
 Technology peripherals
AI
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Technology peripherals
AI
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings

OpenAI最近宣布推出他们的最新一代嵌入模型embedding v3,他们声称这是性能最出色的嵌入模型,具备更高的多语言性能。这一批模型被划分为两种类型:规模较小的text-embeddings-3-small和更为强大、体积较大的text-embeddings-3-large。

这些模型的设计和训练方式的信息披露得很少,模型只能通过付费API访问。所以就出现了很多开源的嵌入模型但是这些开源的模型与OpenAI闭源模型相比如何呢?
本文将对这些新模型与开源模型的性能进行实证比较。我们计划建立一个数据检索工作流程,其中关键任务是根据用户的查询,从语料库中找到最相关的文档。
我们的语料库是欧洲人工智能法案,目前正处于验证阶段。这个语料库是全球首个涉及人工智能的法律框架,其独特之处在于拥有24种语言版本。这使得我们能够比较不同语言背景下数据检索的准确性,为人工智能的跨文化应用提供了重要的支持。
我们计划利用多语言文本语料库创建一个自定义合成问题/答案数据集,并使用这个数据集来比较OpenAI和最先进的开源嵌入模型的准确性。我们将分享完整的代码,因为我们的方法可以轻松适应其他数据语料库。
生成自定义Q/ A数据集
首先,我们可以从创建自定义问答(Q/A)数据集开始,这样做的好处在于可以确保数据集不会成为模型训练中的偏差因素,避免类似于MTEB等基准参考中可能出现的情况。此外,通过生成自定义数据集,我们可以根据特定的数据语料库来调整评估过程,这对于类似于检索增强应用程序(RAG)等场景可能非常重要。
我们将按照Llama Index文档中建议的简单流程进行操作。首先,将语料库划分为多个块。接着,针对每个块,利用大型语言模型(LLM)生成一系列合成问题,确保答案在相应的块中。
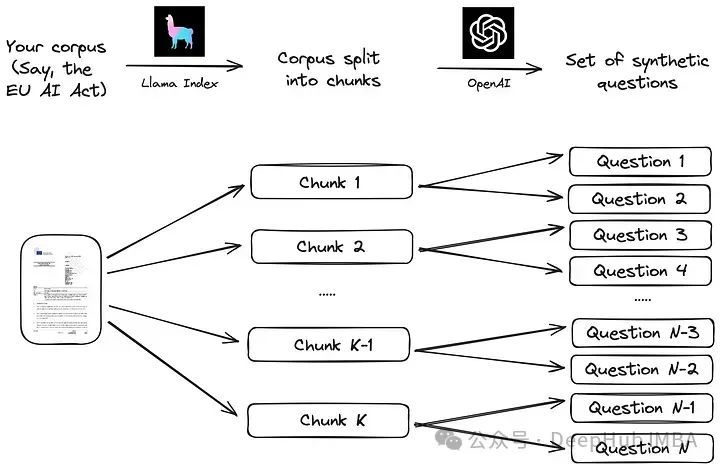
使用Llama Index之类的LLM数据框架实现此策略非常简单,如下面的代码所示。
from llama_index.readers.web import SimpleWebPageReader from llama_index.core.node_parser import SentenceSplitter language = "EN" url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206" documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc]) parser = SentenceSplitter(chunk_size=1000) nodes = parser.get_nodes_from_documents(documents, show_progress=True)
语料库是欧盟人工智能法案的英文版本,使用这个官方URL直接从Web上获取。本文使用2021年4月的草案版本,因为最终版本尚未适用于所有欧洲语言。所以我们选择的这一版可以用其他23种欧盟官方语言中的任何一种语言替换URL中的language,检索不同语言的文本(BG表示保加利亚语,ES表示西班牙语,CS表示捷克语,等等)。

使用SentenceSplitter对象将文档分成每1000个令牌的块。对于英语来说,这会生成大约100个块。然后将每个块作为上下文提供给以下提示(Llama Index库中建议的默认提示):
prompts={} prompts["EN"] = """\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge, generate only questions based on the below query. You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination. The questions should be diverse in nature across the document. Restrict the questions to the context information provided." """这个提示可以生成关于文档块的问题,要为每个数据块生成的问题数量作为参数“num_questions_per_chunk”传递,我们将其设置为2。然后可以通过调用Llama Index库中的generate_qa_embedding_pairs来生成问题:
from llama_index.llms import OpenAI from llama_index.legacy.finetuning import generate_qa_embedding_pairs qa_dataset = generate_qa_embedding_pairs(llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),nodes=nodes,qa_generate_prompt_tmpl = prompts[language],num_questions_per_chunk=2 )我们依靠OpenAI的GPT-3.5-turbo-0125来完成这项任务,结果对象' qa_dataset '包含问题和答案(块)对。作为生成问题的示例,以下是前两个问题的结果(其中“答案”是文本的第一部分):
- What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
- How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
OpenAI嵌入模型
评估函数也是遵循Llama Index文档:首先所有答案(文档块)的嵌入都存储在VectorStoreIndex中,以便有效检索。然后评估函数循环遍历所有查询,检索前k个最相似的文档,并根据MRR (Mean Reciprocal Rank)评估检索的准确性,代码如下:
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):# Get corpus, queries, and relevant documents from the qa_dataset objectcorpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docs # Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddingsnodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]index = VectorStoreIndex(nodes, embed_model=embed_model, insert_batch_size=insert_batch_size)retriever = index.as_retriever(similarity_top_k=top_k) # Prepare to collect evaluation resultseval_results = [] # Iterate over each query in the dataset to evaluate retrieval performancefor query_id, query in tqdm(queries.items()):# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documentsretrieved_nodes = retriever.retrieve(query)retrieved_ids = [node.node.node_id for node in retrieved_nodes] # Check if the expected document was among the retrieved documentsexpected_id = relevant_docs[query_id][0]is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query # Calculate the Mean Reciprocal Rank (MRR) and append to resultsif is_hit:rank = retrieved_ids.index(expected_id) + 1mrr = 1 / rankelse:mrr = 0eval_results.append(mrr) # Return the average MRR across all queries as the final evaluation metricreturn np.average(eval_results)
嵌入模型通过' embed_model '参数传递给评估函数,对于OpenAI模型,该参数是一个用模型名称和模型维度初始化的OpenAIEmbedding对象。
from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions'])
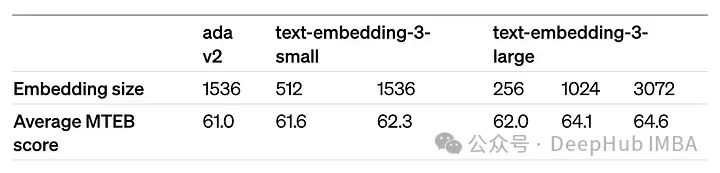
dimensions参数可以缩短嵌入(即从序列的末尾删除一些数字),而不会失去嵌入的概念表示属性。OpenAI在他们的公告中建议,在MTEB基准测试中,嵌入可以缩短到256大小,同时仍然优于未缩短的text-embedding-ada-002嵌入(大小为1536)。
我们在四种不同的嵌入模型上运行评估函数:
两个版本的text-embedding-3-large:一个具有最低可能维度(256),另一个具有最高可能维度(3072)。它们被称为“OAI-large-256”和“OAI-large-3072”。
OAI-small:text-embedding-3-small,维数为1536。
OAI-ada-002:传统的文本嵌入text-embedding-ada-002,维度为1536。
每个模型在四种不同的语言上进行评估:英语(EN),法语(FR),捷克语(CS)和匈牙利语(HU),分别涵盖日耳曼语,罗曼语,斯拉夫语和乌拉尔语的例子。
embeddings_model_spec = { } embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256} embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072} embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536} embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all languages for language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) # Loop through all modelsfor model_name, model_spec in embeddings_model_spec.items(): # Get modelembed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions']) # Assess embedding score (in terms of MRR)score = evaluate(qa_dataset, embed_model) results.append([language, model_name, score]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])MRR精度如下:
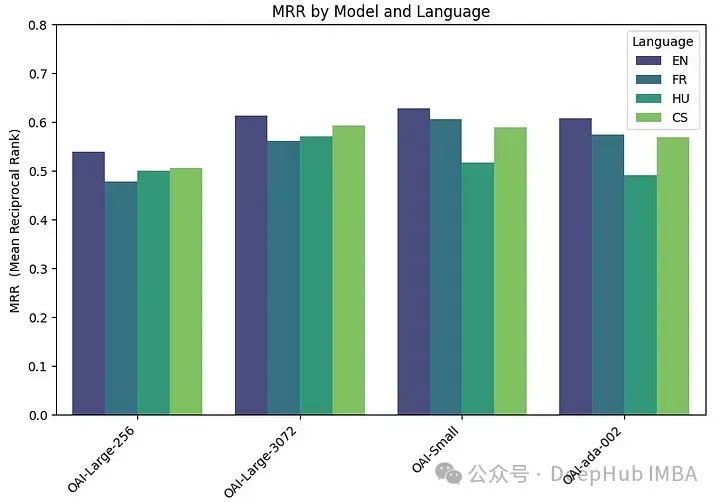
嵌入尺寸越大,性能越好。
开源嵌入模型
围绕嵌入的开源研究也是非常活跃的,Hugging Face 的 MTEB leaderboard会经常发布最新的嵌入模型。
为了在本文中进行比较,我们选择了一组最近发表的四个嵌入模型(2024)。选择的标准是他们在MTEB排行榜上的平均得分和他们处理多语言数据的能力。所选模型的主要特性摘要如下。

e5-mistral-7b-instruct:微软的这个E5嵌入模型是从Mistral-7B-v0.1初始化的,并在多语言混合数据集上进行微调。模型在MTEB排行榜上表现最好,但也是迄今为止最大的(14GB)。
multilingual-e5-large-instruct(ML-E5-large):微软的另一个E5模型,可以更好地处理多语言数据。它从xlm-roberta-large初始化,并在多语言数据集的混合上进行训练。它比E5-Mistral小得多(10倍),上下文大小也小得多(514)。
BGE-M3:该模型由北京人工智能研究院设计,是他们最先进的多语言数据嵌入模型,支持100多种工作语言。截至2024年2月22日,它还没有进入MTEB排行榜。
nomic-embed-text-v1 (Nomic- embed):该模型由Nomic设计,其性能优于OpenAI Ada-002和text-embedding-3-small,而且大小仅为0.55GB。该模型是第一个完全可复制和可审计的(开放数据和开源训练代码)的模型。
用于评估这些开源模型的代码类似于用于OpenAI模型的代码。主要的变化在于模型参数:
embeddings_model_spec = { } embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token', 'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}} embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all models for model_name, model_spec in embeddings_model_spec.items(): print("Processing model : "+str(model_spec)) # Get modeltokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs']) if model_name=="Nomic-Embed":embed_model.to('cuda') # Loop through all languagesfor language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) start_time_assessment=time.time() # Assess embedding score (in terms of hit rate at k=5)score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type']) # Get duration of score assessmentduration_assessment = time.time()-start_time_assessment results.append([language, model_name, score, duration_assessment]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])The results are as follows:
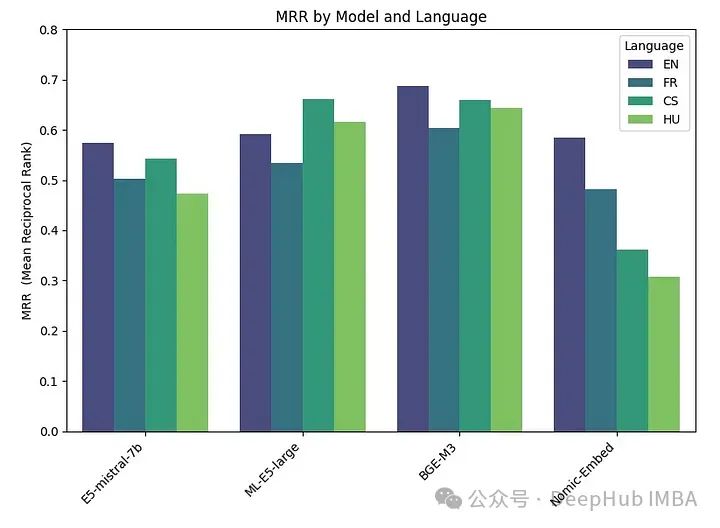
BGE-M3 performed the best, followed by ML-E5-Large, E5-mistral- 7b and Nomic-Embed. The BGE-M3 model has not yet been benchmarked on the MTEB rankings, and our results indicate that it may rank higher than other models. Although BGE-M3 is optimized for multilingual data, it also performs better in English than other models.
Because open source models generally need to be run locally, we also deliberately recorded the processing time of each embedded model.
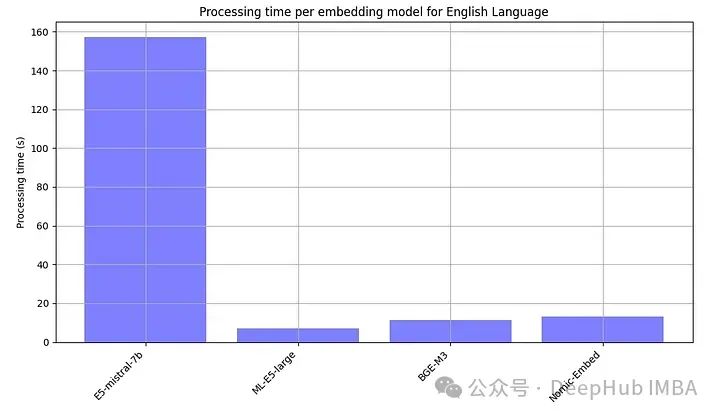
E5-mistral-7b is more than 10 times larger than other models, so the slowest is normal
Summary
We summarize all the results
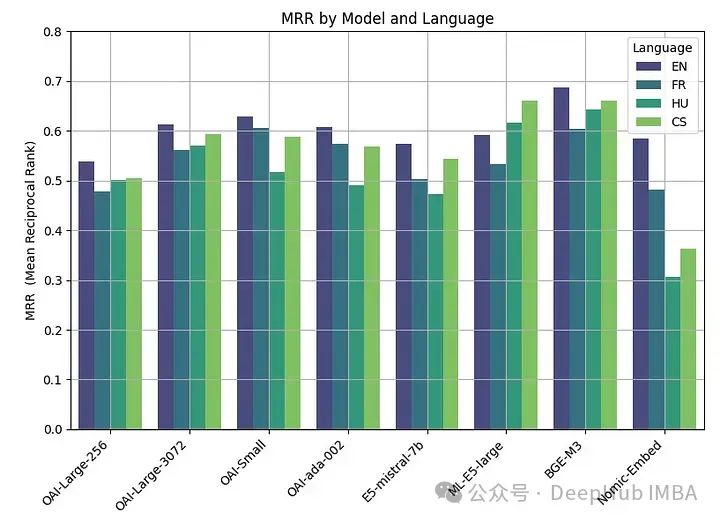
We obtained it using the open source model For the best performance, the BGE-M3 model performed the best. This model has the same context length (8K) as the OpenAI model and is 2.2GB in size.
The performance of OpenAI's large(3072), small and ada models are very similar. Reducing the embedding size of large (256) results in performance degradation and is not as good as ada as OpenAI says.
Almost all models (except ML-E5-large) perform best in English. In languages such as Czech and Hungarian, there are significant differences in performance, possibly because there is less data to train on.
Should we pay to subscribe to OpenAI, or host an open source embedded model?
OpenAI’s recent price adjustment makes their API more affordable , now costs $0.13 per million tokens. If you process a million queries per month (assuming each query involves about 1K tokens), the cost is about $130. Therefore, you can choose whether to host the open source embedding model based on actual needs.
Of course cost-effectiveness is not the only consideration. Other factors such as latency, privacy, and control over data processing workflows may also need to be considered. The open source model offers the advantages of complete data control, enhanced privacy and customization.
Speaking of latency, OpenAI’s API also has latency issues, which sometimes results in extended response times, so sometimes OpenAI’s API is not necessarily the fastest choice.
In short, choosing between an open source model and a proprietary solution like OpenAI is not a simple answer. Open source embedding offers a great option that combines performance with greater control over your data. And OpenAI's products may still appeal to those who prioritize convenience, especially if privacy concerns are secondary.
Code of this article: https://github.com/Yannael/multilingual-embeddings
The above is the detailed content of Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
