
 Technology peripherals
AI
Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Technology peripherals
AI
Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features

After the AI video model Sora became popular, major companies such as Meta and Google have stepped aside to do research and catch up with OpenAI.
Recently, researchers from the Google team proposed a universal video encoder-VideoPrism.
It can handle various video understanding tasks through a single frozen model.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2402.13217.pdf
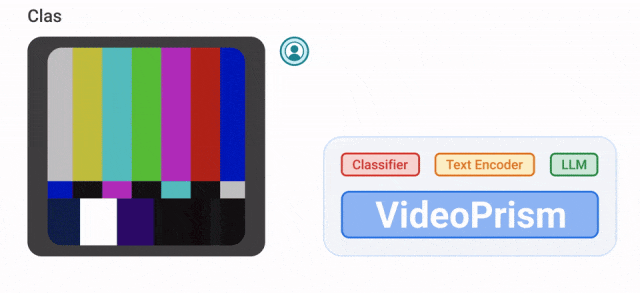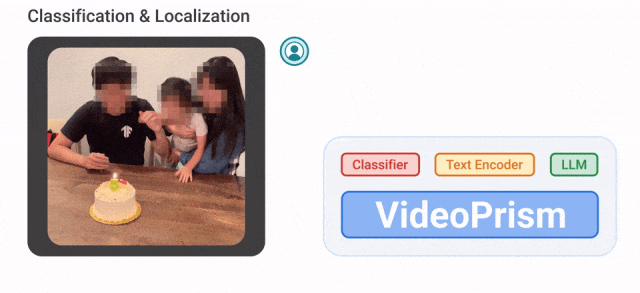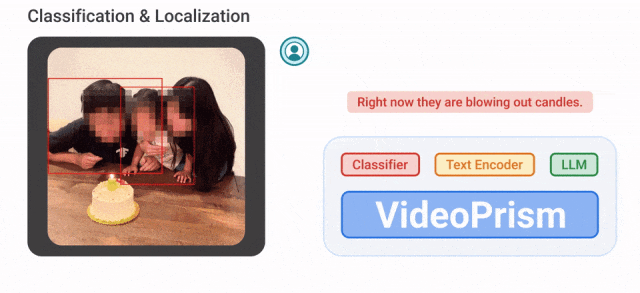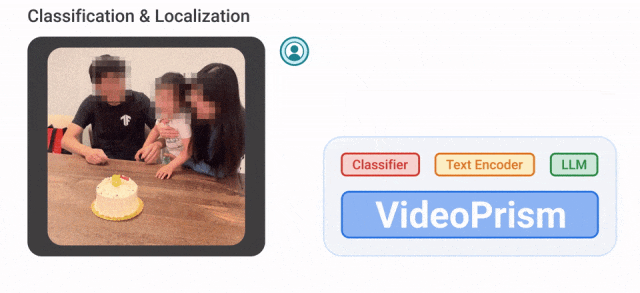
For example, VideoPrism can convert the following The people blowing candles in the video are classified and located.
 Picture
Picture
Video-text retrieval, according to the text content, the corresponding content in the video can be retrieved.
 Picture
Picture
For another example, describe the video below - a little girl is playing with building blocks.
You can also conduct QA questions and answers.
- What color are the blocks she placed above the green blocks?
- Purple.
 Picture
Picture
The researchers pre-trained VideoPrism on a heterogeneous corpus containing 36 million high-quality video subtitle pairs and 582 million video clips. , and with noisy parallel text (such as ASR transcribed text).
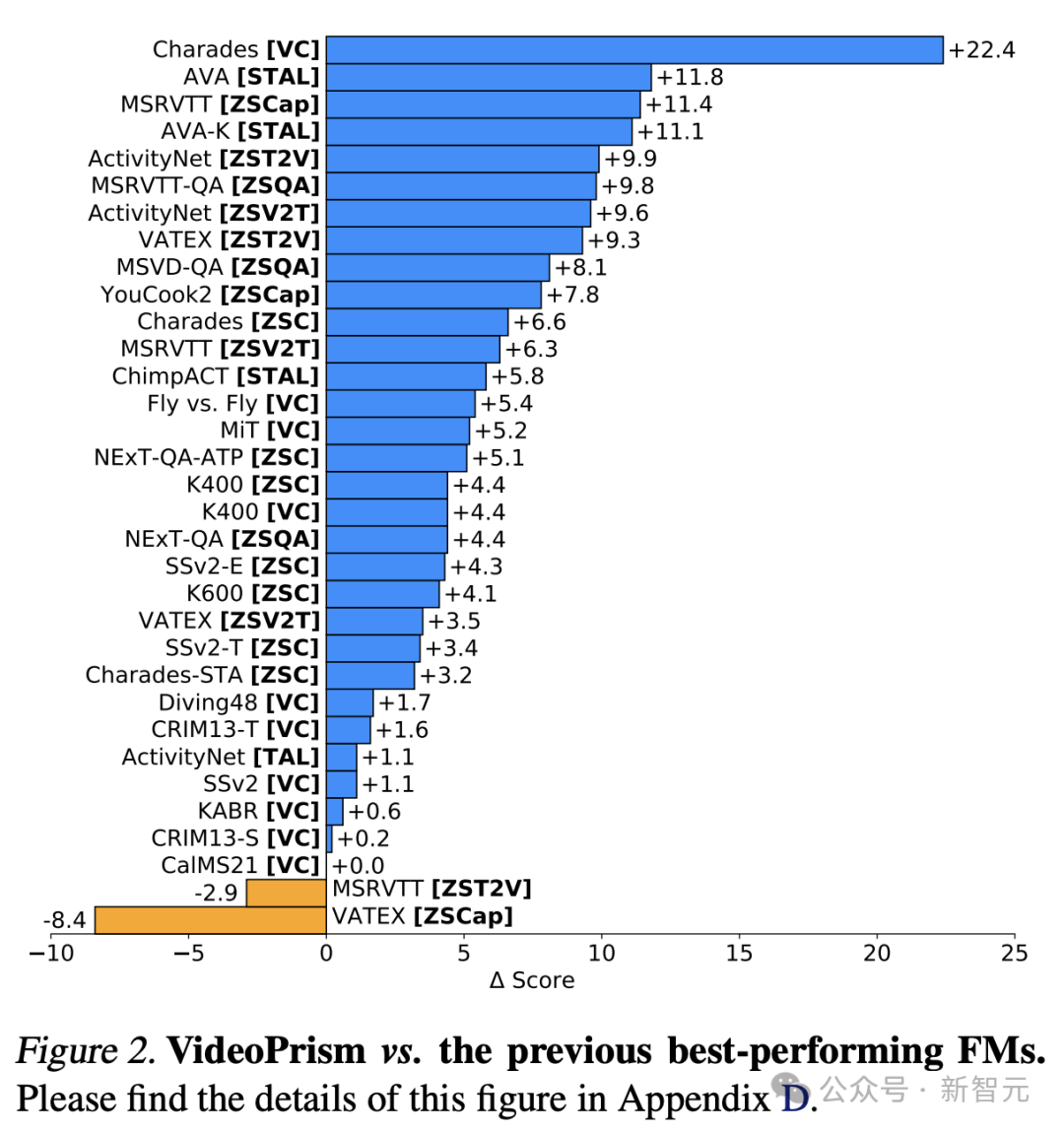
It is worth mentioning that VideoPrism refreshed 30 SOTA in 33 video understanding benchmark tests.
 Picture
Picture
Universal Visual Encoder VideoPrism
Currently, the Video Fundamental Model (ViFM) has great potential to be used in huge Unlock new abilities within the corpus.
Although previous research has made great progress in general video understanding, building a true "basic video model" is still an elusive goal.
In response, Google launched VideoPrism, a general-purpose visual encoder designed to solve a wide range of video understanding tasks, including classification, localization, retrieval, subtitles, and question answering (QA).
VideoPrism is extensively evaluated on CV datasets, as well as CV tasks in scientific fields such as neuroscience and ecology.
Achieve state-of-the-art performance with minimal fitness by using a single frozen model.
In addition, Google researchers say that this frozen encoder setting follows previous research and takes into account its practical practicality, as well as the high cost of computation and fine-tuning the video model.
 Picture
Picture
Design architecture, two-stage training method
The design concept behind VideoPrism is as follows.
Pre-training data is the basis of the basic model (FM). The ideal pre-training data for ViFM is a representative sample of all videos in the world.
In this sample, most videos do not have parallel text describing the content.
However, if trained on such text, it can provide invaluable semantic clues about the video space.
Therefore, Google’s pre-training strategy should focus primarily on the video mode while fully utilizing any available video-text pairs.
On the data side, Google researchers approximated this by assembling 36 million high-quality video subtitle pairs and 582 million video clips with noisy parallel text (such as ASR transcriptions, generated subtitles, and retrieved text). Required pre-training corpus.
 picture
picture
 Picture
Picture
In terms of modeling, the authors first comparatively learn semantic video embeddings from all video-text pairs of different qualities.
The masked video modeling described below is then improved by global and label refinement of the semantic embeddings using a wide range of pure video data.
Despite the success in natural language, masked data modeling remains challenging for CV due to the lack of semantics in the original visual signal.
Existing research addresses this challenge by borrowing indirect semantics (such as using CLIP to guide models or tokenizers, or implicit semantics) or implicitly generalizing them (such as labeling visual patches), which converts high masking rates into Combined with lightweight decoders.
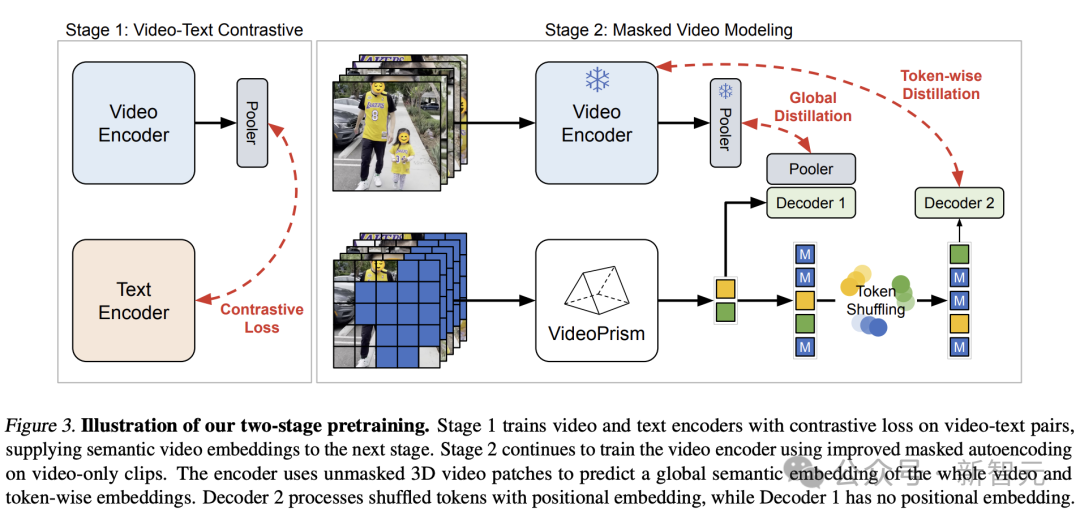
Based on the above ideas, the Google team adopted a two-stage approach based on pre-training data.
 Picture
Picture
In the first stage, contrastive learning is performed to align the video encoder with the text encoder using all video-text pairs.
Based on previous research, the Google team minimized the similarity scores of all video-text pairs in the batch, performing symmetric cross-entropy loss minimization.
And use CoCa's image model to initialize the spatial coding module, and incorporate WebLI into pre-training.
Before calculating the loss, the video encoder features are aggregated through multi-head attention pooling (MAP).
This stage allows the video encoder to learn rich visual semantics from linguistic supervision, and the resulting model provides semantic video embeddings for the second stage training.
 Picture
Picture
In the second stage, the encoder continues to be trained and two improvements are made:
-The model needs to be based on the unmasked The input video patches of the code are used to predict the video-level global embedding and token embedding in the first stage
- The output token of the encoder is randomly shuffled before being passed to the decoder to avoid learning shortcuts.
Notably, the researchers’ pre-training leveraged two supervision signals: the textual description of the video, and contextual self-supervision, allowing VideoPrism to perform well on appearance- and action-centric tasks.
In fact, previous research shows that video captions mainly reveal appearance cues, while contextual supervision helps learn actions.
 Picture
Picture
Experimental Results
Next, the researchers evaluated VideoPrism on a wide range of video-centric comprehension tasks, showing Its capabilities and versatility.
Mainly divided into the following four categories:
(1) Generally only video understanding, including classification and spatio-temporal positioning
(2) Zero-sample video text retrieval
(3) Zero-sample video subtitles and quality checking
(4) CV tasks in science
Classification and spatiotemporal localization
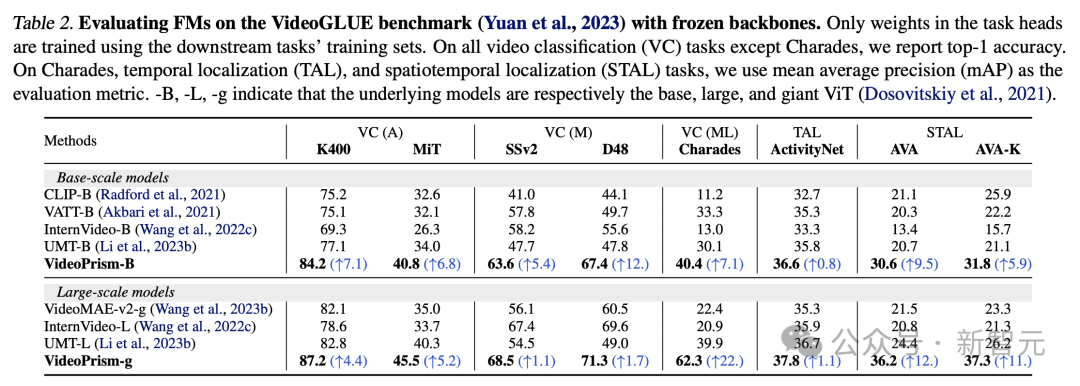
Table 2 shows freezing on VideoGLUE Backbone results.
VideoPrism significantly outperforms the baseline on all datasets. Furthermore, increasing VideoPrism’s underlying model size from ViT-B to ViT-g significantly improves performance.
It is worth noting that no baseline method achieves the second best result across all benchmarks, suggesting that previous methods may have been developed to target certain aspects of video understanding.
And VideoPrism continues to improve on this broad task.
This result shows that VideoPrism integrates various video signals into one encoder: semantics at multiple granularities, appearance and motion cues, spatiotemporal information, and the ability to interpret different video sources (such as online videos and scripted performances) of robustness.
 Picture
Picture
Zero-shot video text retrieval and classification
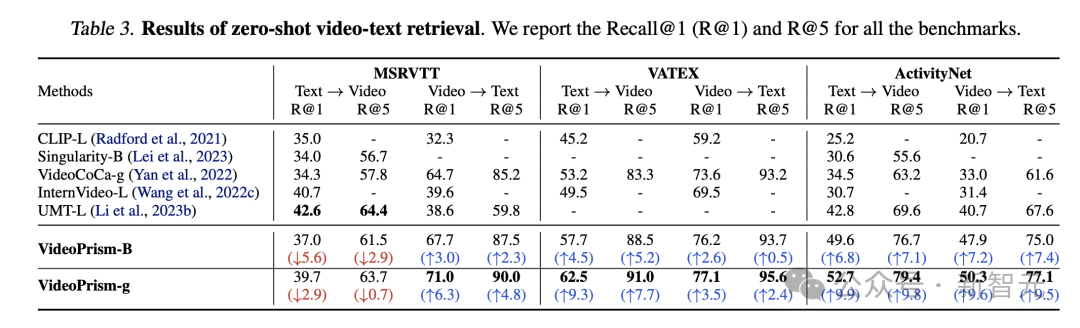
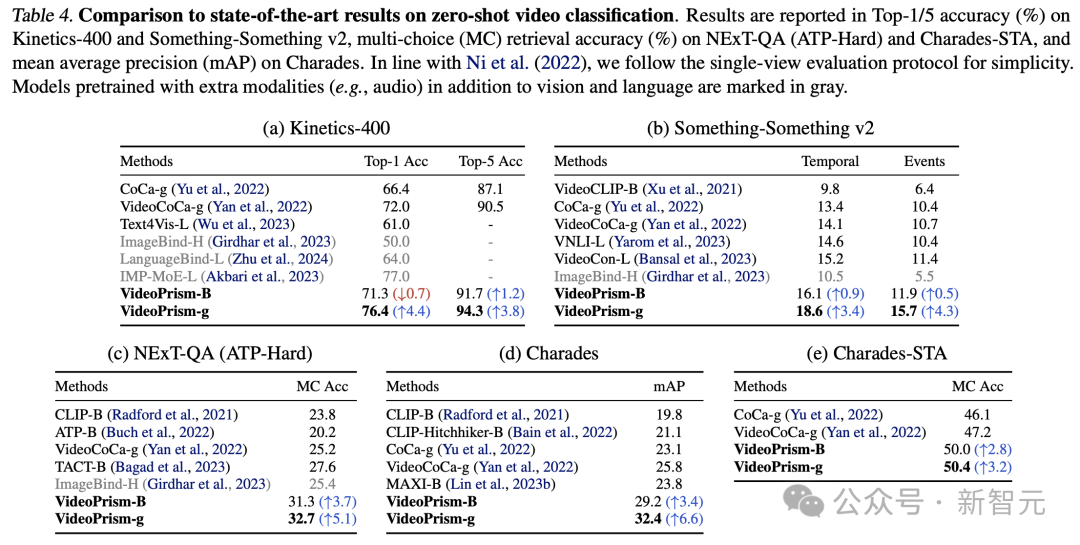
Tables 3 and 4 summarize the results of video text retrieval and video classification respectively.
VideoPrism’s performance refreshes multiple benchmarks, and on challenging data sets, VideoPrism has achieved very significant improvements compared with previous technologies.
 Picture
Picture
Most results for the base model VideoPrism-B actually outperform existing larger-scale models.
Furthermore, VideoPrism is comparable to or even better than the models in Table 4 pretrained using in-domain data and additional modalities (e.g., audio). These improvements in zero-shot retrieval and classification tasks reflect VideoPrism’s powerful generalization capabilities.
 Picture
Picture
Zero-sample video subtitles and quality check
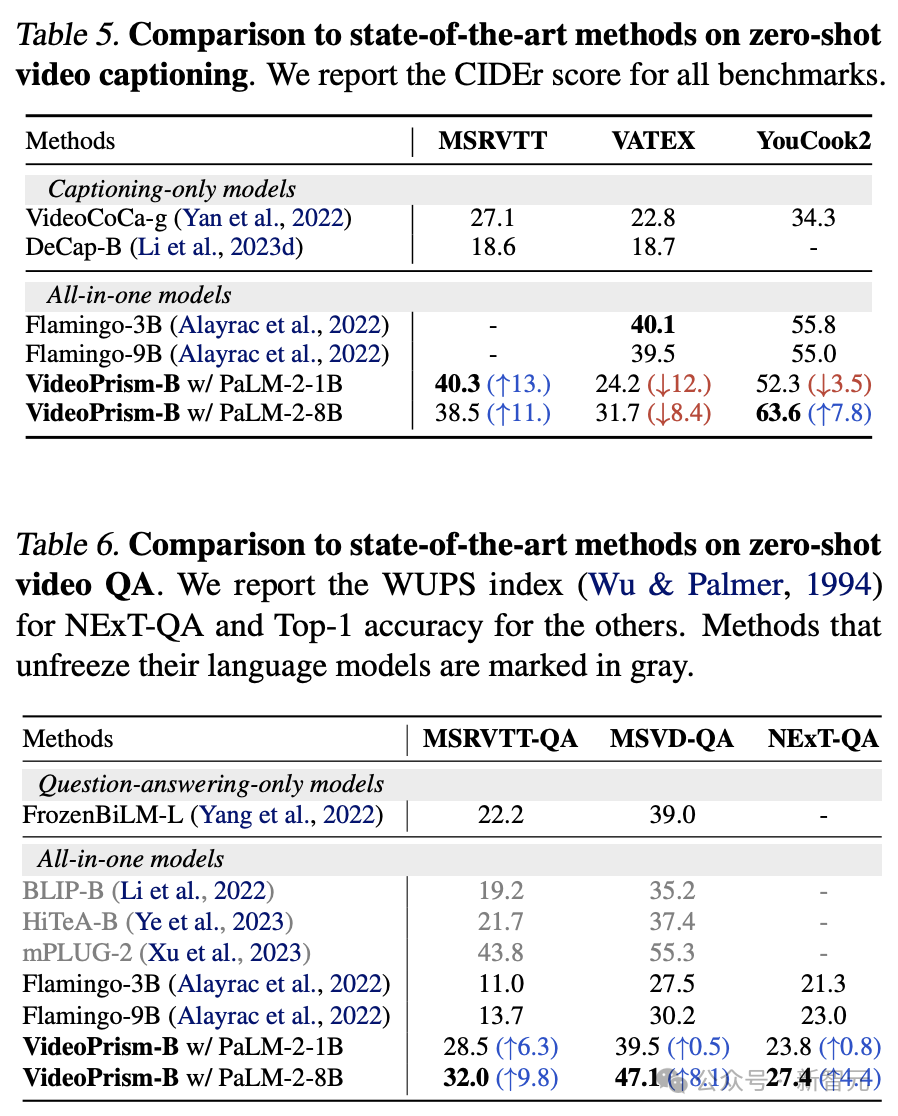
Table 5 and Table 6 show, respectively, zero-sample video subtitles and QA the result of.
Despite the simple model architecture and the small number of adapter parameters, the latest models are still competitive and, with the exception of VATEX, rank among the top methods for freezing visual and language models.
The results show that the VideoPrism encoder can generalize well to video-to-language generation tasks.
 Pictures
Pictures
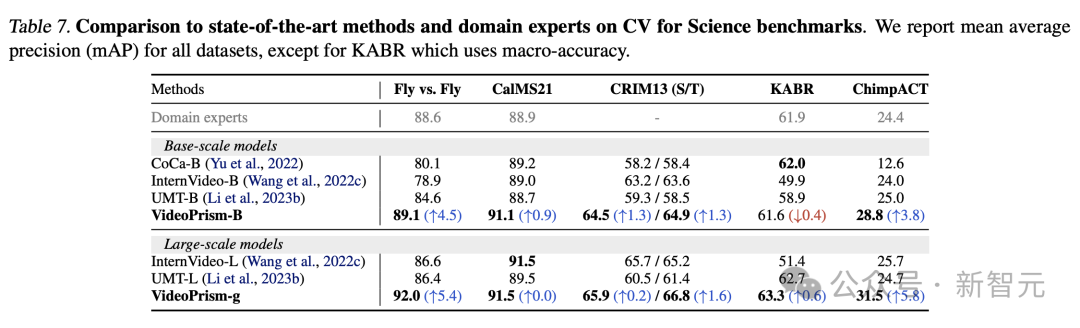
CV tasks in science
Generic ViFM uses a shared frozen encoder in all evaluations and its performance is comparable to that of specialized Comparable to domain-specific models for a single task.
In particular, VideoPrism often performs best and outperforms domain expert models with base scale models.
Scaling to large-scale models can further improve performance on all datasets. These results demonstrate that ViFM has the potential to significantly accelerate video analysis in different fields.
Ablation Study
Figure 4 shows the ablation results. Notably, VideoPrism’s continued improvements on SSv2 demonstrate the effectiveness of data management and model design efforts in promoting motion understanding in video.
Although the comparative baselines already achieved competitive results on K400, the proposed global distillation and token shuffling further improve the accuracy.
 Picture
Picture
Reference:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder.html
The above is the detailed content of Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
Using locally installed font files in web pages Recently, I downloaded a free font from the internet and successfully installed it into my system. Now...
 How to select a child element with the first class name item through CSS?
Apr 05, 2025 pm 11:24 PM
How to select a child element with the first class name item through CSS?
Apr 05, 2025 pm 11:24 PM
When the number of elements is not fixed, how to select the first child element of the specified class name through CSS. When processing HTML structure, you often encounter different elements...
 Where to get the material for H5 page production
Apr 05, 2025 pm 11:33 PM
Where to get the material for H5 page production
Apr 05, 2025 pm 11:33 PM
The main sources of H5 page materials are: 1. Professional material website (paid, high quality, clear copyright); 2. Homemade material (high uniqueness, but time-consuming); 3. Open source material library (free, need to be carefully screened); 4. Picture/video website (copyright verified is required). In addition, unified material style, size adaptation, compression processing, and copyright protection are key points that need to be paid attention to.
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
The H5 page needs to be maintained continuously, because of factors such as code vulnerabilities, browser compatibility, performance optimization, security updates and user experience improvements. Effective maintenance methods include establishing a complete testing system, using version control tools, regularly monitoring page performance, collecting user feedback and formulating maintenance plans.
 Setting flex: 1 1 0 What is the difference between setting flex-basis and not setting flex-basis?
Apr 05, 2025 am 09:39 AM
Setting flex: 1 1 0 What is the difference between setting flex-basis and not setting flex-basis?
Apr 05, 2025 am 09:39 AM
The difference between flex:110 in Flex layout and flex-basis not set In Flex layout, how to set flex...
 How to use CSS and Flexbox to implement responsive layout of images and text at different screen sizes?
Apr 05, 2025 pm 06:06 PM
How to use CSS and Flexbox to implement responsive layout of images and text at different screen sizes?
Apr 05, 2025 pm 06:06 PM
Implementing responsive layouts using CSS When we want to implement layout changes under different screen sizes in web design, CSS...
 How to keep the text at the bottom while the input box height increases?
Apr 05, 2025 pm 02:12 PM
How to keep the text at the bottom while the input box height increases?
Apr 05, 2025 pm 02:12 PM
How to keep the text at the bottom while the input box height increases? During the development process, we often encounter the need to adjust the input box height, and at the same time hope...
 How to increase the height of the input and position the text at the bottom?
Apr 05, 2025 am 06:03 AM
How to increase the height of the input and position the text at the bottom?
Apr 05, 2025 am 06:03 AM
How to increase the height of input and make the text at the bottom? When developing web pages, you often encounter the need to adjust the style of form elements. Especially when...
