In the current development of intelligent dialogue models, powerful underlying models play a crucial role. The pre-training of these advanced models often relies on high-quality and diverse corpora, and how to build such a corpus has become a major challenge in the industry. In the high-profile field of AI for Math, the relative scarcity of high-quality mathematical corpus limits the potential of generative artificial intelligence in mathematical applications. #To address this challenge, the Generative Artificial Intelligence Laboratory of Shanghai Jiao Tong University launched “MathPile”. This is a high-quality, diverse pre-training corpus specifically targeted at the field of mathematics, which contains approximately 9.5 billion tokens and is designed to improve the capabilities of large models in mathematical reasoning. In addition, the laboratory also launched the commercial version of MathPile - "MathPile_Commercial" to further broaden its application scope and commercial potential. 
- Research use: https://huggingface.co/datasets /GAIR/MathPile
- Commercial version: https://huggingface.co/datasets/GAIR/MathPile_Commercial
MathPile has the following characteristics:
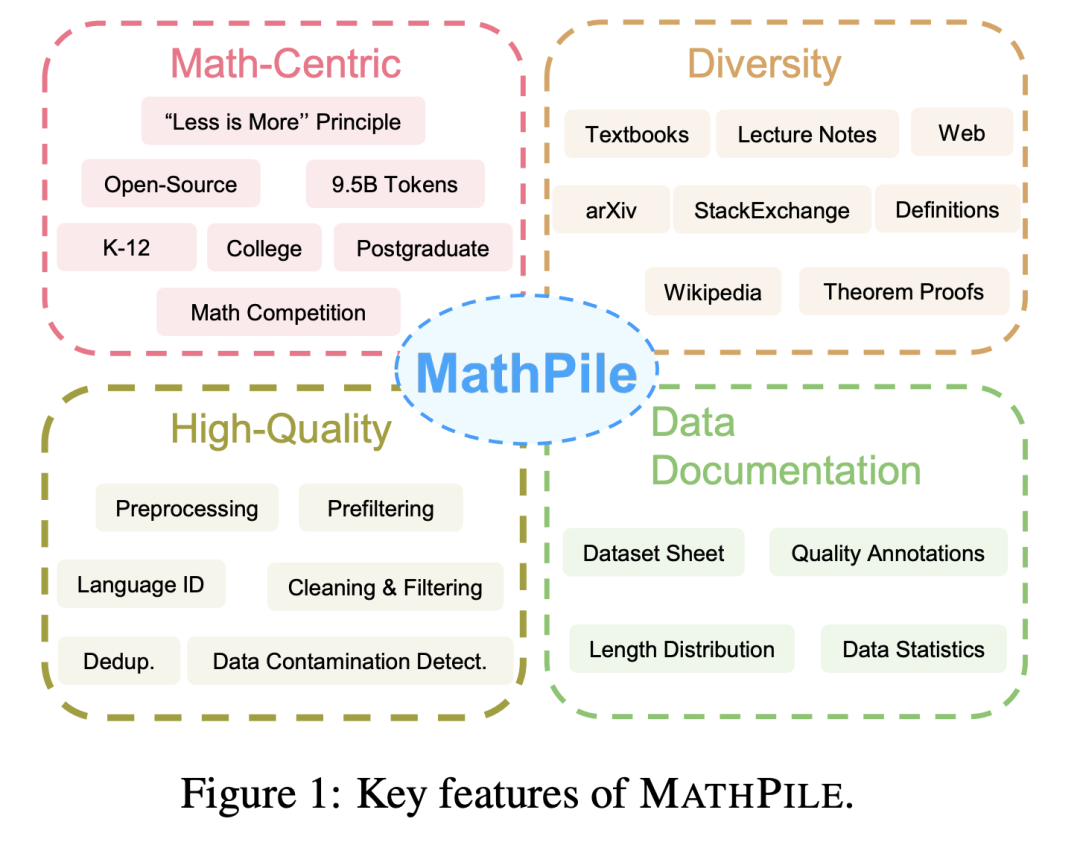
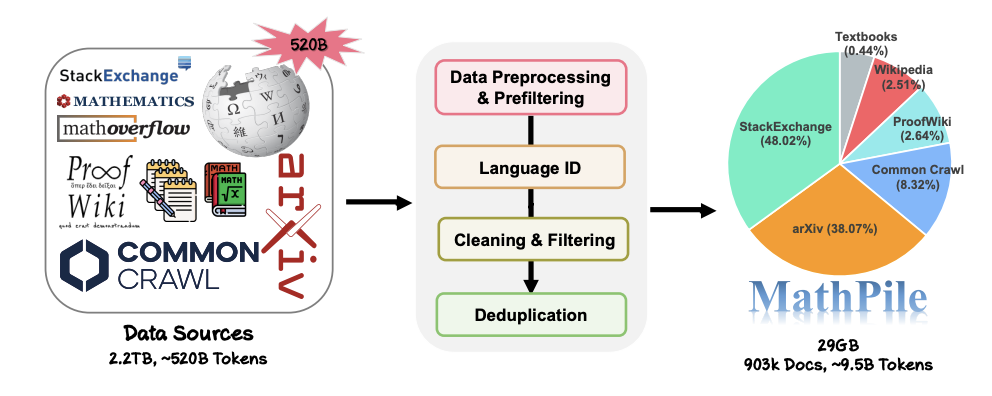
1. Mathematically centered: Different from the corpora that focused on general fields in the past, such as Pile, RedPajama, or the multilingual corpus ROOTS, etc., MathPile focuses on the field of mathematics. Although there are already some specialized mathematical corpora, they are either not open source (such as the corpus used by Google to train Minerva, OpenAI's MathMix), or are not rich and diverse enough (such as ProofPile and the recent OpenWebMath). 2. Diversity: MathPile has a wide range of data sources, such as open source mathematics textbooks, class notes, synthetic textbooks, and mathematics on arXiv Related papers, math-related entries on Wikipedia, lemma proofs and definitions on ProofWiki, high-quality math questions and answers on StackExchange, and math web pages from Common Crawl. The above content covers content suitable for primary and secondary schools, universities, graduate students, and mathematics competitions. MathPile covers 0.19B tokens of high-quality mathematics textbooks for the first time. 3. High Quality: The research team follows the concept of "less is more" during the collection process and firmly believes in data quality Better than quantity, even in the pre-training phase. From a data source of ~520B tokens (approximately 2.2TB), they went through a rigorous and complex set of pre-processing, pre-filtering, language identification, cleaning, filtering and deduplication steps to ensure the high quality of the corpus. It is worth mentioning that the MathMix used by OpenAI only has 1.5B tokens. 4. Data documentation: In order to increase transparency, the research team documented MathPile and provided a dataset sheet. During the data processing process, the research team also performed "quality annotation" on documents from the Web. For example, the score of language recognition and the ratio of symbols to words in the document allow researchers to further filter documents according to their own needs. They also performed downstream test set contamination detection on the corpus to eliminate samples from benchmark test sets such as MATH and MMLU-STEM. At the same time, the research team also discovered that there are also a large number of downstream test samples in OpenWebMath, which shows that extra care should be taken when producing pre-training corpus to avoid invalid downstream evaluation.
MathPile’s data collection and processing process.
Today, as competition in the field of large models becomes increasingly fierce, many technology companies no longer disclose their data; of data sources, matching, not to mention detailed preprocessing details. On the contrary, MathPile summarizes a set of data processing methods suitable for the Math field based on previous explorations. In the data cleaning and filtering part, the specific steps adopted by the research team are:
- Detect lines containing "lorem ipsum". If "lorem ipsum" is replaced by less than 5 characters in the line, remove the line;
- Detect lines containing "javescript" ” and contains a line with "enable", "disable" or "browser", and the number of characters in the line is less than 200 characters, then filter out the line;
- Filter out less than 200 characters. 10 words and lines containing "Login", "sign-in", "read more...", or "items in cart";
- Filter out the proportion of uppercase words More than 40% of the documents;
- Filter out the documents whose lines ending with an ellipsis account for more than 30% of the entire document;
- Filter out the non- Documents where the proportion of letter words exceeds 80%;
- Filter out documents whose average English word character length is outside the range of (3, 10);
- Filter out documents that do not contain at least two stop words (such as the, be, to, of, and, that, have, etc.);
- Filter out ellipses and Documents with a word proportion exceeding 50%;
- Filter out documents in which the line starting with a bullet accounts for more than 90%;
- Filter out documents with lines starting with bullets Documents of less than 200 characters after excluding spaces and punctuation;
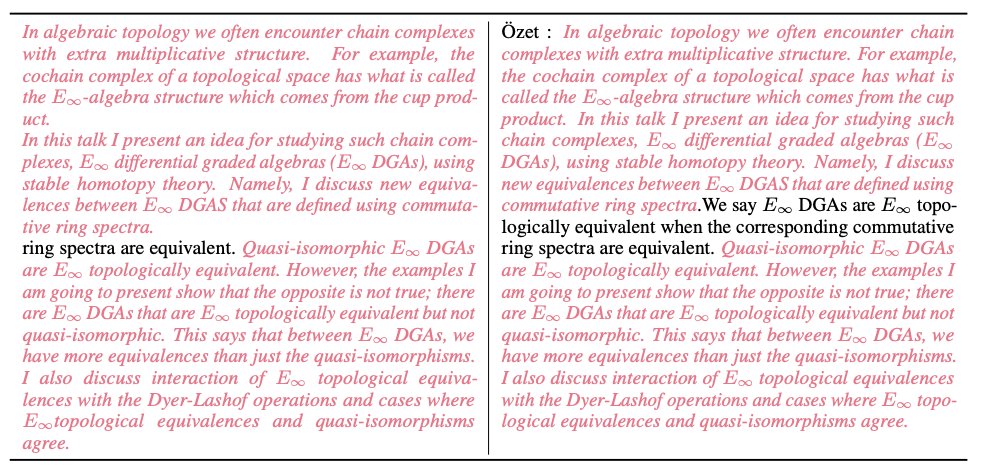
More processing details can be found in the paper. In addition, the research team also provided many data samples during the cleaning process. The picture below shows the nearly duplicate documents in Common Crawl detected by the MinHash LSH algorithm (shown in pink highlights).
As shown in the figure below, the research team discovered problems from the MATH test set (as highlighted in yellow) during the data leakage detection process.
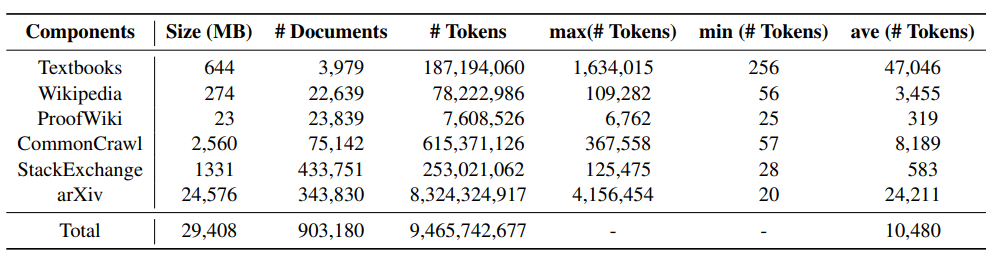
Data set statistics and examplesThe following table shows the various components of MathPile According to the statistical information, you can find arXiv papers. Textbooks usually have longer document lengths, while documents on wikis are relatively shorter. The picture below is a sample document of a textbook in the MathPile corpus. It can be seen that the document structure is relatively clear and the quality is high.
Experimental results
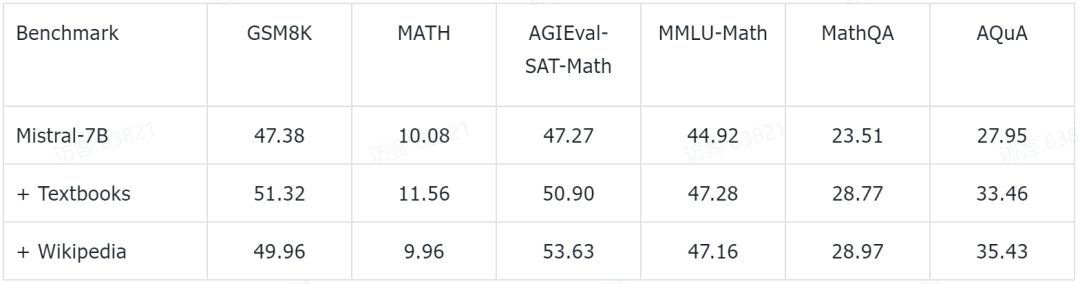
The research team also disclosed some preliminary experimental results. They performed further pre-training based on the currently popular Mistral-7B model. Then, it was evaluated on some common mathematical reasoning benchmark data sets through a few-shot prompting method. The preliminary experimental data that have been obtained so far are as follows:
These test benchmarks cover all levels of mathematical knowledge, including primary school mathematics (such as GSM8K, TAL-SCQ5K-EN and MMLU- Math), high school mathematics (such as MATH, SAT-Math, MMLU-Math, AQuA, and MathQA), and college mathematics (such as MMLU-Math). Preliminary experimental results announced by the research team show that by continuing to pre-train on textbooks and Wikipedia subsets in MathPile, the language model has achieved considerable improvements in mathematical reasoning capabilities at different difficulty levels.
The research team also emphasized that relevant experiments are still ongoing.
Conclusion
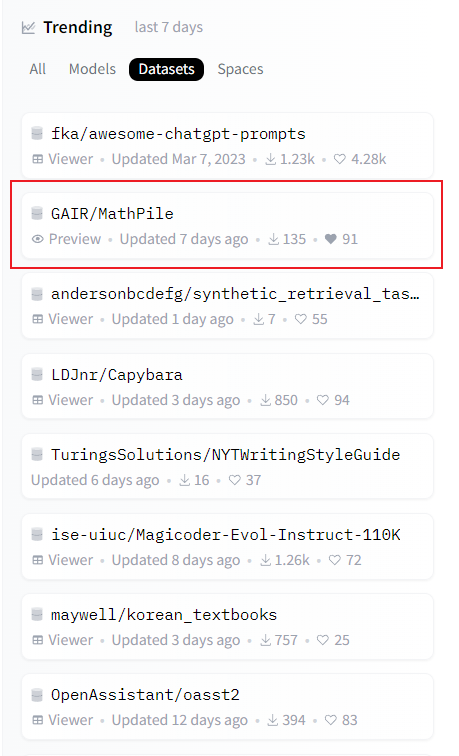
MathPile has received widespread attention since its release and has been reproduced by many parties. It is currently listed on the Huggingface Datasets trend list. The research team stated that they will continue to optimize and upgrade the data set to further improve data quality.
MathPile is trending on Huggingface Datasets. MathPile was forwarded by the well-known AI blogger AK, source: https://twitter.com/_akhaliq/status/1740571256234057798.
Currently, MathPile has been updated to the second version, aiming to contribute to the research and development of the open source community. At the same time, its commercial version of the data set has also been opened to the public. The above is the detailed content of To supplement mathematics for large models, submit the open source MathPile corpus with 9.5 billion tokens, which can also be used commercially. For more information, please follow other related articles on the PHP Chinese website!





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



