
 Technology peripherals
AI
Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Technology peripherals
AI
Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Visualize FAISS vector space and adjust RAG parameters to improve result accuracy

As the performance of open source large-scale language models continues to improve, the performance of writing and analyzing code, recommendations, text summarization, and question and answer (QA) pairs has improved significantly. But when it comes to QA, LLM often falls short on issues related to untrained data, and many internal documents are kept within the company to ensure compliance, trade secrets, or privacy. When these documents are queried, LLM can hallucinate and produce irrelevant, fabricated, or inconsistent content.

#One possible technique to handle this challenge is Retrieval Augmented Generation (RAG). It involves the process of enhancing responses by referencing authoritative knowledge bases beyond the training data source to improve the quality and accuracy of the generation. The RAG system consists of a retrieval system that retrieves relevant document fragments from the corpus, and an LLM model that utilizes the retrieved fragments as context to generate responses. Therefore, the quality of the corpus and the representation embedded in vector space are crucial to the performance of RAG.
In this article we will use the visualization library renumics-spotlight to visualize multidimensional embeddings of FAISS vector spaces in 2-D and look for improvements by varying certain key vectorization parameters RAG response accuracy possibilities. For the LLM we choose, we will use the TinyLlama 1.1B Chat, a compact model with the same architecture as the Llama 2. It has the advantage of having a smaller resource footprint and faster runtimes without a proportional drop in accuracy, making it ideal for rapid experimentation.
System design
The QA system has two modules, as shown in the figure.
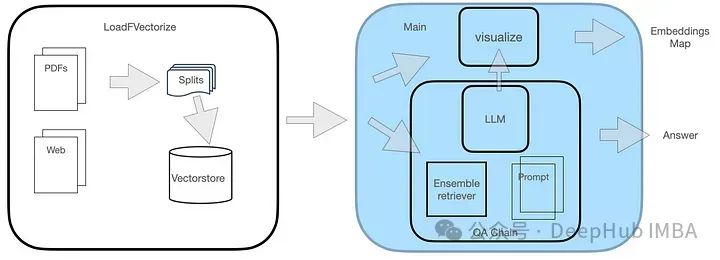
The LoadFVectorize module is used to load PDF or Web documents and perform preliminary testing and visualization. Another module is responsible for loading LLM and instantiating the FAISS searcher, and then building a search chain including LLM, searcher and custom query prompts. Finally, we visualize the vector space.
Code implementation
1. Install the necessary libraries
renomics-spotlight library adopts similar Umap's visualization method reduces high-dimensional embeddings to manageable 2D visualizations while preserving key attributes. We have briefly introduced the use of umap before, but only the basic functions. This time, we integrated it into a real project as part of the system design. First, you need to install the necessary libraries.
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
The last line above is to install the llama-pcp-python library with Metal support, which will be used to load the llama-pcp-python library with Metal support on the M1 processor Hardware accelerated TinyLlama.
2. LoadFVectorize module
The module includes 3 functions:
load_doc processes online pdf The document is loaded, each block is divided into 512 characters, overlapped by 100 characters, and the document list is returned.
vectorize calls the function load_doc above to get the block list of the document, create an embed and save it to the local directory opdf_index, and return a FAISS instance.
load_db checks whether the FAISS library is on disk in the directory opdf_index and attempts to load it, eventually returning a FAISS object.
The complete code of this module code is as follows:
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return db3. Main module
The main module initially defines the TinyLlama prompt template for the following template:
{context}{question}Also using the quantized version of TinyLlama from TheBloke can be greatly To reduce memory, we choose to load the quantized LLM in GGUF format.
Then use the FAISS object returned by the LoadFVectorize module to create a FAISS retriever, instantiate RetrievalQA, and use it for queries.
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])The vector space visualization itself is handled by the last line of visualize_distance in the code above:
visualize_distance access FAISS The object's attribute __dict__, index_to_docstore_id itself is a key index dictionary of values docstore-ids, and the total document count used for vectorization is represented by the index object's attribute ntotal.
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotalCalling the method reconstruct_n of the object index can achieve approximate reconstruction of the vector space
embeddings_vec = db.index.reconstruct_n()
With the docstore-id list as index_list, you can find the relevant document object and use it to create a list that includes the docstore-id, document metadata, document content, and its embedding in the vector space of all ids:
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])Then use the list to create a DF containing the column headers, we finally use this DF for visualization
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])
在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
This step will launch spotlight in the browser window.
Run the test
1. Basic test
The following are the sample questions we selected:
What versions of TLS supported by Client Accelerator 6.3.0?
The correct answer is:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2.
The following additional information may be included in the response.
You must enable this capability using the following CLI command on the Client Accelerator:(config) # policy id
ssl backend client-tls-1.2Even though TLS 1.1 is not mentioned in the syntax of this command, using this command automatically enables support for both TLS 1.1 and 1.2.
Then let’s take a look at TinyLlama’s response to the above problem Answer:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2 as the default supported TLS versions with Client Accelerator. You must enable this capability using the following CLI command on the Client Accelerator:```(config) # policy id
ssl backend client -tlss1.2```Note that this command only applies to TLS 1.1 or TLS 1.2. If you need to support older TLS versions, you can use the ssl backend command with the client-tlss1.0 or client-tlss1.1 option instead.
## looks very similar to the actual answer, but It's not entirely correct as these TLS versions are not their default.
So let’s take a look at which passages he found the answer from?
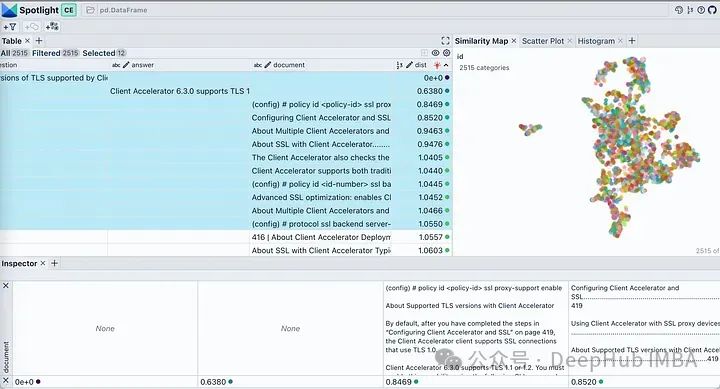
Use the visible button in spotlight to control the displayed columns. Sort the table by "dist" to show questions, answers and the most relevant document snippets at the top. Looking at the embedding of our document, it describes almost all chunks of the document as a single cluster. This is reasonable because our original PDF is a deployment guide for a specific product, so there is no problem with it being considered a cluster.
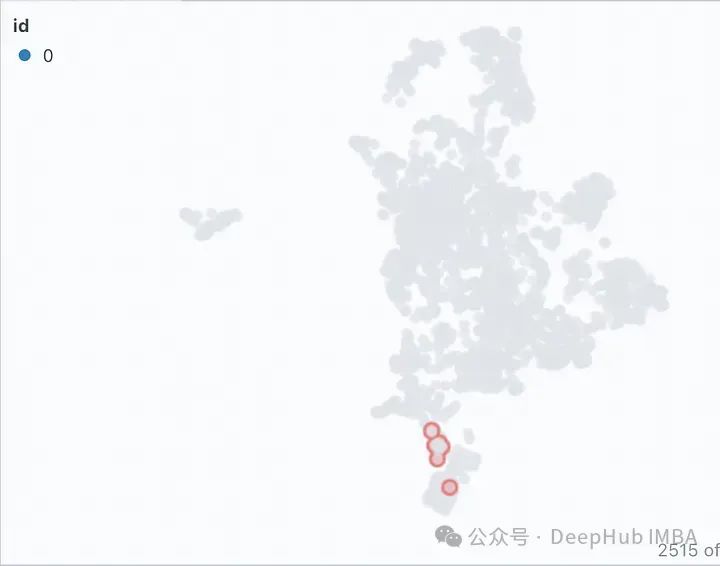
Click the filter icon in the Similarity Map tab, it only highlights the selected document list, which is tightly clustered, and the rest is grayed out as shown below shown.
2. Test block size and overlap parameters
Since the retriever is the key to affecting RAG performance Factors, let’s take a look at several parameters that affect the embedding space. TextSplitter's chunk size (1000, 2000) and/or overlap (100, 200) parameters are different during document splitting.
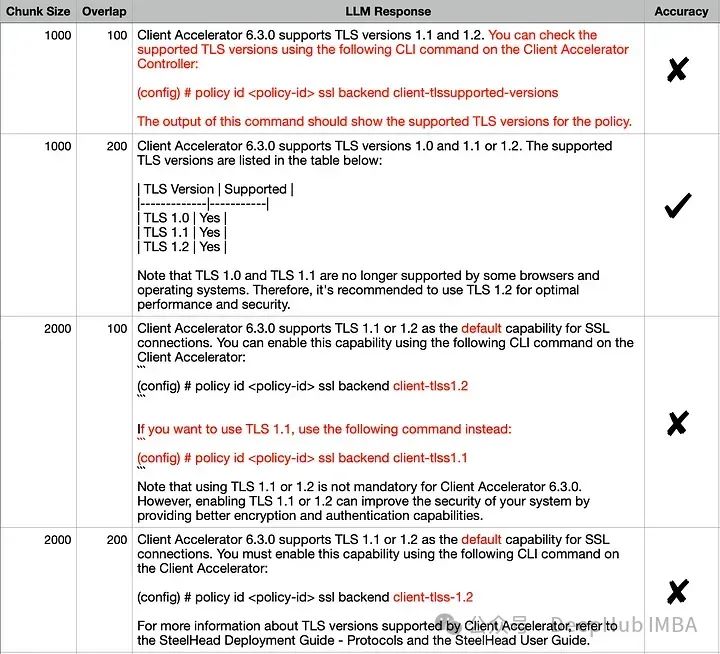
The output seems similar for all combinations, but if we carefully compare the correct answer with each answer, the exact answer is (1000,200) . Incorrect details in other responses have been highlighted in red. Let’s try to explain this behavior using visual embedding:
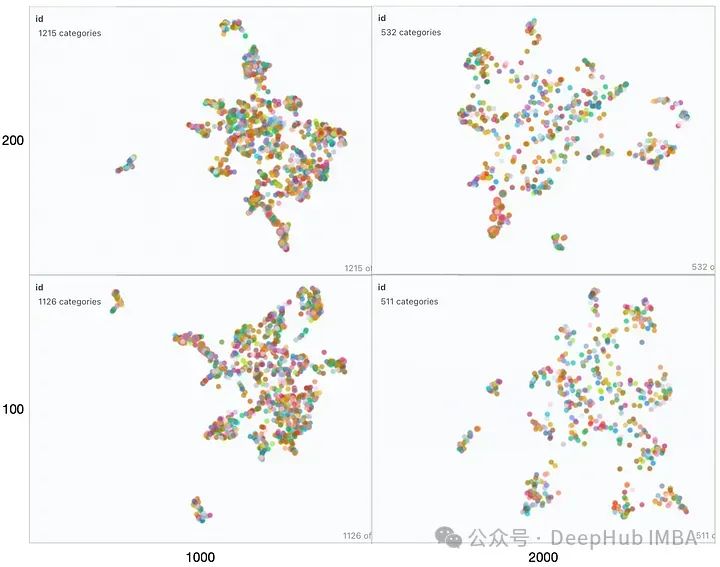
Looking from left to right, as the block size increases, we can observe The vector space becomes sparse and the blocks are smaller. From bottom to top, the overlap gradually increases without significant changes in the vector space characteristics. In all these mappings the entire set still appears more or less as a single cluster, with only a few outliers present. This can be seen in the generated responses because the generated responses are all very similar.
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
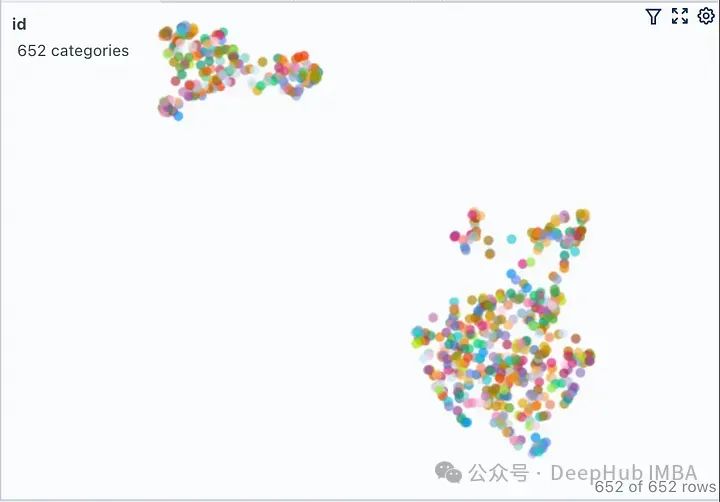
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
The above is the detailed content of Visualize FAISS vector space and adjust RAG parameters to improve result accuracy. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Why does Chrome browser crash? How to solve the problem of Google Chrome crashing when opening?
Mar 13, 2024 pm 07:28 PM
Why does Chrome browser crash? How to solve the problem of Google Chrome crashing when opening?
Mar 13, 2024 pm 07:28 PM
Google Chrome has high security and strong stability, and is loved by the majority of users. However, some users find that Google Chrome crashes as soon as they open it. What is going on? It may be that too many tabs are open, or the browser version is too old. Let’s take a look at the detailed solutions below. How to solve the crash problem of Google Chrome? 1. Close some unnecessary tabs If there are too many open tabs, try closing some unnecessary tabs, which can effectively relieve the resource pressure of Google Chrome and reduce the possibility of crashing. 2. Update Google Chrome If the version of Google Chrome is too old, it will also cause crashes and other errors. It is recommended that you update Chrome to the latest version. Click [Customize and Control]-[Settings] in the upper right corner
 Windows on Ollama: A new tool for running large language models (LLM) locally
Feb 28, 2024 pm 02:43 PM
Windows on Ollama: A new tool for running large language models (LLM) locally
Feb 28, 2024 pm 02:43 PM
Recently, both OpenAITranslator and NextChat have begun to support large-scale language models running locally in Ollama, which provides a new way of playing for "newbies" enthusiasts. Moreover, the launch of Ollama on Windows (preview version) has completely subverted the way of AI development on Windows devices. It has guided a clear path for explorers in the field of AI and ordinary "water-testing players". What is Ollama? Ollama is a groundbreaking artificial intelligence (AI) and machine learning (ML) tool platform that greatly simplifies the development and use of AI models. In the technical community, the hardware configuration and environment construction of AI models have always been a thorny issue.
 How to solve pycharm crash
Apr 25, 2024 am 05:09 AM
How to solve pycharm crash
Apr 25, 2024 am 05:09 AM
Solutions to PyCharm crashes include: check memory usage and increase PyCharm's memory limit; update PyCharm to the latest version; check plug-ins and disable or uninstall unnecessary plug-ins; reset PyCharm settings; disable hardware acceleration; reinstall PyCharm; contact Support staff asked for help.
 Why do large language models use SwiGLU as activation function?
Apr 08, 2024 pm 09:31 PM
Why do large language models use SwiGLU as activation function?
Apr 08, 2024 pm 09:31 PM
If you have been paying attention to the architecture of large language models, you may have seen the term "SwiGLU" in the latest models and research papers. SwiGLU can be said to be the most commonly used activation function in large language models. We will introduce it in detail in this article. SwiGLU is actually an activation function proposed by Google in 2020, which combines the characteristics of SWISH and GLU. The full Chinese name of SwiGLU is "bidirectional gated linear unit". It optimizes and combines two activation functions, SWISH and GLU, to improve the nonlinear expression ability of the model. SWISH is a very common activation function that is widely used in large language models, while GLU has shown good performance in natural language processing tasks.
 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 Recommended Android emulator that is smoother (choose the Android emulator you want to use)
Apr 21, 2024 pm 06:01 PM
Recommended Android emulator that is smoother (choose the Android emulator you want to use)
Apr 21, 2024 pm 06:01 PM
It can provide users with a better gaming experience and usage experience. An Android emulator is a software that can simulate the running of the Android system on a computer. There are many kinds of Android emulators on the market, and their quality varies, however. To help readers choose the emulator that suits them best, this article will focus on some smooth and easy-to-use Android emulators. 1. BlueStacks: Fast running speed. With excellent running speed and smooth user experience, BlueStacks is a popular Android emulator. Allowing users to play a variety of mobile games and applications, it can simulate Android systems on computers with extremely high performance. 2. NoxPlayer: Supports multiple openings, making it more enjoyable to play games. You can run different games in multiple emulators at the same time. It supports
 Do I need to enable GPU hardware acceleration?
Feb 26, 2024 pm 08:45 PM
Do I need to enable GPU hardware acceleration?
Feb 26, 2024 pm 08:45 PM
Is it necessary to enable hardware accelerated GPU? With the continuous development and advancement of technology, GPU (Graphics Processing Unit), as the core component of computer graphics processing, plays a vital role. However, some users may have questions about whether hardware acceleration needs to be turned on. This article will discuss the necessity of hardware acceleration for GPU and the impact of turning on hardware acceleration on computer performance and user experience. First, we need to understand how hardware-accelerated GPUs work. GPU is a specialized
 What should I do if a WPS form responds slowly? Why is the WPS form stuck and slow to respond?
Mar 14, 2024 pm 02:43 PM
What should I do if a WPS form responds slowly? Why is the WPS form stuck and slow to respond?
Mar 14, 2024 pm 02:43 PM
What should I do if a WPS form responds very slowly? Users can try to close other programs or update the software to perform the operation. Let this site carefully introduce to users why the WPS form is slow to respond. Why is the WPS table slow to respond? 1. Close other programs: Close other running programs, especially those that take up a lot of system resources. This can provide WPS Office with more computing resources and reduce lags and delays. 2. Update WPSOffice: Make sure you are using the latest version of WPSOffice. Downloading and installing the latest version from the official WPSOffice website can resolve some known performance issues. 3. Reduce file size
