
 Technology peripherals
AI
Break into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it
Technology peripherals
AI
Break into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it
Break into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it

The diffusion model has ushered in a major new application -
Just like Sora generates videos, it generates parameters for the neural network and directly penetrates into the bottom layer of AI!
This is the latest open source research result of Professor You Yang’s team at the National University of Singapore, together with UCB, Meta AI Laboratory and other institutions.

Specifically, the research team proposed a diffusion model p(arameter)-diff for generating neural network parameters.
Use it to generate network parameters, the speed is up to 44 times faster than direct training, and the performance is not inferior.
After the model was released, it quickly aroused heated discussions in the AI community. Experts in the circle expressed the same amazing attitude towards it as ordinary people did when they saw Sora.
Some people even directly exclaimed that this is basically equivalent to AI creating new AI.

Even AI giant LeCun praised the result after seeing it, saying it was really a cute idea.
In fact, p-diff does have the same significance as Sora. Dr. Fuzhao Xue (Xue Fuzhao) from the same laboratory explained in detail:
Sora generates high-dimensional data, i.e. videos, which makes Sora a world simulator (close to AGI from one dimension).
And this work, neural network diffusion, can generate parameters in the model, has the potential to become a meta-world-class learner/optimizer, moving towards AGI from another new important dimension.

Getting back to the subject, how does p-diff generate neural network parameters?
Combining the autoencoder with the diffusion model
To clarify this problem, we must first understand the working characteristics of the diffusion model and the neural network.
The diffusion generation process is a transformation from a random distribution to a highly specific distribution. Through the addition of compound noise, the visual information is reduced to a simple noise distribution.
Neural network training also follows this transformation process and can also be degraded by adding noise. Inspired by this feature, researchers proposed the p-diff method.
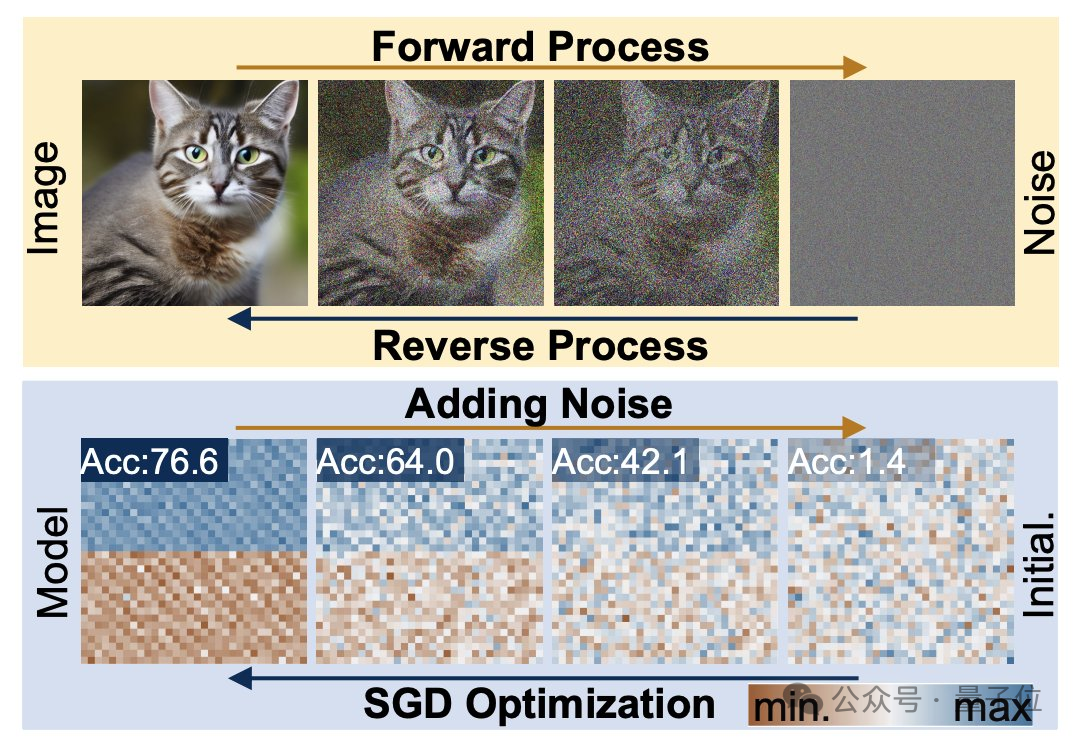
From a structural point of view, p-diff is designed by the research team based on the standard latent diffusion model and combined with the autoencoder.
The researcher first selects a part of the network parameters that have been trained and performed well, and expands them into a one-dimensional vector form.
An autoencoder is then used to extract latent representations from the one-dimensional vector as training data for the diffusion model, which can capture the key features of the original parameters.
During the training process, the researchers let p-diff learn the distribution of parameters through forward and reverse processes. After completion, the diffusion model synthesizes these potential representations from random noise like the process of generating visual information. .
Finally, the newly generated latent representation is restored to network parameters by the decoder corresponding to the encoder and used to build a new model.
The following figure is the parameter distribution of the ResNet-18 model trained from scratch using 3 random seeds through p-diff, showing the differences between different layers and the same layer. distribution pattern among parameters.

To evaluate the quality of the parameters generated by p-diff, the researchers used 3 types of neural networks of two sizes each on 8 data sets. taking the test.
In the table below, the three numbers in each group represent the evaluation results of the original model, the integrated model and the model generated with p-diff.
As can be seen from the results, the performance of the model generated by p-diff is basically close to or even better than the original model trained manually.
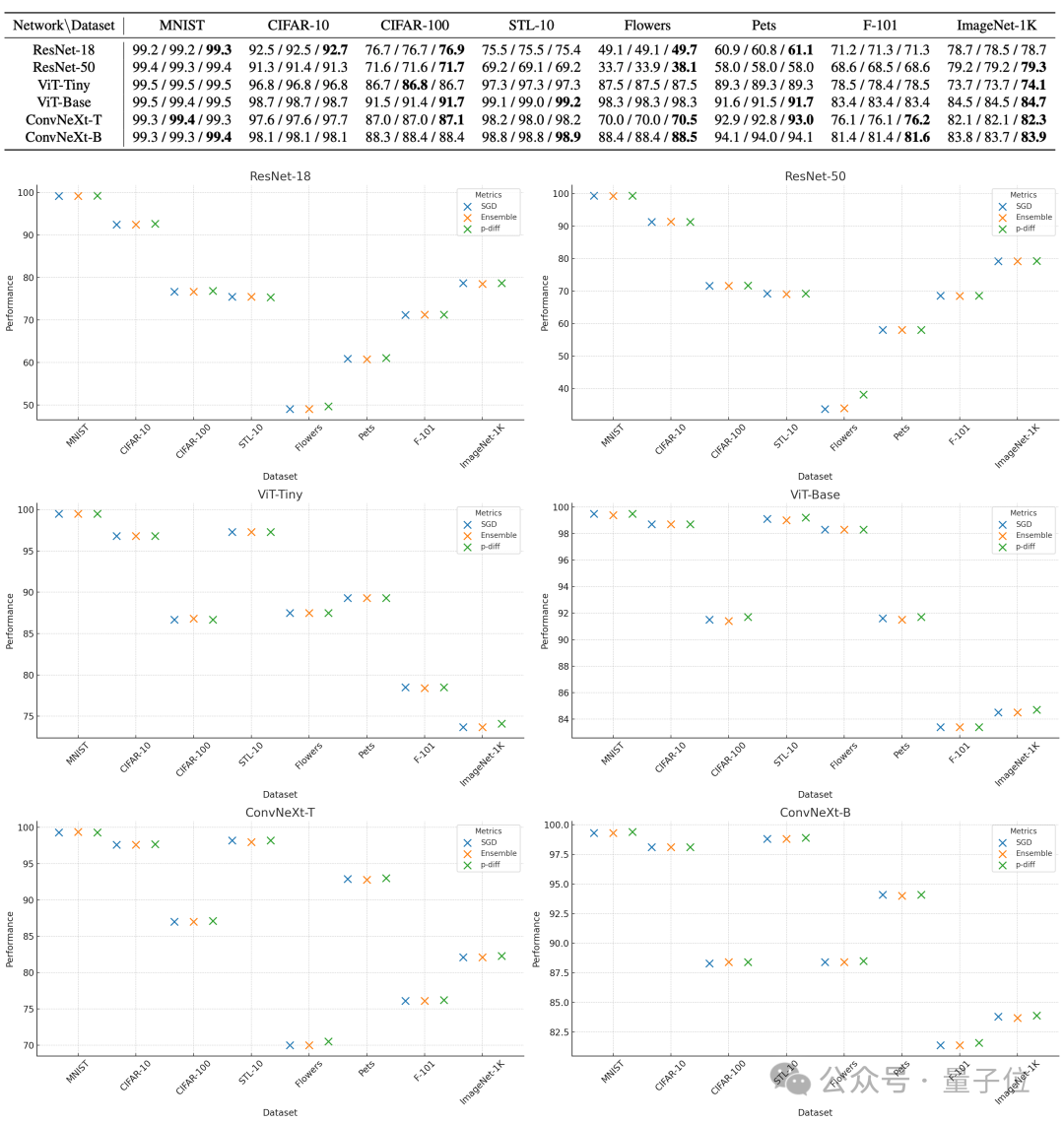
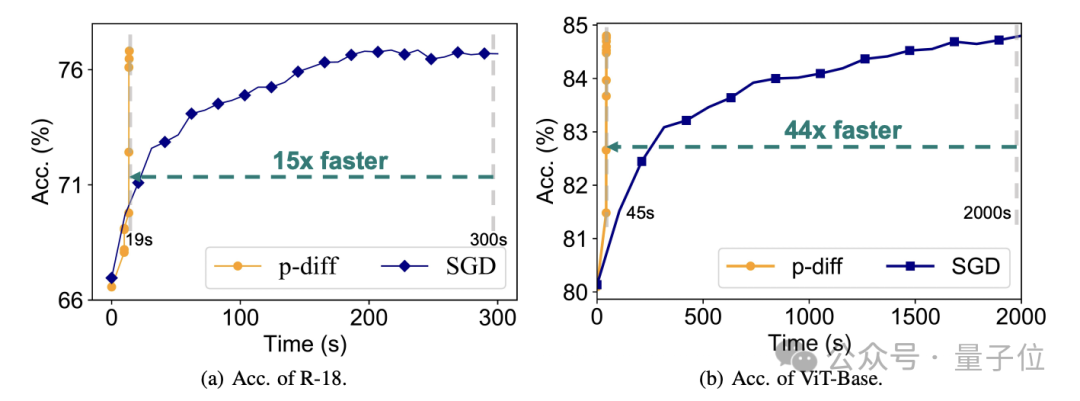
In terms of efficiency, without losing accuracy, p-diff generates ResNet-18 network 15 times faster than traditional training, and generates Vit-Base 44 times faster.
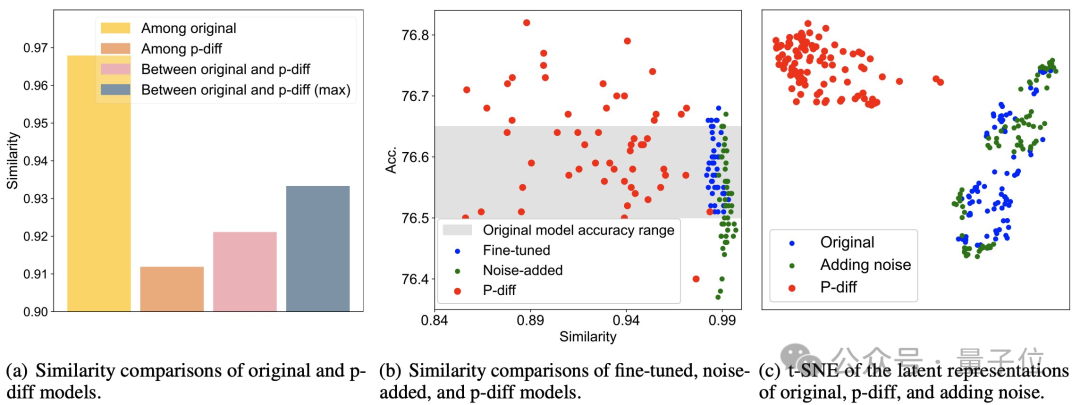
Additional test results demonstrate that the model generated by p-diff is significantly different from the training data.
As can be seen from the figure (a) below, the similarity between the models generated by p-diff is lower than the similarity between the original models, as well as the similarity between p-diff and the original model.
It can be seen from (b) and (c) that compared with fine-tuning and noise addition methods, the similarity of p-diff is also lower.
These results show that p-diff actually generates a new model, rather than just memorizing training samples. It also shows that it has good generalization ability and can generate new models that are different from the training data.
Currently, the code of p-diff has been open sourced. If you are interested, you can check it out on GitHub.
Paper address: https://arxiv.org/abs/2402.13144
GitHub: https ://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
The above is the detailed content of Break into the bottom layer of AI! NUS Youyang's team uses diffusion model to construct neural network parameters, LeCun likes it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
