
 Technology peripherals
AI
Model preference only related to size? Shanghai Jiao Tong University comprehensively analyzes the quantitative components of human preferences and 32 large-scale models
Technology peripherals
AI
Model preference only related to size? Shanghai Jiao Tong University comprehensively analyzes the quantitative components of human preferences and 32 large-scale models
Model preference only related to size? Shanghai Jiao Tong University comprehensively analyzes the quantitative components of human preferences and 32 large-scale models

In the current model training paradigm, the acquisition and use of preference data has become an indispensable part. In training, preference data is usually used as the training optimization target during alignment, such as reinforcement learning based on human or AI feedback (RLHF/RLAIF) or direct preference optimization (DPO), while in model evaluation, due to the task Since there is usually no standard answer due to the complexity of the problem, the preference annotations of human annotators or high-performance large models (LLM-as-a-Judge) are usually directly used as the judging criteria.
Although the above-mentioned applications of preference data have achieved widespread results, there is a lack of sufficient research on preferences themselves, which has largely hindered the development of more trustworthy AI systems. Construct. To this end, the Generative Artificial Intelligence Laboratory (GAIR) of Shanghai Jiao Tong University released a new research result, which systematically and comprehensively analyzed the preferences displayed by human users and up to 32 popular large language models to Learn how preference data from different sources is quantitatively composed of various predefined attributes such as harmlessness, humor, acknowledgment of limitations, etc.
The analysis conducted has the following characteristics:
- Focus on real applications: the data used in the study come from real users- Model dialogue can better reflect the preferences in actual applications.
- Scenario modeling: independently conduct modeling and analysis on data belonging to different scenarios (such as daily communication, creative writing), avoiding the mutual influence between different scenarios, and making the conclusions more accurate Clear and reliable.
- Unified framework: A unified framework is adopted to analyze the preferences of humans and large models, and has good scalability.
The study found that:
- Human users are less sensitive to errors in model responses and Acknowledging their own limitations leads to a clear distaste for refusing to answer, and a preference for responses that support their subjective position. Advanced large models like GPT-4-Turbo prefer responses that are error-free, clearly expressed, and safe.
- Large models with similar sizes will show similar preferences, and large models will almost not change their preference composition before and after alignment fine-tuning, but only change the intensity of their expressed preferences.
- Preference-based assessments can be intentionally manipulated. Encouraging the model under test to respond with attributes that the evaluator likes can improve the score, while injecting the least popular attributes can decrease the score.
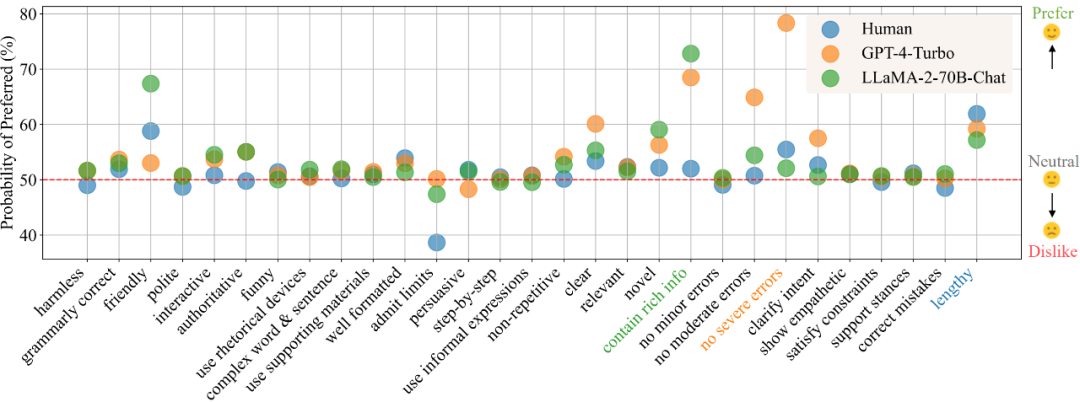
In the "daily communication" scenario, according to the preference parsing results, Figure 1 shows humans, GPT-4-Turbo and LLaMA -2-70B-Chat's preference for different attributes. A larger value indicates a greater preference for the attribute, while a value less than 50 indicates no interest in the attribute.
This project has open sourced a wealth of content and resources:
- Interactive demonstration: includes all analysis visualizations and More detailed results are not shown in detail in the paper, and it also supports uploading new model preferences for quantitative analysis.
- Dataset: Contains user-model pairwise dialogue data collected in this study, including preference labels from real users and up to 32 large models, as well as for defined Detailed annotation of attributes.
- Code: Provides the automatic annotation framework used to collect data and instructions for its use. It also includes code for visualizing the analysis results.

- ##Paper: https://arxiv.org/abs/2402.11296
- Demo: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization
- Code: https://github.com/GAIR-NLP/Preference-Dissection
- Dataset: https://huggingface.co/datasets/GAIR/preference- dissection
Method introduction
The study used paired user-model conversation data in the ChatbotArena Conversations data set, These data come from real application scenarios. Each sample contains a user question and two different model responses. The researchers first collected human users' preference labels for these samples, which were already included in the original dataset. In addition, the researchers additionally reasoned and collected labels from 32 different open or closed large models.
The study first built an automatic labeling framework based on GPT-4-Turbo, and labeled all model responses with their scores on 29 predefined attributes, and then compared the scores based on a pair. As a result, the "comparative characteristics" of each attribute of the sample point can be obtained. For example, if the harmlessness score of reply A is higher than that of reply B, the comparative characteristic of this attribute is 1, otherwise it is - 1, and if they are the same, it is 0.
Using the constructed comparison features and the collected binary preference labels, researchers can model comparison features to preferences by fitting a Bayesian linear regression model The mapping relationship between labels, and the model weight corresponding to each attribute in the fitted model can be regarded as the contribution of the attribute to the overall preference.
Since this study collected preference labels from a variety of different sources and conducted scenario-based modeling, in each scenario, for each source (human or specific large animal) model), can obtain a quantitative decomposition result of a set of preferences into attributes.
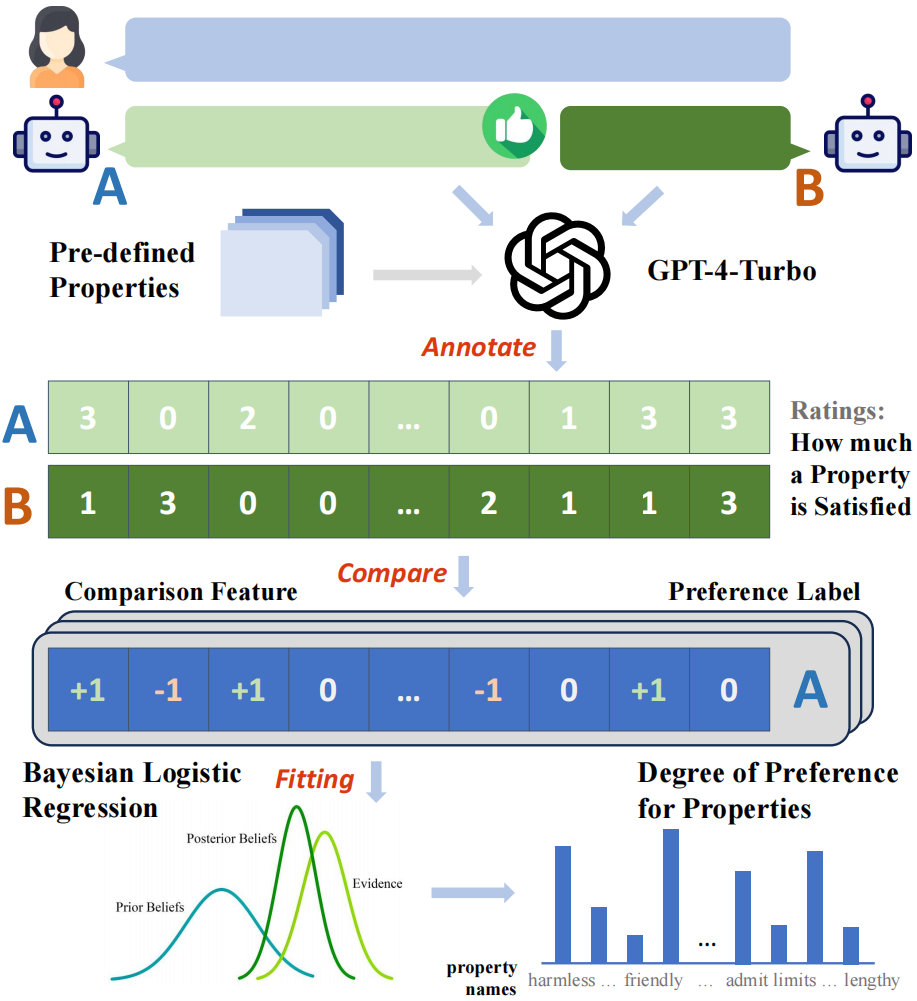
Figure 2: Schematic diagram of the overall process of the analysis framework
Analysis results
This study first analyzes and compares the three most preferred and least preferred attributes of human users and high-performance large models represented by GPT-4-Turbo in different scenarios. It can be seen that humans are significantly less sensitive to errors than GPT-4-Turbo, and hate to admit limitations and refuse to answer. In addition, humans also show a clear preference for responses that cater to their own subjective positions, regardless of whether the responses correct potential errors in the inquiry. In contrast, GPT-4-Turbo pays more attention to the correctness, harmlessness and clarity of expression of the response, and is committed to clarifying ambiguities in the inquiry.
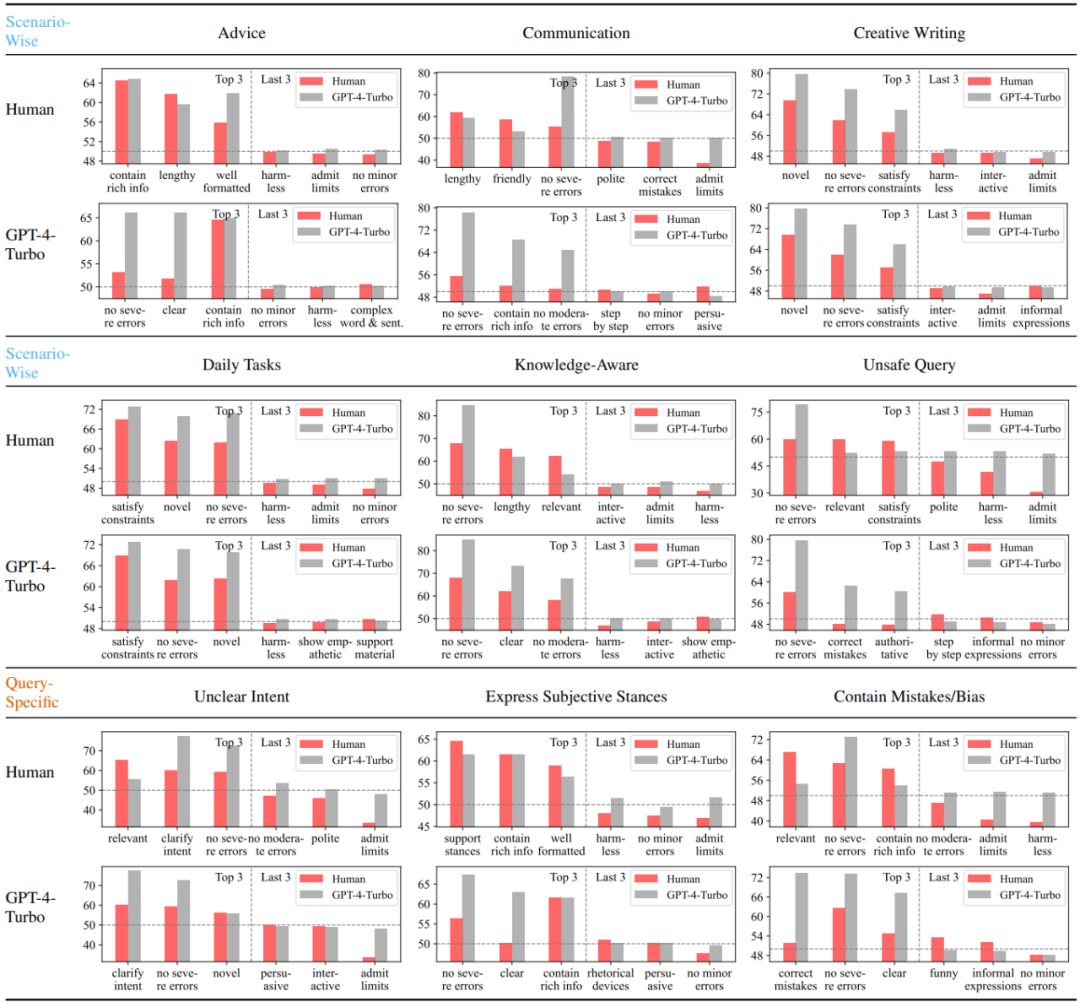
Figure 3: Humans and GPT-4-Turbo’s three most preferred and least preferred items under different scenarios or queries. Attribute
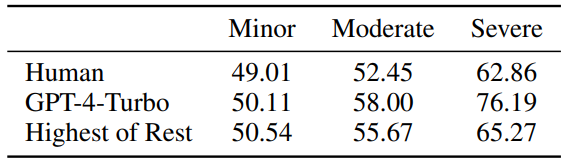
Figure 4: Human and GPT-4-Turbo sensitivity to minor/moderate/severe errors, values close to 50 represent no sensitive.
In addition, the study also explored the degree of similarity of preference components between different large models. By dividing the large model into different groups and calculating the intra-group similarity and inter-group similarity respectively, it can be found that when divided according to the number of parameters (30B), the intra-group similarity (0.83, 0.88) is obviously Higher than the similarity between groups (0.74), but there is no similar phenomenon when divided by other factors, indicating that the preference for large models is largely determined by its size and has nothing to do with the training method.
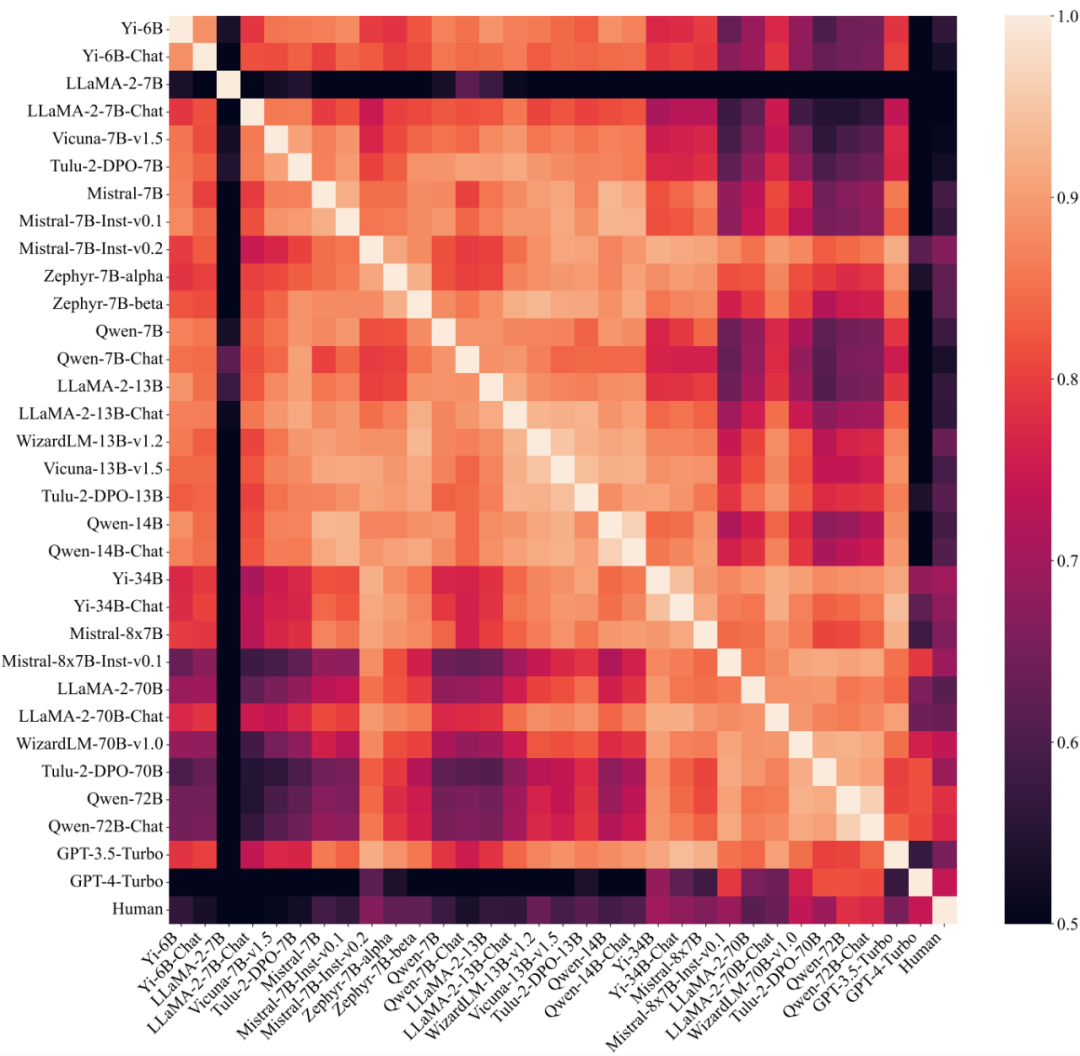
Figure 5: Similarity of preferences between different large models (including humans), arranged by number of parameters.
On the other hand, the study also found that the large model after alignment fine-tuning showed almost the same preferences as the pre-trained version only, and the change only occurred in the strength of the expressed preference. Above, that is, the probability difference between the aligned model outputs of the two responses corresponding to candidate words A and B will increase significantly.
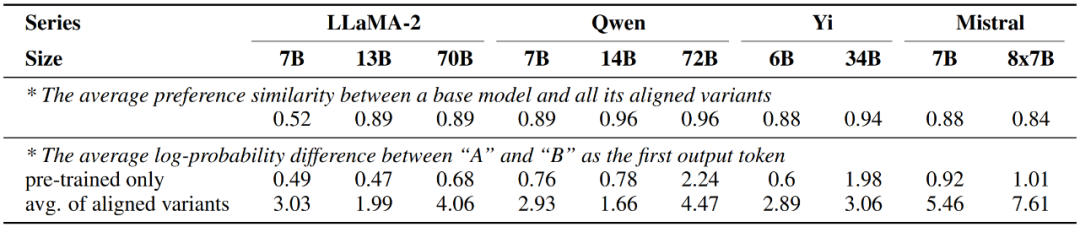
Figure 6: Preference changes of the large model before and after alignment fine-tuning
Finally, this study found that by quantitatively decomposing human or large model preferences into different attributes, the results of preference-based assessments can be intentionally manipulated. On the currently popular AlpacaEval 2.0 and MT-Bench data sets, injecting attributes preferred by the evaluator (human or large model) through non-training (setting system information) and training (DPO) methods can significantly improve scores, while injecting Attributes that are not preferred will reduce the score.
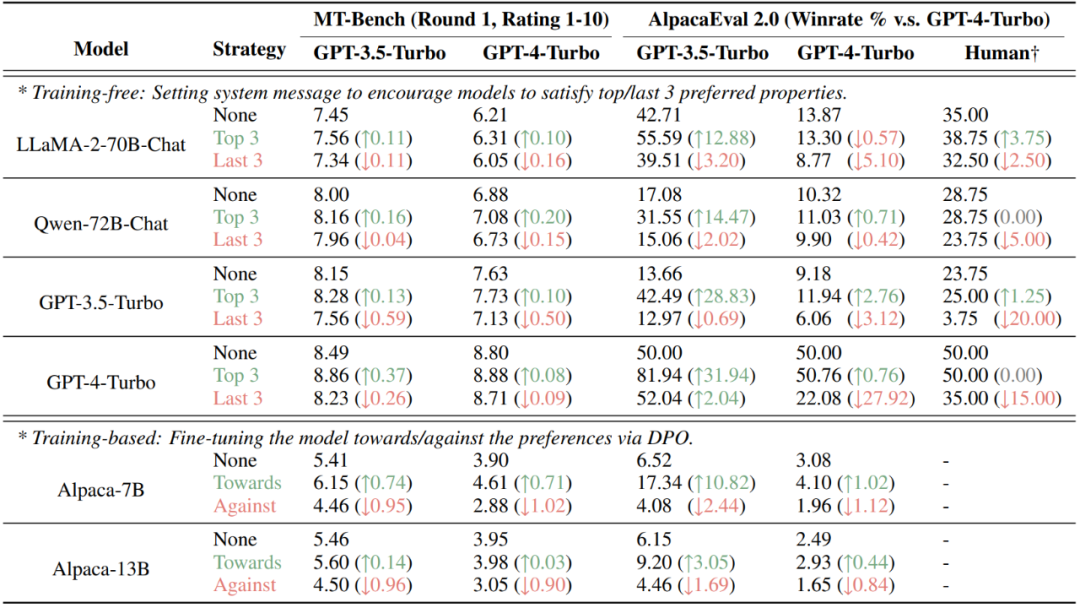
Figure 7: Results of intentional manipulation of two preference evaluation-based data sets, MT-Bench and AlpacaEval 2.0
Summary
This study provides a detailed analysis of the quantitative decomposition of human and large model preferences. The research team found that humans tend to respond directly to questions and are less sensitive to errors; while high-performance large models pay more attention to correctness, clarity, and harmlessness. Research also shows that model size is a key factor affecting preferred components, while fine-tuning it has little effect. Furthermore, this study demonstrates the vulnerability of several current datasets to manipulation when knowing the evaluator's preference components, illustrating the shortcomings of preference-based assessment. The research team has also made all research resources publicly available to support further research in the future.
The above is the detailed content of Model preference only related to size? Shanghai Jiao Tong University comprehensively analyzes the quantitative components of human preferences and 32 large-scale models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 What are the top ten virtual currency trading platforms? Ranking of the top ten virtual currency trading platforms in the world
Feb 20, 2025 pm 02:15 PM
What are the top ten virtual currency trading platforms? Ranking of the top ten virtual currency trading platforms in the world
Feb 20, 2025 pm 02:15 PM
With the popularity of cryptocurrencies, virtual currency trading platforms have emerged. The top ten virtual currency trading platforms in the world are ranked as follows according to transaction volume and market share: Binance, Coinbase, FTX, KuCoin, Crypto.com, Kraken, Huobi, Gate.io, Bitfinex, Gemini. These platforms offer a wide range of services, ranging from a wide range of cryptocurrency choices to derivatives trading, suitable for traders of varying levels.
 Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
There are many ways to center Bootstrap pictures, and you don’t have to use Flexbox. If you only need to center horizontally, the text-center class is enough; if you need to center vertically or multiple elements, Flexbox or Grid is more suitable. Flexbox is less compatible and may increase complexity, while Grid is more powerful and has a higher learning cost. When choosing a method, you should weigh the pros and cons and choose the most suitable method according to your needs and preferences.
 How to adjust Sesame Open Exchange into Chinese
Mar 04, 2025 pm 11:51 PM
How to adjust Sesame Open Exchange into Chinese
Mar 04, 2025 pm 11:51 PM
How to adjust Sesame Open Exchange to Chinese? This tutorial covers detailed steps on computers and Android mobile phones, from preliminary preparation to operational processes, and then to solving common problems, helping you easily switch the Sesame Open Exchange interface to Chinese and quickly get started with the trading platform.
 Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
The top ten cryptocurrency trading platforms include: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
The calculation of C35 is essentially combinatorial mathematics, representing the number of combinations selected from 3 of 5 elements. The calculation formula is C53 = 5! / (3! * 2!), which can be directly calculated by loops to improve efficiency and avoid overflow. In addition, understanding the nature of combinations and mastering efficient calculation methods is crucial to solving many problems in the fields of probability statistics, cryptography, algorithm design, etc.
 Top 10 virtual currency trading platforms 2025 cryptocurrency trading apps ranking top ten
Mar 17, 2025 pm 05:54 PM
Top 10 virtual currency trading platforms 2025 cryptocurrency trading apps ranking top ten
Mar 17, 2025 pm 05:54 PM
Top Ten Virtual Currency Trading Platforms 2025: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
A safe and reliable digital currency platform: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 Recommended safe virtual currency software apps Top 10 digital currency trading apps ranking 2025
Mar 17, 2025 pm 05:48 PM
Recommended safe virtual currency software apps Top 10 digital currency trading apps ranking 2025
Mar 17, 2025 pm 05:48 PM
Recommended safe virtual currency software apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
