

At first, because the amount of data was not large, the system performance was pretty good, and various list queries, report queries, Excel data export functions, etc. were all used smoothly. However, as the company's business developed and the order volume accumulated day by day, and the demand for report queries and data exports from various business departments continued to increase in the later period, we gradually felt that the system was running slower and slower. So the first solution we may think of is to optimize the system bottleneck database. One of our possible attempts is to place the database separately on a server to separate the database and the application, or to establish various database table indexes, optimize program code, etc. After such research and optimization, the performance of some functions of the system may indeed be greatly improved, but we still found that the data query and export of some function lists is still very slow, or as the amount of data continues to accumulate, the originally faster list export function has also It's getting slower and slower. We tried various methods, but in the end we could not achieve the ideal system performance speed.
In order to improve system performance, we may take the initiative to learn from the technical experience of some Internet companies, such as high concurrency, high performance, big data, read-write separation and other solutions, but find that we have no way to start. We would think that the business characteristics of the system are different. The concurrency of the ERP system is not high, mainly due to the complexity of the business. The coupling degree of various businesses is much higher than that of Internet applications, making it difficult to split. The data query logic is much more complicated than that of the Internet system. The data queried from a list page often requires The result can be obtained by correlating 4 or 5 tables. Some reports have even more. Coupled with the transactional nature of various business operations and high data consistency requirements, we were often caught off guard and unable to further optimize the system.
Once upon a time, I was frustrated by one reason or another, thinking that the ERP system was very special and incurable, but later. . .
I no longer think so, there seems to be a new solution O(∩_∩)O haha~
Before describing the specific plan, let me first express my thoughts. First of all, I think that before we build an ERP system, we must have today's Internet thinking. We no longer want to build a unified system. We need to split a large system into small systems. These small systems are then allowed to communicate with each other through system interfaces. This forms a large system, specifically the "distributed" and "service-oriented" Internet thinking. Let the system be a system that inherently supports high scalability in terms of architectural design.
How to do it? Specifically, it is necessary to split order management, commodity management, production and procurement, warehouse management, logistics management, and financial management into a subsystem. These subsystems can be designed and developed independently, and the data interfaces required by various other subsystems can be exposed to the outside world. Each subsystem has a separate database. Even these subsystems can be developed and maintained by different teams, using different technical systems and different databases. Rather than being integrated into the same large and comprehensive system, a large and comprehensive database, as before.
What are the advantages of the new architecture system?
The first and most important thing is to solve the system performance problem. In the past, there was only one database instance, and it was impossible to expand to multiple instances so that load balancing could be achieved by adding additional database instances when performance was limited. Some people may say that a read-write separation solution can be used, but due to the characteristics of the ERP system, this solution is often unrealistic. For example, when operating inventory, you cannot read the inventory from the reading library and then write the inventory in the writing library. Because master-slave replication is time-sensitive, the written inventory cannot be written to the slave database immediately. There are many such scenarios in ERP. What's more, the writing library cannot be expanded, there can only be one. The new design solution is to separate the writing library, and each subsystem has its own database.
Secondly, it is very convenient to update, and each subsystem exists as a background microservice. There is a separate web project in the front end, and this web project calls the service interfaces of these subsystems in the backend. With this design, when a certain business subsystem needs to be updated, it can be updated independently. Unlike the previous single-process architecture, a small update required a restart of the entire system, causing the user session to be lost and the user to log in again. The current design will not have this problem.
System physical deployment view
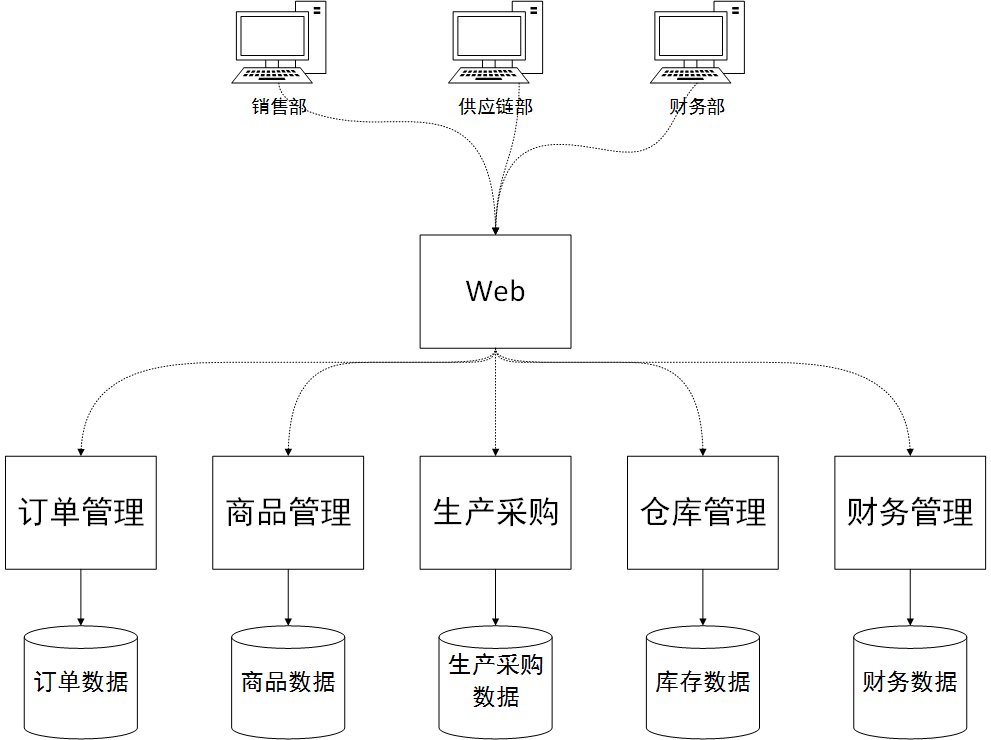
Splitting the application layer is to implement the concept of "microservice" architecture. Split the original large and comprehensive single-process architecture into independently deployable applications according to business modules to achieve smooth system updates and upgrades and facilitate load expansion. Specifically, technically you can use a restfull style interface, or you can use a framework like Dubbo in Java to simplify development complexity. The ERP web client or other mobile client is also a separate application that acts as the presentation layer. It is very thin. It simply accepts parameters and calls the interfaces of various other microservice programs in the background to obtain the data that needs to be displayed. Microservices act as the business logic layer. Each microservice is a program that can be deployed independently and provides external data access interfaces.
Microservices can use various popular RPC frameworks, such as dubbo, which can support multiple calling protocols Http, TCP, etc. These frameworks make coding easier. The framework encapsulates the underlying data communication details, making the client execute remote methods as if they were executed. The native method is just as simple.
Dubbo microservice architecture also supports service governance, load balancing and other functions. This can not only improve the availability of the system, but also dynamically improve the performance of the system application layer. For example, in warehouse management, the warehousing business is very busy and takes up a lot of CPU and memory resources. We can add another machine and deploy a separate warehouse management service. This allows the entire system to have two warehouse management services working at the same time to balance the load. And all this is done automatically in the service registration center, such as Zookeeper.
The microservice structure naturally supports system update and upgrade operations. For example, if the financial module has a new requirement and needs to go online, we only need to replace the service of the financial module and restart it. This will not have much impact on users who have already logged in to the system. They do not need to log in to the system again, and the use of other module services will not be affected.
Database bottleneck is a permanent injury to the ERP system. A large amount of complex data query table connection logic floods the entire system. The key to the success of vertical database splitting is how to redesign the mutual coupling of various modules in the system data layer. If you can solve this problem, the permanent damage can be solved.
Let’s first look at a typical data layer module coupling problem. The requirement is to display material inventory, list fields: material number, material name, category, warehouse, quantity
Material list:
Inventory table:
Category and warehouse tables are omitted. . .
Obviously, in a traditional database, we only need a simple join operation to associate these two tables, and associate the category and warehouse tables to query the data we want. But now in our architecture, the material table and product table are not in the same database instance, and we cannot use the join operation. So how do we realize the requirements?
The new architecture only allows us to obtain data through the other party's service interface, and cannot directly associate with the private database of the other party's service. At least from an architectural perspective, from a service-oriented perspective, you cannot directly access the database of the other party's service. In this case, assuming that the web module subsystem calls the warehouse subsystem to obtain data, we need to create a service method in the warehouse module to assemble the data. Then it is returned to the web subsystem. As shown in the figure below, the warehouse management method first obtains the material code of the local inventory table and the warehouse name field information of the warehouse table. After paging, it is finally ready to return 20 pieces of data to the Web module. The material ID in these 20 pieces of data is As a parameter to request the commodity module subsystem, the commodity subsystem returns the commodity information related to these 20 material IDs to the warehouse management module, and then the warehouse management module reassembles the two field data of material name and category required in the upper list to achieve the final requirement. Data returned to the web subsystem.
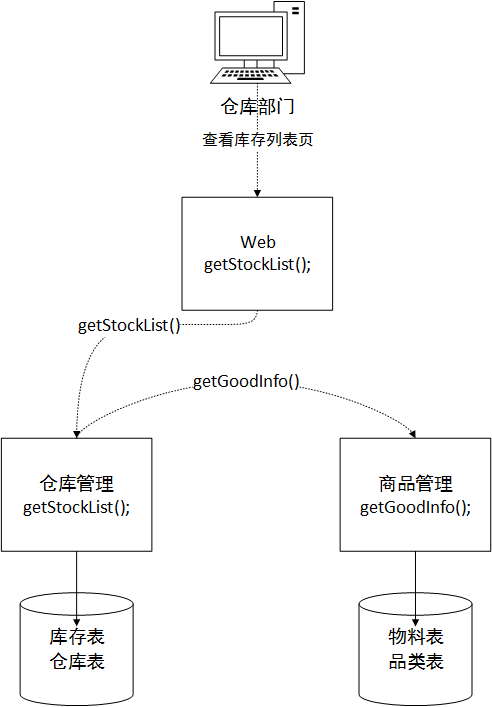
Maybe you will say that this is too troublesome. The performance of this method is definitely not as high as that of direct join, and it cannot solve the performance problem. It seems like this is the case, but if you think about it carefully, in an environment where the system concurrency is low, the data volume is small, and the business is not busy, the performance is indeed not as fast as the traditional join method in one data. But let’s think about it later! Our current architectural design is to split one database into multiple databases, and each database can run on a separate server, so that the pressure on the database can be loaded in the future. Overall, this will prevent the database from becoming a performance bottleneck when business is busy in the future. It’s exciting just thinking about it, isn’t it?
At this time, some people will ask again, what if the system data volume and business will become larger in the future, and even if you split it into several databases, it is not enough? My method is based on a split database, and each library can separate reading and writing, use caching, etc. You can even continue to split the subsystem into multiple subsystems again. It depends on how busy the business module is.
Some people may ask again, some list query logic is very complex and is associated with more than ten tables. If the data is split according to the above method, it will be a disaster! Yes, you are right. In this case, my plan is to use this more complex report-level data query to display the requirements, and I can build a separate report system. The report database design adopts data warehouse approach. For higher reading performance, we can design the database table into many redundant fields, which is an anti-paradigm design, and create a lot of combined indexes.
The key to the success of this system is the synchronization of data and the main ERP system business library. Generally, you can write a scheduled synchronization program to directly generate the final or intermediate data required for report views through selection, transformation, etc. of the data in the ERP main business system to simplify related queries. The reporting system can also be designed using a microservice architecture. As shown below:
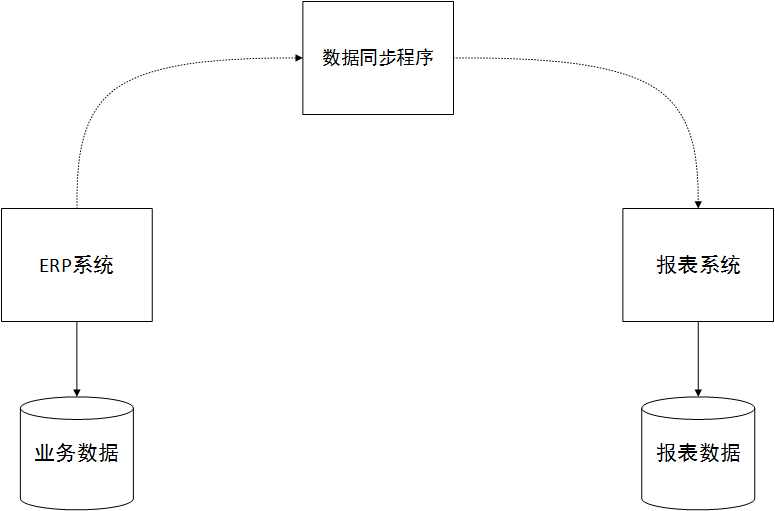
If the data required for the report requires real-time, we can allow the ERP system to trigger a data synchronization request during business operations and synchronize it to the report library in real time.
Maybe someone asked again, many operations in the ERP system require transactionality. How do you achieve transactionality and ensure data consistency after you split the system?
This is a good question, and it is also the last question I thought about before I decided to write this article. In a microservice architecture, it is not easy to implement services that boast services, at least not as convenient as local applications using local database transactions, with efficient performance and good data consistency.
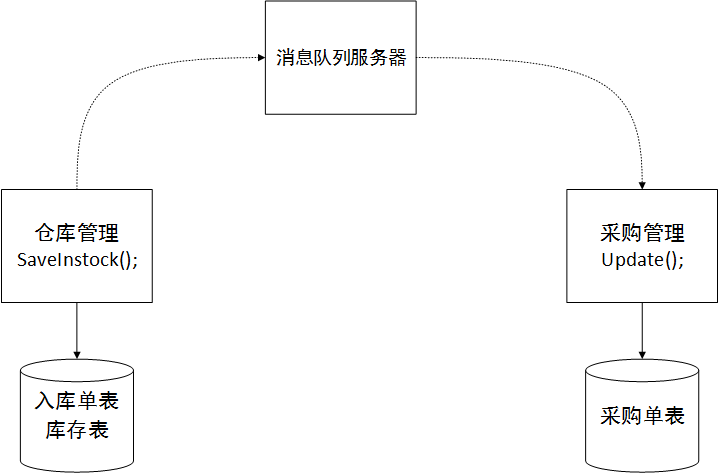
Perhaps you have heard of the concept of distributed transactions. There are two scenarios. One is using multiple databases in one application. To ensure data consistency, distributed transactions need to be used. There is another situation that is specific to our architecture. Distributed transactions in a microservice environment, specifically, use an analogy. The operation of purchasing and warehousing is designed in the warehouse management service. After warehousing, the warehousing quantity in the purchase order in the procurement subsystem needs to be updated. This process requires data consistency, that is, the quantity in the inventory table is written into the inventory table after the purchase order is successfully put into the warehouse, and the quantity in the purchase order table needs to be updated at the same time. We cannot access the database in the procurement service directly in the warehouse service. We must use the service interface provided by the procurement service. If so, how can we ensure data consistency? Because it is very possible that the inventory table is written successfully, but the call to the procurement service to write the purchase order data fails. It may be caused by network problems, so the data is inconsistent.
In distributed transaction technology, there is such a thing as achieving ultimate consistency, which means that as long as I can ensure that the data on both sides are ultimately consistent, it is not necessary to use transactions. So there is a plan. For example, when the warehouse subsystem processes purchases and warehousing, it needs to add warehousing order data and update inventory data and other tables. These multiple tables are all in the warehouse subsystem, and we can use a local transaction to ensure the consistency of table data in the warehouse subsystem. Then call the procurement subsystem to update the warehousing quantity in the purchase order. In order to prevent this process from being suddenly interrupted and causing the call to fail, we consider adding a message queue middleware such as ActiveMQ. If the interface fails to return, we will write the processing request to MQ. After the procurement subsystem returns to normal, MQ will notify the procurement subsystem to process the update operation. Since there will be no more notifications after the message is consumed, an exception occurred during the processing of the procurement subsystem, causing the update to fail. The problem needs to be written to the local log library in order to notify the administrator for subsequent compensation processing. In this way, various methods can be used to achieve the final consistency of the data. Although it sounds a bit confusing, this is the solution. There is nothing else better. Or after the update fails, call the warehouse subsystem again to roll back the warehouse receipt and inventory data to achieve final consistency! as the picture shows:
I am very honored to be able to share knowledge and experience with you. It is precisely because of everyone’s selfless sharing that we can grow and progress. I have rarely shared things in recent years. Sometimes it is because I am very busy at work and have no time to write. Sometimes it’s because I’m lazy or I don’t have anything new to share with everyone. Finally, I hope that everyone will criticize and correct my shortcomings in sharing, so that we can make progress together!
The above is the detailed content of Build distribution & service ERP system. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



