps to change image elements or introducing new text embeddings. There is research to ensure that the model pays attention to all keywords of the text when generating it to ensure that the image accurately reflects the description. Diffusion models can also handle image-based conditional inputs, such as source images, depth maps, or human skeletons, by encoding and integrating these features to guide image generation. Some studies add source image encoding features to the starting layer of the model to achieve image-to-image editing, which is also applicable to scenes where depth maps, edge detection or skeletons are used as conditions. In terms of 3D generation, the main methods through diffusion models are Two kinds. The first is to train models directly on 3D data, which have been effectively applied to a variety of 3D representations such as NeRF, point clouds, or voxels. For example, researchers have shown how to directly generate point clouds of 3D objects. In order to improve the efficiency of sampling, some studies have introduced hybrid point-voxel representation, or image synthesis as an additional condition for point cloud generation. On the other hand, there are studies that use diffusion models to process NeRF representations of 3D objects, and synthesize novel views and optimize NeRF representations by training perspective-conditional diffusion models. The second approach emphasizes using prior knowledge of 2D diffusion models to generate 3D content. For example, the Dreamfusion project uses a score distillation sampling objective to extract NeRF from a pretrained text-to-image model and achieves low-loss rendered images through a gradient descent optimization process. This process has also been further extended to speed up generation. The video diffusion model is an extension of the 2D image diffusion model. They generate video sequences by adding a temporal dimension. The basic idea of this approach is to add temporal layers to the existing 2D structure as a way to model continuity and dependencies between video frames. Related work shows how to use video diffusion models to generate dynamic content, such as Make-A-Video, AnimatedDiff and other models. More specifically, the RaMViD model uses a 3D convolutional neural network to extend the image diffusion model to video and develops a series of video-specific conditional techniques. ##Diffusion model helps solve the problem of obtaining high-quality data in medical analysis set of challenges, especially in medical imaging. These models have been successful in improving image resolution, classification, and noise processing due to their powerful image capture capabilities. For example, Score-MRI and Diff-MIC use advanced techniques to speed up the reconstruction of MRI images and enable more precise classification. MCG employs manifold correction in CT image super-resolution, improving reconstruction speed and accuracy. In terms of generating rare images, the model can convert between different types of images through specific techniques. For example, FNDM and DiffuseMorph are used for brain anomaly detection and MR image registration respectively. Some new methods synthesize training datasets from a small number of high-quality samples, such as a model using 31,740 samples that synthesized a dataset of 100,000 instances and achieved very low FID scores.
Text generation technology is an important bridge between humans and AI. Can produce fluent and natural language. Autoregressive language models generate text with strong coherence but are slow, while diffusion models can generate text quickly but with relatively weak coherence. The two mainstream methods are discrete generation and latent generation. Discrete generation relies on advanced techniques and pre-trained models; for example, D3PM and Argmax treat words as categorical vectors, while DiffusionBERT combines diffusion models with language models to improve text generation. Latent generation generates text in the latent space of tokens. For example, models such as LM-Diffusion and GENIE perform well in various tasks, showing the potential of diffusion models in text generation. Diffusion models are expected to improve performance in natural language processing, integrate with large language models, and enable cross-modal generation.
Time series data modeling is used in finance, climate Key technology for prediction and analysis in science, medical and other fields. Diffusion models have been used in the generation of time series data due to their ability to generate high-quality data samples.In this field, diffusion models are often designed to take into account the temporal dependence and periodicity of time series data. For example, CSDI (Conditional Sequence Diffusion Interpolation) is a model that utilizes a bidirectional convolutional neural network structure to generate or interpolate time series data points. It excels in medical data generation and environmental data generation. Other models such as DiffSTG and TimeGrad can better capture the dynamic characteristics of time series and generate more realistic time series samples by combining spatiotemporal convolutional networks. These models gradually recover meaningful time series data from Gaussian noise through self-conditioning guidance.
Audio generation involves everything from speech synthesis to music generation. application scenarios. Since audio data usually contains complex temporal structures and rich spectral information, diffusion models also show potential in this field. For example, WaveGrad and DiffSinger are two diffusion models that utilize a conditional generation process to produce high-quality audio waveforms. WaveGrad uses the Mel spectrum as a conditional input, while DiffSinger adds additional musical information such as pitch and tempo on top of this to provide finer stylistic control. In text-to-speech (TTS) applications, Guided-TTS and Diff-TTS combine the concepts of text encoders and acoustic classifiers to generate speech that both conforms to the text content and follows a specific sound style. Guide-TTS2 further demonstrates how to generate speech without an explicit classifier, guiding sound generation through features learned by the model itself. In the fields of drug design, materials science and chemical biology , molecular design is an important step in the discovery and synthesis of new compounds. Diffusion models serve here as a powerful tool to efficiently explore chemical space and generate molecules with specific properties. In unconditional molecule generation, the diffusion model generates molecular structures spontaneously without relying on any prior knowledge. In cross-modal generation, the model may incorporate specific functional conditions, such as drug efficacy or binding propensity of a target protein, to generate molecules with desired properties. Sequence-based methods may consider the protein sequence to guide the generation of molecules, while structure-based methods may use the three-dimensional structural information of the protein. Such structural information can be used as prior knowledge in molecular docking or antibody design, thereby improving the quality of generated molecules. Generates graphs using a diffusion model aimed at better understanding and simulate real-world network structures and propagation processes. This approach helps researchers mine patterns and interactions in complex systems and predict possible outcomes. Applications include social networks, biological network analysis, and the creation of graph datasets. Traditional methods rely on generating adjacency matrices or node features, but these methods have poor scalability and limited practicality. Therefore, modern graph generation techniques prefer to generate graphs based on specific conditions. For example, the PCFI model uses part of the graph's features and shortest path predictions to guide the generation process; EDGE and DiffFormer use node degree and energy constraints to optimize generation respectively; D4Explainer explores different possibilities of the graph by combining distribution and counterfactual losses. These methods improve the accuracy and practicality of graph generation.
Challenges under data limitations In addition to slow inference speed, diffusion models often encounter difficulties in identifying patterns and regularities from low-quality data, causing them to fail to generalize to new scenarios or data sets. Additionally, computational challenges arise when dealing with large-scale datasets, such as extended training times, excessive memory usage, or inability to converge to desired states, thereby limiting model size and complexity. What’s more, biased or uneven data sampling can limit a model’s ability to generate outputs that are adaptable to different domains or populations. Controllable distribution-based generationImprove model understanding and generate specific distributions The ability to in-sample is critical to achieving better generalization with limited data. By focusing on identifying patterns and correlations in the data, the model can generate samples that closely match the training data and meet specific requirements. This requires efficient data sampling, utilization techniques, and optimization of model parameters and structures. Ultimately, this enhanced understanding allows for more controlled and precise generation, thereby improving generalization performance. Advanced multimodal generation utilizing large language modelsThe future of diffusion models Development directions involve advancing multimodal generation by integrating large language models (LLMs). This integration enables the model to generate outputs containing combinations of text, images, and other modalities. By incorporating LLMs, the model's understanding of the interactions between different modalities is enhanced, and the generated outputs are more diverse and realistic. Furthermore, LLMs significantly improve prompt-based generation efficiency by effectively leveraging the connections between text and other modalities. In addition, LLMs, as catalysts, improve the generation capability of diffusion models and expand the range of fields in which they can generate modes. Integration with the field of machine learningIntegrate the diffusion model with traditional machine learning Combining theory provides new opportunities to improve performance on a variety of tasks. Semi-supervised learning is particularly valuable in addressing inherent challenges of diffusion models, such as generalization problems, and in enabling efficient conditional generation when data is limited. By leveraging unlabeled data, it enhances the generalization capabilities of diffusion models and achieves ideal performance when generating samples under specific conditions. In addition, reinforcement learning plays a crucial role by using fine-tuning algorithms to provide targeted guidance during the sampling process of the model. This guidance ensures focused exploration and promotes controlled generation. In addition, reinforcement learning is enriched by integrating additional feedback, thereby improving the model's ability to generate controllable conditions. Algorithm improvement method (Appendix)
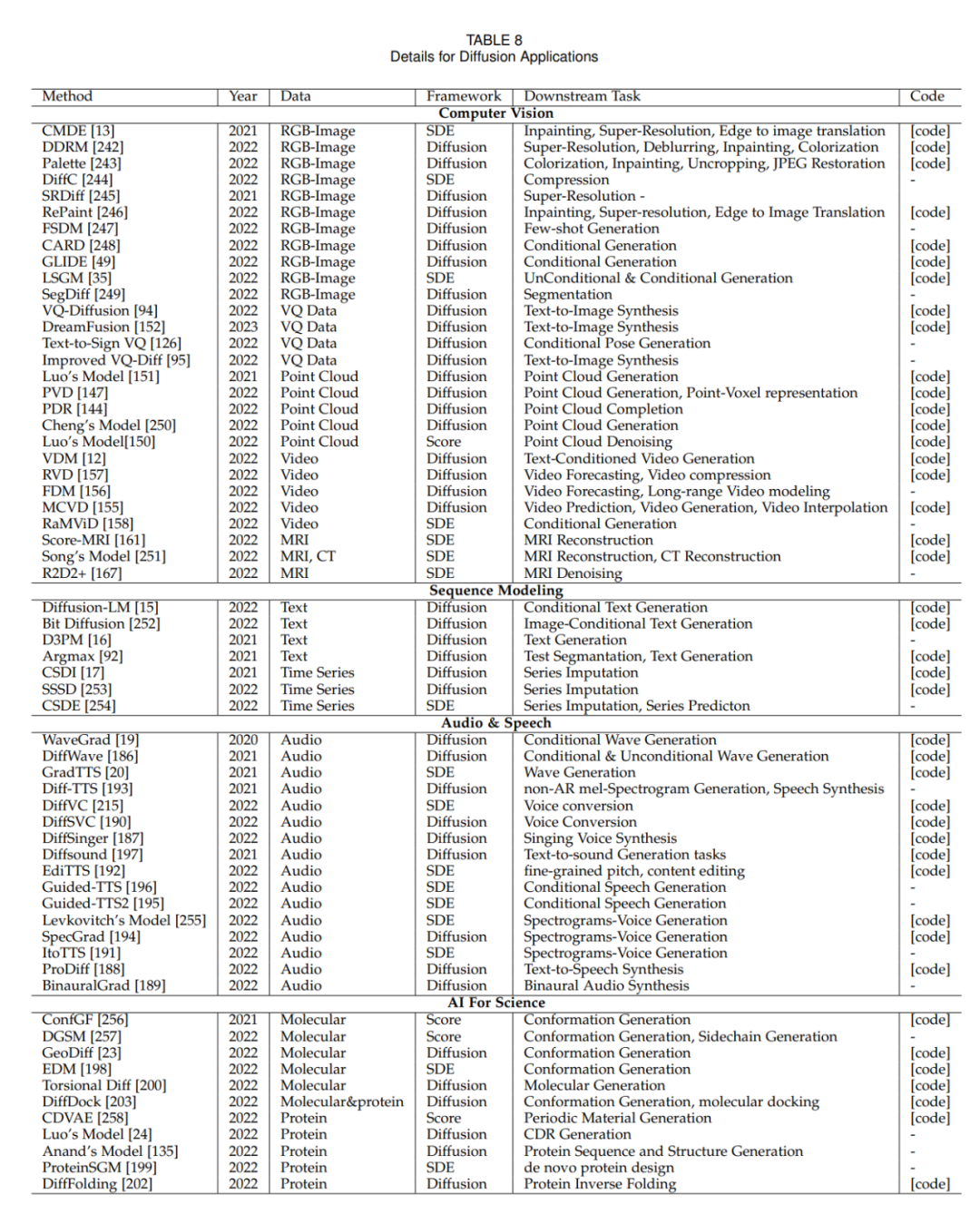
Field application method (Appendix )
The above is the detailed content of The technology behind the explosion of Sora, an article summarizing the latest development direction of diffusion models. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



