
 Technology peripherals
AI
Google's 10M context window is killing RAG? Is Gemini underrated after being stolen away from the limelight by Sora?
Technology peripherals
AI
Google's 10M context window is killing RAG? Is Gemini underrated after being stolen away from the limelight by Sora?
Google's 10M context window is killing RAG? Is Gemini underrated after being stolen away from the limelight by Sora?

To be said to be the most depressing company recently, Google must be one: its own Gemini 1.5 Just after it was released, it was stolen by OpenAI's Sora, which can be called the "Wang Feng" in the AI industry.
Specifically, what Google launched this time is the first version of Gemini 1.5 for early testing-Gemini 1.5 Pro. It is a medium-sized multimodal model (across text, video, audio) with similar performance levels to Google’s largest model to date, 1.0 Ultra, and introduces groundbreaking experimental features in long-context understanding. It can stably handle up to 1 million tokens (equivalent to 1 hour of video, 11 hours of audio, more than 30,000 lines of code, or 700,000 words), with a limit of 10 million tokens (equivalent to the "Lord of the Rings" trilogy), Set a record for the longest context window.
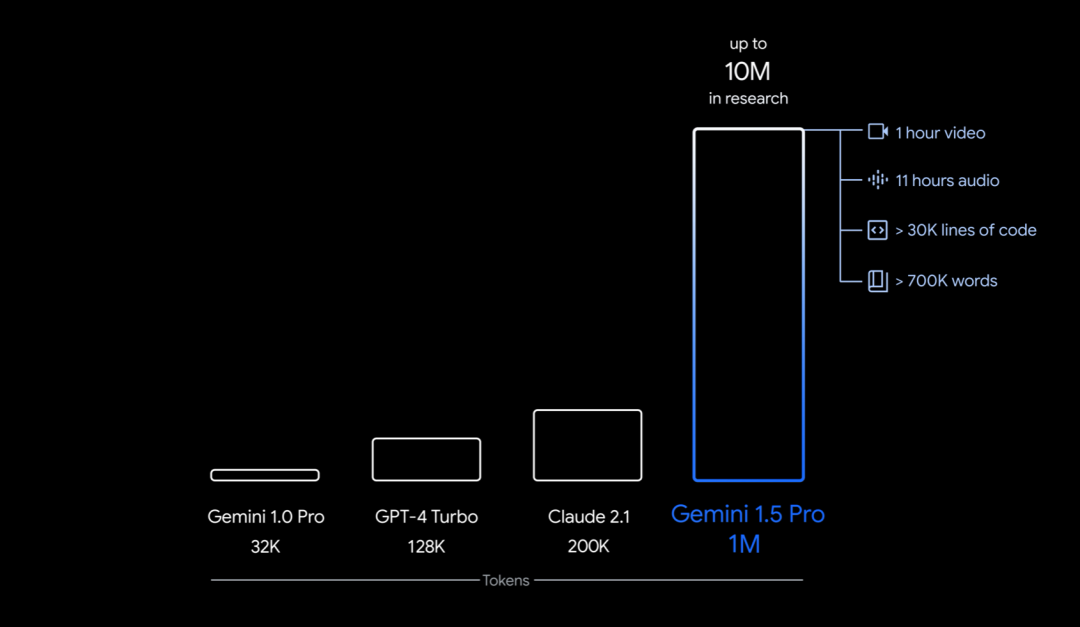
Additionally, it can be learned with just a 500-page grammar book, 2,000 bilingual entries, and 400 additional parallel sentences The translation of a small language (there is no relevant information on the Internet) has reached a level close to human learners in terms of translation.
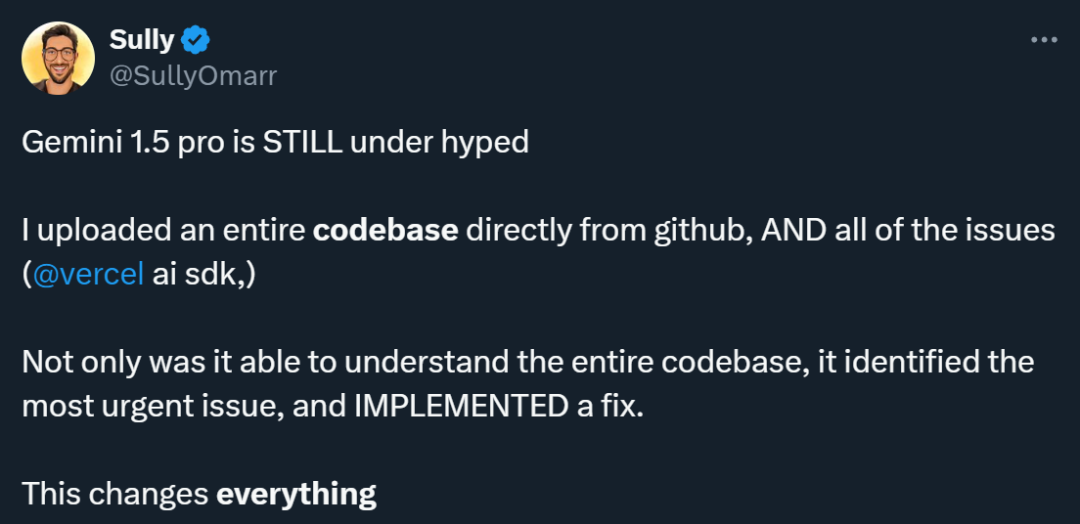
Many people who have used the Gemini 1.5 Pro consider this model to be underrated. Someone conducted an experiment and input the complete code base and related issues downloaded from Github into Gemini 1.5 Pro. The results were surprising: not only did it understand the entire code base, but it was also able to identify the most urgent issues and fix them. .
In another code-related test, Gemini 1.5 Pro demonstrated excellent search capabilities, being able to quickly find in the code base Most relevant example. In addition, it demonstrates strong understanding and is able to accurately find the code that controls animations and provide personalized code suggestions. Likewise, Gemini 1.5 Pro also demonstrated excellent cross-mode capabilities, being able to pinpoint demo content through screenshots and providing guidance for editing image code.

Such a model should attract everyone's attention. Moreover, it is worth noting that the ability of Gemini 1.5 Pro to handle ultra-long contexts has also made many researchers start to think, is the traditional RAG method still necessary?
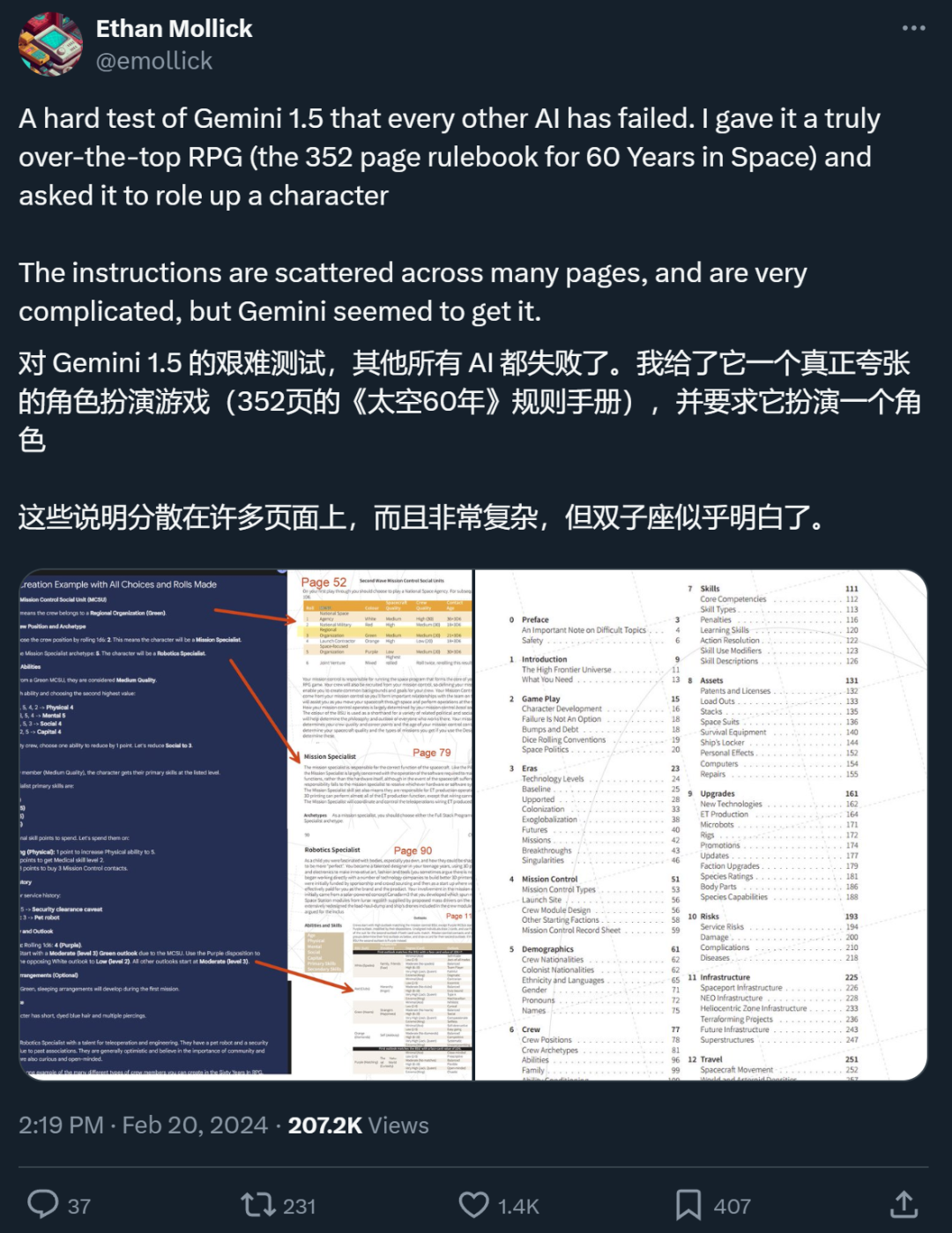
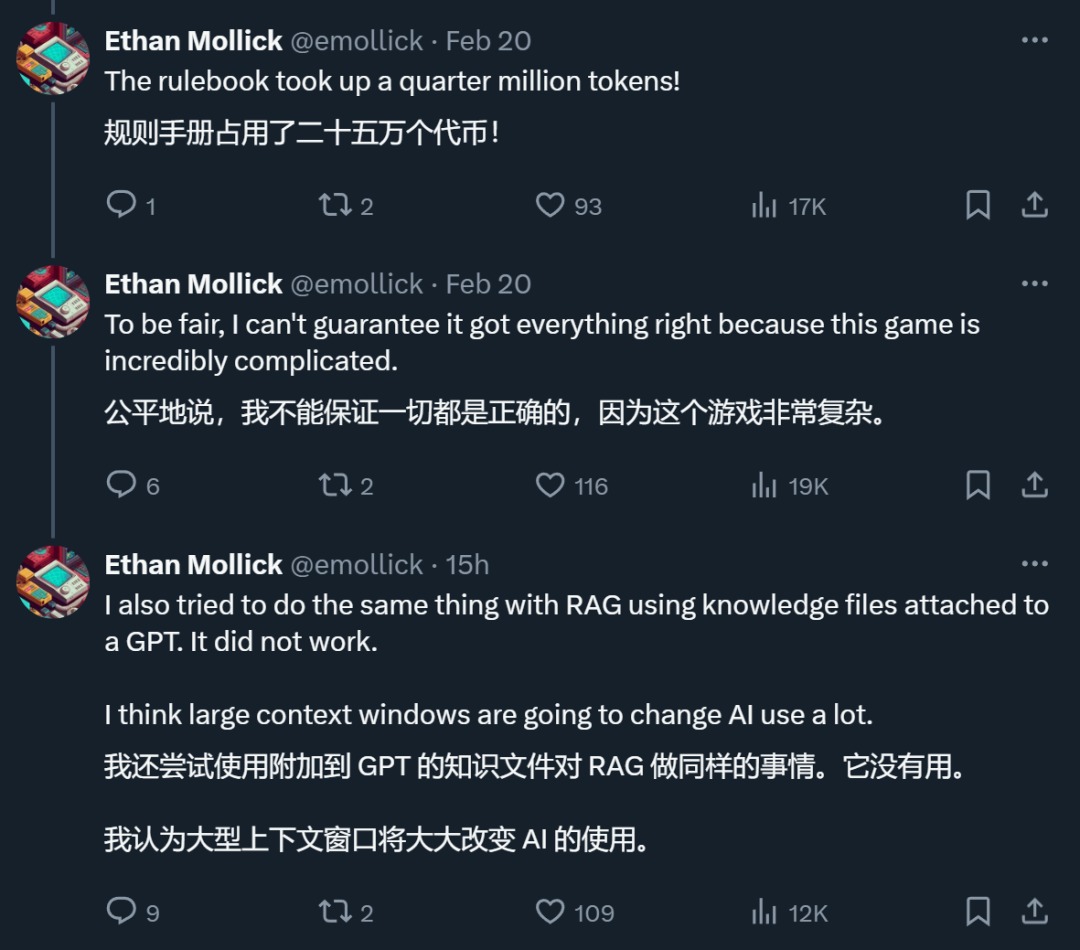
An X netizen said that in a test he conducted, Gemini that supports ultra-long context The 1.5 Pro does indeed do what the RAG cannot.
RAG is going to be killed by the long context model?
"A model with a 10 million token context window makes most existing RAG frameworks unnecessary, that is, 10 million token context kills RAG ," Fu Yao, a doctoral student at the University of Edinburgh, wrote in a post evaluating Gemini 1.5 Pro.

 ##
##
RAG is the abbreviation of "Retrieval-Augmented Generation", which can be translated into Chinese as "Retrieval Enhanced Generation". RAG typically consists of two stages: retrieving context-relevant information and using the retrieved knowledge to guide the generation process. For example, as an employee, you can directly ask the big model, "What are the penalties for lateness in our company?" Without reading the "Employee Handbook", the big model has no way to answer. However, with the help of the RAG method, we can first let a search model search for the most relevant answers in the "Employee Handbook", and then send your question and the relevant answers it found to the generation model, allowing the large model to generate Answer. This solves the problem that the context window of many previous large models was not large enough (for example, it could not accommodate the "Employee Handbook"), but RAGfangfa was lacking in capturing the subtle connections between contexts.
Fu Yao believes that if a model can directly process the contextual information of 10 million tokens, there is no need to go through additional retrieval steps to find and integrate relevant information. Users can put all the data they need directly into the model as context and then interact with the model as usual. "The large language model itself is already a very powerful searcher, so why bother to build a weak searcher and spend a lot of engineering energy on chunking, embedding, indexing, etc.?" he continued to write.

#However, Fu Yao’s views have been refuted by many researchers. He said that many of the objections are reasonable, and he also systematically sorted out these opinions:
1. Cost issue: Critics point out that RAG is cheaper than the long context model. Fu Yao acknowledged this, but he compared the development history of different technologies, pointing out that although low-cost models (such as BERT-small or n-gram) are indeed cheap, in the history of AI development, the cost of advanced technologies will eventually decrease. His point is to pursue the performance of smart models first, and then reduce costs through technological advancement, because it is much easier to make smart models cheap than to make cheap models smart.
#2. Integration of retrieval and reasoning: Fu Yao emphasized that the long context model can mix retrieval and reasoning during the entire decoding process, while RAG only Retrieve at start. The long context model can be retrieved at each layer and each token, which means that the model can dynamically determine the information to be retrieved based on the results of preliminary inference, achieving closer integration of retrieval and inference.
3. Number of supported tokens: Although the number of tokens supported by RAG has reached trillions, the long context model currently supports millions. Fu Yao believes that in natural distribution Among the input documents, most of the cases that need to be retrieved are below the million level. He cited legal document analysis and learning machine learning as examples, and believed that the input volume in these cases would not exceed millions.

#4. Caching mechanism: Regarding the problem that the long context model requires re-entering the entire document, Fu Yao pointed out that there is a so-called KV (key value) cache mechanism, complex cache and memory hierarchies can be designed so that input only needs to be read once, and subsequent queries can reuse the KV cache. He also mentioned that although KV caches can be large, he is optimistic that efficient KV cache compression algorithms will emerge in the future.
5. The need to call search engines: He admitted that in the short term, calling search engines for retrieval is still necessary. However, he proposed a bold idea, which is to let the language model directly access the entire Google search index to absorb all the information, which reflects the great imagination of the future potential of AI technology.
#6. Performance issues: Fu Yao admitted that the current Gemini 1.5 is slow when processing 1M context, but he is optimistic about speed up and believes that the speed of long context model will be greatly improved in the future. Improvement, may eventually reach speeds comparable to RAG.

In addition to Fu Yao, many other researchers have also expressed their views on the prospects of RAG on the X platform, such as AI blogger @elvis.
Overall, he does not think that the long context model can replace RAG. The reasons include:
1. Specific data types Challenge: @elvis presented a scenario where the data has a complex structure, changes regularly, and has a significant time dimension (e.g. code edits/changes and web logs). This type of data may be connected to historical data points, and possibly more data points in the future. @elvis believes that today's long context language models alone cannot handle use cases that rely on such data because the data may be too complex for LLM and the current maximum context window is not feasible for such data. When dealing with this kind of data, you may end up needing some clever retrieval mechanism.
2. Processing of dynamic information: Today’s long context LLM performs well in processing static information (such as books, video recordings, PDFs, etc.), but it is difficult to process highly dynamic information. and knowledge have not yet been tested in practice. @elvis believes that while we will make progress towards solving some challenges (such as "lost in the middle") and dealing with more complex structured and dynamic data, we still have a long way to go.

3. @elvis proposed that in order to solve these types of problems, RAG and long context LLM can be combined to build a powerful system. Retrieve and analyze critical historical information effectively and efficiently. He stressed that even this may not be enough in many cases. Especially because large amounts of data can change rapidly, AI-based agents add even more complexity. @elvis thinks that for complex use cases it will most likely be a combination of these ideas rather than a general purpose or long context LLM replacing everything.
4. Demand for different types of LLM: @elvis pointed out that not all data is static, and a lot of data is dynamic. When considering these applications, keep in mind the three Vs of big data: velocity, volume, and variety. @elvis learned this lesson through experience working at a search company. He believes that different types of LLMs will help solve different types of problems, and we need to move away from the idea that one LLM will rule them all.

@elvis ended by quoting Oriol Vinyals (Vice President of Research at Google DeepMind), pointing out that even now we can handle 1 million or more tokens context, the era of RAG is far from over. RAG actually has some very nice features. Not only can these properties be enhanced by long context models, but long context models can also be enhanced by RAG. RAG allows us to find relevant information, but the way the model accesses this information may become too restricted due to data compression. The long context model can help bridge this gap, somewhat similar to how L1/L2 cache and main memory work together in modern CPUs. In this collaborative model, cache and main memory each play different roles but complement each other, thereby increasing processing speed and efficiency. Similarly, the combined use of RAG and long context can achieve more flexible and efficient information retrieval and generation, making full use of their respective advantages to handle complex data and tasks.

It seems that "whether the era of RAG is coming to an end" has not yet been determined. But many people say that the Gemini 1.5 Pro is really underrated as an extra-long context window model. @elvis also gave his test results.
##Gemini 1.5 Pro preliminary evaluation report
Long document analysis capabilities
To demonstrate Gemini 1.5 Pro's ability to process and analyze documents, @elvis started with a very basic question-answering task. He uploaded a PDF file and asked a simple question: What is this paper about?
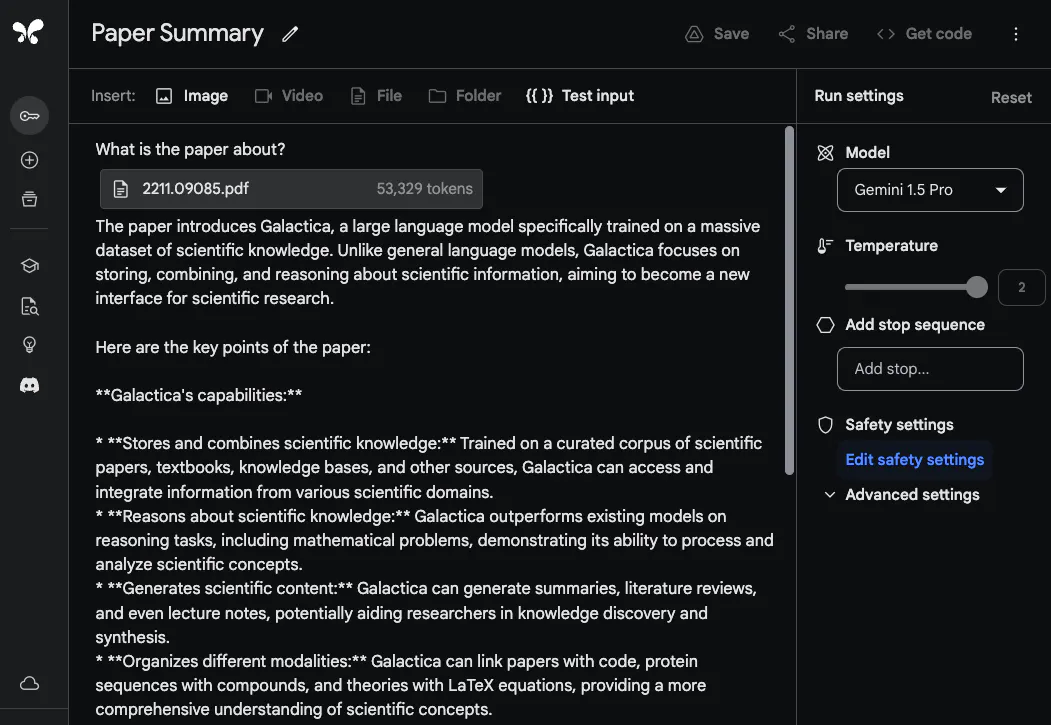
The model's response is accurate and concise as it provides an acceptable summary of the Galactica paper. The example above uses free-form prompts in Google AI Studio, but you can also use chat format to interact with uploaded PDFs. This is a very useful feature if you have a lot of questions that you would like answered from the documentation provided.
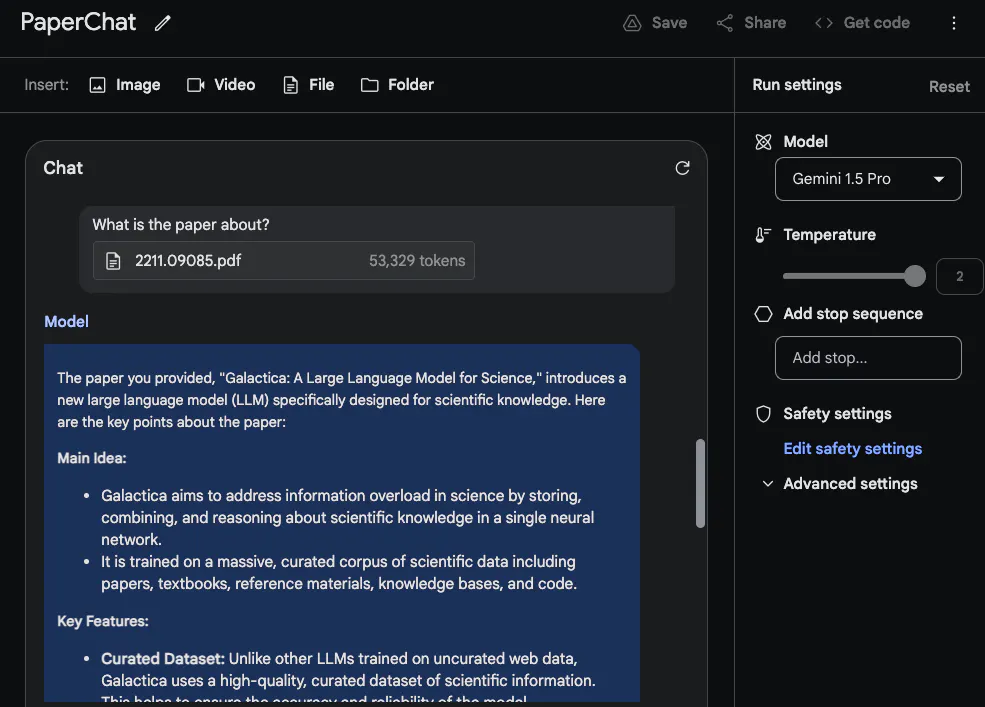
To take full advantage of the long context window, @elvis next uploaded two PDFs for testing and asked a question spanning both PDFs .
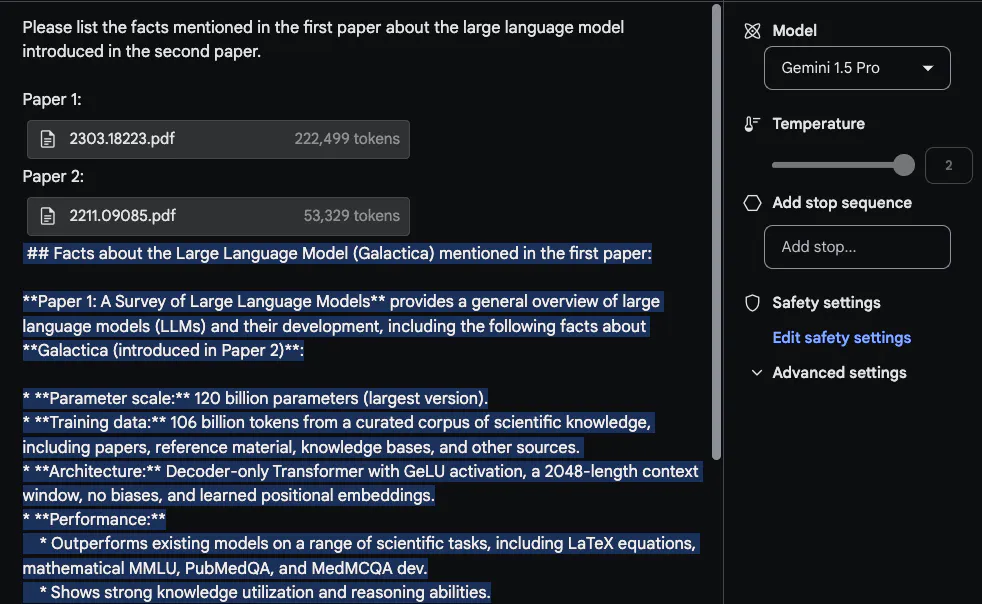
The response given by Gemini 1.5 Pro is reasonable. Interestingly, the information extracted from the first paper (a review paper on LLM) comes from a table. The "architecture" information also looks correct. However, the "Performance" part does not belong here because it was not included in the first paper. In this task, it is important to put the prompt "Please list the facts mentioned in the first paper about the large language model introduced in the second paper" at the top and label the paper, such as "Paper 1" and "Paper 2". Another related follow-up task to this lab is to write a related work by uploading a set of papers and instructions on how to summarize them. Another interesting task asked the model to include newer LLM papers in a review.
Video Understanding
##Gemini 1.5 Pro is trained on multi-modal data from the start. @elvis tested some prompts using Andrej Karpathy’s recent LLM lecture video:
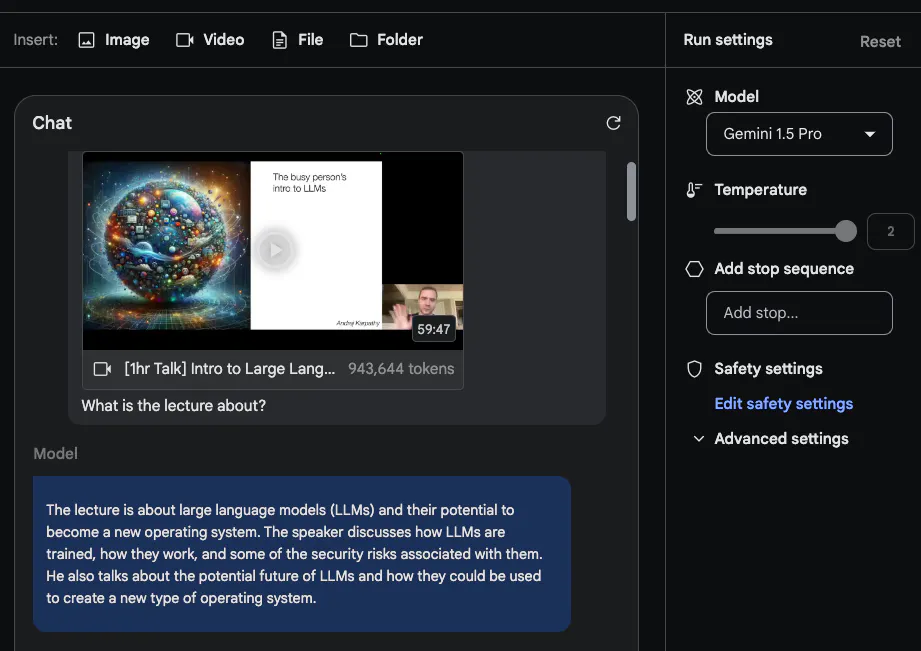
The second task he asked the model to complete was to provide a concise A brief outline of the lecture (one page in length). The answer is as follows (edited for brevity):

Gemini 1.5 Pro The summary given by Gemini 1.5 Pro is very concise and gives a good summary of the lecture content and Points.
When specific details are important, be aware that models may sometimes "hallucinate" or retrieve incorrect information for various reasons. For example, when the model is asked the following question: "What are the FLOPs reported for Llama 2 in the lecture?", its answer is "The lecture reports that training Llama 2 70B requires approximately 1 trillion FLOPs", which is inaccurate . The correct answer should be "~1e24 FLOPs". The technical report contains numerous examples of where these long-context models stumble when asked specific questions about videos.
The next task is to extract table information from the video. Test results show that the model is able to generate tables with some details correct and some incorrect. For example, the columns of the table are correct, but the label for one of the rows is wrong (i.e. Concept Resolution should be Coref Resolution). Testers tested some of these extraction tasks with other tables and other different elements (such as text boxes) and found similar inconsistencies.
One interesting example documented in the technical report is the model’s ability to retrieve details from videos based on specific scenes or timestamps. In the first example, the tester asks the model where a certain part begins. The model answered correctly.
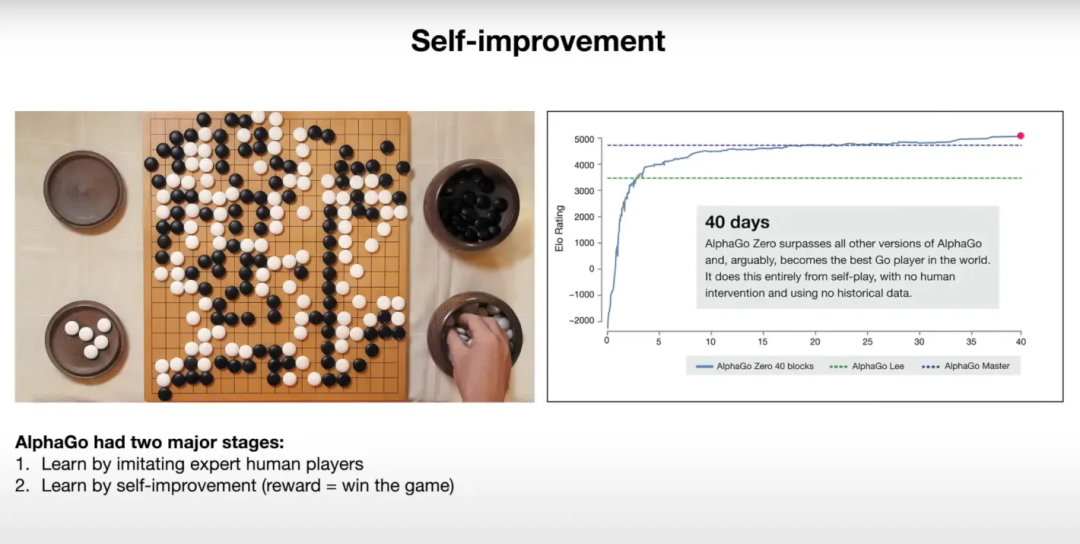
In the next example, he asked the model to explain a diagram on a slide. The model seems to make good use of the information provided to explain the results in the graph.

Here are snapshots of the corresponding slides:
@elvis said that he has begun the second round of testing, and interested students can go to the X platform to watch.
The above is the detailed content of Google's 10M context window is killing RAG? Is Gemini underrated after being stolen away from the limelight by Sora?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
This article describes how to configure firewall rules using iptables or ufw in Debian systems and use Syslog to record firewall activities. Method 1: Use iptablesiptables is a powerful command line firewall tool in Debian system. View existing rules: Use the following command to view the current iptables rules: sudoiptables-L-n-v allows specific IP access: For example, allow IP address 192.168.1.100 to access port 80: sudoiptables-AINPUT-ptcp--dport80-s192.16
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
This guide will guide you to learn how to use Syslog in Debian systems. Syslog is a key service in Linux systems for logging system and application log messages. It helps administrators monitor and analyze system activity to quickly identify and resolve problems. 1. Basic knowledge of Syslog The core functions of Syslog include: centrally collecting and managing log messages; supporting multiple log output formats and target locations (such as files or networks); providing real-time log viewing and filtering functions. 2. Install and configure Syslog (using Rsyslog) The Debian system uses Rsyslog by default. You can install it with the following command: sudoaptupdatesud
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
