
 Technology peripherals
AI
Want to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration
Technology peripherals
AI
Want to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration
Want to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration

Sora’s stunning performance in early 2024 has become a new benchmark, inspiring all those who study Wensheng videos to rush to catch up. Every researcher is eager to replicate Sora's results and works against time.
According to the technical report disclosed by OpenAI, an important innovation point of Sora is to convert visual data into a unified representation of patches, and combine it with the Transformer and diffusion model to demonstrate excellent performance. Scalability. With the release of the report, the paper "Scalable Diffusion Models with Transformers" co-authored by William Peebles, Sora's core developer, and Xie Saining, assistant professor of computer science at New York University, has attracted much attention from researchers. The research community hopes to explore feasible ways to reproduce Sora through the DiT architecture proposed in the paper.
Recently, a project called OpenDiT open sourced by the You Yang team of the National University of Singapore has opened up new ideas for training and deploying DiT models.
OpenDiT is a system designed to improve the training and inference efficiency of DiT applications. It is not only easy to operate, but also fast and memory efficient. The system covers functions such as text-to-video generation and text-to-image generation, aiming to provide users with an efficient and convenient experience.
Project address: https://github.com/NUS-HPC-AI-Lab/OpenDiT
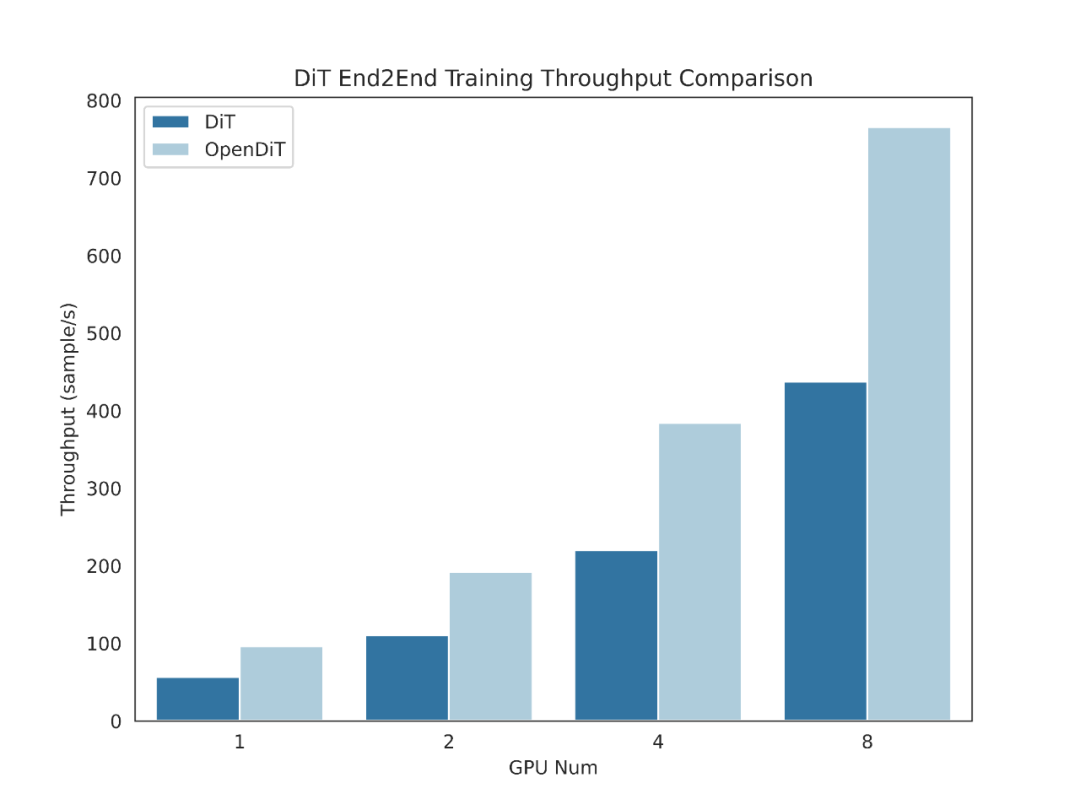
OpenDiT method introduction
OpenDiT provides a high-performance implementation of the Diffusion Transformer (DiT) powered by Colossal-AI. During training, video and condition information are input into the corresponding encoder respectively as input to the DiT model. Subsequently, training and parameter updating are performed through the diffusion method, and finally the updated parameters are synchronized to the EMA (Exponential Moving Average) model. In the inference stage, the EMA model is directly used, taking condition information as input to generate corresponding results.
Picture source: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT uses the ZeRO parallel strategy to distribute the DiT model parameters to multiple machines, initially reducing the memory pressure. In order to achieve a better balance between performance and accuracy, OpenDiT also adopts a mixed-precision training strategy. Specifically, model parameters and optimizers are stored using float32 to ensure accurate updates. During the model calculation process, the research team designed a mixed precision method of float16 and float32 for the DiT model to speed up the calculation process while maintaining model accuracy.
The EMA method used in the DiT model is a strategy for smoothing model parameter updates, which can effectively improve the stability and generalization ability of the model. However, an additional copy of the parameters will be generated, which increases the burden on the video memory. In order to further reduce this part of video memory, the research team fragmented the EMA model and stored it on different GPUs. During the training process, each GPU only needs to calculate and store its own part of the EMA model parameters, and wait for ZeRO to complete the update after each step for synchronous updates.
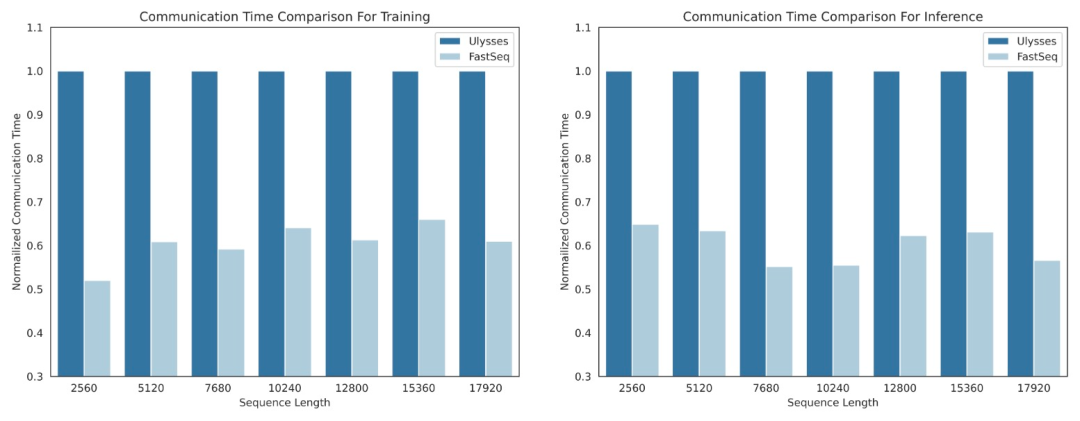
FastSeq
In the field of visual generative models such as DiT, sequence parallelism is critical for efficient long sequence training and low Delayed reasoning is essential.
However, existing methods such as DeepSpeed-Ulysses, Megatron-LM Sequence Parallelism face limitations when applied to such tasks - either introducing too much sequence communication, or Lack of efficiency when dealing with small-scale sequential parallelism.
To this end, the research team proposed FastSeq, a new sequence parallelism suitable for large sequences and small-scale parallelism. FastSeq minimizes sequence communication by using only two communication operators per transformer layer, leverages AllGather to improve communication efficiency, and strategically employs asynchronous rings to overlap AllGather communication with qkv calculations to further optimize performance.
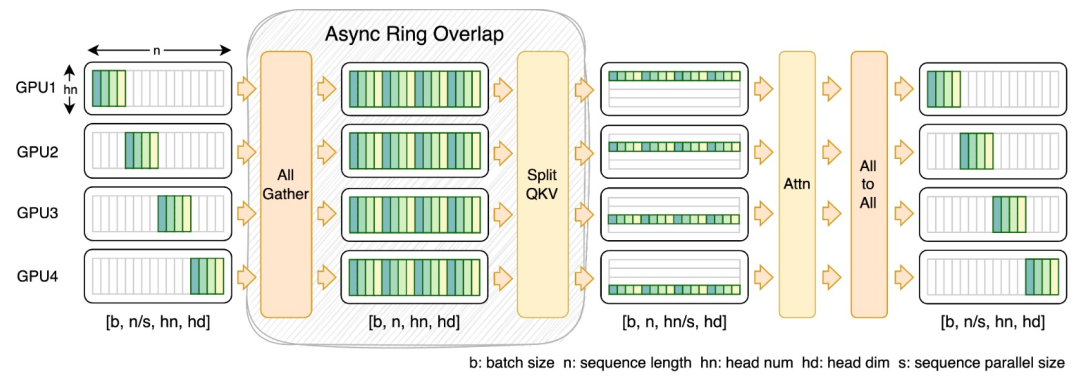
##Operator optimization
The adaLN module is introduced into the DiT model to integrate conditional information into visual content. Although this operation is crucial to improving the performance of the model, it also brings a large number of element-by-element operations and is frequently used in the model. Calling reduces the overall computing efficiency. In order to solve this problem, the research team proposed an efficient Fused adaLN Kernel, which merges multiple operations into one, thereby increasing computing efficiency and reducing I/O consumption of visual information.
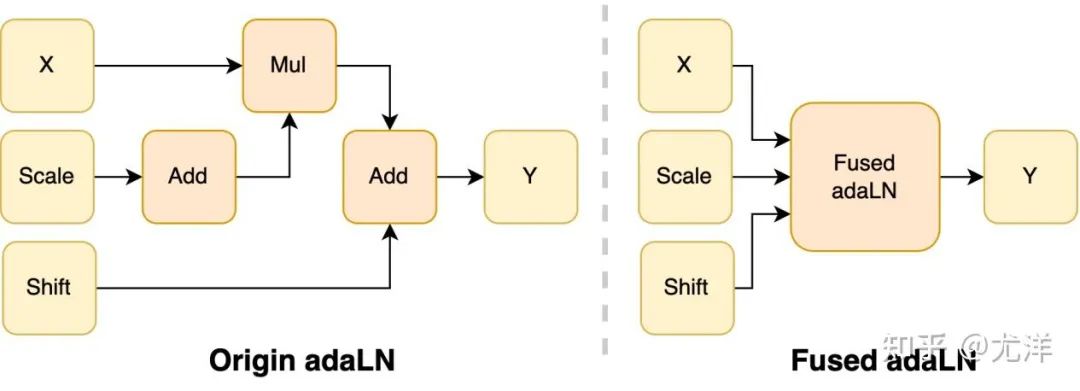
Picture source: https://www.zhihu.com/people/berkeley-you-yang
Simply put, OpenDiT has the following performance advantages:
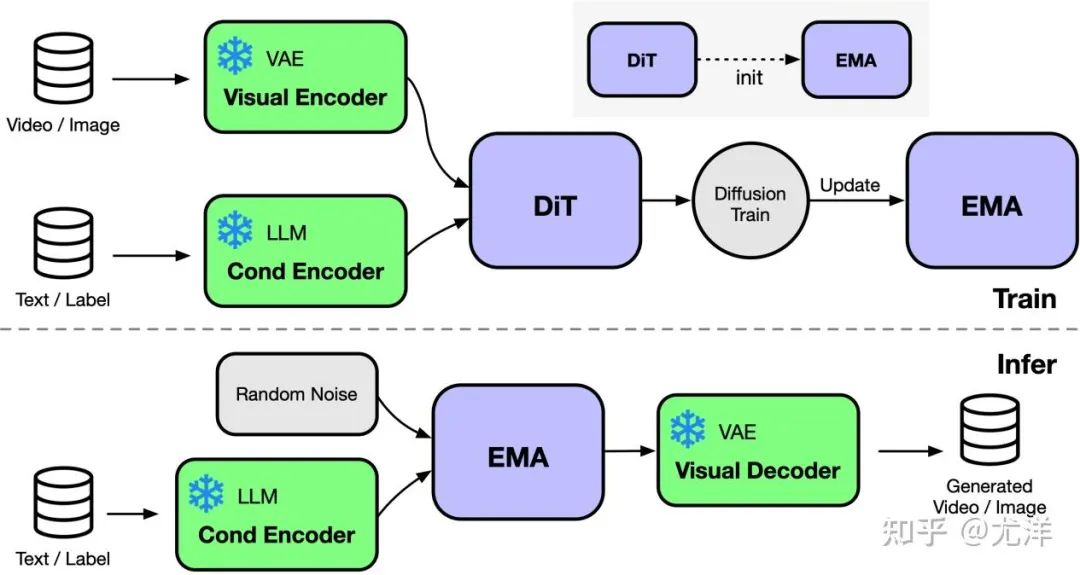
#1. Acceleration up to 80% on GPU, 50% memory saving
- Designed efficient operators, including Fused AdaLN designed for DiT, as well as FlashAttention, Fused Layernorm and HybridAdam.
- Use a hybrid parallel approach including ZeRO, Gemini and DDP. Sharding the ema model also further reduces memory costs.
#2. FastSeq: a novel sequence parallel method
- is designed for similar DiT is designed for workloads where the sequences are usually longer but the parameters are smaller compared to LLM.
- Intra-node sequence parallelism can save up to 48% of traffic.
- Break the memory limitations of a single GPU and reduce overall training and inference time.
3. Easy to use
- Just need to modify a few lines of code. Get huge performance improvements.
- Users do not need to understand how distributed training is implemented.
4. Text to image and text to video generation complete pipeline
- Researcher and engineers can easily use the OpenDiT pipeline and apply it to real-world applications without modifying the parallel part.
- The research team verified the accuracy of OpenDiT by conducting text-to-image training on ImageNet and released a checkpoint.
Installation and use
To use OpenDiT, you must first install the prerequisites:
- Python >= 3.10
- PyTorch >= 1.13 (version 2.0 is recommended)
- CUDA > = 11.6
It is recommended to create a new environment using Anaconda (Python >= 3.10) to run the examples:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
Install ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
Install OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
(can Optional but recommended) Install libraries to speed up training and inference:
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
Image generation
You can train the DiT model by executing the following command:
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
All acceleration methods are disabled by default. Here are details on some of the key elements in the training process:
- #plugin: Supports the booster plugin used by ColossalAI, zero2 and ddp. The default is zero2, it is recommended to enable zero2.
- mixed_ precision: The data type of mixed precision training, the default is fp16.
- grad_checkpoint: Whether to enable gradient checkpoint. This saves the memory cost of the training process. The default value is False. It is recommended to disable it if there is enough memory.
- enable_modulate_kernel: Whether to enable modulate kernel optimization to speed up the training process. The default value is False and it is recommended to enable it on GPUs
- enable_layernorm_kernel: Whether to enable layernorm kernel optimization to speed up the training process. The default value is False and it is recommended to enable it.
- enable_flashattn: Whether to enable FlashAttention to speed up the training process. The default value is False and it is recommended to enable it.
- sequence_parallel_size: sequence parallelism size. Sequence parallelism is enabled when setting a value > 1. The default value is 1, it is recommended to disable it if there is enough memory.
If you want to use the DiT model for inference, you can run the following code. You need to replace the checkpoint path with your own trained model.
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
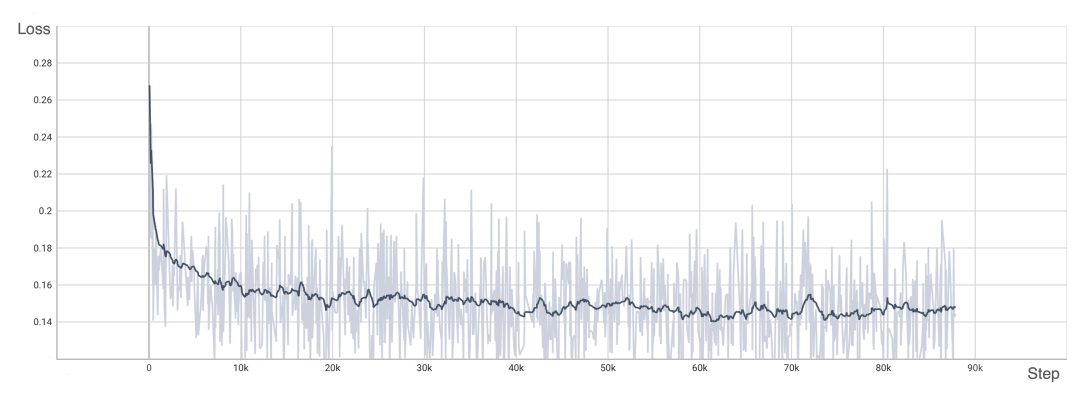
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
The above is the detailed content of Want to train a Sora-like model? You Yang's team OpenDiT achieves 80% acceleration. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to dynamically create an object through a string and call its methods in Python?
Apr 01, 2025 pm 11:18 PM
How to dynamically create an object through a string and call its methods in Python?
Apr 01, 2025 pm 11:18 PM
In Python, how to dynamically create an object through a string and call its methods? This is a common programming requirement, especially if it needs to be configured or run...
 How to use Go or Rust to call Python scripts to achieve true parallel execution?
Apr 01, 2025 pm 11:39 PM
How to use Go or Rust to call Python scripts to achieve true parallel execution?
Apr 01, 2025 pm 11:39 PM
How to use Go or Rust to call Python scripts to achieve true parallel execution? Recently I've been using Python...
 How to solve the problem of missing dynamic loading content when obtaining web page data?
Apr 01, 2025 pm 11:24 PM
How to solve the problem of missing dynamic loading content when obtaining web page data?
Apr 01, 2025 pm 11:24 PM
Problems and solutions encountered when using the requests library to crawl web page data. When using the requests library to obtain web page data, you sometimes encounter the...
 Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
About Pythonasyncio...
 How to recover Debian mail server
Apr 02, 2025 am 07:33 AM
How to recover Debian mail server
Apr 02, 2025 am 07:33 AM
Detailed Steps for Restoring Debian Mail Server This article will guide you on how to restore Debian Mail Server. Before you begin, it is important to remember the importance of data backup. Recovery Steps: Backup Data: Be sure to back up all important email data and configuration files before performing any recovery operations. This will ensure that you have a fallback version when problems occur during the recovery process. Check log files: Check mail server log files (such as /var/log/mail.log) for errors or exceptions. Log files often provide valuable clues about the cause of the problem. Stop service: Stop the mail service to prevent further data corruption. Use the following command: su
 How to operate Zookeeper performance tuning on Debian
Apr 02, 2025 am 07:42 AM
How to operate Zookeeper performance tuning on Debian
Apr 02, 2025 am 07:42 AM
This article describes how to optimize ZooKeeper performance on Debian systems. We will provide advice on hardware, operating system, ZooKeeper configuration and monitoring. 1. Optimize storage media upgrade at the system level: Replacing traditional mechanical hard drives with SSD solid-state drives will significantly improve I/O performance and reduce access latency. Disable swap partitioning: By adjusting kernel parameters, reduce dependence on swap partitions and avoid performance losses caused by frequent memory and disk swaps. Improve file descriptor upper limit: Increase the number of file descriptors allowed to be opened at the same time by the system to avoid resource limitations affecting the processing efficiency of ZooKeeper. 2. ZooKeeper configuration optimization zoo.cfg file configuration
 How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
To strengthen the security of Oracle database on the Debian system, it requires many aspects to start. The following steps provide a framework for secure configuration: 1. Oracle database installation and initial configuration system preparation: Ensure that the Debian system has been updated to the latest version, the network configuration is correct, and all required software packages are installed. It is recommended to refer to official documents or reliable third-party resources for installation. Users and Groups: Create a dedicated Oracle user group (such as oinstall, dba, backupdba) and set appropriate permissions for it. 2. Security restrictions set resource restrictions: Edit /etc/security/limits.d/30-oracle.conf
 In the ChatGPT era, how can the technical Q&A community respond to challenges?
Apr 01, 2025 pm 11:51 PM
In the ChatGPT era, how can the technical Q&A community respond to challenges?
Apr 01, 2025 pm 11:51 PM
The technical Q&A community in the ChatGPT era: SegmentFault’s response strategy StackOverflow...
