
 Technology peripherals
AI
This article is enough for you to read about autonomous driving and trajectory prediction!
Technology peripherals
AI
This article is enough for you to read about autonomous driving and trajectory prediction!
This article is enough for you to read about autonomous driving and trajectory prediction!

Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction!
Introduction related knowledge
1. Is there an entry order for the preview papers?
A: Let’s first look at the sequential network, graph neural network and Evaluation in survey, problem formulation, and deep learning-based methods.
2. Is behavior prediction trajectory prediction?
Coupling and behavior are not the same. Coupling usually refers to the actions that the target vehicle may take, such as changing lanes, parking, and overtaking. , accelerate, turn left, turn right or go straight. The trajectory refers to a specific future location point with time information.
3. Among the data components mentioned in the Argoverse data set, what do labels and targets refer to? Does labels refer to the ground truth within the time period to be predicted?
In the table on the right, the OBJECT_TYPE column usually represents the self-driving vehicle itself. The data set usually specifies one or more obstacles to be predicted for each scene, and these targets to be predicted are called targets or focal agents. Some datasets also provide semantic labels for each obstacle, such as vehicles, pedestrians, or bicycles.
Q2: Are the data forms of vehicles and pedestrians the same? I mean, for example, one point cloud point represents a pedestrian, and dozens of points represent vehicles?
A: This kind of trajectory data set actually gives the xyz coordinates of the center point of the object, both for pedestrians and vehicles.
Q3: The argo1 and argo2 data sets are only specified. A predicted obstacle, right? How to use these two data sets when doing multi-agent prediction
argo1 only specifies one obstacle, while argo2 may specify as many as twenty. However, even if only one obstacle is specified, this does not affect your model's ability to predict multiple obstacles.
4. Path planning generally considers low-speed and static obstacles. What is the role of combining trajectory prediction? ? Key snapshot?
A: "Predict" the self-vehicle trajectory as the self-vehicle planning trajectory, you can refer to uniad
5. Trajectory prediction has high requirements for the vehicle dynamics model ? Do you just need mathematics and automotive theory to establish an accurate vehicle dynamics model?
A: nn network is basically not required, rule based requires some knowledge
6. A vague novice, where should I start to expand? Knowledge (not able to write code yet)
A: First read the review and sort out the mind map, such as "Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research" Directions" for this review, please read the original English text
7. What is the relationship between prediction and decision-making? Why do I feel that prediction is not that important?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
8. At present, for leading companies, do general predictions belong to the large perception module or the large regulation module?
A: Prediction is based on the trajectory of other cars, and control is based on the trajectory of the car. The two trajectories also affect each other, so prediction is generally based on regulation.
Q: Some public information, such as Xiaopeng’s perception xnet, will produce prediction trajectories at the same time. At this time, I feel that the prediction work is placed under the perception module, or that both modules have their own predictions. Modules, different goals?
A: They will affect each other, so in some places prediction and decision-making are a group. For example, if the trajectory planned by your own car is intended to squeeze other cars, other cars will generally give way. Therefore, some work will regard the planning of the own vehicle as part of the input of other vehicle models. You can refer to M2I (M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction). This article has similar ideas. You can learn about this lane of PiP: Planning-informed Trajectory Prediction for Autonomous Driving
9.argoverse How do you get the center line map at the intersection where there are no lane lines?
A: Manually marked
10. If you use trajectory prediction to write a paper, where can you get it? Can the code of this paper be used as a baseline?
A: hivt can be used as a baseline, and many people use it
11. Nowadays, trajectory prediction basically relies on maps. If you change In a new map environment, will the original model no longer apply and need to be retrained?
A: It has a certain generalization ability, and the effect is not bad without retraining.
12. For multi-modal output, choose the best trajectory Is it time to choose based on the highest probability value?
A(stu): 选择结果最好的Q2:结果最好是根据什么来判定呢?是根据概率值大小还是根据和gt的距离A: 实际在没有ground truth的情况下,你要取“最好”的轨迹,那只能选择相信预测概率值最大的那条轨迹了Q3: 那有gt的情况下,选择最好轨迹的时候,根据和gt之间的end point或者average都可以是吗A: 嗯嗯,看指标咋定义
Trajectory prediction basic module
1. How to use HD-Map in the Argoverse data set? Can it be combined with motion forecast as input to build a driving scene graph, heterogeneous graph How to understand?
A: It’s all covered in this course. You can refer to Chapter 2, which will also be covered in Chapter 4. The difference between heterogeneous graphs and isomorphic graphs: the types of nodes in isomorphic graphs There is only one kind of connection between one node and another node. For example, in a social network, it can be imagined that node only has one type of "people" and edge only has one type of connection "knowledge". And people either know each other or they don't. But it is also possible to segment people, likes, and tweets. Then people may be connected through acquaintance, people may be connected through likes on tweets, and people may also be connected through likes on a tweet (meta path). Here, the diverse expression of nodes and relationships between nodes requires the introduction of heterogeneous graphs. In heterogeneous graphs, there are many types of nodes. There are also many types of connection relationships (edges) between nodes, and there are even more types of combinations of these connection relationships (meta-path). The relationships between these nodes are classified into different degrees of severity, and different connection relationships are also classified into different degrees of severity.
2.A-A interaction considers which vehicles interact with the predicted vehicles?
A: You can select cars within a certain radius, or you can consider cars with K nearest neighbors. You can even come up with a more advanced heuristic neighbor screening strategy yourself, and it is even possible to let the model learn it by itself. Are the two cars coming out neighbors?
Q2: Let’s consider a certain range. Is there any principle for selecting the radius? In addition, at which time step did the selected vehicles occur?
A: It is difficult to have a standard answer to the choice of radius. This is essentially asking how much remote information the model needs when making predictions. It is a bit For the second question when choosing the size of the convolution kernel, my personal rule is that if you want to model the interaction between objects at which time, you should select neighbors based on the relative position of the object at that time
Q3: In this case, do we need to model the historical time domain? The surrounding vehicles within a certain range will also change at different time steps, or should we only consider the surrounding vehicle information at the current moment?
A: Either way, it depends on how you design the model
3. What are the flaws in the prediction part of the teacher's uniad end-to-end model?
A: Just look at it. The operation of motion former is relatively conventional. You will see similar SA and CA in many papers. Nowadays, many sota models are relatively heavy. For example, the decoder will have a cyclic refine
A2: What is done is marginal prediction rather than joint prediction; 2. Prediction and planning are done separately, without explicitly considering ego and Interactive game of surrounding agents; 3. Scene-centric representation is used, without considering symmetry, and the effect is inevitable
Q2: What is marginal prediction
A: For details, please refer to scene transformer
Q3: Regarding the third point, scene centric does not consider symmetry. How to understand it?
A: It is recommended to look at HiVT, QCNet, MTR. Of course, symmetry is important for end-to-end models. The design is not easy to do either
A2: It can be understood that the input is scene data, but in the network it will be modeled to look at the surrounding scenes with each target as the central perspective, so that you can In the forward, we get the coding of each target centered on itself, and then we can consider the interaction between these codes
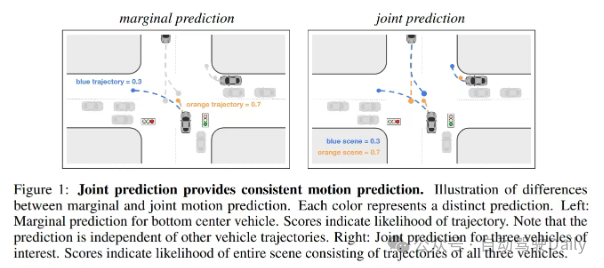
4. What is agent-based? center?
A: Each agent has its own local region, and the local region is centered on this agent.
5. Are yaw and heading mixed in trajectory prediction?
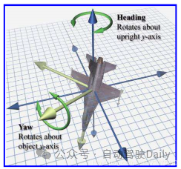
A: It can be understood as the direction of the front of the car
6.What does the has_traffic_control attribute in the argument map mean?
A: Actually, I don’t know if I understand it correctly. I guess it refers to whether a certain lane is affected by traffic lights/stop signs/speed limit signs, etc.
7. What are the advantages and disadvantages of Laplace loss and huber loss for trajectory prediction? If I only predict one lane line
A: Try both, whichever one works better There are advantages. For Laplace loss to be effective, there are still some details that need to be paid attention to
Q2: Does it mean that the parameters need to be adjusted?
A: Compared with L1 loss, Laplace loss actually predicts one more scale parameter
Q3: Yes, but I don’t know what use this is if it only predicts one trajectory. It feels like redundancy. I understand it as uncertainty. I don’t know if it is correct
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
11. Is there any way to judge the smoothness of the score? If you must do it
A: This requires you to enter a flowing input such as 0-19 and 1-20 The frames are then compared with the square of the difference in scores of the corresponding trajectories between the two frames, and statistics are enough.
Q2: What indicators does Mr. Thomas recommend? I currently use first-order derivatives and second-order derivatives. But it seems not very obvious. Most of the first-order derivatives and second-order derivatives are concentrated near 0.
A: I feel that the squared difference of the scores of the corresponding trajectories of consecutive frames is enough. For example, if you have n consecutive inputs, sum them up and divide by n. But the scene changes in real time, and the score should change suddenly when there is an interaction or when going from a non-intersection to an intersection.
12. Isn’t the trajectory in hivt scaled, like ×0.01 10? . The distribution is as close to 0 as possible. I just use some methods when I see them, and I don’t use some methods. How to define the trade-off?
A: Just standardize the data. It may be somewhat useful, but probably not much
13. Why are the category attributes of the map in HiVT added to the numerical attributes after embedding, instead of concat?
A: There is not much difference between addition and concat, but for the fusion of category embedding and numerical embedding, they are actually completely equivalent
Q2: How should we understand complete equivalence?
A: Concating the two and then passing through a linear layer is actually equivalent to embedding the value through a linear layer and embedding the category through a linear layer, and then adding the two. There is actually no point in embedding the category through a linear layer. In theory, this linear layer can be integrated with the parameters in nn.Embeddding
14. As a user, you may be more concerned about HiVT What are the minimum hardware requirements for actual deployment?
A: I don’t know, but according to the information I learned, I don’t know whether NV or which car manufacturer uses HiVT to predict pedestrians, so the actual deployment is definitely feasible
15. Is there anything special about predictions based on occupation network? Do you have any paper recommendations?
A: Among the current future prediction solutions based on occupation, the most promising one should be this one: https://arxiv.org/abs/2308.01471
16. Are there any recommended papers considering prediction of planning trajectories? Is it to consider the planned trajectory of the own vehicle when predicting other obstacles?
A: This potentially public data set is difficult and generally does not provide the planned trajectory of your own vehicle. In ancient times, there was an article called PiP, Hong Kong Ke Haoran Song. I feel that articles about conditional prediction can be considered what you want, such as M2I
17. Are there any simulation projects suitable for performance testing of prediction algorithms that you can learn from and refer to?
A(stu): This paper is discussed: Choose Your Simulator Wisely A Review on Open-source Simulators for Autonomous Driving
18. How to estimate how much GPU memory is needed? If used For the Argoverse data set, how is it calculated? /mp.weixin.qq.com/s/EEkr8g4w0s2zhS_jmczUiA
The above is the detailed content of This article is enough for you to read about autonomous driving and trajectory prediction!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
Unfortunately, people often delete certain contacts accidentally for some reasons. WeChat is a widely used social software. To help users solve this problem, this article will introduce how to retrieve deleted contacts in a simple way. 1. Understand the WeChat contact deletion mechanism. This provides us with the possibility to retrieve deleted contacts. The contact deletion mechanism in WeChat removes them from the address book, but does not delete them completely. 2. Use WeChat’s built-in “Contact Book Recovery” function. WeChat provides “Contact Book Recovery” to save time and energy. Users can quickly retrieve previously deleted contacts through this function. 3. Enter the WeChat settings page and click the lower right corner, open the WeChat application "Me" and click the settings icon in the upper right corner to enter the settings page.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
 An inventory of six airdrop projects worthy of attention in May 2024
May 05, 2024 am 09:04 AM
An inventory of six airdrop projects worthy of attention in May 2024
May 05, 2024 am 09:04 AM
What other airdrop projects are worthy of your attention in 2024.5? A list of six airdrop projects worthy of attention! Several airdrop chasers in May are turning to other targets — DeFi protocols without native tokens. This expectation often causes liquidity to flood into the platform as users prepare for the airdrop. While the current market slowdown hampered crypto tokens’ price gains earlier this year, here are some projects attracting hope. Today, the editor of this website will introduce to you in detail six airdrop projects worthy of your attention. I wish you all to make money soon! Airdrop hopefuls continue to develop tokenless projects. Cryptocurrencies are driving investor deposits. Airdrop recipients were not swayed by the project team’s attempts to deny the possibility of token distribution. April is an important month for airdrops
 Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Written above & The author’s personal understanding In recent years, autonomous driving has received increasing attention due to its potential in reducing driver burden and improving driving safety. Vision-based three-dimensional occupancy prediction is an emerging perception task suitable for cost-effective and comprehensive investigation of autonomous driving safety. Although many studies have demonstrated the superiority of 3D occupancy prediction tools compared to object-centered perception tasks, there are still reviews dedicated to this rapidly developing field. This paper first introduces the background of vision-based 3D occupancy prediction and discusses the challenges encountered in this task. Next, we comprehensively discuss the current status and development trends of current 3D occupancy prediction methods from three aspects: feature enhancement, deployment friendliness, and labeling efficiency. at last
